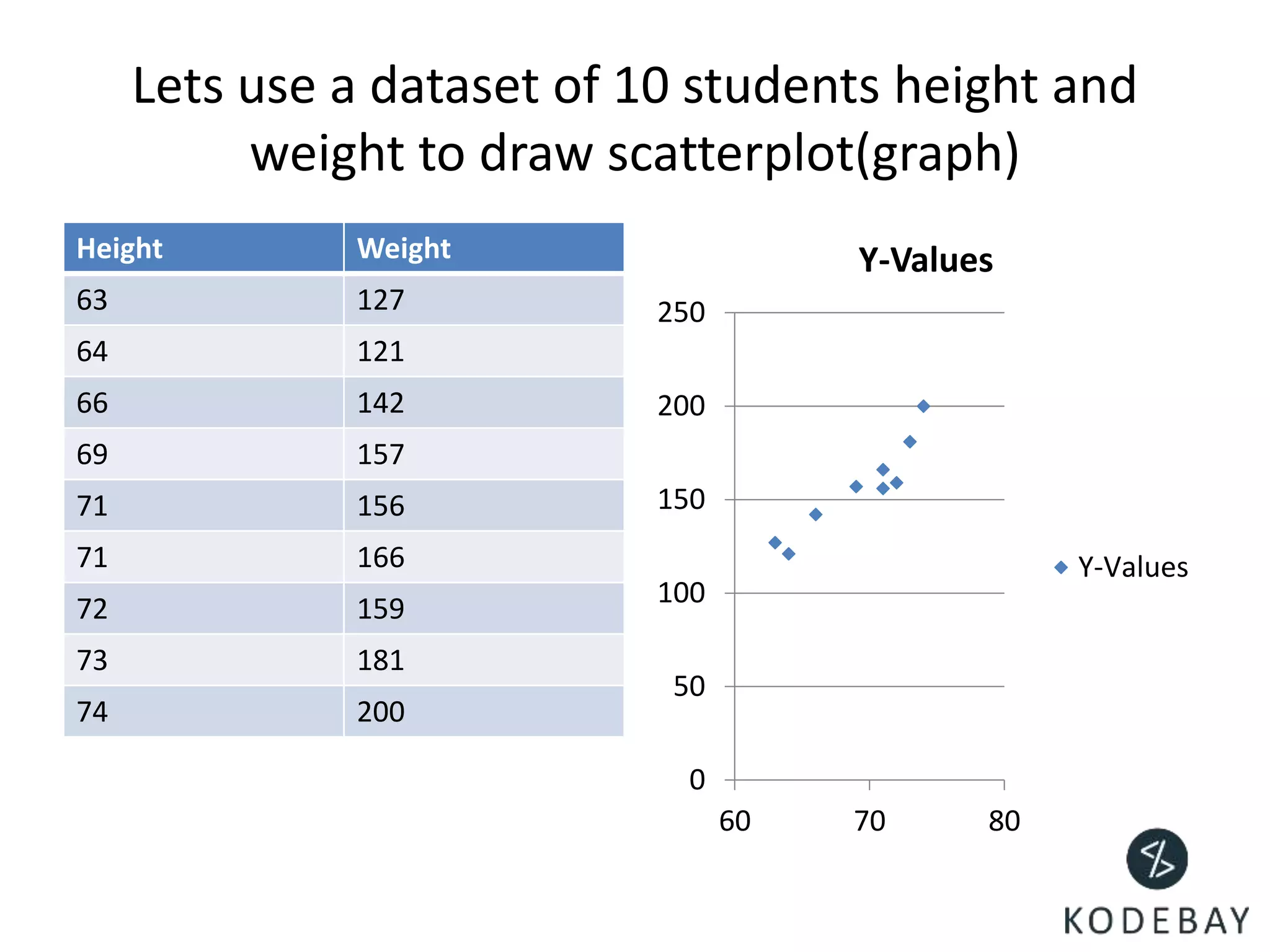
- Linear regression is a predictive modeling technique used to establish a relationship between two variables, known as the predictor and response variables.
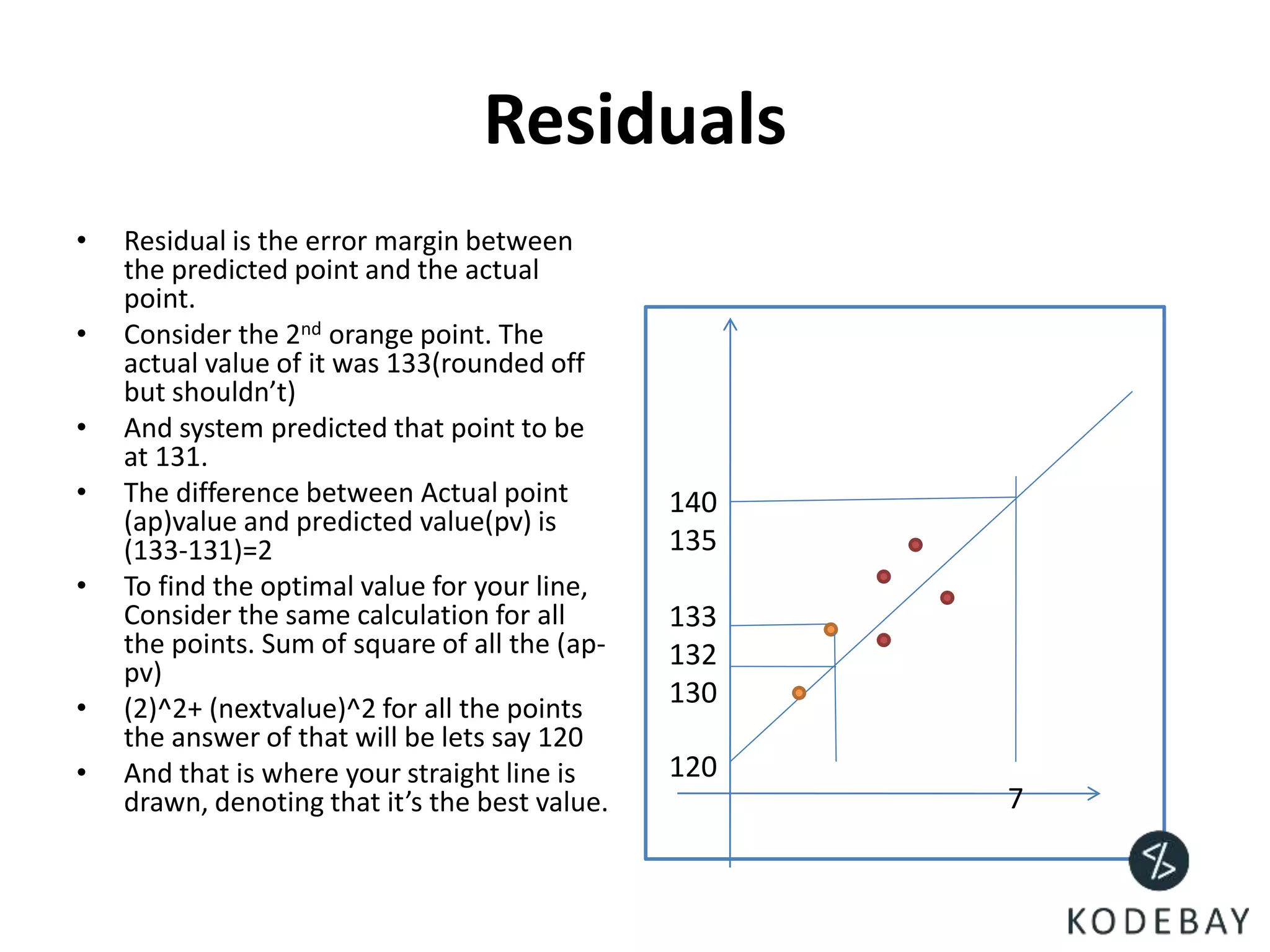
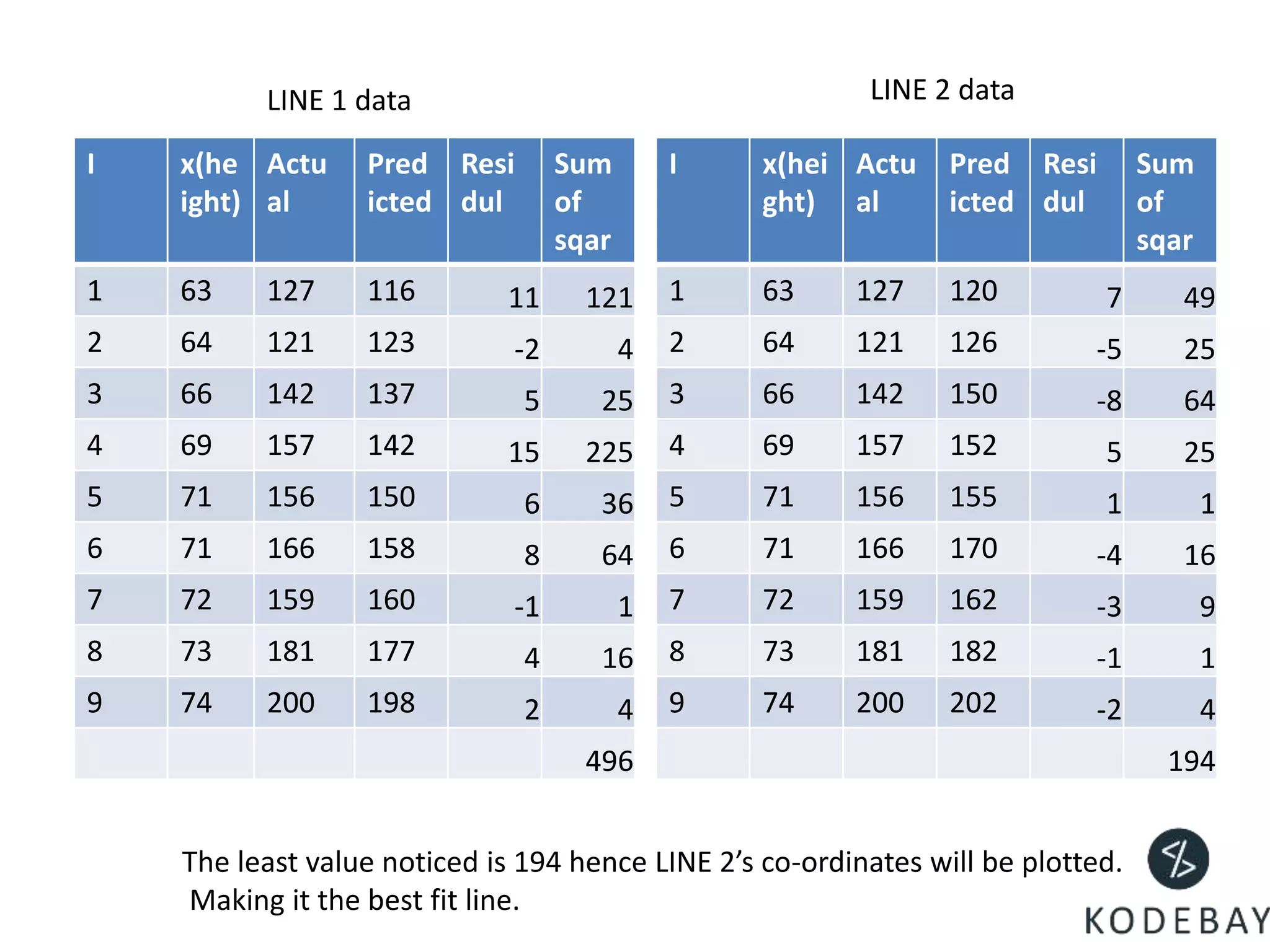
- The residuals are the errors between predicted and actual values, and the optimal regression line is the one that minimizes the sum of squared residuals.
- Linear regression can be used to predict variables like salary based on experience, or housing prices based on features like crime rates or school quality. Co-relation analysis examines the relationships between predictor variables.