Download to read offline
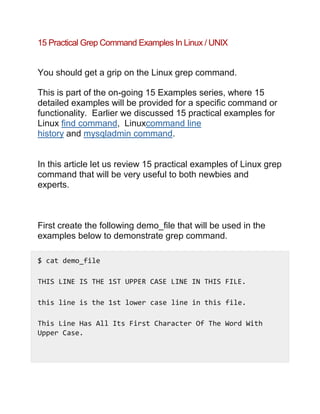
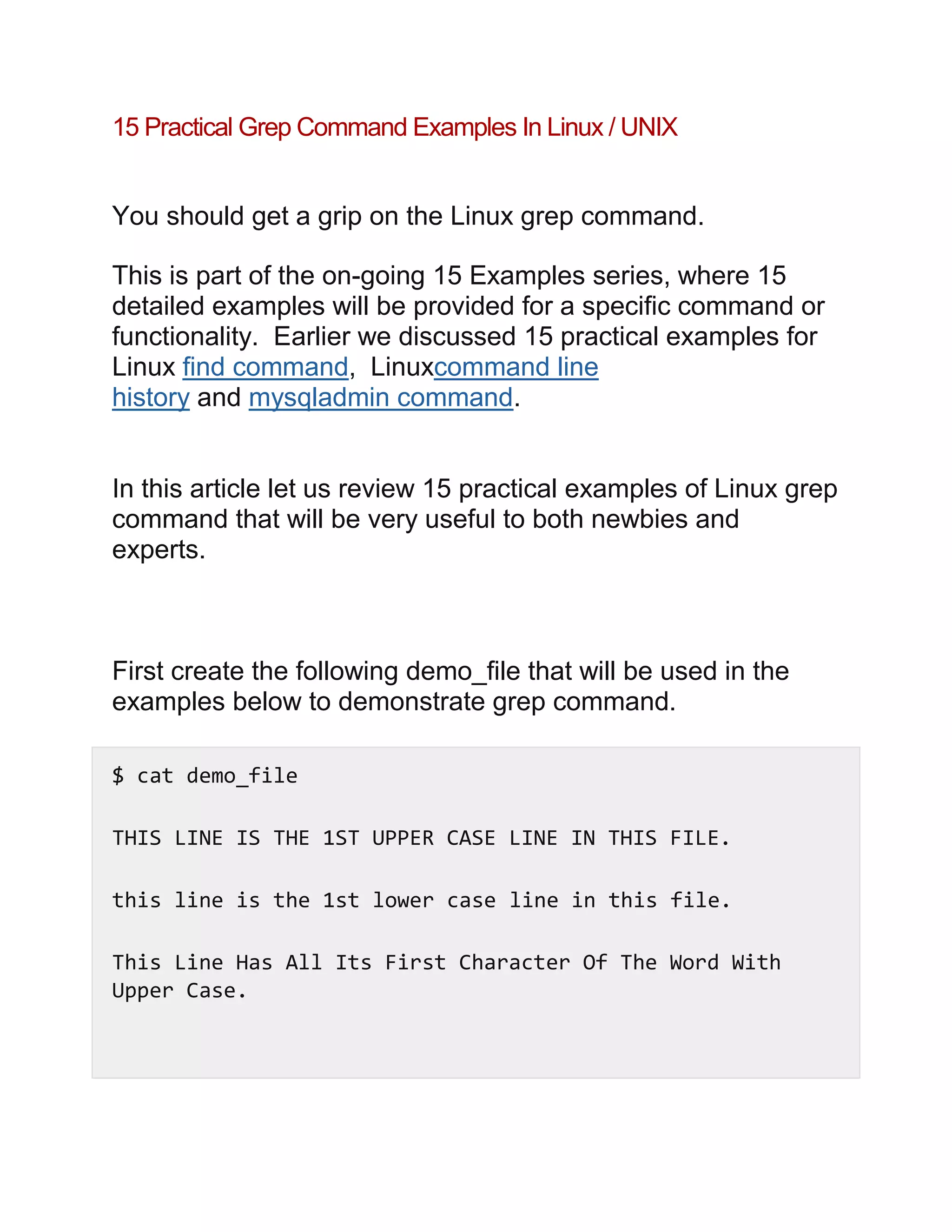


![words such as “the”, “THE” and “The” case insensitively as
shown below.
$ grep -i "the" demo_file
THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE.
this line is the 1st lower case line in this file.
This Line Has All Its First Character Of The Word With
Upper Case.
And this is the last line.
4. Match regular expression in files
Syntax:
grep "REGEX" filename
This is a very powerful feature, if you can use use regular
expression effectively. In the following example, it searches
for all the pattern that starts with “lines” and ends with “empty”
with anything in-between. i.e To search “lines[anything in-
between]empty” in the demo_file.
$ grep "lines.*empty" demo_file
Two lines above this line is empty.](https://image.slidesharecdn.com/15practicalgrepcommandexamplesinlinux-140624075306-phpapp02/85/15-practical-grep-command-examples-in-linux-4-320.jpg)














![$ grep -v "^#|^'|^//" comments
This file shows the comment character in various
programming/scripting languages
If the Line starts with single hash symbol,
then its a comment in Perl and shell scripting.
The line should start with a single quote to comment in VB
scripting.
Double slashes in the beginning of the line for single
line comment in C.
Example 2. Character class expression
As we have seen in our previous regex article example 9, list
of characters can be mentioned with in the square brackets to
match only one out of several characters. Grep command
supports some special character classes that denote certain
common ranges. Few of them are listed here. Refer man
page of grep to know various character class expressions.
[:digit:] Only the digits 0 to 9
[:alnum:] Any alphanumeric character 0 to 9 OR A to Z or
a to z.
[:alpha:] Any alpha character A to Z or a to z.
[:blank:] Space and TAB characters only.](https://image.slidesharecdn.com/15practicalgrepcommandexamplesinlinux-140624075306-phpapp02/85/15-practical-grep-command-examples-in-linux-19-320.jpg)
![These are always used inside square brackets in the form
[[:digit:]]. Now let us grep all the process Ids of ntpd daemon
process using appropriate character class expression.
$ grep -e "ntpd[[[:digit:]]+]" /var/log/messages.4
Oct 28 11:42:20 gstuff1 ntpd[2241]: synchronized to
LOCAL(0), stratum 10
Oct 28 11:42:20 gstuff1 ntpd[2241]: synchronized to
15.11.13.123, stratum 3
Oct 28 12:33:31 gstuff1 ntpd[2241]: synchronized to
LOCAL(0), stratum 10
Oct 28 12:50:46 gstuff1 ntpd[2241]: synchronized to
15.11.13.123, stratum 3
Oct 29 07:55:29 gstuff1 ntpd[2241]: time reset -0.180737 s
Example 3. M to N occurences ({m,n})
A regular expression followed by {m,n} indicates that the
preceding item is matched at least m times, but not more than
n times. The values of m and n must be non-negative and
smaller than 255.
The following example prints the line if its in the range of 0 to
99999.
$ cat number](https://image.slidesharecdn.com/15practicalgrepcommandexamplesinlinux-140624075306-phpapp02/85/15-practical-grep-command-examples-in-linux-20-320.jpg)
![12
12345
123456
19816282
$ grep "^[0-9]{1,5}$" number
12
12345
The file called “number” has the list of numbers, the above
grep command matches only the number which 1 (minimum is
0) to 5 digits (maximum 99999).
Note: For basic grep command examples, read 15 Practical
Grep Command Examples.
Example 4. Exact M occurence ({m})
A Regular expression followed by {m} matches exactly m
occurences of the preceding expression. The following grep
command will display only the number which has 5 digits.
$ grep "^[0-9]{5}$" number](https://image.slidesharecdn.com/15practicalgrepcommandexamplesinlinux-140624075306-phpapp02/85/15-practical-grep-command-examples-in-linux-21-320.jpg)
![12345
Example 5. M or more occurences ({m,})
A Regular expression followed by {m,} matches m or more
occurences of the preceding expression. The following grep
command will display the number which has 5 or more digits.
$ grep "[0-9]{5,}" number
12345
123456
19816282
Note: Did you know that you can use bzgrep command to
search for a string or a pattern (regular expression) on bzip2
compressed files.
Example 6. Word boundary (b)
b is to match for a word boundary. b matches any
character(s) at the beginning (bxx) and/or end (xxb) of a
word, thus btheb will find the but not thet, but bthe will find
they.
# grep -i "btheb" comments
This file shows the comment character in various
programming/scripting languages](https://image.slidesharecdn.com/15practicalgrepcommandexamplesinlinux-140624075306-phpapp02/85/15-practical-grep-command-examples-in-linux-22-320.jpg)
![If the Line starts with single hash symbol,
The line should start with a single quote to comment in VB
scripting.
Double slashes in the beginning of the line for single
line comment in C.
Example 7. Back references (n)
Grouping the expressions for further use is available in grep
through back-references. For ex, ([0-9])1 matches two digit
number in which both the digits are same number like
11,22,33 etc.,
# grep -e '^(abc)1$'
abc
abcabc
abcabc
In the above grep command, it accepts the input the STDIN.
when it reads the input “abc” it didnt match, The line “abcabc”
matches with the given expression so it prints. If you want to
use Extended regular expression its always preferred to use
egrep command. grep with -e option also works like egrep,
but you have to escape the special characters like
paranthesis.](https://image.slidesharecdn.com/15practicalgrepcommandexamplesinlinux-140624075306-phpapp02/85/15-practical-grep-command-examples-in-linux-23-320.jpg)
![Note: You can also use zgrep command to to search inside a
compressed gz file.
Example 8. Match the pattern “Object Oriented”
So far we have seen different tips in grep command, Now
using those tips, let us match “object oriented” in various
formats.
$ grep "OO|([oO]bject( |-)[oO]riented)"
The above grep command matches the “OO”, “object
oriented”, “Object-oriented” and etc.,
Example 9. Print the line “vowel singlecharacter
samevowel”
The following grep command print all lines containing a vowel
(a, e, i, o, or u) followed by a single character followed by the
same vowel again. Thus, it will find eve or adam but not vera.
$ cat input
evening
adam
vera](https://image.slidesharecdn.com/15practicalgrepcommandexamplesinlinux-140624075306-phpapp02/85/15-practical-grep-command-examples-in-linux-24-320.jpg)
![$ grep "([aeiou]).1" input
evening
adam
Example 10. Valid IP address
The following grep command matches only valid IP address.
$ cat input
15.12.141.121
255.255.255
255.255.255.255
256.125.124.124
$ egrep 'b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-
9]?.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' input
15.12.141.121
255.255.255.255](https://image.slidesharecdn.com/15practicalgrepcommandexamplesinlinux-140624075306-phpapp02/85/15-practical-grep-command-examples-in-linux-25-320.jpg)


This document provides 15 examples of practical grep command usage in Linux/UNIX. It begins with basic uses like searching for a string in a single file or multiple files. It then demonstrates more advanced features such as ignoring case, using regular expressions to match patterns, highlighting search results, counting/inverting matches, and displaying line numbers. Overall, the examples progress from introductory to more complex uses of grep flags and operations to help both new and experienced users better utilize this powerful search tool.