Picard
• Picard [1]:Preconditioned ICA for Real Data
– It shows state of the art speed of convergence,
and solves the same problems as the widely used
FastICA, Infomax and extended-Infomax, faster.
• https://github.com/pierreablin/picard
– 2018年発表された新しいICAアルゴリズム
• 収束が早い
[1]Ablin, Pierre, Jean-François Cardoso, and Alexandre Gramfort. "Faster independent component analysis by preconditioning with Hessian
approximations." IEEE Transactions on Signal Processing 66.15 (2018): 4040-4049.
𝑦 = 𝑊𝑥
今回の話に直接関係ないが、
𝑦= 𝑊𝑥 ↔ 𝑥 = 𝑊−1
𝑦 似ている構造・・・
• 下記のAutoencorder[1]と等価
– 中間層が1層、バイアスがなく(データ平均化)、
重みづけの数は同じ、活性化関数無し
𝑥 = 𝑊−1
𝑦
x x
𝐼 = 𝑊𝑊−1となるようなWを見つけるわけだが、たくさん存在
PCAは分散最大化、ICAは信号源の独立という条件を制約
NNの最適化技法(e.g Adam)+制約条件を組み合わせれば別の解法も出来るかも
x x
中間層を削除した場合は、
PCAのn主成分を使うのと同じ
[1]Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks." science 313.5786 (2006): 504-507.







![主成分分析(PCA)とは
• 参考文献から主成分分析の定義を抜粋
– “相関のある多数の変数から相関のない少数で全体のばらつき
を最もよく表す主成分と呼ばれる変数を合成する多変量解析の
一手法。データの次元を削減するために用いられる。”[1]
– “多変量の資料から、エッセンスとなる少数の変量を合成し、それ
で資料を分析するのが主成分分析”[2]
– “主成分分析(pincipal component analysis) は,各データを主部分
空間と呼ばれる低次元の線形空間上へ直交射影する方法であ
る。(略)データの統計的特徴を保持しつつ,次元を圧縮すること
が可能になる。”[3]
– “主成分分析(Principal Component Analysis :PCA)は、さまざまな
分野にわたって広く使用されている教師なし線形変換法であり、
最もよく用いられるタスクは次元削減である。”[4]
– “主成分分析は、学習データの分散が最大になる方向への線形
変換を求める手法である。”[5]
[1]主成分分析, https://ja.wikipedia.org/wiki/%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90
[2]涌井 良幸, 涌井 貞美, 図解でわかる多変量解析, 日本実業出版社, 2001 [3]後藤 正幸, 小林 学, 入門パターン認識と機械学習, コロナ社, 2014
[4]Sebastian Raschka, Python機械学習プログラミング 達人データサイエンティストによる理論と実践, インプレス, 2016
[5]平井 有三, はじめてのパターン認識, 森北出版, 2012](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-8-320.jpg)
![主成分分析(PCA)とは
• 参考文献から主成分分析の定義を抜粋
– “相関のある多数の変数から相関のない少数で全体のばらつき
を最もよく表す主成分と呼ばれる変数を合成する多変量解析の
一手法。データの次元を削減するために用いられる。”[1]
– “多変量の資料から、エッセンスとなる少数の変量を合成し、それ
で資料を分析するのが主成分分析”[2]
– “主成分分析(pincipal component analysis) は,各データを主部分
空間と呼ばれる低次元の線形空間上へ直交射影する方法であ
る。(略)データの統計的特徴を保持しつつ,次元を圧縮すること
が可能になる。”[3]
– “主成分分析(Principal Component Analysis :PCA)は、さまざまな
分野にわたって広く使用されている教師なし線形変換法であり、
最もよく用いられるタスクは次元削減である。”[4]
– “主成分分析は、学習データの分散が最大になる方向への線形
変換を求める手法である。”[5]
[1]主成分分析, https://ja.wikipedia.org/wiki/%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90
[2]涌井 良幸, 涌井 貞美, 図解でわかる多変量解析, 日本実業出版社, 2001 [3]後藤 正幸, 小林 学, 入門パターン認識と機械学習, コロナ社, 2014
[4]Sebastian Raschka, Python機械学習プログラミング 達人データサイエンティストによる理論と実践, インプレス, 2016
[5]平井 有三, はじめてのパターン認識, 森北出版, 2012](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-9-320.jpg)




![No. 国語テスト1 国語テスト2 数学テスト 合否
1 90 80 50 合格
… … … … …
2種類の国語のテスト、数学のテストの結果から合否を予測する
説明変数:各種テスト 目的変数:合否
結果:
accuracy = 0.864
confusion matrix =
[[56 13]
[ 4 52]]
coefficient = [[-0.06441062 0.16919924
0.0143036 ]]
intercept = [-5.76899425]](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-14-320.jpg)
![No. 国語テスト1 国語テスト2 数学テスト 合否
1 90 80 50 合格
… … … … …
2種類の国語のテスト、数学のテストの結果から合否を予測する
説明変数:各種テスト 目的変数:合否
結果:
accuracy = 0.864
confusion matrix =
[[56 13]
[ 4 52]]
coefficient = [[-0.06441062 0.16919924
0.0143036 ]]
intercept = [-5.76899425]
←国語テスト1の点数が高いと不合格?](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-15-320.jpg)
![No. 国語テスト1 国語テスト2 数学テスト 合否
1 90 80 50 合格
… … … … …
2種類の国語のテスト、数学のテストの結果から合否を予測する
説明変数:各種テスト 目的変数:合否
結果:
accuracy = 0.864
confusion matrix =
[[56 13]
[ 4 52]]
coefficient = [[-0.06441062 0.16919924
0.0143036 ]]
intercept = [-5.76899425]
国語テスト1の点数が高い人は
国語テスト2の点数が高い!(高相関)
相関の高い説明変数が存在したとき
の回避策
・正則化を用いて抑制
L1ノルム=変数の縮小選択
L2ノルム
・相関の高い説明変数を削除
・相関の高い説明変数を合成
→この場合は単純加算でもOK
(線形の分類/回帰モデル)だけの問題?
散布図行列を眺めてみる](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-16-320.jpg)
![PCA後のデータで散布図行列を描いてみる
第1主成分(PCA1軸)、第2主成分(PCA2軸)で分離される事が分かる
第1,2主成分を用いてロジスティック回帰を行う
結果:
accuracy = 1.0
confusion matrix =
[[69 0]
[ 0 56]]
coefficient = [[4.99597397 3.40544357]]
intercept = [3.78853398]
寄与率(主成分がどれだけ元の信号説明
しているかを表す値)
[0.66637975 0.33065191 0.00296834]
※第1主成分で66%, 第2主成分で33%](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-17-320.jpg)



![神経細胞の活動によって生じる電位
• 神経細胞の活動によって生じる電流が頭皮、頭蓋骨、
髄膜(硬膜)、髄液を通り電位差として頭皮に発生=脳波
– 頭皮、頭蓋骨、髄膜(硬膜)、髄液は抵抗
– 神経細胞の活動由来の電流は微弱
– 頭皮に生じる電位差は数[μV]~数[十μV]
電流の流れ→
(体積電流)
オームの法則で簡単に考えると
VEEG=INeuron R
※各成分は下記になる
VEEG:脳波
INeuron:神経細胞によって生じた電流
R:髄液などの抵抗成分
ネットワーク(未知)
R I
←電極1と2の2点間に電位差として
神経活動由来の電位が計測される
実際には複数の電極(20~)で計測
電流源→
髄膜(硬膜)/髄液
頭蓋骨
頭皮
電極1
電極2
参考資料](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-21-320.jpg)
![脳波データ
• OSSの解析ソフトBrainstorm[1]の
チュートリアル用に公開されている脳波データ
[1]https://neuroimage.usc.edu/brainstorm/Introduction](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-22-320.jpg)







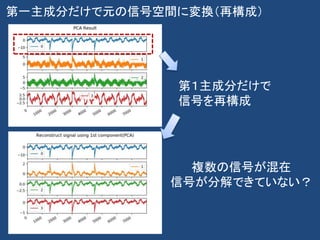


![ICAにおける問題[1]
• 1.信号の時間構造の問題
– ”信号の持つ時間方向の構造という情報を使っていない.したがって,信号を本質的には時
系列として扱っていないことになる.これまでは一般論として理論が構築されてきたが,今後
個別の問題を考える際には時系列信号としての特性を解析に取り入れる枠組をきちんと議
論する必要があるだろう.”
• 2.非線形混合の問題
– ”信号の混合作用のモデルは線形作用だけを考え,信号の混合における非線形性の影響
というものは考えていない.”
• 3.観測雑音の問題
– ”観測値に雑音が混入したモデルの解析が乏しいのが現状である.”
– ”正規雑音の場合には尖度(kurtosis)などの高次のキユムラントを用いることによって理論
的には雑音の影響を受けない評価関数を構成することができるが,実際には高次であれ
ばあるほど外れ値などの影響を受けやすい.一部の研究によって学習則の安定性,頑健性
なども取り上げられてはいるが,各種のアルゴリズムの比較などはまだ十分で、はない.”
• 4.アルゴリズムの高速化・安定性
– ”多くのアルゴリズムは勾配法により実装されているが,例えばMEGのようにセンサの多次
元化,データの大規模化が急速に進んでいる計測分野で利用する場合,勾配法は十分に
速いとはいえないので,アルゴリズムの高速化は急務である.”
[1]村田昇. 入門独立成分分析. 東京電機大学出版局, 2004.](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-33-320.jpg)
![Picard
• Picard [1]: Preconditioned ICA for Real Data
– It shows state of the art speed of convergence,
and solves the same problems as the widely used
FastICA, Infomax and extended-Infomax, faster.
• https://github.com/pierreablin/picard
– 2018年発表された新しいICAアルゴリズム
• 収束が早い
[1]Ablin, Pierre, Jean-François Cardoso, and Alexandre Gramfort. "Faster independent component analysis by preconditioning with Hessian
approximations." IEEE Transactions on Signal Processing 66.15 (2018): 4040-4049.](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-34-320.jpg)
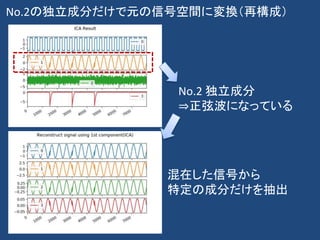

![𝑦 = 𝑊𝑥
今回の話に直接関係ないが、
𝑦 = 𝑊𝑥 ↔ 𝑥 = 𝑊−1
𝑦 似ている構造・・・
• 下記のAutoencorder[1]と等価
– 中間層が1層、バイアスがなく(データ平均化)、
重みづけの数は同じ、活性化関数無し
𝑥 = 𝑊−1
𝑦
x x
𝐼 = 𝑊𝑊−1となるようなWを見つけるわけだが、たくさん存在
PCAは分散最大化、ICAは信号源の独立という条件を制約
NNの最適化技法(e.g Adam)+制約条件を組み合わせれば別の解法も出来るかも
x x
中間層を削除した場合は、
PCAのn主成分を使うのと同じ
[1]Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks." science 313.5786 (2006): 504-507.](https://image.slidesharecdn.com/20191124decompositonusingpca-191209153423/85/13-KAIM-37-320.jpg)












![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]DIVERSE TRAJECTORY FORECASTING WITH DETERMINANTAL POINT PROCESSES](https://cdn.slidesharecdn.com/ss_thumbnails/kimura20200821dlseminarv1-200821021249-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/0105-180105000252-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[ICLR/ICML2019読み会] Data Interpolating Prediction: Alternative Interpretation ...](https://cdn.slidesharecdn.com/ss_thumbnails/20190721shimada-190721024027-thumbnail.jpg?width=640&height=640&fit=bounds)











