Download to read offline






![統計を背景に持つ分析技法が注目
[1]イアン・エアーズ 山形浩生 訳, “その数学が戦略を決める (文春文庫)”, 株式会社文藝春秋, 2010年 第1刷, p42, p218, p262
2013/12007 20142013/4
「その数学が戦略を決めるより」[1]より抜粋
“専門家:経験と直感に基づく意見。
絶対計算:大量データの解析に基づく分析。“
“専門家と絶対計算のどちらかが優秀かを比べると、ほぼ例外なく絶対計算が勝つ。
理由:人間は大量の条件にうまく重みづけができない。感情や先入観に左右されがち。“
“手法自体は昔からあった。でもこうした周辺の条件が整ってきたことで、一気に絶対計算があらゆる
場面で容易に使えるようになった。ただし、完ぺきではない。”
絶対計算≒コンピュータによる大量データ+分析手法
分析手法の改善、大量データへの分析手法・
計算リソースが手に入れやすくなった](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-7-2048.jpg)
![統計を背景に持つ分析技法が注目
• Just One Word: Statistics[1] ※2009年
– “I keep saying that the sexy job in the next 10 years will be
statisticians,” said Hal Varian, chief economist at Google.
• Jobs in IT: The Hottest New Careers in Tech ?[2] ※2010年
– Data Mining/Machine Learning/AI/Natural Language
Processing
– Business Intelligence/Competitive Intelligence
– Analytics/Statistics – specifically Web Analytics, A/B Testing
and statistical analysis
• グーグルやマイクロソフトによると、「統計分析」こそ次の
10年でもっとも魅力的な職業になるのだそうです[3]
[2]The Top Three hottest new majors for a career in technology
http://jobsblog.com/blog/top-three-new-tech-majors/
[1]For Today’s Graduate, Just One Word: Statistics
http://www.nytimes.com/2009/08/06/technology/06stats.html?_r=3
[3]次の10年、「統計分析」こそテクノロジー分野でいちばんホットな職業になる
http://www.publickey1.jp/blog/10/10_3.html](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-8-2048.jpg)




![ガートナー 先進テクノロジのハイプサイクル 2015~2018 赤破線は機械学習、応用したテクノロジを指す
[1]Gartner's 2015 Hype Cycle for Emerging Technologies Identifies the Computing Innovations That Organizations Should Monitor
https://www.gartner.com/newsroom/id/3114217
[2]Gartner's 2016 Hype Cycle for Emerging Technologies Identifies Three Key Trends That Organizations Must Track to Gain Competitive Advantage
http://www.gartner.com/newsroom/id/3412017
[3]ガートナー、「先進テクノロジのハイプ・サイクル:2017年」を発表
https://www.gartner.com/jp/newsroom/press-releases/pr-20170823
[4]ガートナー、「先進テクノロジのハイプ・サイクル:2018年」を発表
https://www.gartner.com/jp/newsroom/press-releases/pr-20180822](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-13-2048.jpg)
![機械学習
• 機械学習
– コンピュータにヒトのような学習能力を持たせるた
めの技術の総称[1]
– 人間が自然に行っている学習能力と同様の機能を
コンピュータで実現しようとする技術・手法のこと[2]
[1]杉山 将, "イラストで学ぶ 機械学習 最小二乗法による識別モデル学習を中心に (KS情報科学専門書)", 講談社, 2013年
[2]機械学習:http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-14-2048.jpg)









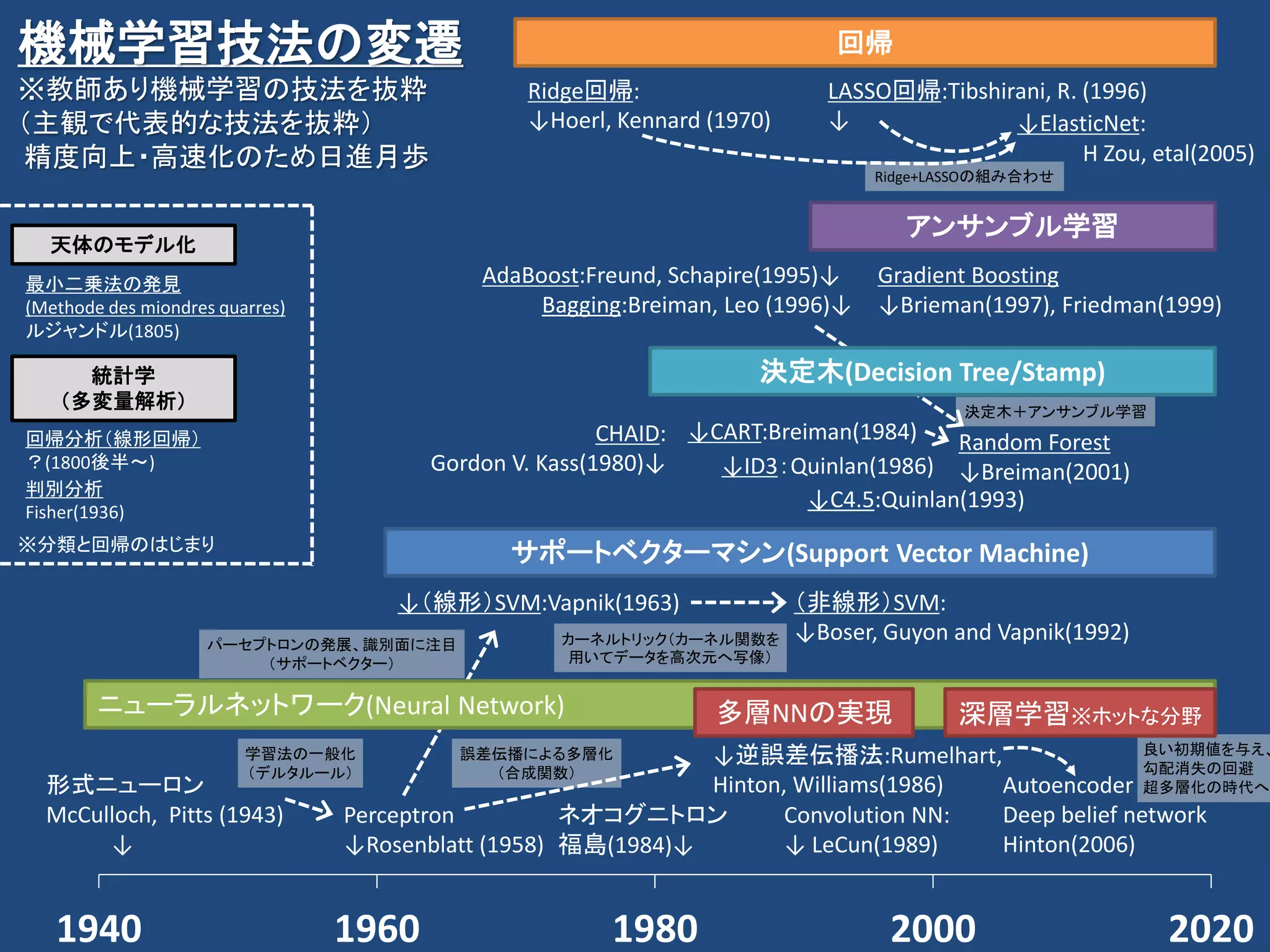







![(線形)判別分析
• 概要
– 事前に与えられているデータが異なるグループに分かれる
ことが明らかな場合、新しいデータが得られた際に、どちら
のグループに入るのかを判別するための基準(判別関数)
を得るための手法[1]
⇒与えられたデータをもとに「分類」する技法
• どのように分類するか?
– 1本の線(平面、超平面)で分類を行う。
[1]https://ja.wikipedia.org/wiki/%E5%88%A4%E5%88%A5%E5%88%86%E6%9E%90](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-32-2048.jpg)
![(線形)判別分析
• 線形識別関数/判別関数
– 群(グループ、クラス)の塊(分布)が重ならない方向を探す。
クラスを分ける直線(判別関数)になる。
[1]図は引用し加工:http://www.weblio.jp/content/%E5%88%A4%E5%88%A5%E5%88%86%E6%9E%90
[2]杉山将,”イラストで学ぶ機械学習”, p72-74
判別関数の式
𝑓 𝑥 = 𝑤0 𝑥 + ⋯ + 𝑐 = 𝑤 𝑇 𝑥 + 𝑐
データから分布が重ならない方向の式(wとc)を
求める。2変数の場合は直線、3変数は面、4変数
以上は超平面となる。
条件有り:各クラスにおいて、共分散行列の等し
いガウス分布に従うとき最適な分類が可能[2]
→クラスの確率分布が正規分布を仮定](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-34-2048.jpg)

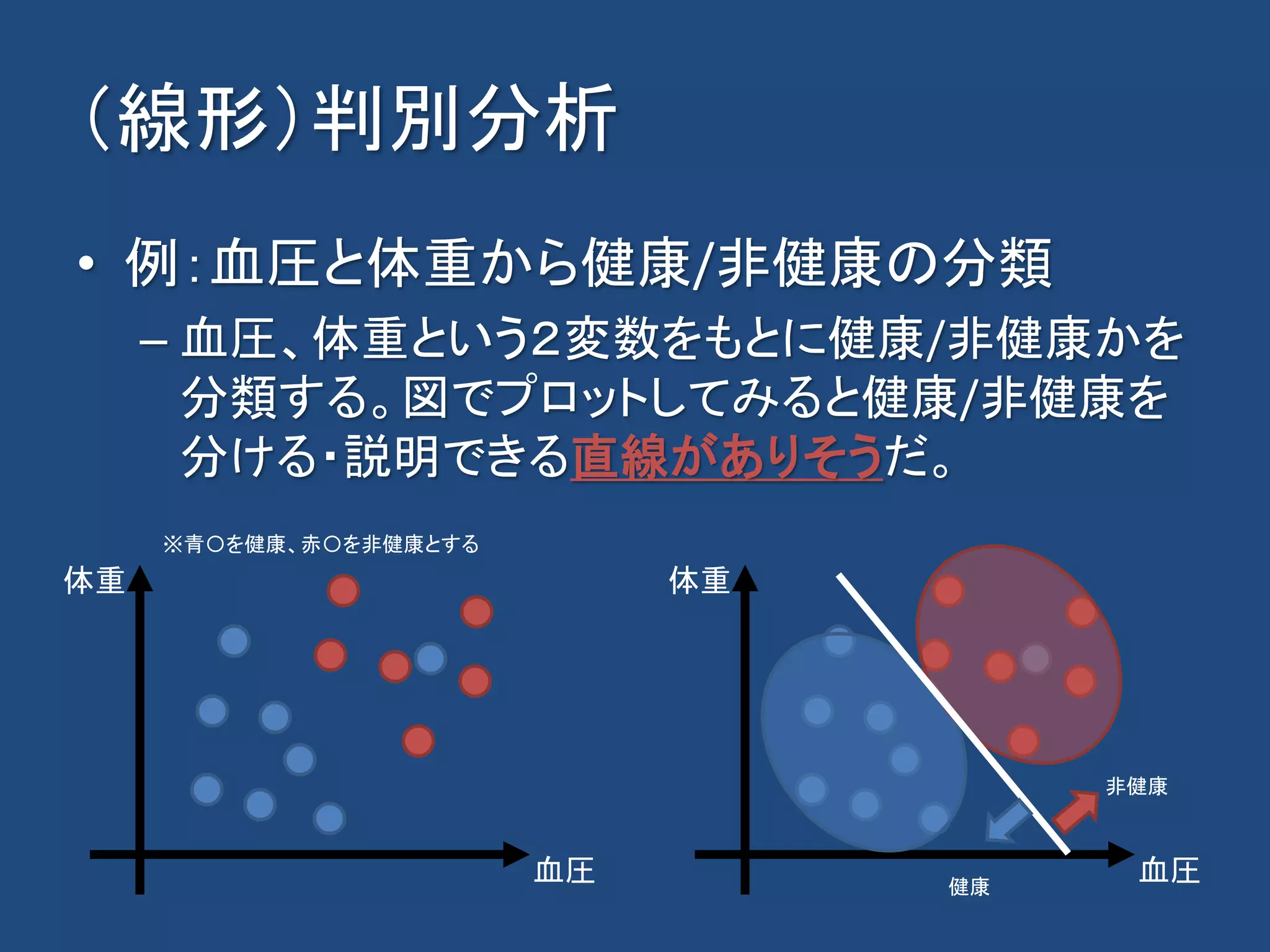
![(線形)サポートベクターマシン
• 概要
– 訓練サンプルから、各データ点との距離が最大となるマー
ジン最大化超平面を求めるという基準で線形入力素子のパ
ラメータを学習する。 [1]
– 分類/回帰も可能。
• どのように分類するか?
– マージン最大化の識別線・面で分類を行う。
• 「境界を,それぞれの集合でもっとも境界に近い点のど
ちらからも,もっとも遠くなるように置く」[2]
[1] https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%9D%E3%83%BC%E3%83%88%E3%83%99%E3%82%AF%E3%82%BF%E3%83%BC%E3%83%9E%E3%82%B7%E3%83%B3
[2] http://racco.mikeneko.jp/Kougi/10s/AS/AS10pr.pdf](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-36-2048.jpg)


![(非線形)サポートベクターマシン
• 直線・面で分離できない場合
– 1つ次元を上げて線から面で分類ができないか?
• 「線形分離可能でない学習データは、非線形変換で高次
元特徴空間へ写像することにより線形分離可能となる可
能性がある」[1]
– カーネルトリック
• カーネル関数を用いてデータを高次元へ写像
– カーネル関数:多項式カーネル、ガウス関数など
[1]平井 有三, "はじめてのパターン認識", 森北出版, 2012年](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-40-2048.jpg)
![[1] SVM with polynomial kernel visualization https://www.youtube.com/watch?v=3liCbRZPrZA
(非線形)サポートベクターマシン
• SVM with polynomial kernel visualization[1]
– 多項式関数(y=w0*x+w1*x^2…+c)をカーネル関数
青/赤の点を分類
青の点は白い円内にある
カーネル関数として多項式関数を使用
3次元の空間に写像
識別面で分類→](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-41-2048.jpg)


![決定木
• 概要
– 決定木は予測モデルであり、ある事項に対する観察結果か
ら、その事項の目標値に関する結論を導く。内部節点は変
数に対応し、子節点への枝はその変数の取り得る値を示す。
葉(端点)は、根(root)からの経路によって表される変数値
に対して、目的変数の予測値を表す。[1]
• どのように分類するか?
– IF-THENルールから分類/回帰を行う。
– 回帰を行う決定木は回帰木
[1] https://ja.wikipedia.org/wiki/%E6%B1%BA%E5%AE%9A%E6%9C%A8](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-44-2048.jpg)









![ニューラルネットワークの歴史
• 形式ニューロン(Threshold Logical Unit)
– McCulloch, Pitts (1943)
• Perceptron
– Rosenblatt (1958)
~人工知能 冬の時代~
• Neocognitron
– 福島(1980)
• Back propagation
– Rumelhart, Hinton, Williams(1986)
• Convolution Neural Network
– LeCun(1989)
• Autoencoder, Deep belief network
– Hinton(2006)
線形識別しかできないということで冬の時代
の突入したといわれているが、、、
「パーセプトロンへの興味が薄れた原因はア
メリカではミンスキーがダメだと言ったからだ
ということになっていますが、要するに当時の
テクノロジーで作れる見込みがほとんどな
かったというのが本当の原因ではないかと思
います。
・・・
いまの単純なものでさえその時代のテクノロ
ジーでは実現できない。ましてやもっと複雑
なものなど夢のまた夢だし、複雑にしたら何
が起こるかを解析する数学的な手段もちょっ
と見当がつかない。」[1]
[1]甘利俊一, "ニューロコンピューティングから
情報幾何学へ (ステアリングシリーズ―科学
技術を先導する30人)", 三田出版会, 1990, 第
一版第一刷](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-54-2048.jpg)












![M5StickV
・Kendryte K210[1]
・LCD
・カメラ
を1つにまとめたHW
3000円
機械学習の成果を
現実世界で手軽に使
う共通HWになりうる
≒モデルを差し替えて
機能を実現する
[1]Windows環境でSiPEED M1 dockが顔認識できるまでの手順
https://qiita.com/tomitomi3/items/d1b675957238f9b7f965](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-68-2048.jpg)





![ネットで調べると色々言葉が出てくるが、、、
• 多変量解析
– 変量が2つ以上のことを多変量という(1つの場合は単変量?)
– 複数の項目について同時に調査が行われた資料の分析に有効な統計
解析の手法[1]
– 複数の結果変数からなる多変量データを統計的に扱う手法[2]
• データマイニング
– 大量のデータの中からビジネスに有用な知識となるパターンを発見する
プロセス[3]
– 統計学、パターン認識、人工知能等のデータ解析の技法を大量のデー
タに網羅的に適用することで知識を取り出す技術[4]
[1]涌井 良幸, 涌井 貞美, "図解でわかる多変量解析―データの山から本質を見抜く科学的分析ツール", 日本実業出版社, 2003年第8刷
[2]多変量解析:http://ja.wikipedia.org/wiki/%E5%A4%9A%E5%A4%89%E9%87%8F%E8%A7%A3%E6%9E%90
[3]近藤 宏 , 末吉 正成, "Excelでできるかんたんデータマイニング入門", 同友館
[4]データマイニング: http://ja.wikipedia.org/wiki/%E3%83%87%E3%83%BC%E3%82%BF%E3%83%9E%E3%82%A4%E3%83%8B%E3%83%B3%E3%82%B0](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-74-2048.jpg)
![ネットで調べると色々言葉が出てくるが、、、
• データサイエンス(データサイエンティスト)
– データに関する研究を行う学問。(略)データサイエンスの研究者や実践
者はデータサイエンティストと呼ばれる。[1]
• パターン認識
– 物事の類型を知るはたらき、およびその内容[2]
– 画像・音声などの雑多な情報を含むデータの中から、意味を持つ対象を
選別して取り出す処理[3]
• 機械学習
– コンピュータにヒトのような学習能力を持たせるための技術の総称[4]
– 人間が自然に行っている学習能力と同様の機能をコンピュータで実現し
ようとする技術・手法のこと[5]
[1]データサイエンス:http://ja.wikipedia.org/wiki/%E3%83%87%E3%83%BC%E3%82%BF%E3%82%B5%E3%82%A4%E3%82%A8%E3%83%B3%E3%82%B9
[2]平井 有三, "はじめてのパターン認識", 森北出版, 2012年
[3]パターン認識:http://ja.wikipedia.org/wiki/%E3%83%91%E3%82%BF%E3%83%BC%E3%83%B3%E8%AA%8D%E8%AD%98
[4]杉山 将, "イラストで学ぶ 機械学習 最小二乗法による識別モデル学習を中心に (KS情報科学専門書)", 講談社, 2013年
[5]機械学習:http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92](https://image.slidesharecdn.com/machinelearninglandscapekaim11-190816141516/75/11-KAIM-75-2048.jpg)
KAIM(金沢人工知能勉強会)では最近の機械学習技法およびアプリケーションで紹介している。今回は改めて「機械学習」の技法について紹介する。 KAIM (Kanazawa Artificial Intelligence Meetup) introduced recently Machine learning techniques and Application including deep learning. In this presentation, I will introduce a little old Machine learning techniques.


























![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)












