






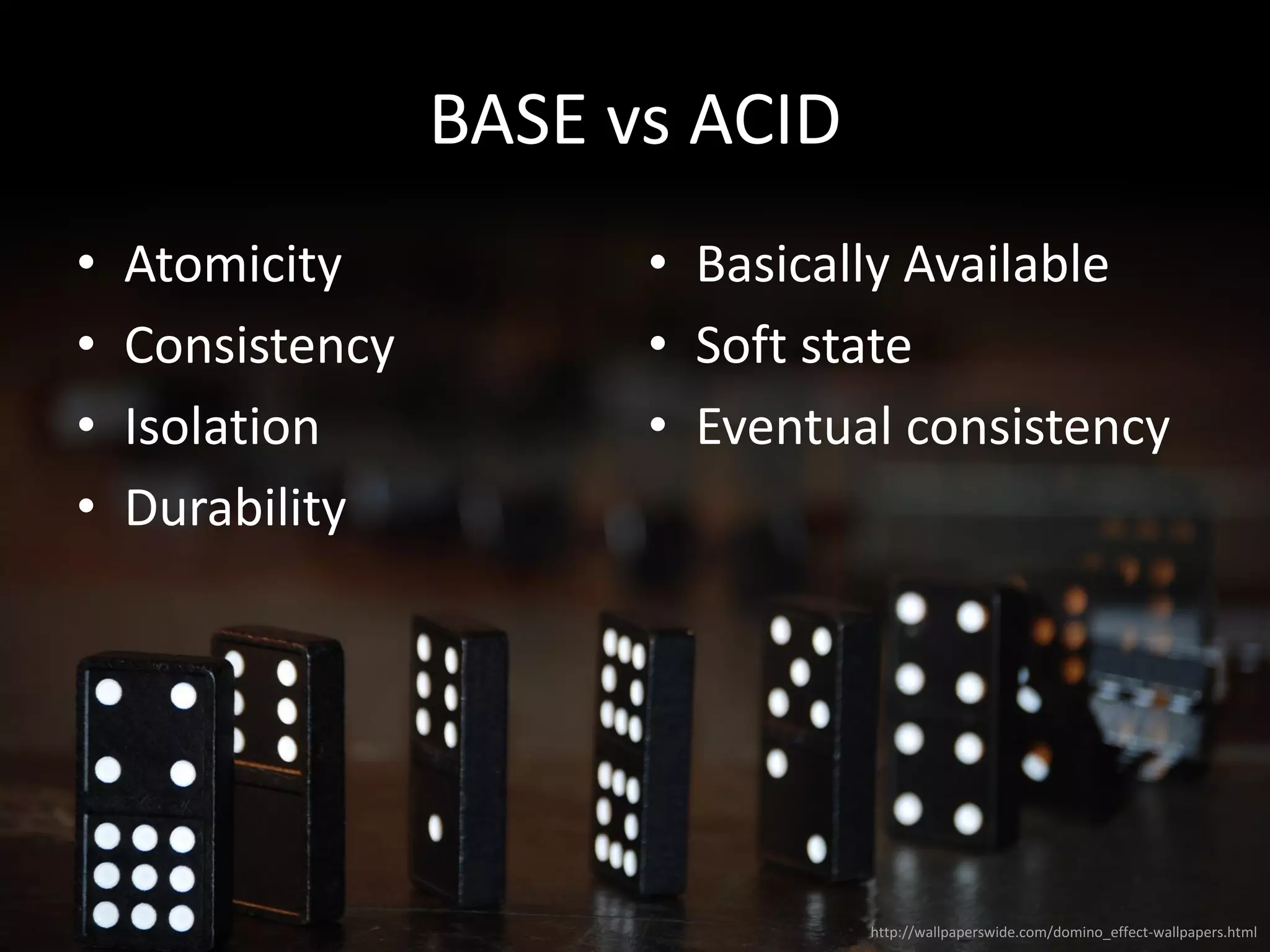








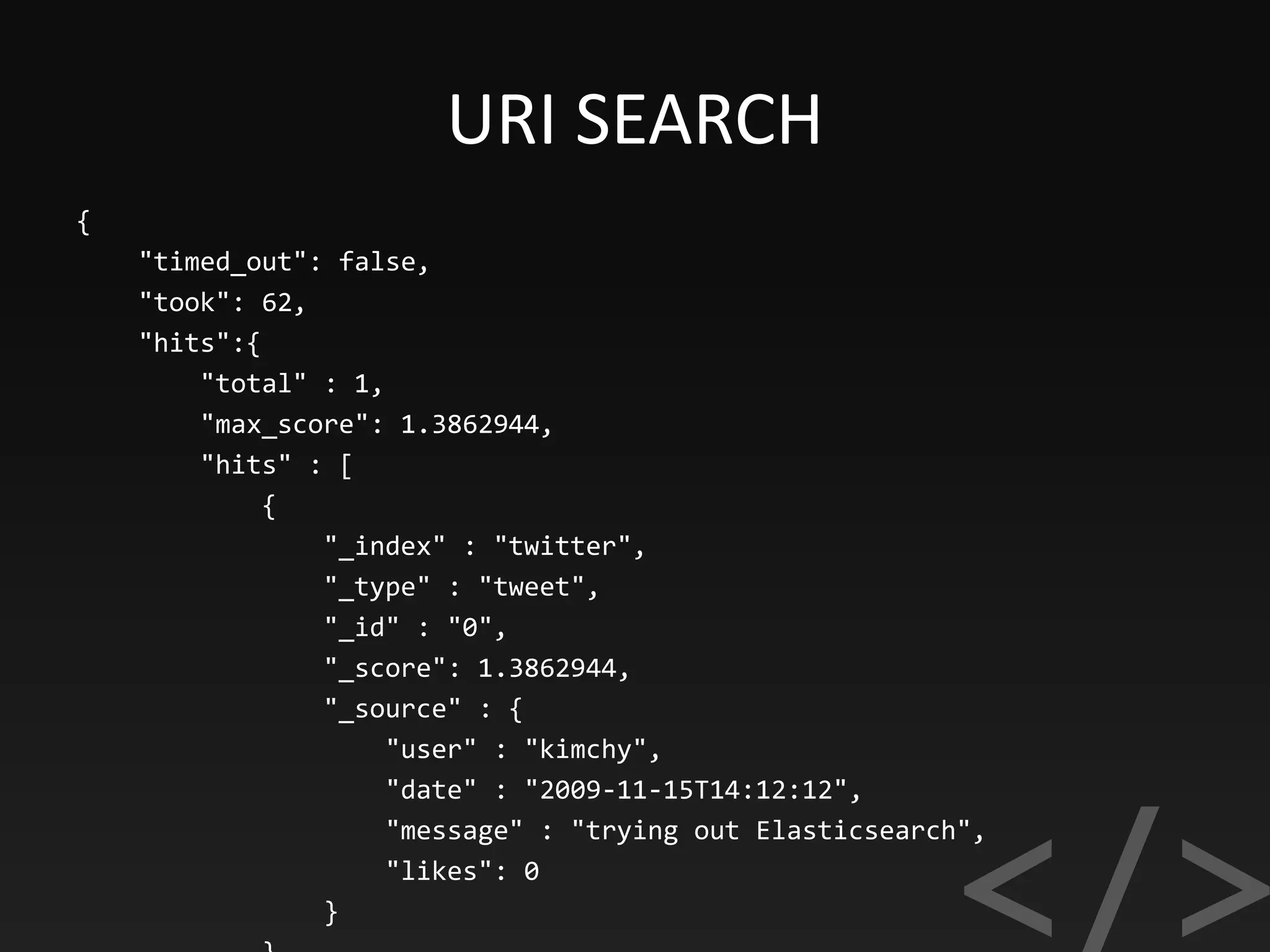
![CUSTOM ANALYSERS
PUT /index_name
{
"settings": {
"analysis": {
"analyzer": {
"polskie_slowa": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "stopwords_polska", "polish_stem", "asciifolding"],
"char_filter": ["html_strip"]
}
},
"filter": {
"stopwords_polska": {
"type": "stop",
"stopwords": ["a", "aby", ...]
}
}
}
}
// ...](https://image.slidesharecdn.com/elasticsearch-170918193359/75/Elasticsearch-SEARCH-ANALYZE-DATA-IN-REAL-TIME-17-2048.jpg)


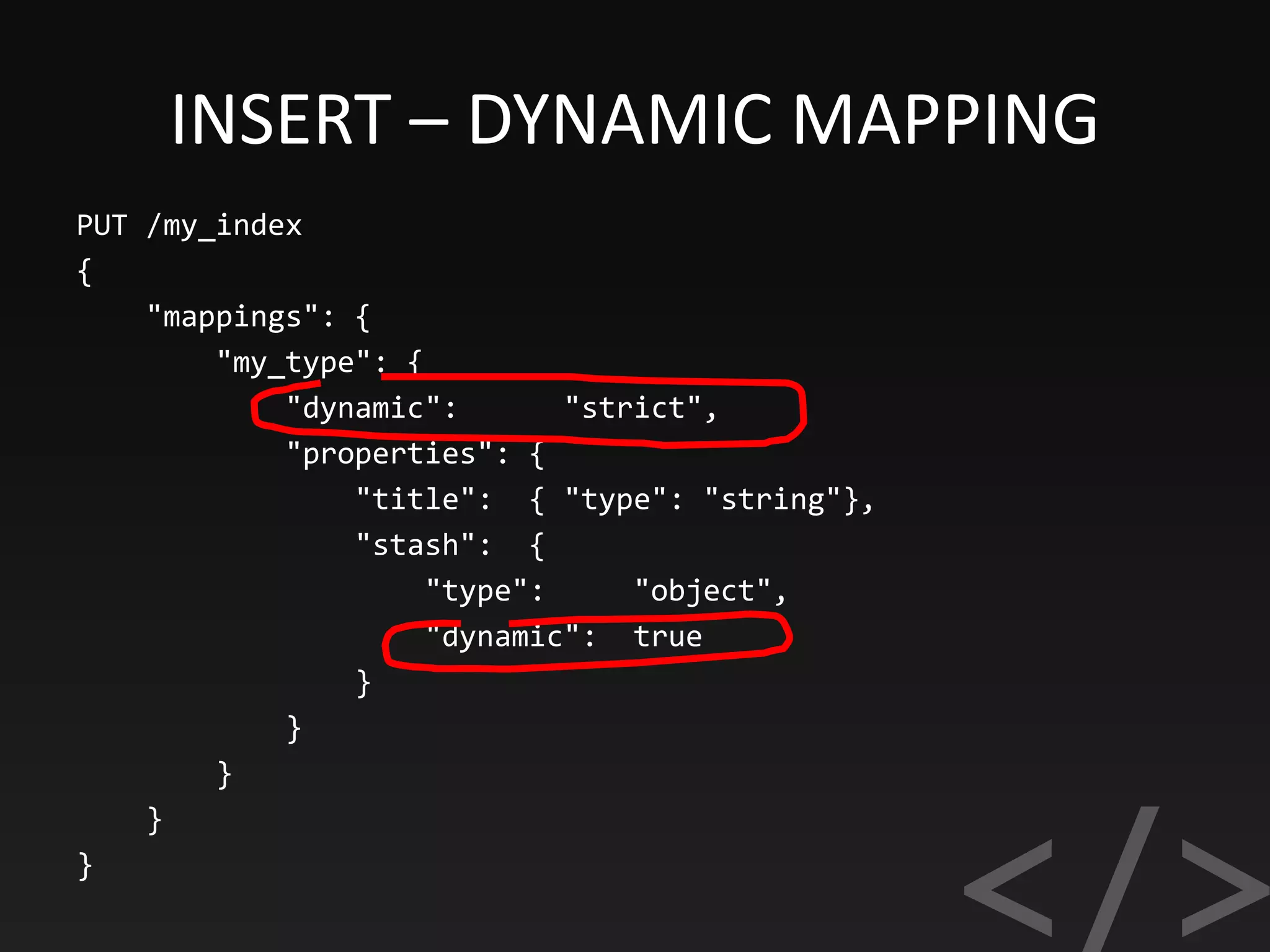







![TERM QUERY & BOOST
"query": {
"bool": {
"should" : [
{
"match": { "title": { "query": "myśliwy", "boost": 1 }
},
],
"filter": {
"and" : [
{
"term": {
"media.gallery_has": false
}
}
]
}](https://image.slidesharecdn.com/elasticsearch-170918193359/75/Elasticsearch-SEARCH-ANALYZE-DATA-IN-REAL-TIME-35-2048.jpg)
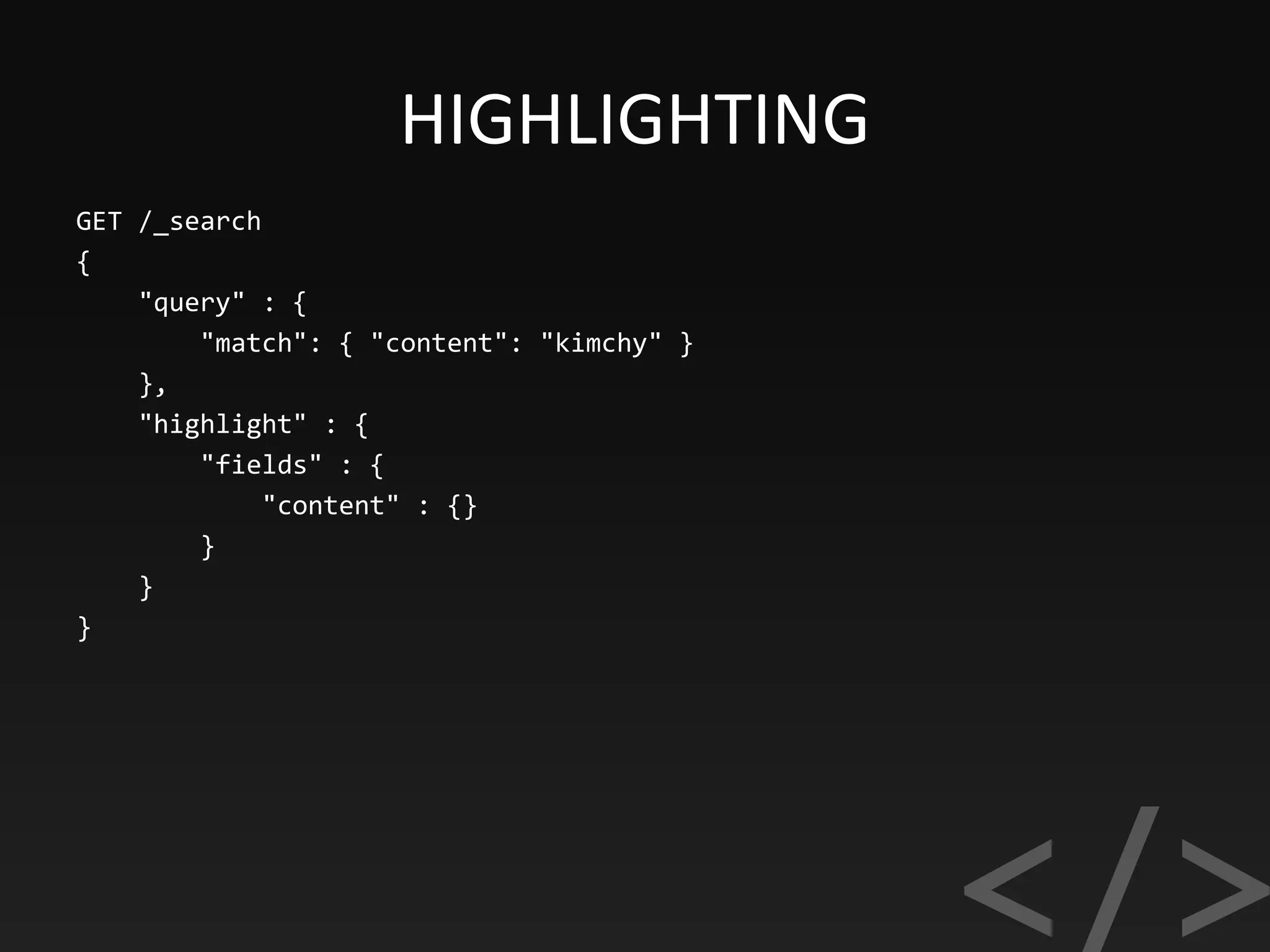

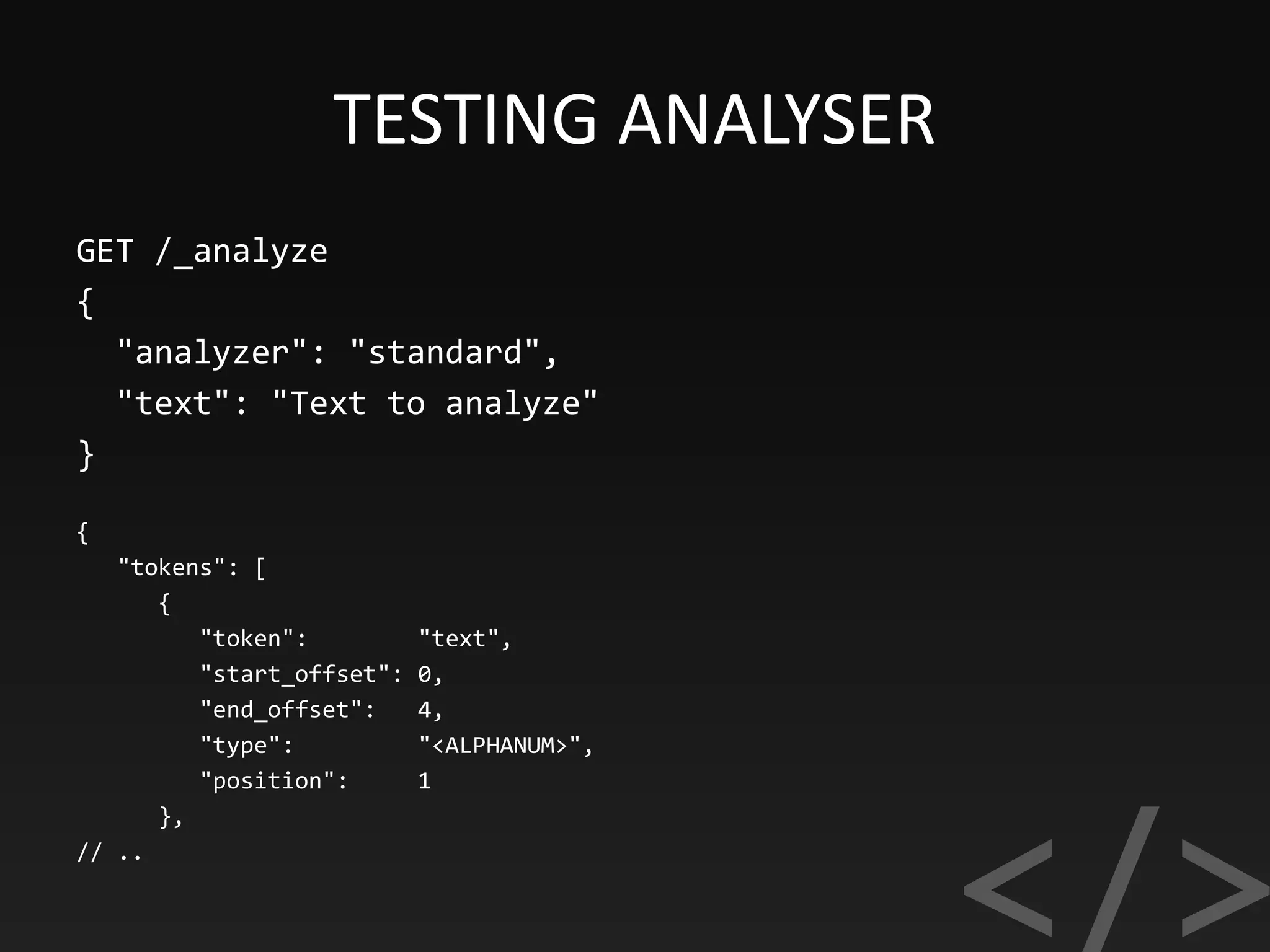
![SUGGESTING
"suggest": {
"song-suggest" : [ {
"text" : "nir",
"offset" : 0,
"length" : 3,
"options" : [ {
"text" : "Nirvana",
"_index": "music",
"_type": "song",
"_id": "1",
"_score": 1.0,
"_source": {
"suggest": ["Nevermind", "Nirvana"]
}
} ]](https://image.slidesharecdn.com/elasticsearch-170918193359/75/Elasticsearch-SEARCH-ANALYZE-DATA-IN-REAL-TIME-38-2048.jpg)





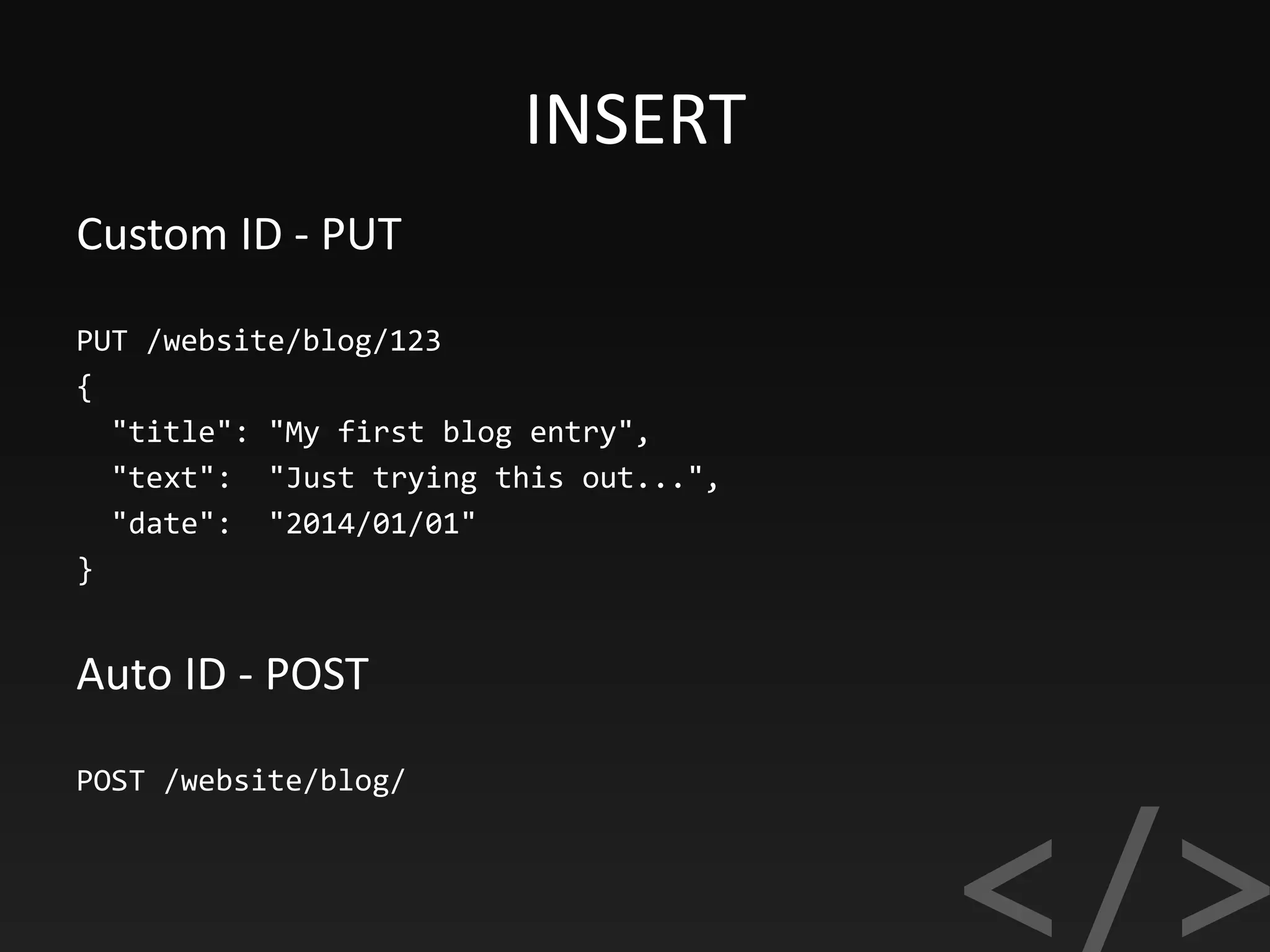
![Index Aliases and Zero Downtime
POST /_aliases
{
"actions" : [
{ "remove" : { "index" : "news_v1",
"alias" : "news_view" } },
{ "add" : { "index" : "news_v2",
"alias" : "news_view" } }
]
}
https://www.elastic.co/guide/en/
elasticsearch/guide/current/index-aliases.html](https://image.slidesharecdn.com/elasticsearch-170918193359/75/Elasticsearch-SEARCH-ANALYZE-DATA-IN-REAL-TIME-45-2048.jpg)




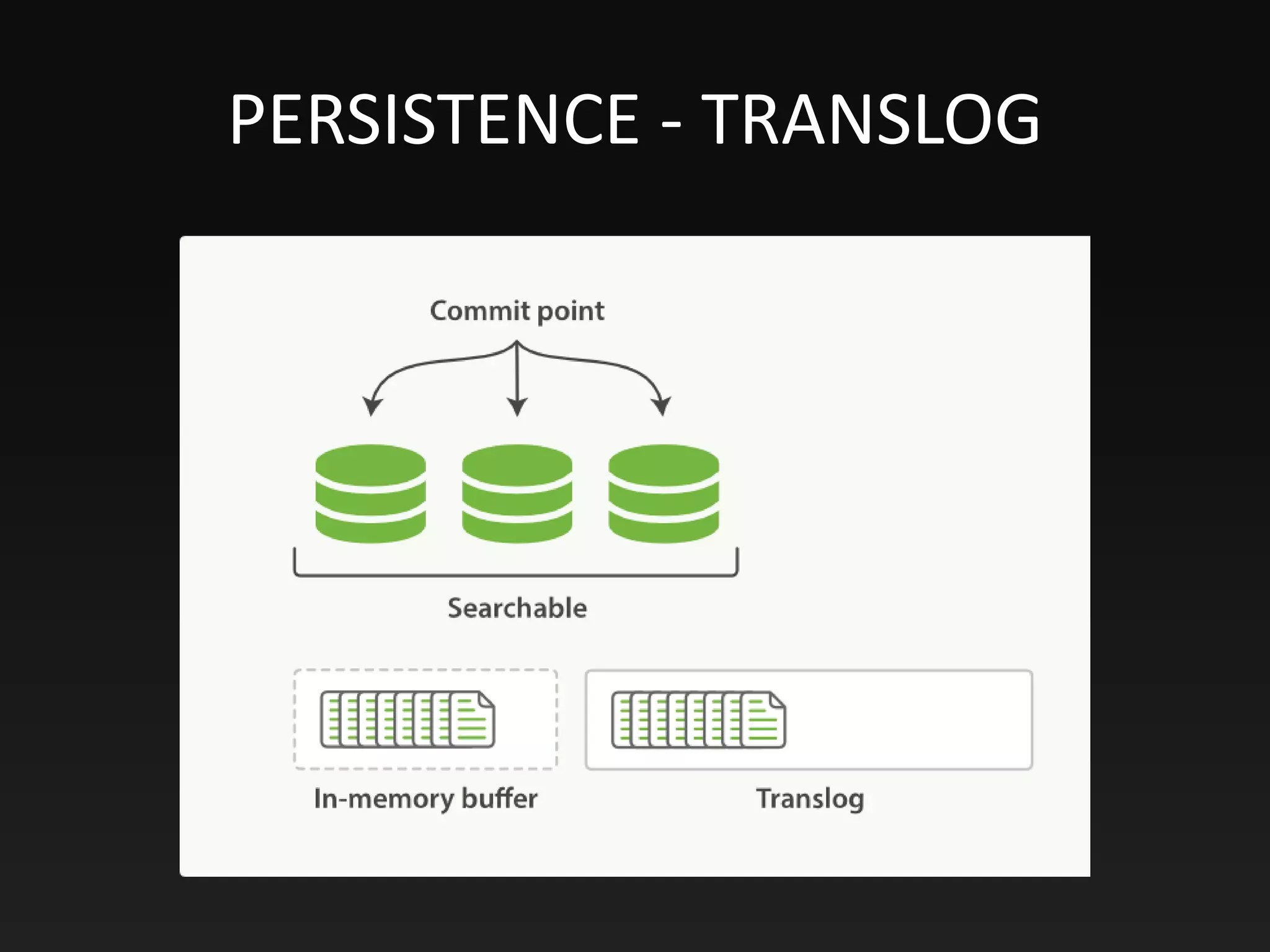




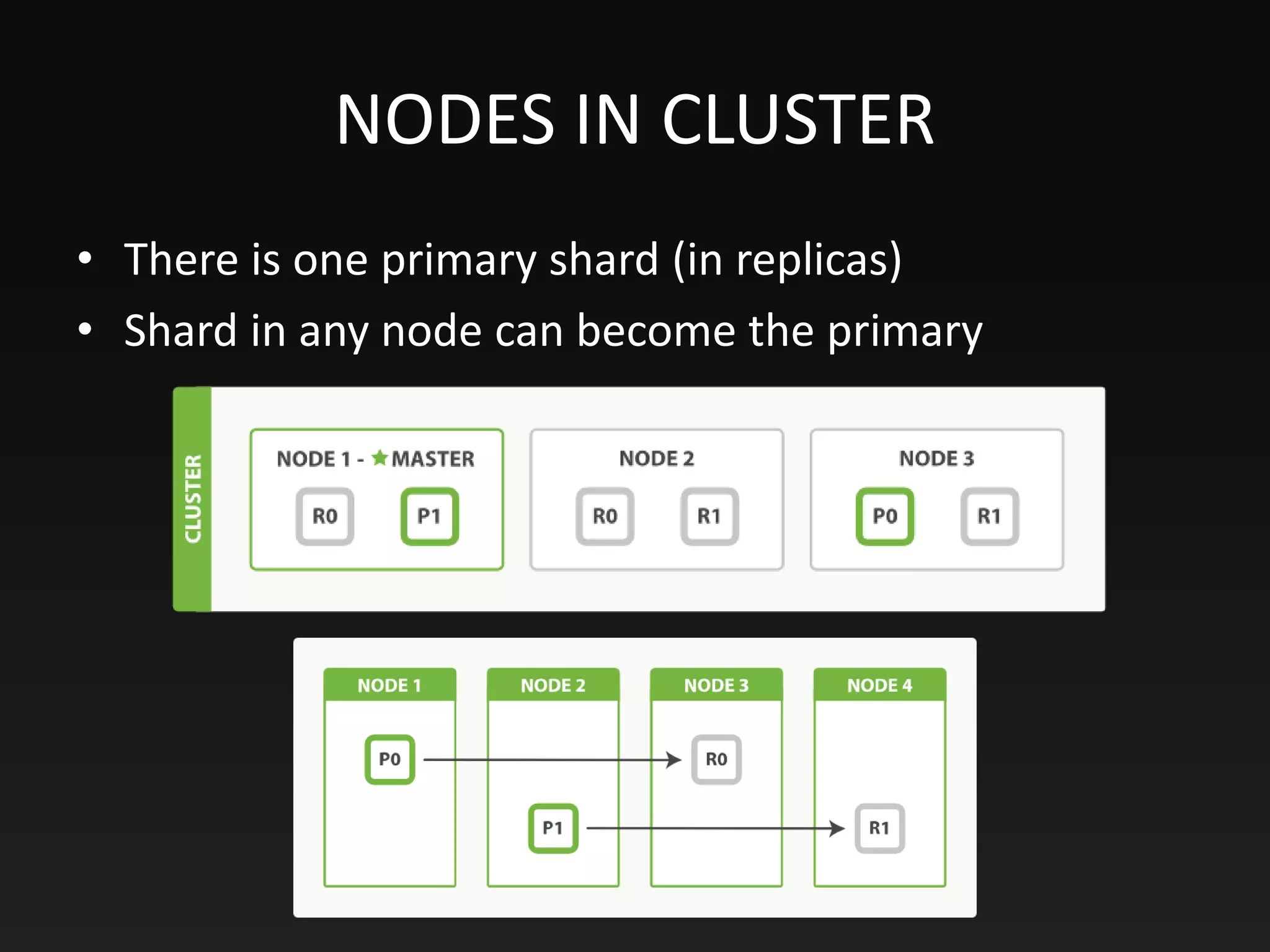
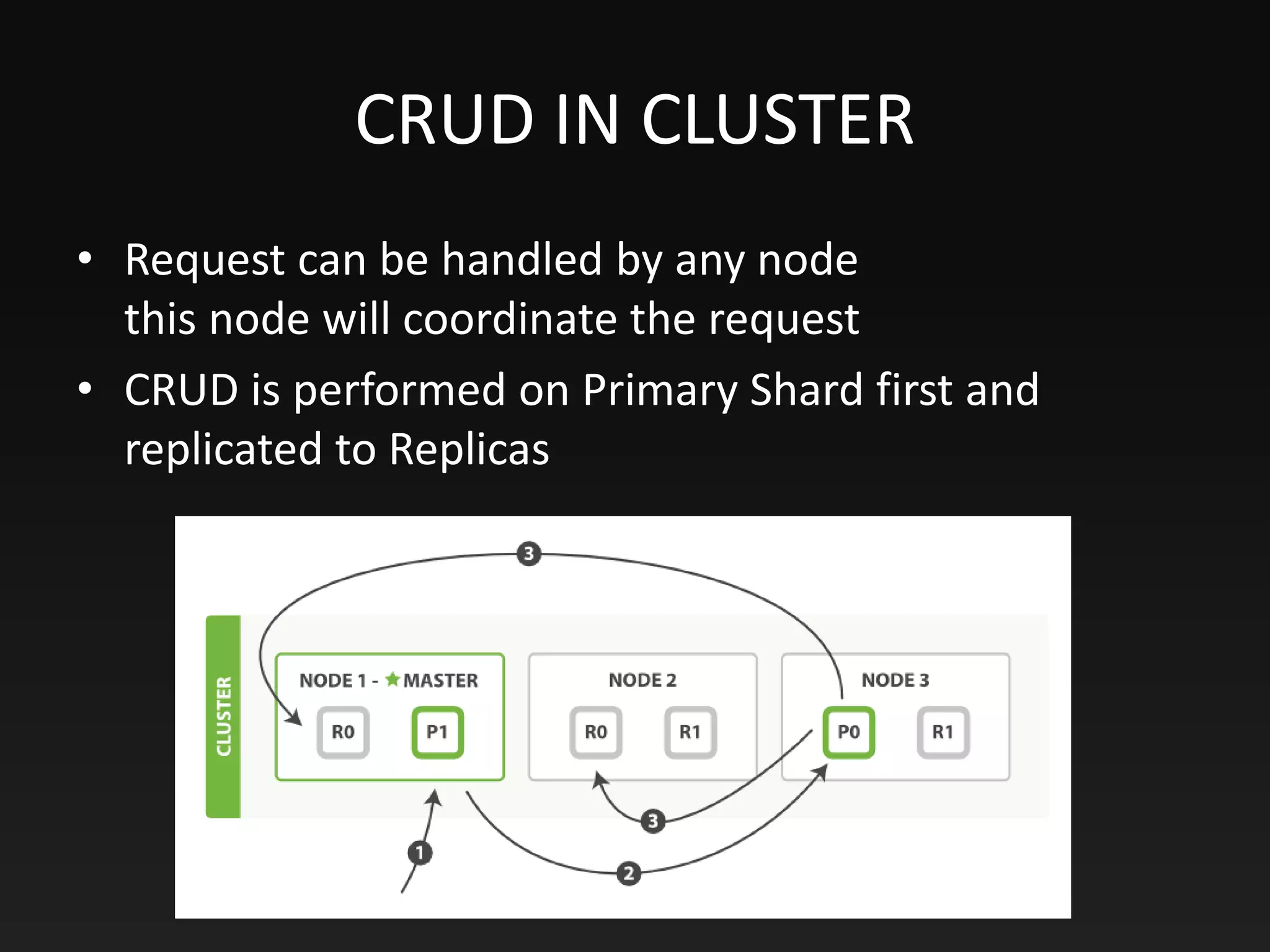

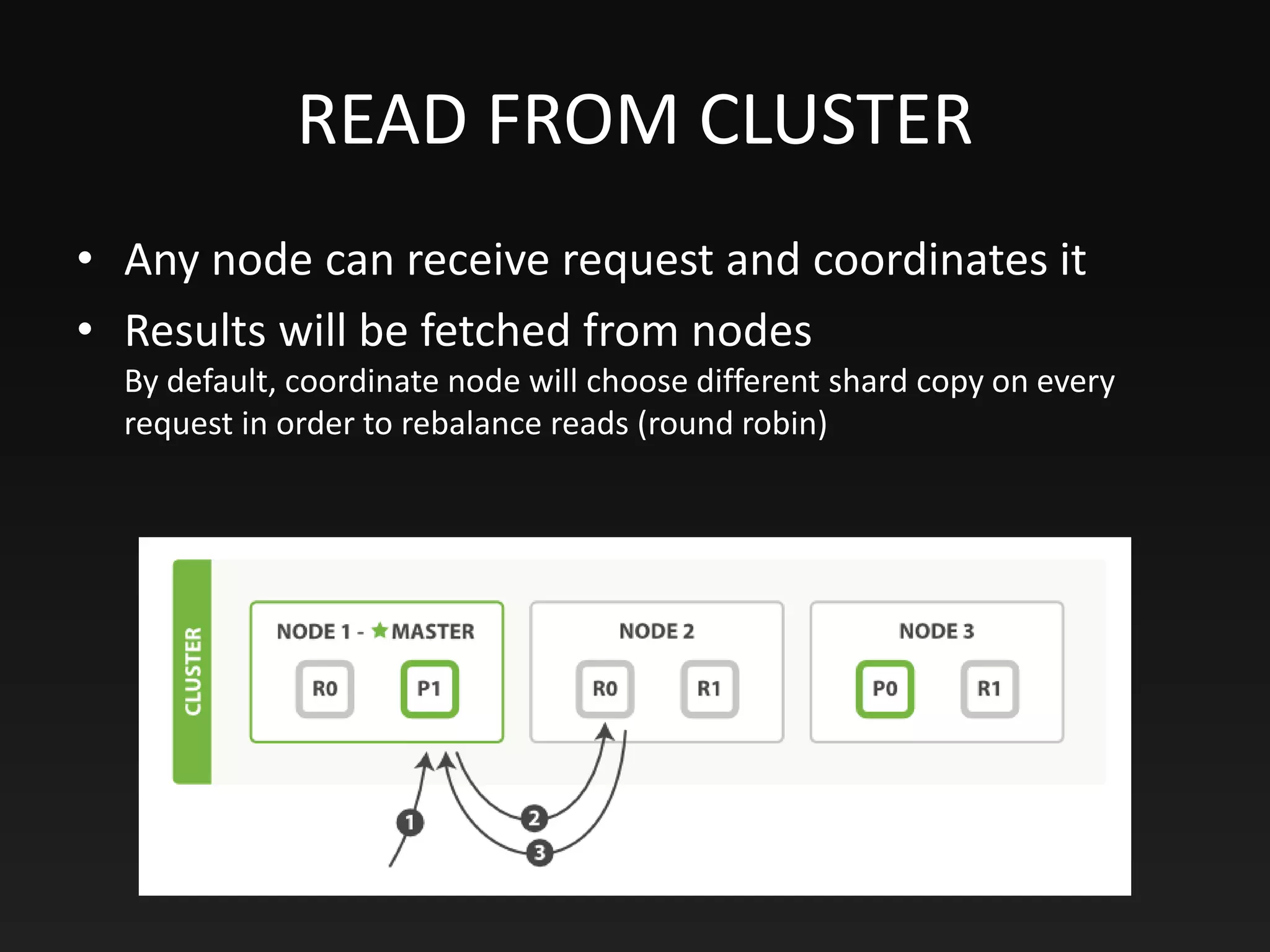

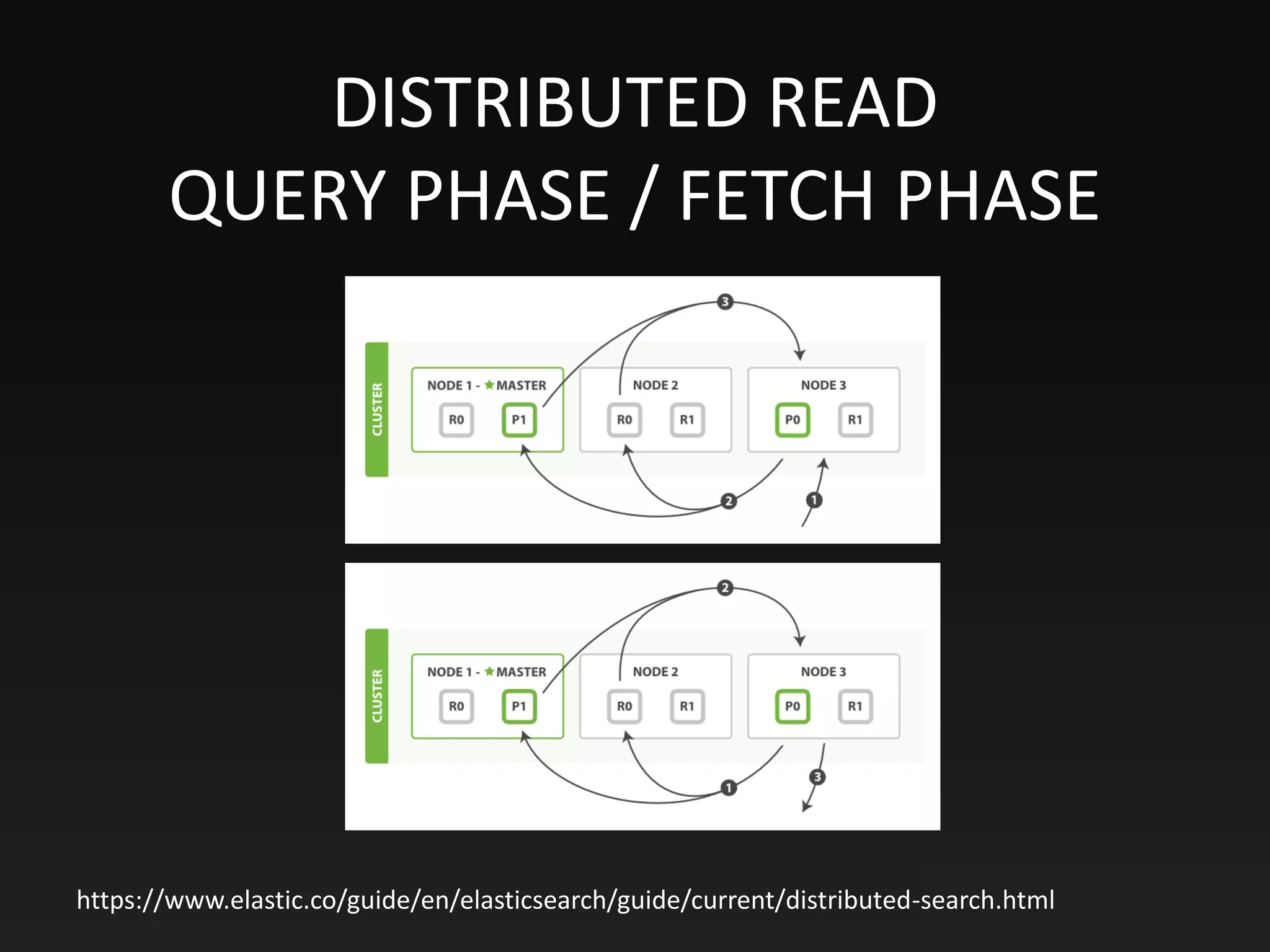







This document provides an overview of Elasticsearch, including its purpose, data storage and searching capabilities, features, architecture, and use cases. Elasticsearch is a NoSQL database that enables full-text search and analysis of data in real time. It stores data in documents that have a dynamic schema. Documents are indexed and searchable using Elasticsearch's full-text search functionality, which is powered by Apache Lucene. Elasticsearch can scale horizontally by sharding indexes across multiple nodes and vertically by replicating shards for high availability. It uses an inverted index and scoring algorithms like BM25 to rank search results.

















































![[BDD] Introduction to Behat (PL)](https://cdn.slidesharecdn.com/ss_thumbnails/behat-141216193109-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)


