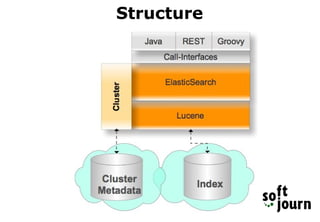
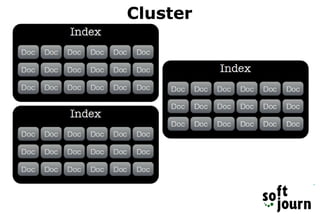
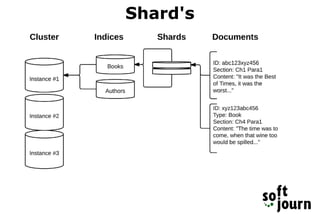
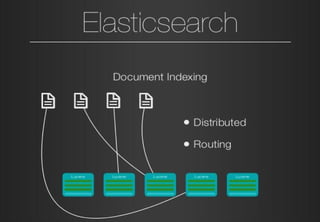
Elasticsearch is a search engine based on Apache Lucene that provides distributed, full-text search capabilities. It allows users to store and search documents of any structure in near real-time. Documents are organized into indexes, shards, and clusters to provide scalability and fault tolerance. Elasticsearch uses analysis and mapping to index documents for full-text search. Queries can be built using the Elasticsearch DSL for complex searches. While Elasticsearch provides fast search, it has disadvantages for transactional operations or large document churn. Elastic HQ is a web plugin that provides monitoring and management of Elasticsearch clusters through a browser-based interface.
















![Phrase: "What's new in Ivano-Frankivsk?"
Standard: [{what's}, {new}, {in}, {ivano}, {frankivsk}]
Simple: [{what}, {s}, {new}, {in}, {ivano}, {frankivsk}]
WhiteSpace: [{What's}, {new}, {in}, {Ivano-Frankivsk?}]
English: [{what}, {new}, {in}, {ivano}, {frankivsk}]](https://image.slidesharecdn.com/elasticsearch-presentation-160818163343/85/ElasticSearch-20-320.jpg)



![Dynamic templates example
"dynamic_templates": [ {
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "string",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed",
"ignore_above": 256
}}}}}]](https://image.slidesharecdn.com/elasticsearch-presentation-160818163343/85/ElasticSearch-24-320.jpg)

![Query example
{ "from" : 0,
"size" : 10,
"query" : {
"bool" : {
"must" : {
"multi_match" : {
"query" : "Some word",
"fields" : [ "Id",
"phone1", "title", "user" ],
"minimum_should_match" :
"100%"
}},
"filter" : [ {
"multi_match" : {
"query" : "Some report",
"fields" : [ "document
type" ],
"type" : "phrase",
"minimum_should_match" :
"100%"
}},
{ "terms" : {
"user" : [
"user1234@yudu.com", "user2@mail.com",
"user4321@mail.com" ]}
}, {"terms" : {
"id" : [ "123456789",
"123456", "3011163" ]
}} ],
"minimum_should_match" : "1"
}
},
"sort" : [ {
"id.raw" : {
"order" : "desc"
}}, {
"phone1.raw" : {
"order" : "desc"
}}, {
"title.raw" : {
"order" : "desc"
}}, {
"user" : {
"order" : "asc"
}}, {
"type.raw" : {
"order" : "desc"
}
} ]
}](https://image.slidesharecdn.com/elasticsearch-presentation-160818163343/85/ElasticSearch-27-320.jpg)

![Document's metadata
{
"took": 49,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "out-source",
"_type": "companies",
"_id": "AVX-nPLNu3mBekLrnXXZ",
"_score": 1,
"_source": {
"name": "Softjourn",
"fullName": "Softjourn Inc."
}}
]
}}](https://image.slidesharecdn.com/elasticsearch-presentation-160818163343/85/ElasticSearch-29-320.jpg)



























































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)










