More Related Content

PDF

PPTX

PDF
最近のRのランダムフォレストパッケージ -ranger/Rborist- 
PDF
なぜベイズ統計はリスク分析に向いているのか? その哲学上および実用上の理由 
PPTX

PDF
R言語による アソシエーション分析-組合せ・事象の規則を解明する-(第5回R勉強会@東京) 
PDF

PPTX
What's hot

PDF

PDF

PDF
勉強か?趣味か?人生か?―プログラミングコンテストとは 
PDF

PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章 
DOCX

PDF

PPTX

PPTX

PDF

PPTX

PDF
「R言語による Random Forest 徹底入門 -集団学習による分類・予測-」 - #TokyoR #11 
PDF
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた 
PDF
Rにおける大規模データ解析(第10回TokyoWebMining) 
KEY

PDF

PDF

PDF

PDF

PDF
Viewers also liked

PPTX
巨大な表を高速に扱うData.table について 
PDF
VLDB2013 Session 1 Emerging Hardware 
PDF
ICDE2015 Research 3: Distributed Storage and Processing 
PDF
ICDE2014 Session 14 Data Warehousing 
PDF
「数字を見せろ」から「コードを見せろ」へ 〜過程の透明性を確保したデータ可視化を目指す〜 
PPTX
遅延価値観数と階層ベイズを用いた男心をくすぐる女の戦略.R 
PDF

PDF
Similar to data.tableパッケージで大規模データをサクッと処理する

PDF

PPTX

PPTX

PDF
2017年3月版データマエショリスト入門(誤植修正版) 
PDF

PDF

PDF
第8回 大規模データを用いたデータフレーム操作実習(2) 
PDF
第9回 大規模データを用いたデータフレーム操作実習(3) 
PDF

PDF

PDF

PDF
Sendai r01 beginnerssession1 
PDF

PDF
R言語で始めよう、データサイエンス(ハンズオン勉強会) 〜機会学習・データビジュアライゼーション事始め〜 
PDF

PDF

PDF

PDF
R入門(dplyrでデータ加工)-TokyoR42 
PPTX

PDF
More from Shintaro Fukushima

PDF
20230216_Python機械学習プログラミング.pdf 
PDF

PDF
Materials Informatics and Python 
PDF

PDF
Why dont you_create_new_spark_jl 
PDF

PDF

PDF

PDF

PDF
アクションマイニングを用いた最適なアクションの導出 
PDF

PDF

PDF

PDF
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用 
PDF

PDF

PDF

PDF

PDF

PDF
data.tableパッケージで大規模データをサクッと処理する
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
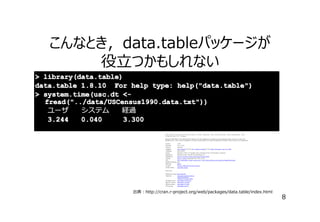
そんなデータフレームも,
結構処理が遅いことがある
> # データの読み込み
>system.time(usc.df <read.csv("../data/USCensus1990.data.txt"))
ユーザ
システム
経過
65.588 3.152
68.868
⽶国の1990年の国勢調査データ
出典:US Census(1990) Data Set
http://archive.ics.uci.edu/ml/datasets/US
+Census+Data+%281990%29
7
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
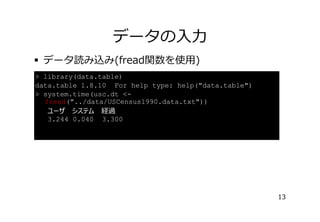
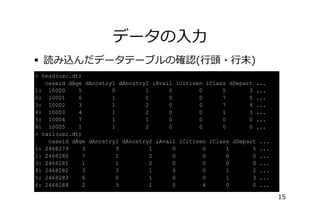
データの⼊⼒
� 読み込んだデータテーブルの確認(⾏頭・⾏末)
> head(usc.dt)
caseiddAge dAncstry1 dAncstry2 iAvail iCitizen iClass dDepart ...
1: 10000
5
0
1
0
0
5
3 ...
2: 10001
6
1
1
0
0
7
5 ...
3: 10002
3
1
2
0
0
7
4 ...
4: 10003
4
1
2
0
0
1
3 ...
5: 10004
7
1
1
0
0
0
0 ...
6: 10005
1
1
2
0
0
0
0 ...
> tail(usc.dt)
caseid dAge dAncstry1 dAncstry2 iAvail iCitizen iClass dDepart ...
1: 2468279
3
3
1
0
0
1
5 ...
2: 2468280
7
1
2
0
0
0
0 ...
3: 2468281
1
1
2
0
0
0
0 ...
4: 2468282
3
3
1
0
0
1
2 ...
5: 2468283
6
0
1
0
0
1
3 ...
6: 2468284
2
3
1
0
4
0
0 ...
15
- 17.
データの⼊⼒
� 読み込んだデータテーブルの確認(サイズ,表頭・表側)
> dim(usc.dt)
[1]2458285
69
> dimnames(usc.dt)
[[1]]
NULL
[[2]]
[1] "caseid"
[7] "iClass"
[13] "iFertil"
[19] "dIncome2"
[25] "dIncome8"
[31] "iMay75880"
[37] "iOthrserv"
[43] "dRearning"
[49] "iRownchld"
[55] "iSchool"
[61] "dTravtime"
[67] "iYearsch"
"dAge"
"dDepart"
"dHispanic"
"dIncome3"
"dIndustry"
"iMeans"
"iPerscare"
"iRelat1"
"dRpincome"
"iSept80"
"iVietnam"
"iYearwrk"
表側はつかない
"dAncstry1"
"iDisabl1"
"dHour89"
"dIncome4"
"iKorean"
"iMilitary"
"dPOB"
"iRelat2"
"iRPOB"
"iSex"
"dWeek89"
"dYrsserv"
"dAncstry2"
"iDisabl2"
"dHours"
"dIncome5"
"iLang1"
"iMobility"
"dPoverty"
"iRemplpar"
"iRrelchld"
"iSubfam1"
"iWork89"
"iAvail"
"iEnglish"
"iImmigr"
"dIncome6"
"iLooking"
"iMobillim"
"dPwgt1"
"iRiders"
"iRspouse"
"iSubfam2"
"iWorklwk"
"iCitizen"
"iFeb55"
"dIncome1"
"dIncome7"
"iMarital"
"dOccup"
"iRagechld"
"iRlabor"
"iRvetserv"
"iTmpabsnt"
"iWWII"
16
- 18.
データの⼊⼒
� メモリ上に⽣成されたデータテーブルのリストの確認
オブジェクト名
> tables()
NAME
NROWMB
[1,] usc.dt 2,458,285 648
⾏数
COLS
[1,]
caseid,dAge,dAncstry1,dAncstry2,iAvail,iCitizen,iClass,
dDepart,iDisabl1,iDisabl2
KEY
[1,]
表側(の⼀部)
Total: 648MB
17
- 19.
- 20.
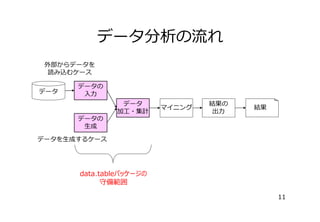
データ加⼯・集計
� キーの付加(setkey関数)
# キーの付加(dAge,dIncome1 をキーにする)
setkey(usc.dt, dAge, dIncome1)
# オブジェクトのリストの中にもキーが表⽰されている
tables()
NAME
NROW MB
[1,] usc.dt 2,458,285 648
COLS
[1,]
caseid,dAge,dAncstry1,dAncstry2,iAvail,iCitizen,iClass,
dDepart,iDisabl1,iDisabl2
KEY
キーが付加された
[1,] dAge,dIncome1
Total: 648MB
>
>
>
>
19
- 21.
データ加⼯・集計
� バイナリサーチを⽤いた⾼速な要素抽出
> #2つのキーの値によりデータの要素へのアクセスが可能
> system.time(x <- usc.dt[1, 1])
ユーザ
システム
経過
0.000
0.000
0.001
dAge=1 かつ
dIncome1=1の
⾏の取得
> # ⽐較: 通常のデータフレームを⽤いた場合
> system.time(y <- usc.df[usc.df$dAge==1 &
usc.df$dIncome1==1, ])
ユーザ
システム
経過
1.536
0.096
1.637
20
- 22.
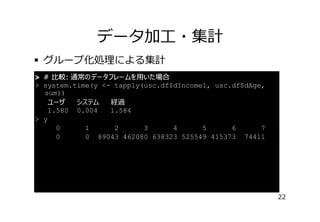
データ加⼯・集計
� グループ化処理による集計
> #キーの値ごとの層別集計
> system.time(x <- usc.dt[, sum(dIncome1), by=dAge])
ユーザ
システム
経過
0.032
0.000
0.033
> x
第2引数には集計処理を,
dAge
V1
by引数には集計軸を指定
1:
0
0
2:
1
0
3:
2 89043
4:
3 462080
5:
4 638323
6:
5 525549
7:
6 415373
8:
7 74411
21
- 23.
データ加⼯・集計
� グループ化処理による集計
> #⽐較: 通常のデータフレームを⽤いた場合
> system.time(y <- tapply(usc.df$dIncome1, usc.df$dAge,
sum))
ユーザ
システム
経過
1.580 0.004
1.584
> y
0
1
2
3
4
5
6
7
0
0 89043 462080 638323 525549 415373 74411
22
- 24.
- 25.
- 26.
- 27.











![各⼯程の処理例とdata.tableの関数
⼯程
データの⼊⼒・変換
処理
データの読み込み
data.tableの関数
�fread
通常のRの関数
�read.csv/read.table
�scan 等
データフレームからのデータ
変換
データの加⼯・集計
�data.table
キーの付加
�setkey
--
グループ化の処理
�添字表記[[]], by引数
--
テーブルのジョイン
�merge
�merge
複数のリストの結合
�rbindlst
�do.call("rbind", リスト)
--
�do.call("cbind", リスト)
部分集合の取り出し
�subset
�subset
⾏の重複のチェック
�duplicated
�duplicated
※data.tableパッケージについては,
他にも様々な関数がある
12](https://image.slidesharecdn.com/data-131109003726-phpapp02/85/data-table-13-320.jpg)

![データの⼊⼒
� 読み込んだデータテーブルの確認(サイズ,表頭・表側)
> dim(usc.dt)
[1] 2458285
69
> dimnames(usc.dt)
[[1]]
NULL
[[2]]
[1] "caseid"
[7] "iClass"
[13] "iFertil"
[19] "dIncome2"
[25] "dIncome8"
[31] "iMay75880"
[37] "iOthrserv"
[43] "dRearning"
[49] "iRownchld"
[55] "iSchool"
[61] "dTravtime"
[67] "iYearsch"
"dAge"
"dDepart"
"dHispanic"
"dIncome3"
"dIndustry"
"iMeans"
"iPerscare"
"iRelat1"
"dRpincome"
"iSept80"
"iVietnam"
"iYearwrk"
表側はつかない
"dAncstry1"
"iDisabl1"
"dHour89"
"dIncome4"
"iKorean"
"iMilitary"
"dPOB"
"iRelat2"
"iRPOB"
"iSex"
"dWeek89"
"dYrsserv"
"dAncstry2"
"iDisabl2"
"dHours"
"dIncome5"
"iLang1"
"iMobility"
"dPoverty"
"iRemplpar"
"iRrelchld"
"iSubfam1"
"iWork89"
"iAvail"
"iEnglish"
"iImmigr"
"dIncome6"
"iLooking"
"iMobillim"
"dPwgt1"
"iRiders"
"iRspouse"
"iSubfam2"
"iWorklwk"
"iCitizen"
"iFeb55"
"dIncome1"
"dIncome7"
"iMarital"
"dOccup"
"iRagechld"
"iRlabor"
"iRvetserv"
"iTmpabsnt"
"iWWII"
16](https://image.slidesharecdn.com/data-131109003726-phpapp02/85/data-table-17-320.jpg)
![データの⼊⼒
� メモリ上に⽣成されたデータテーブルのリストの確認
オブジェクト名
> tables()
NAME
NROW MB
[1,] usc.dt 2,458,285 648
⾏数
COLS
[1,]
caseid,dAge,dAncstry1,dAncstry2,iAvail,iCitizen,iClass,
dDepart,iDisabl1,iDisabl2
KEY
[1,]
表側(の⼀部)
Total: 648MB
17](https://image.slidesharecdn.com/data-131109003726-phpapp02/85/data-table-18-320.jpg)

![データ加⼯・集計
� キーの付加(setkey関数)
# キーの付加(dAge, dIncome1 をキーにする)
setkey(usc.dt, dAge, dIncome1)
# オブジェクトのリストの中にもキーが表⽰されている
tables()
NAME
NROW MB
[1,] usc.dt 2,458,285 648
COLS
[1,]
caseid,dAge,dAncstry1,dAncstry2,iAvail,iCitizen,iClass,
dDepart,iDisabl1,iDisabl2
KEY
キーが付加された
[1,] dAge,dIncome1
Total: 648MB
>
>
>
>
19](https://image.slidesharecdn.com/data-131109003726-phpapp02/85/data-table-20-320.jpg)
![データ加⼯・集計
� バイナリサーチを⽤いた⾼速な要素抽出
> # 2つのキーの値によりデータの要素へのアクセスが可能
> system.time(x <- usc.dt[1, 1])
ユーザ
システム
経過
0.000
0.000
0.001
dAge=1 かつ
dIncome1=1の
⾏の取得
> # ⽐較: 通常のデータフレームを⽤いた場合
> system.time(y <- usc.df[usc.df$dAge==1 &
usc.df$dIncome1==1, ])
ユーザ
システム
経過
1.536
0.096
1.637
20](https://image.slidesharecdn.com/data-131109003726-phpapp02/85/data-table-21-320.jpg)
![データ加⼯・集計
� グループ化処理による集計
> # キーの値ごとの層別集計
> system.time(x <- usc.dt[, sum(dIncome1), by=dAge])
ユーザ
システム
経過
0.032
0.000
0.033
> x
第2引数には集計処理を,
dAge
V1
by引数には集計軸を指定
1:
0
0
2:
1
0
3:
2 89043
4:
3 462080
5:
4 638323
6:
5 525549
7:
6 415373
8:
7 74411
21](https://image.slidesharecdn.com/data-131109003726-phpapp02/85/data-table-22-320.jpg)