Downloaded 109 times










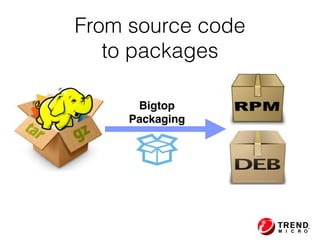



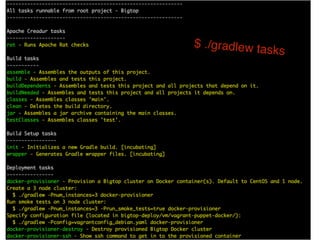
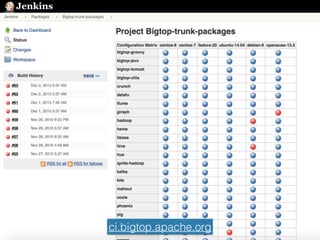


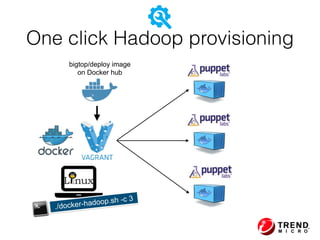
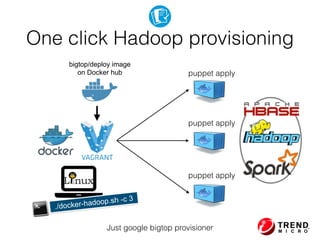









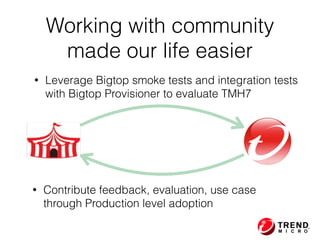


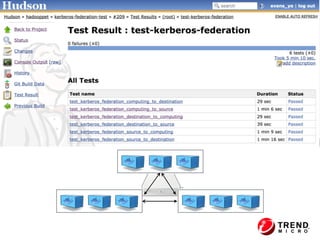

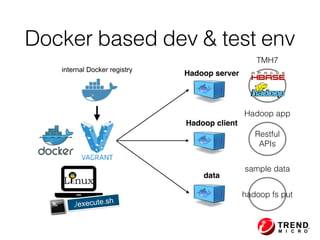
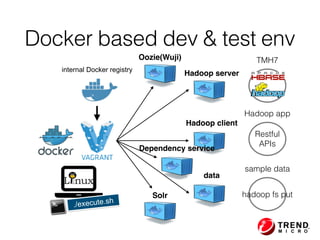



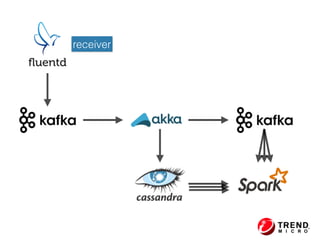
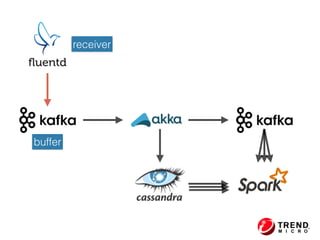
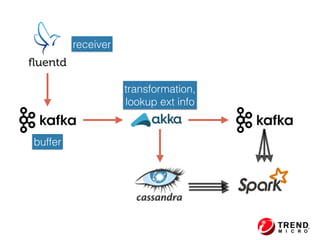
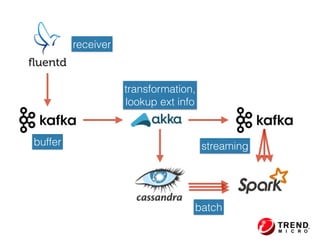
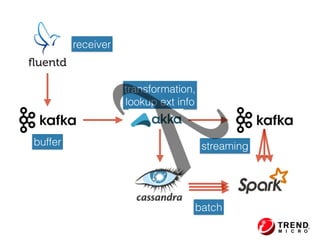


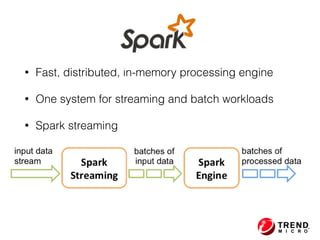


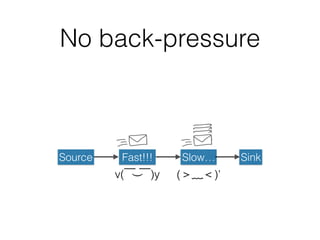
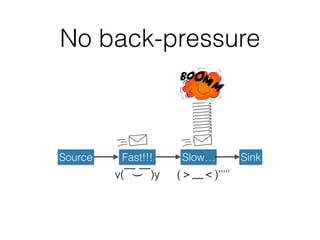
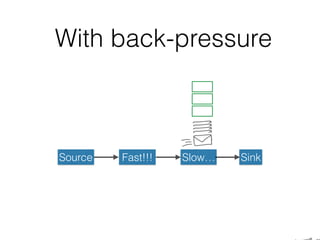
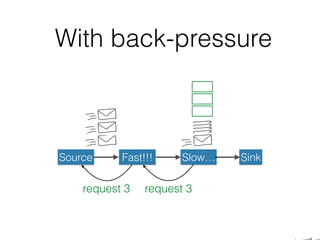
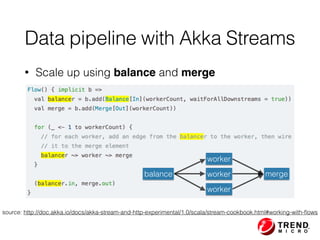
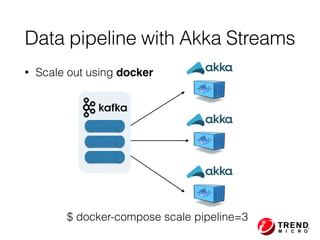












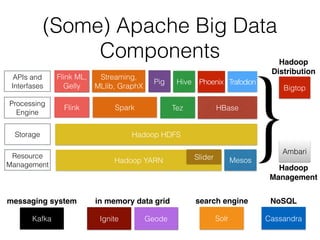










The document presents insights from Evans Ye at the 2015 Big Data Conference, covering the Trend Micro Big Data Platform and Apache Bigtop. It discusses the advantages of using Bigtop for building custom big data stacks, its features for deployment and testing, and the integration of various technologies like Hadoop, Spark, and Kafka. Additionally, it outlines the evolving big data landscape and future trends, including in-memory computing solutions and Bigtop's roadmap for upcoming releases.










































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)










