Downloaded 33 times

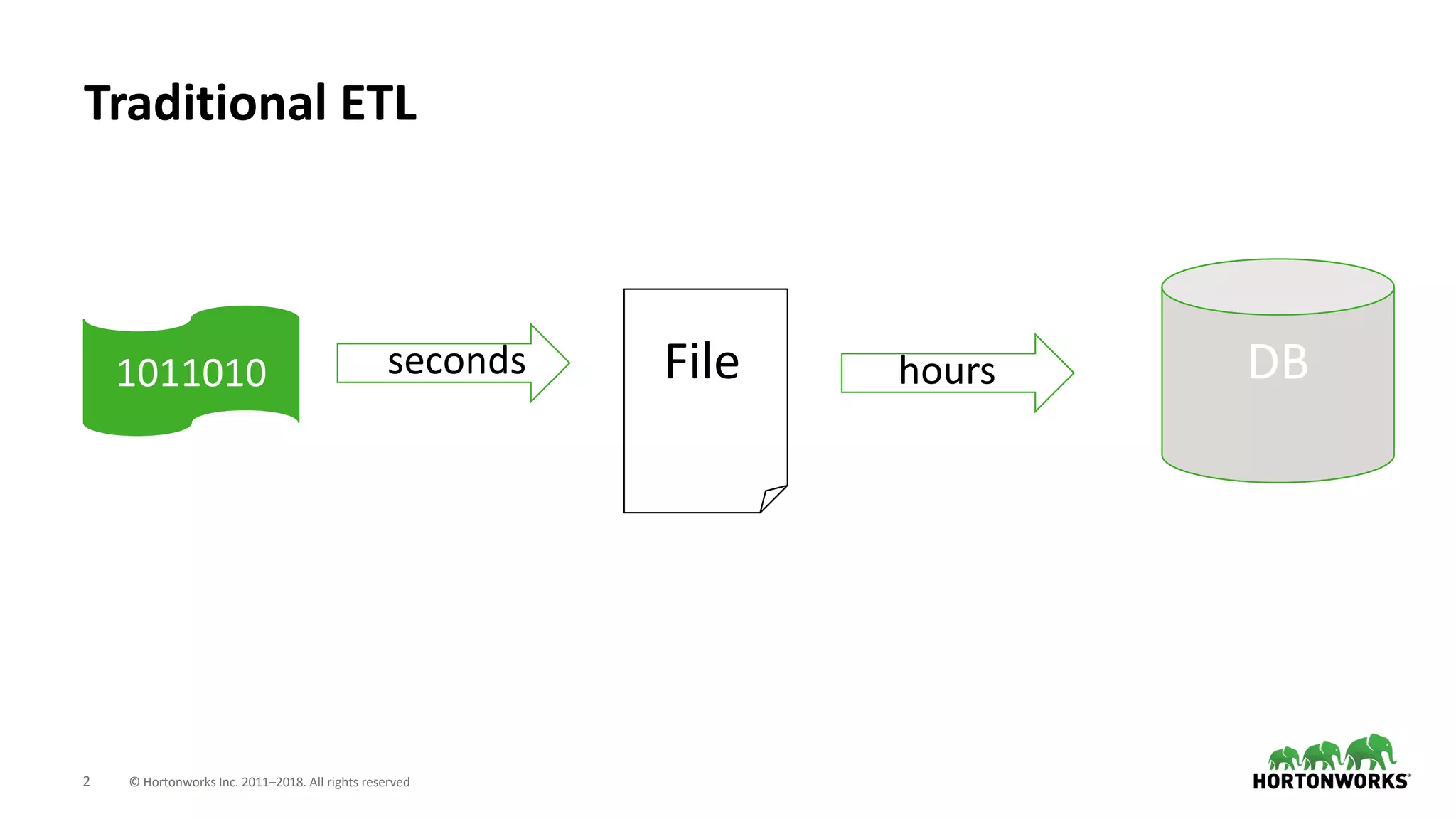
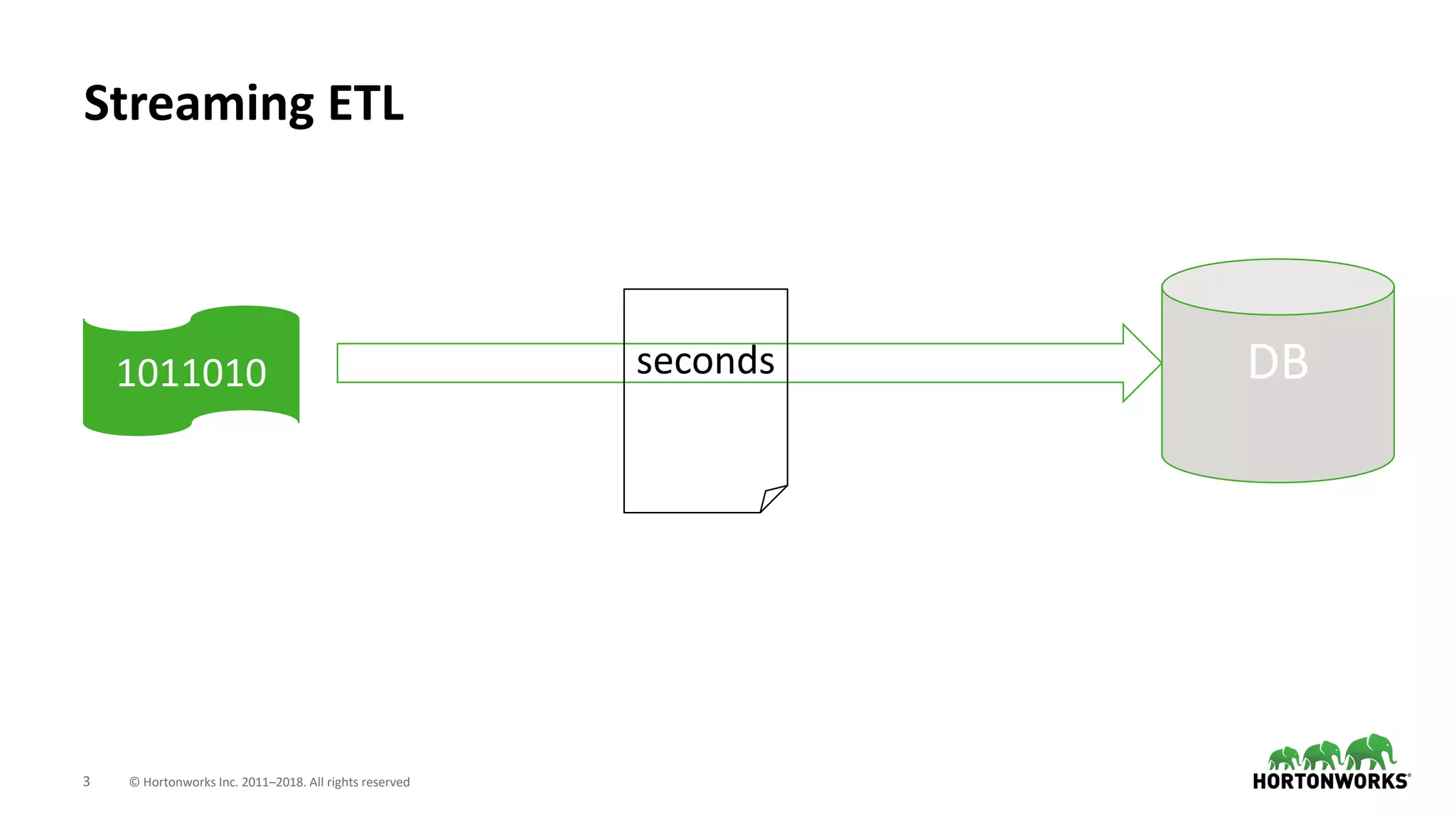
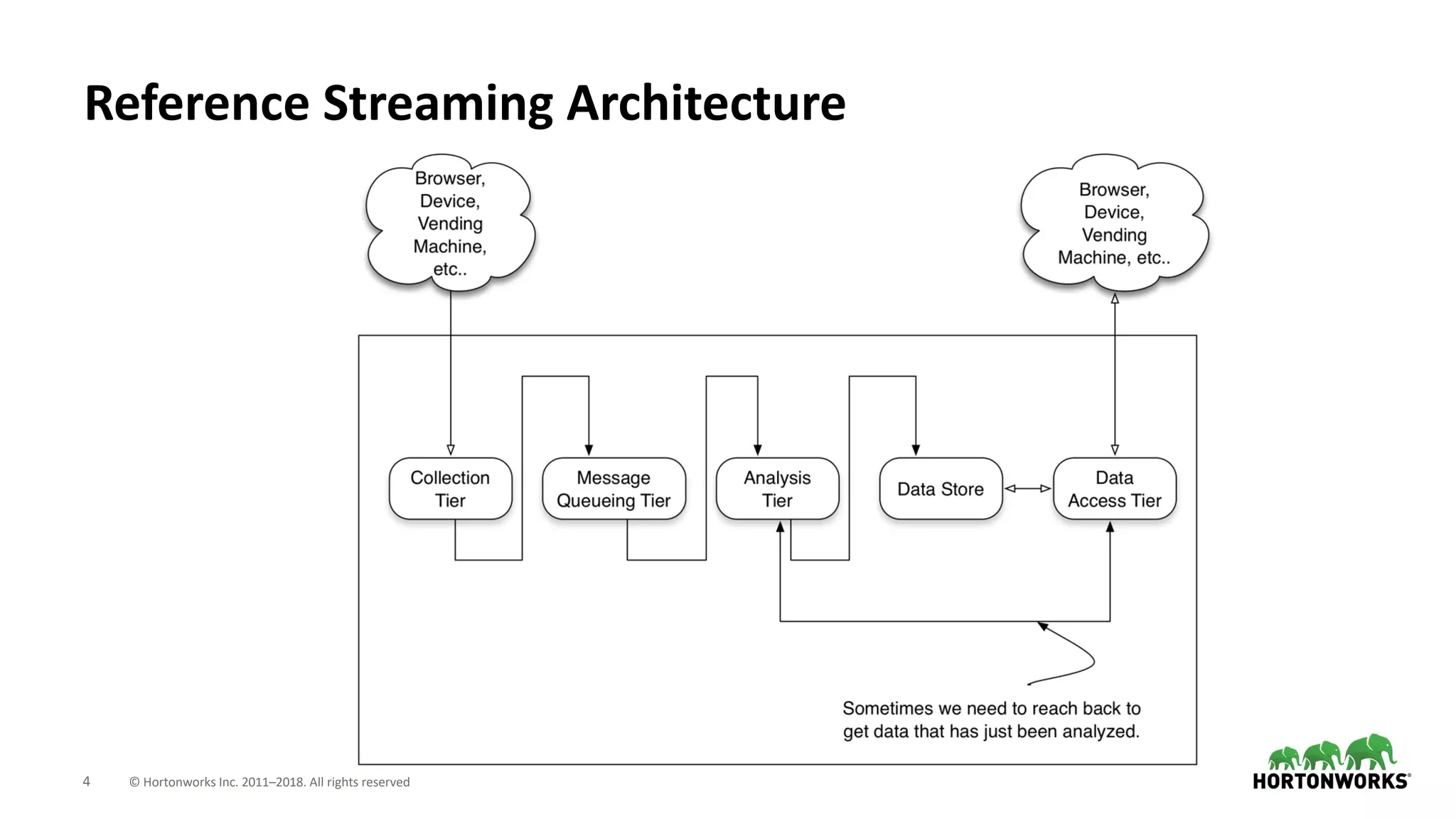

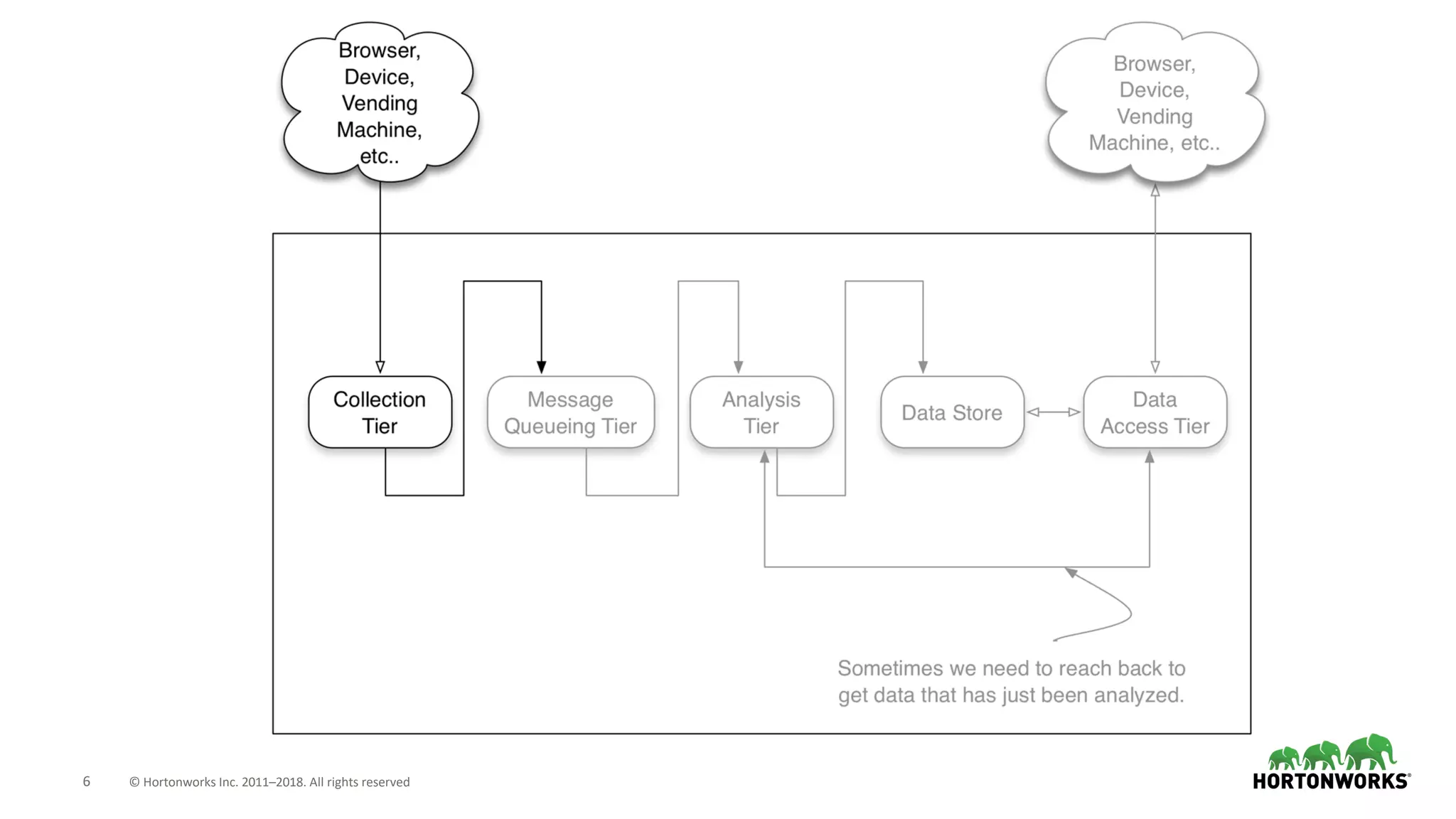


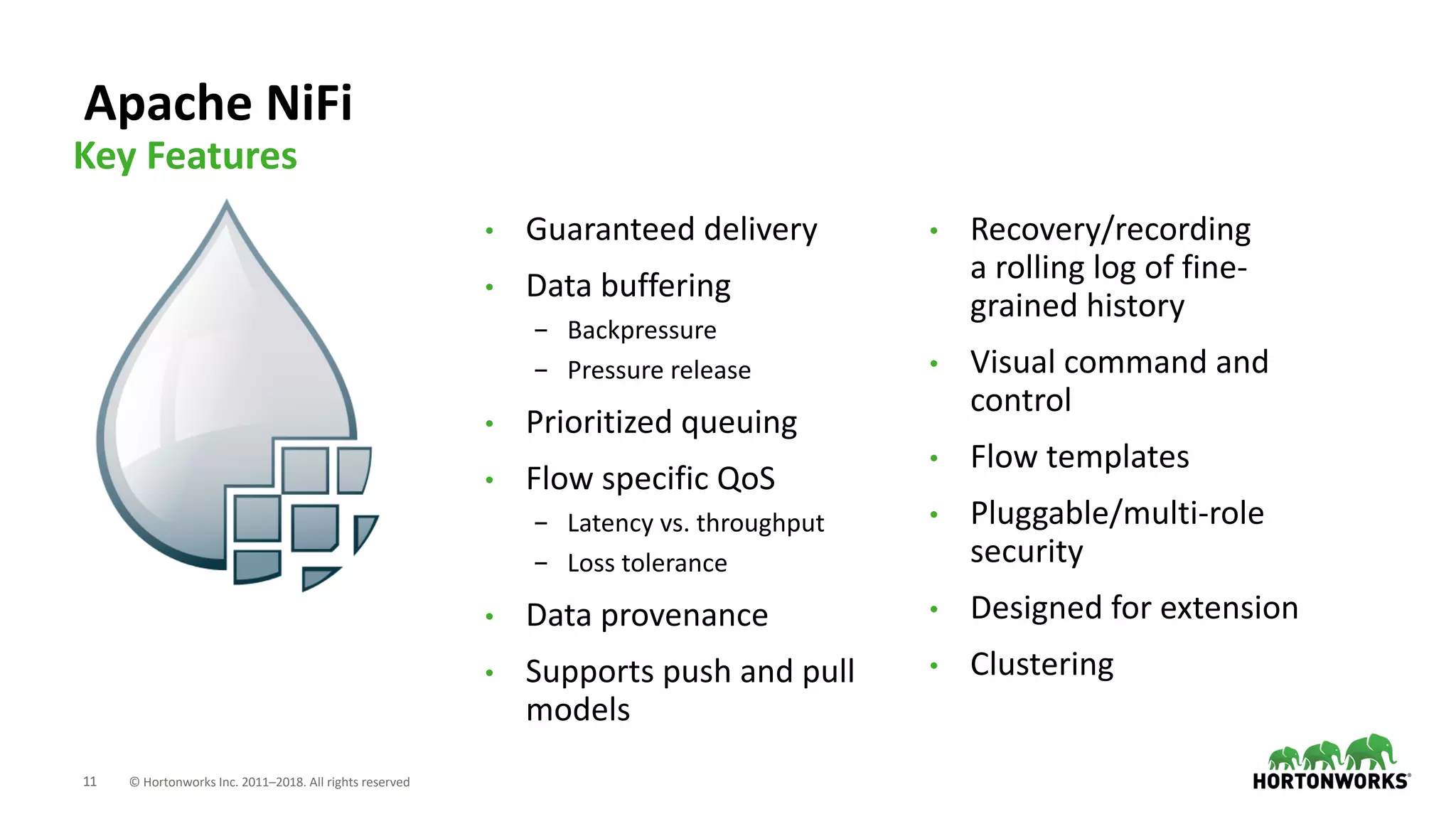
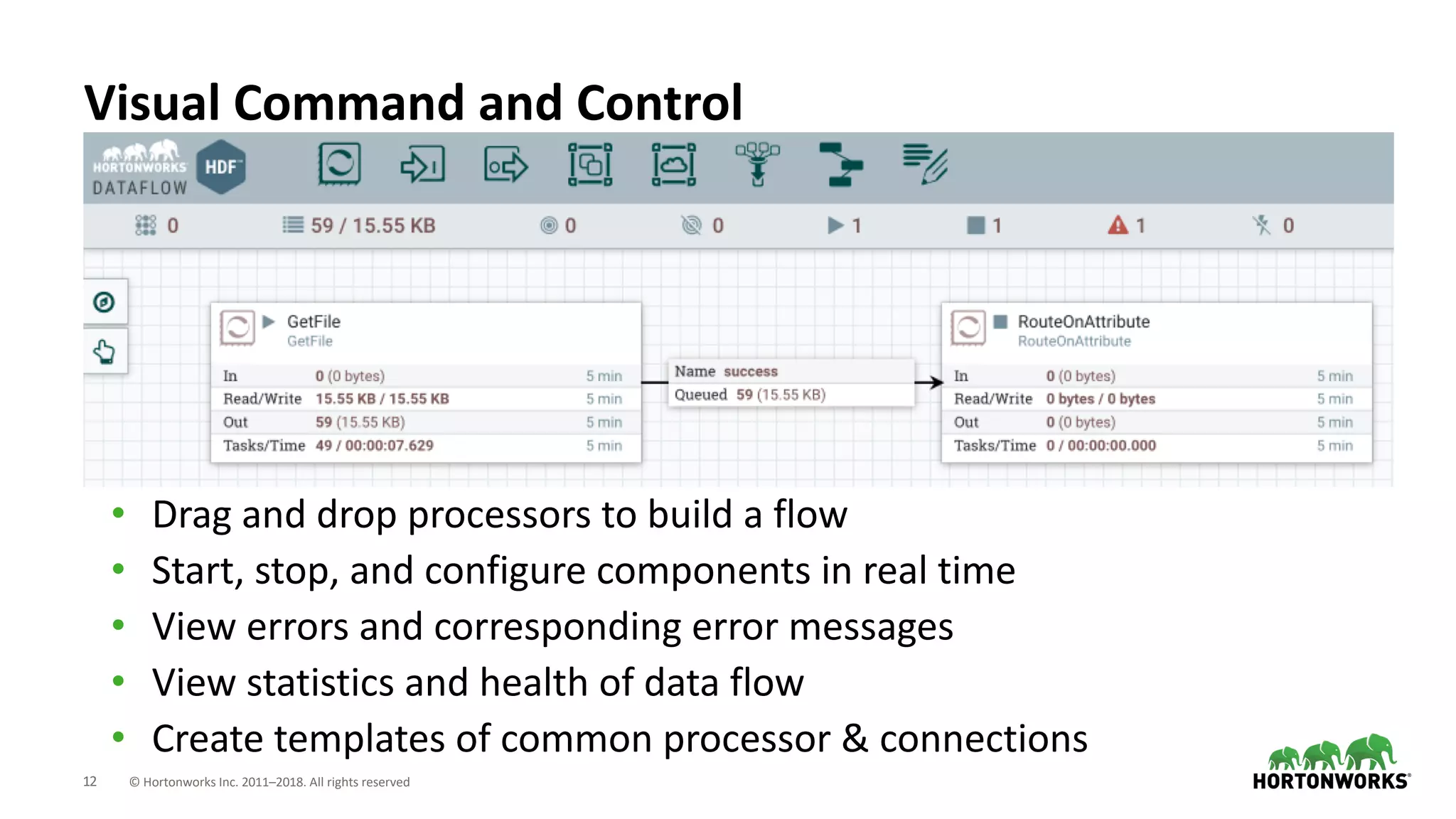

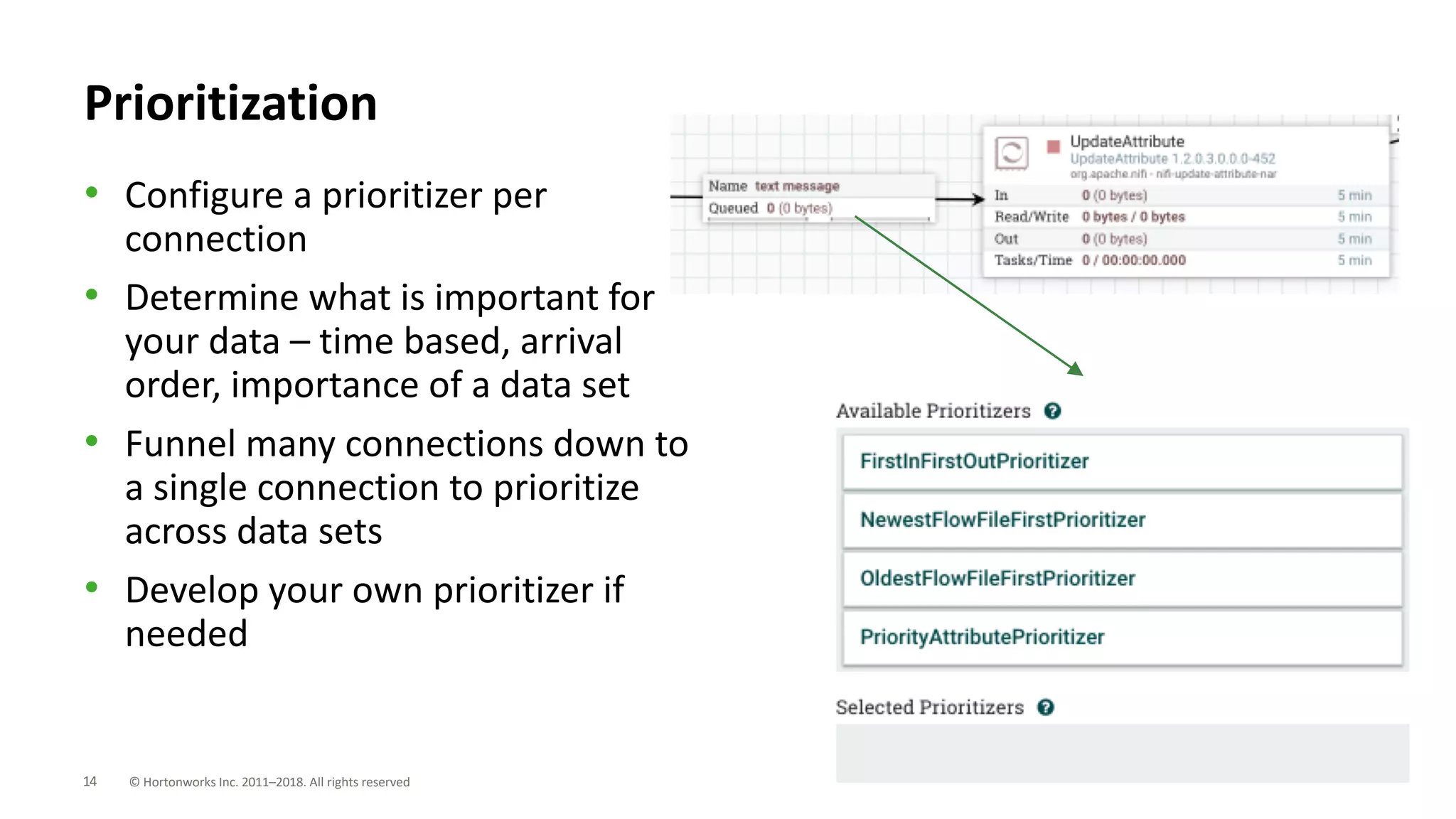
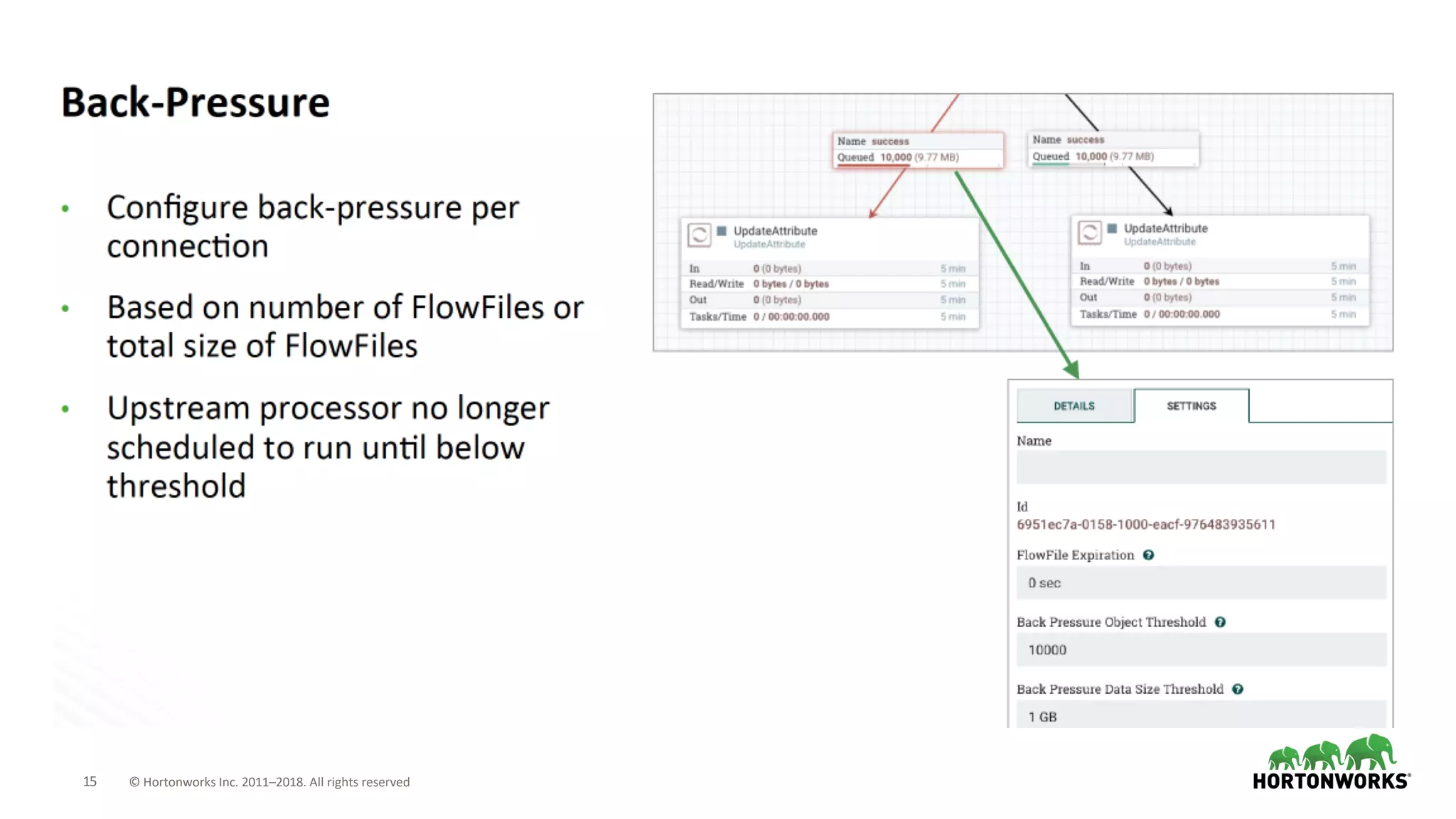

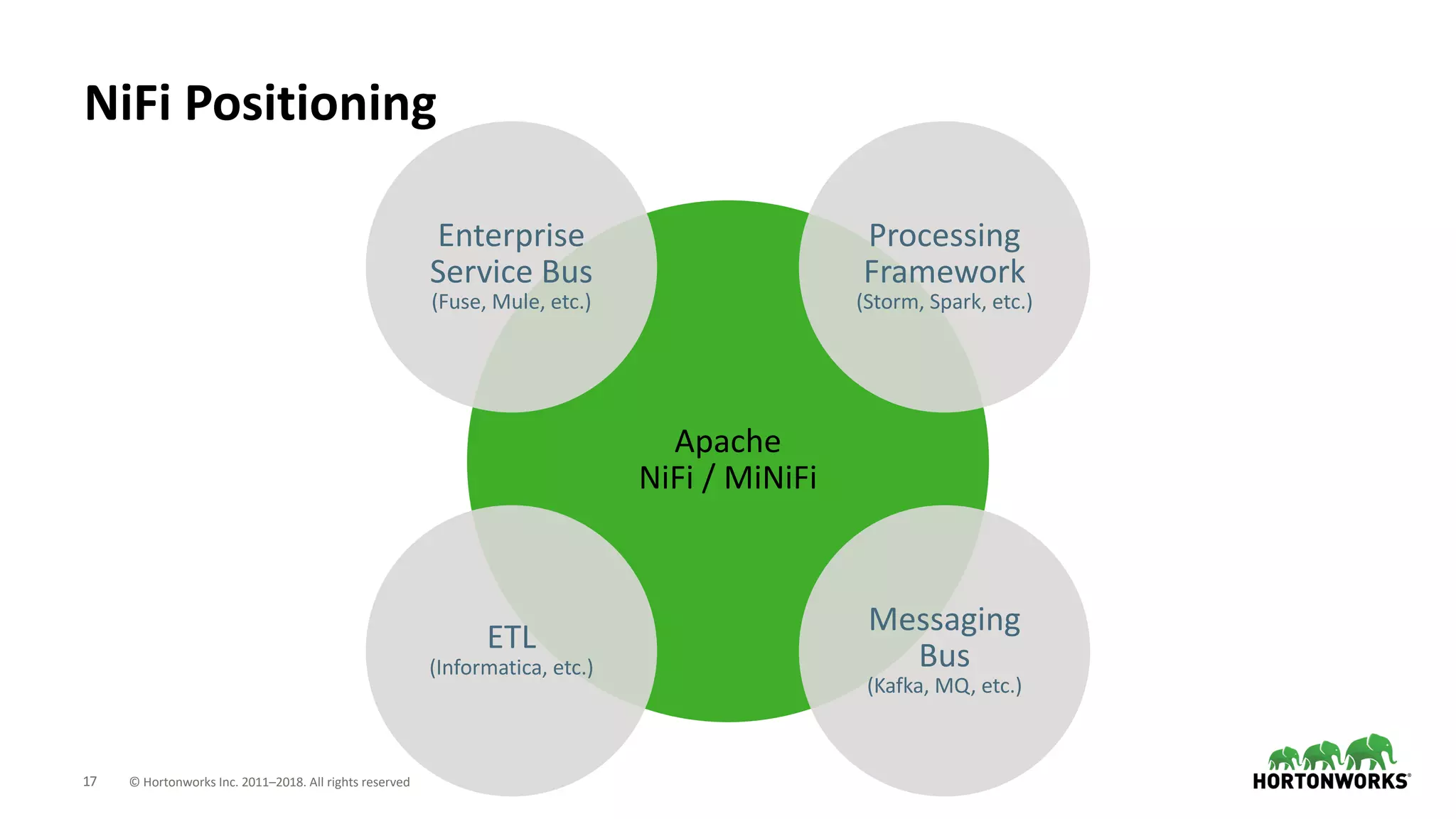
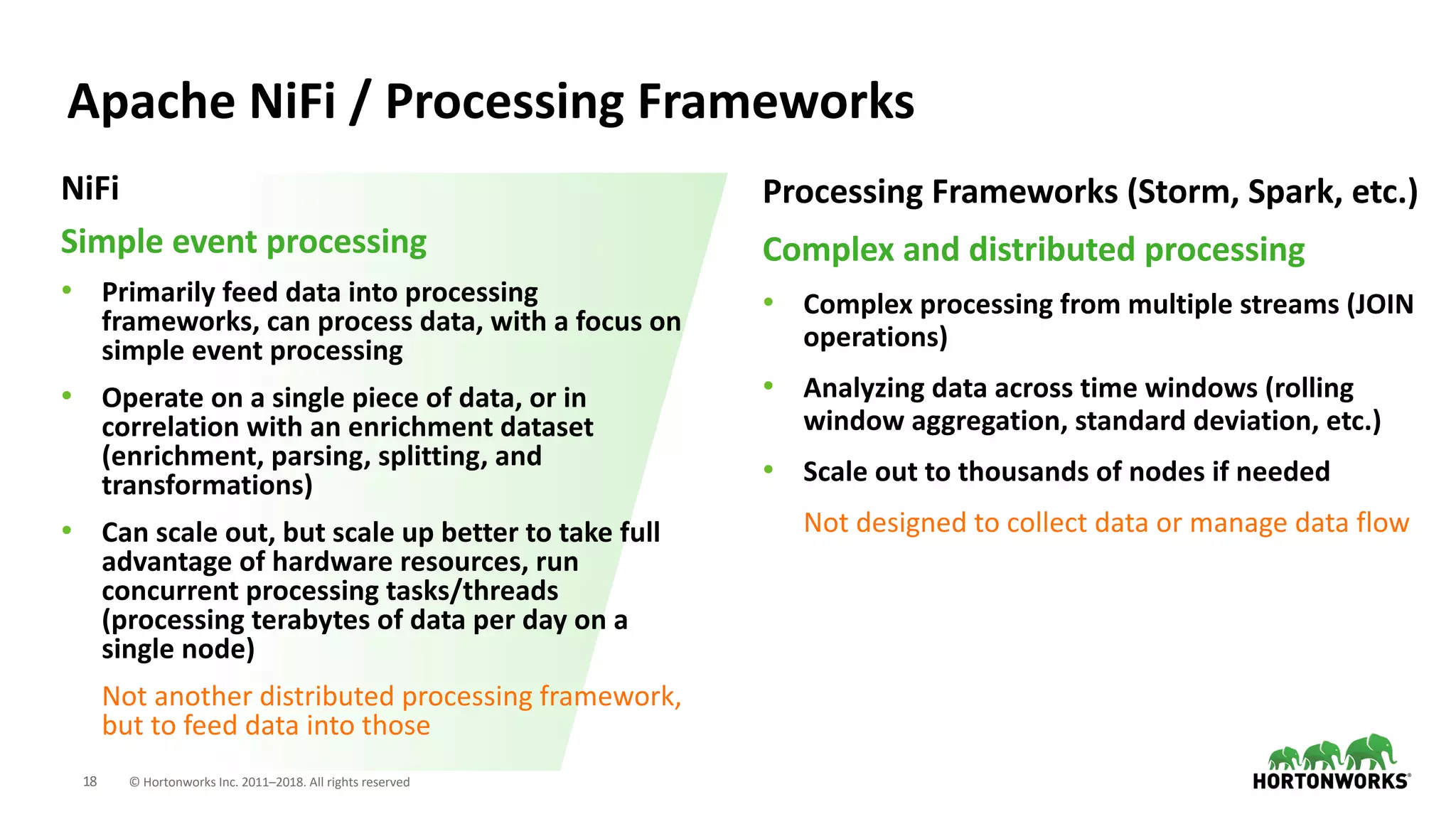
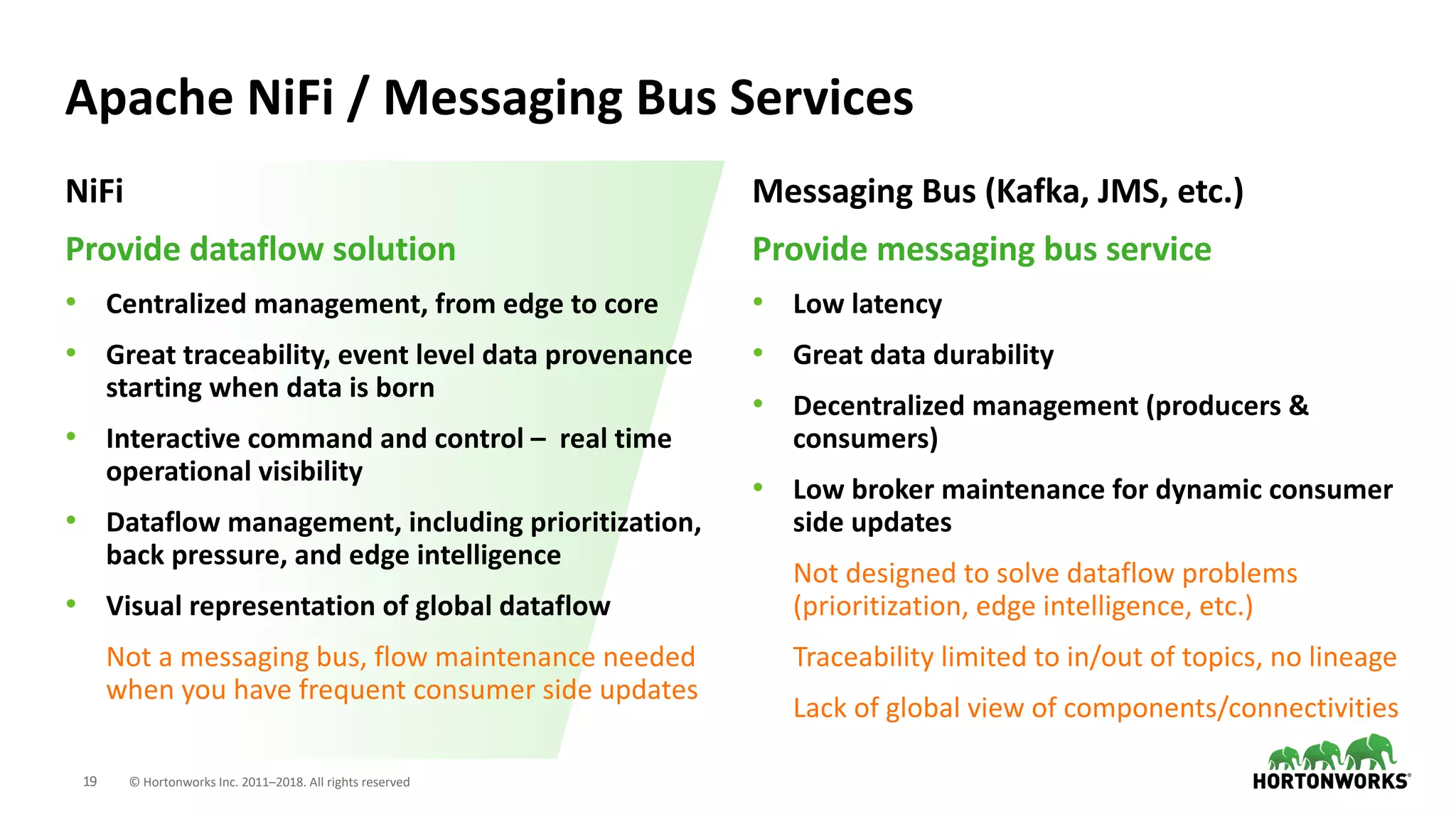
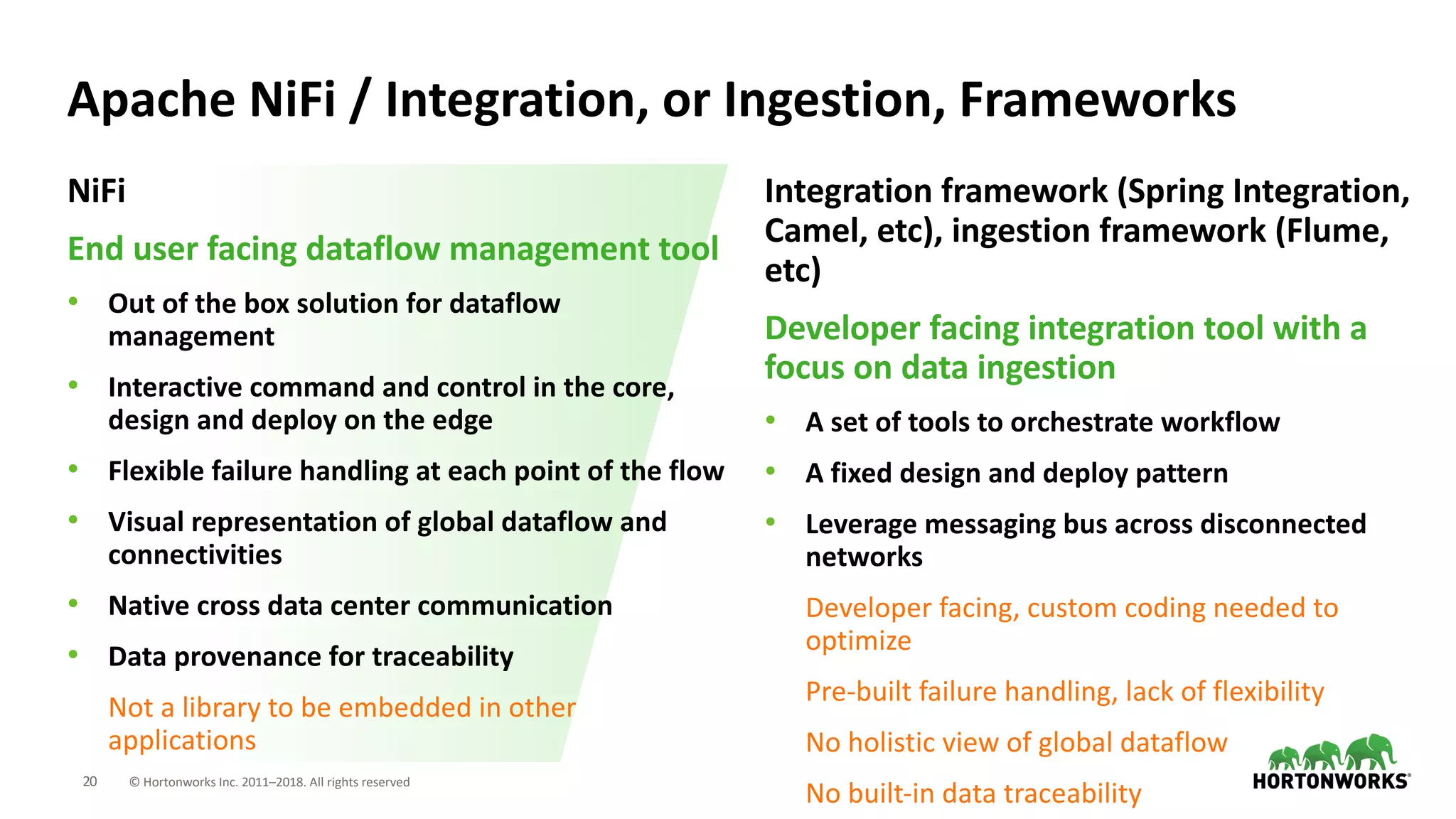

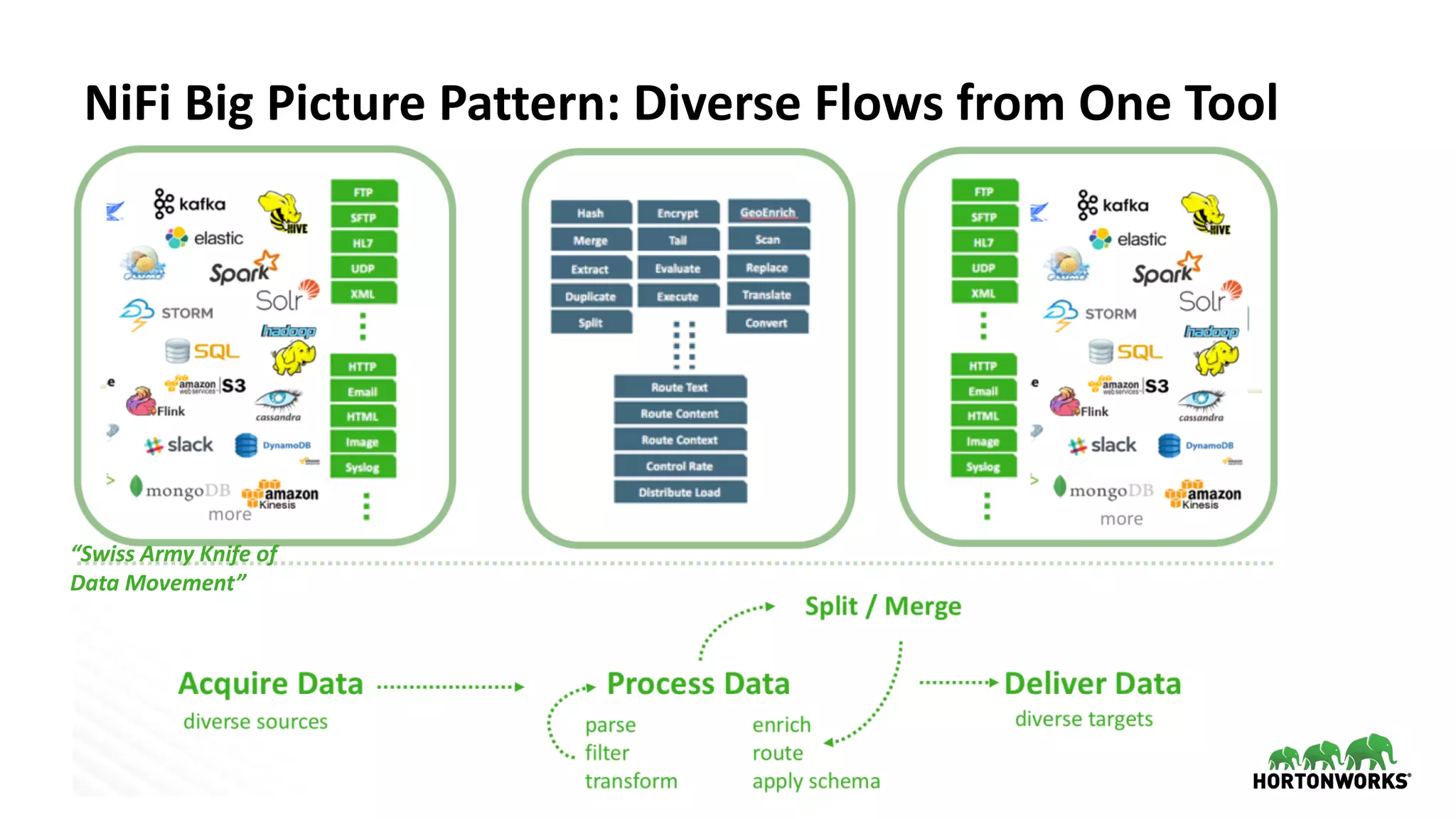

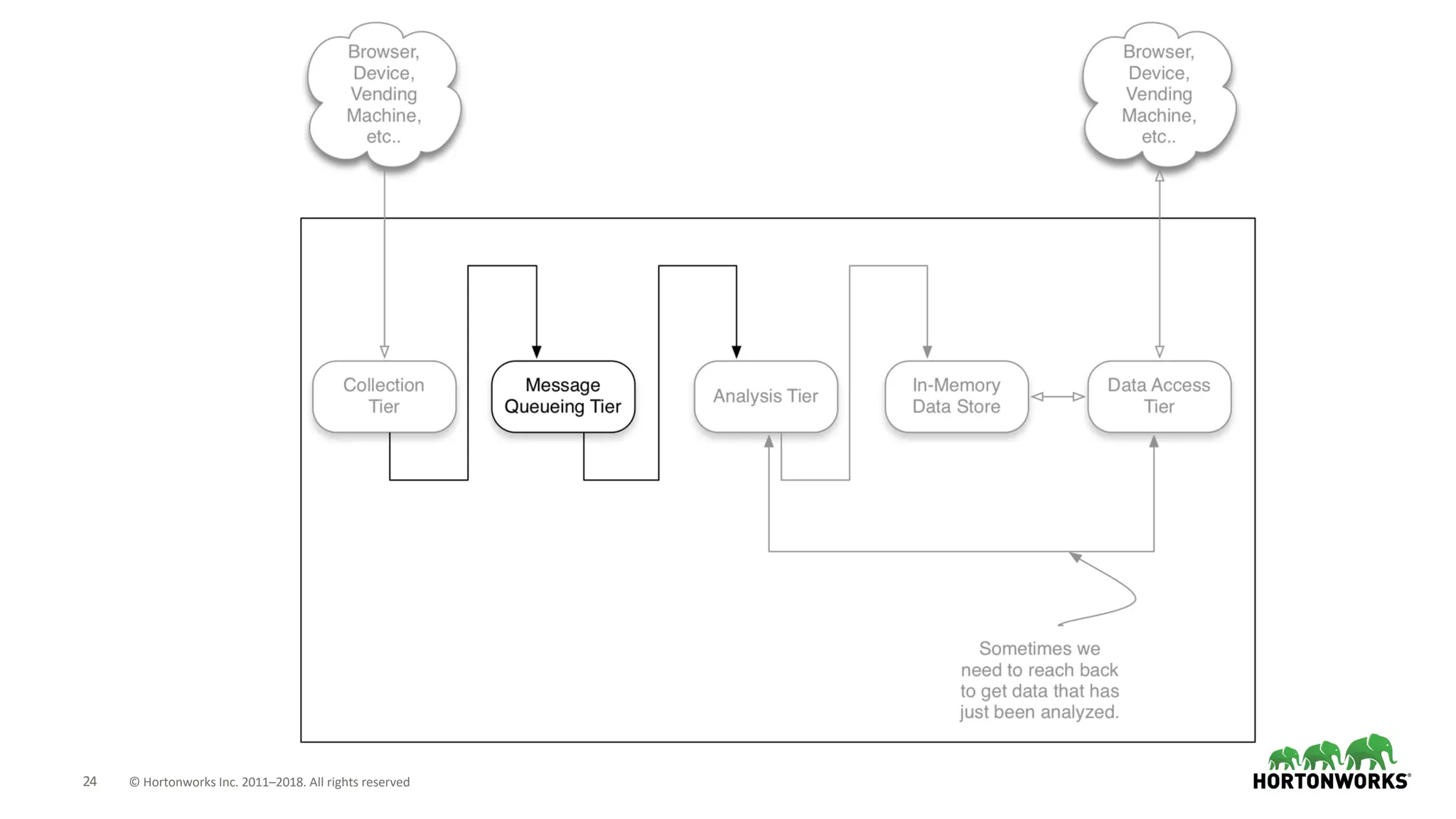
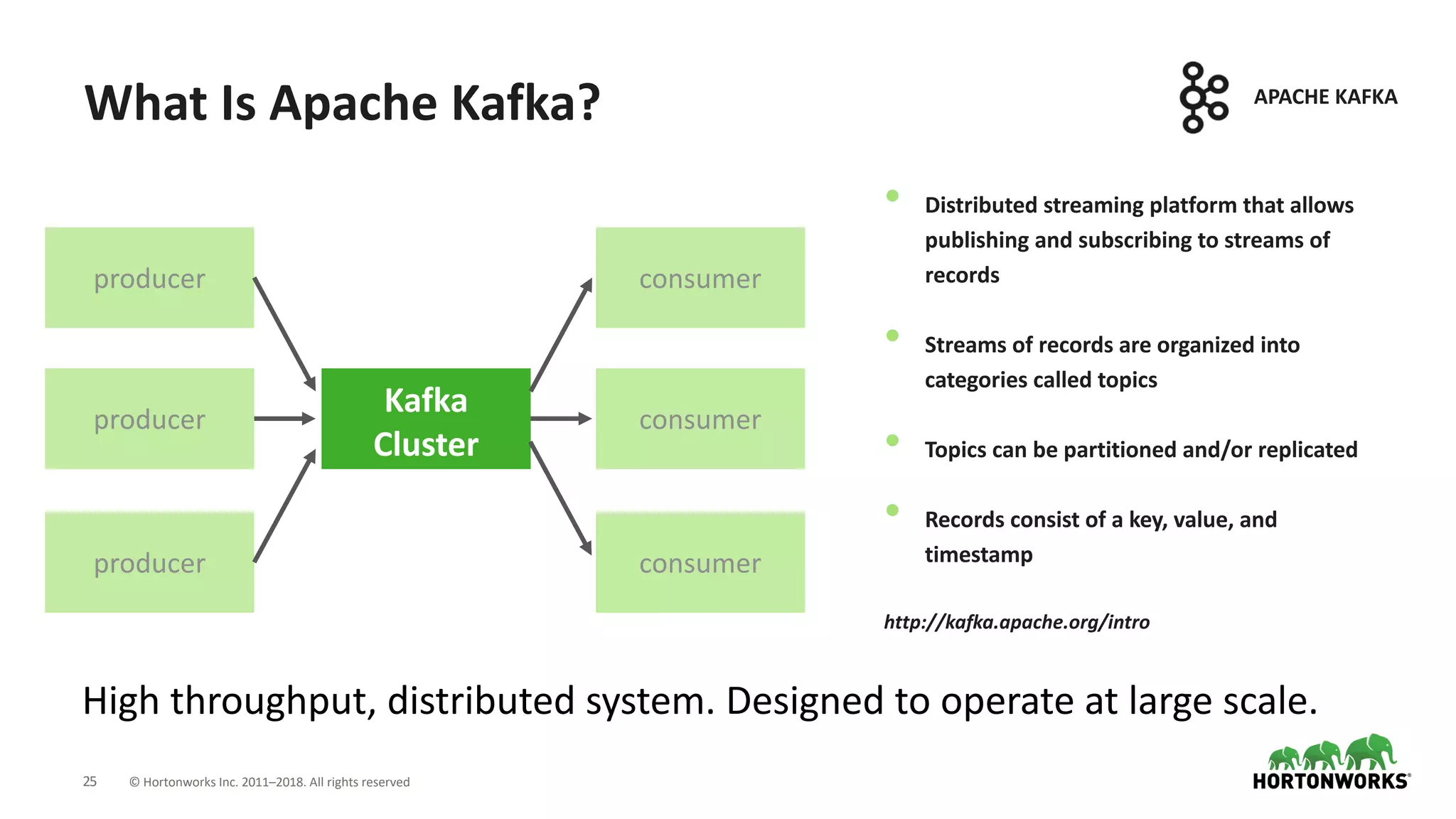
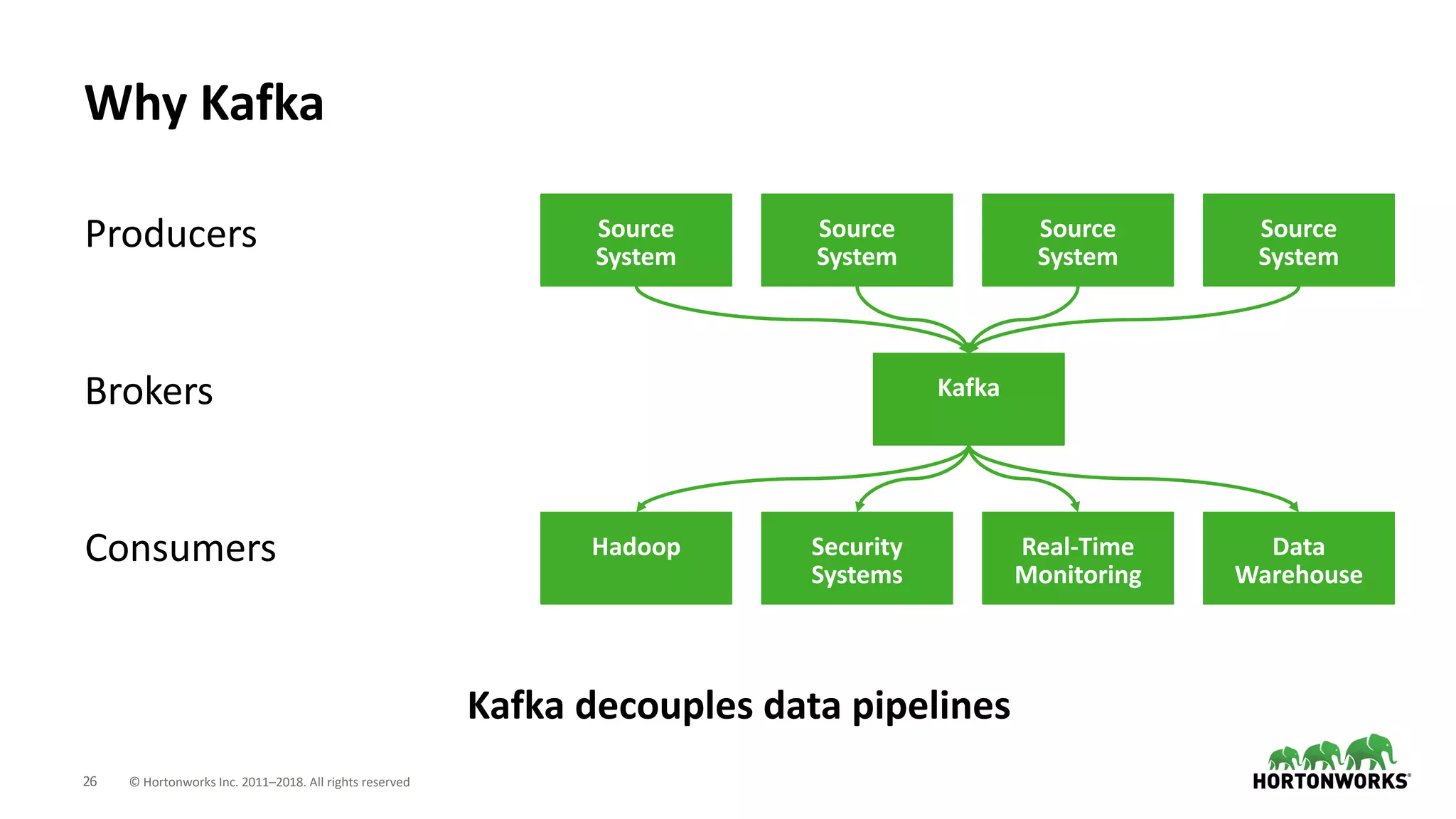





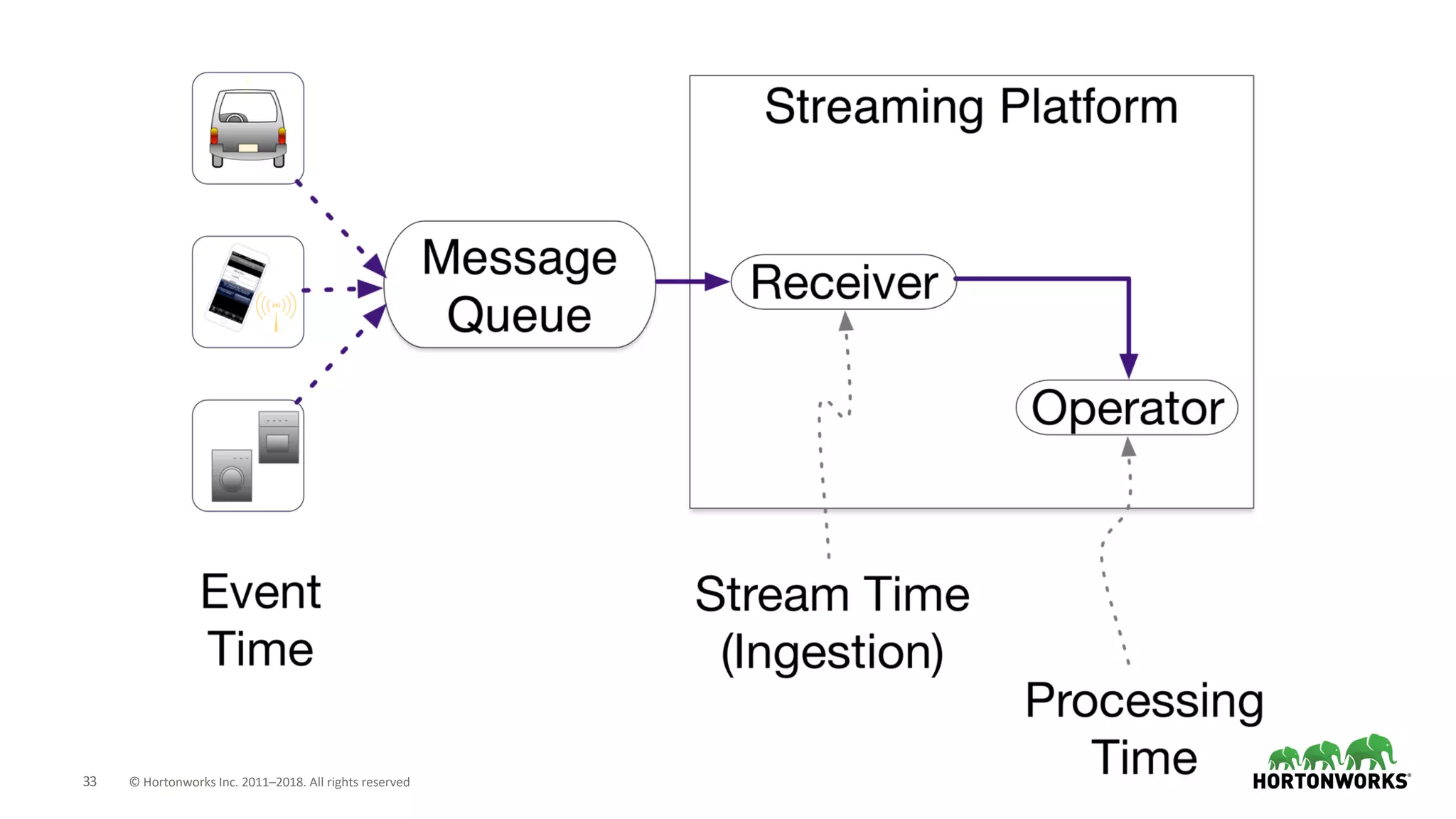
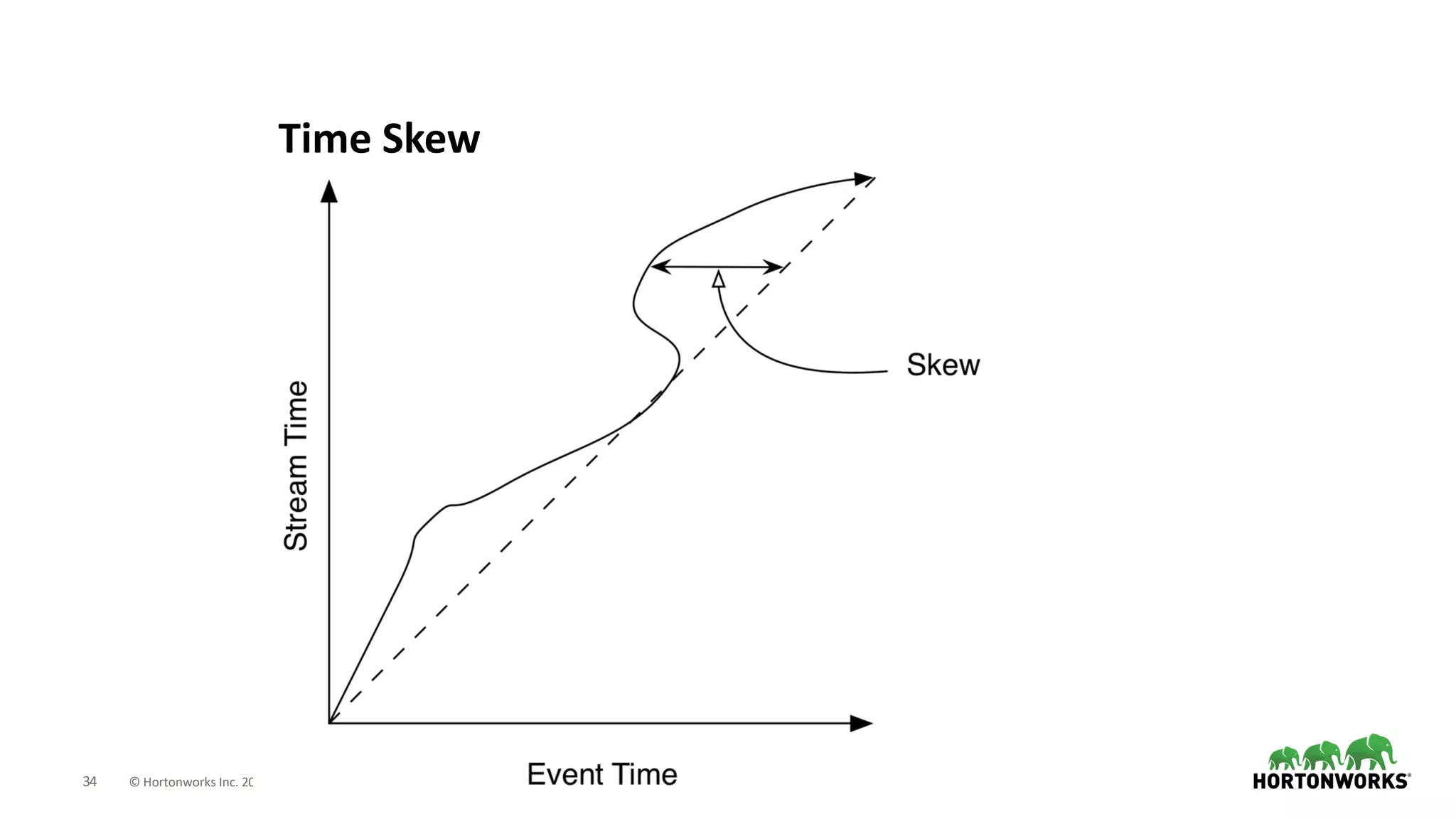


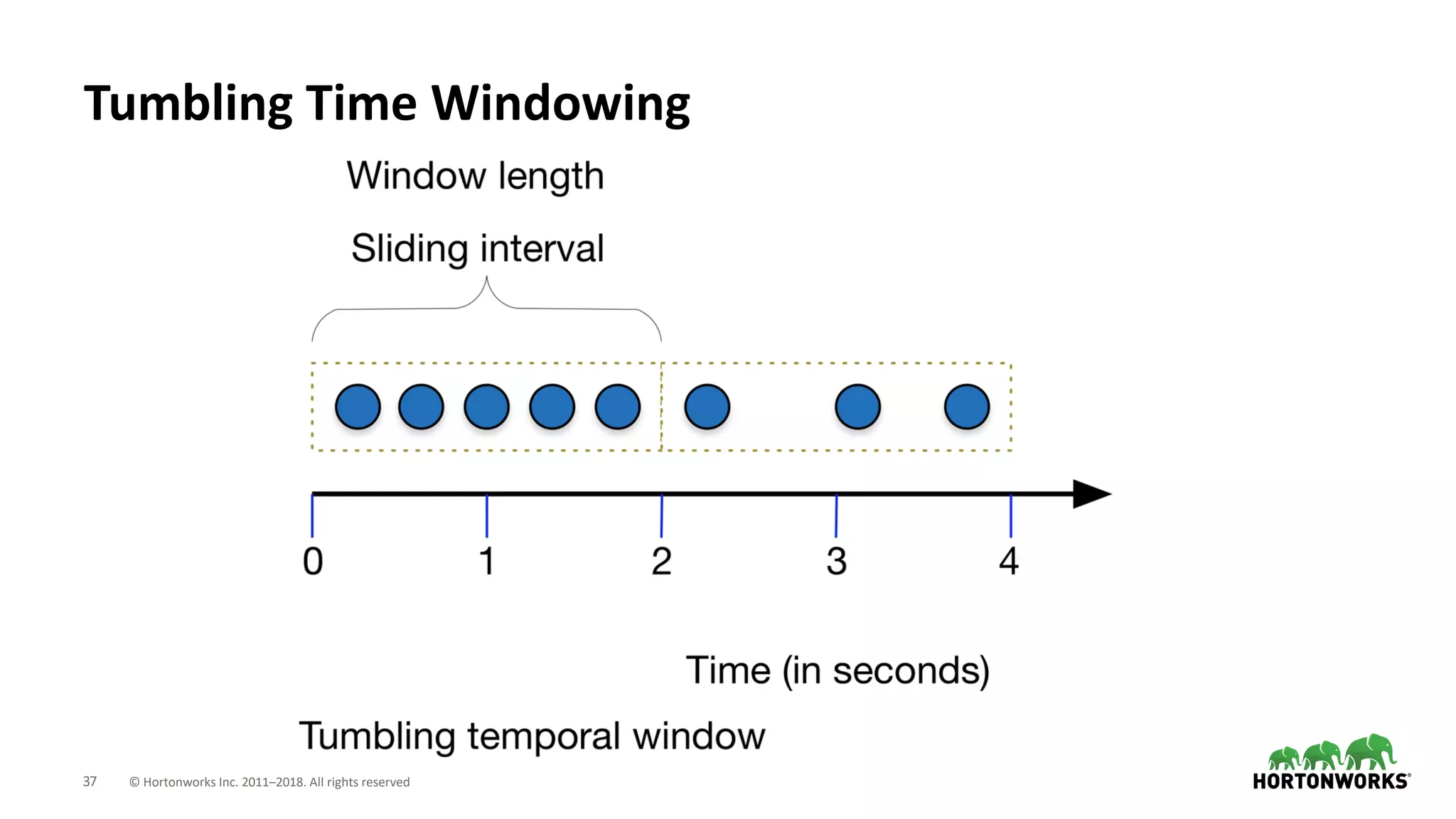


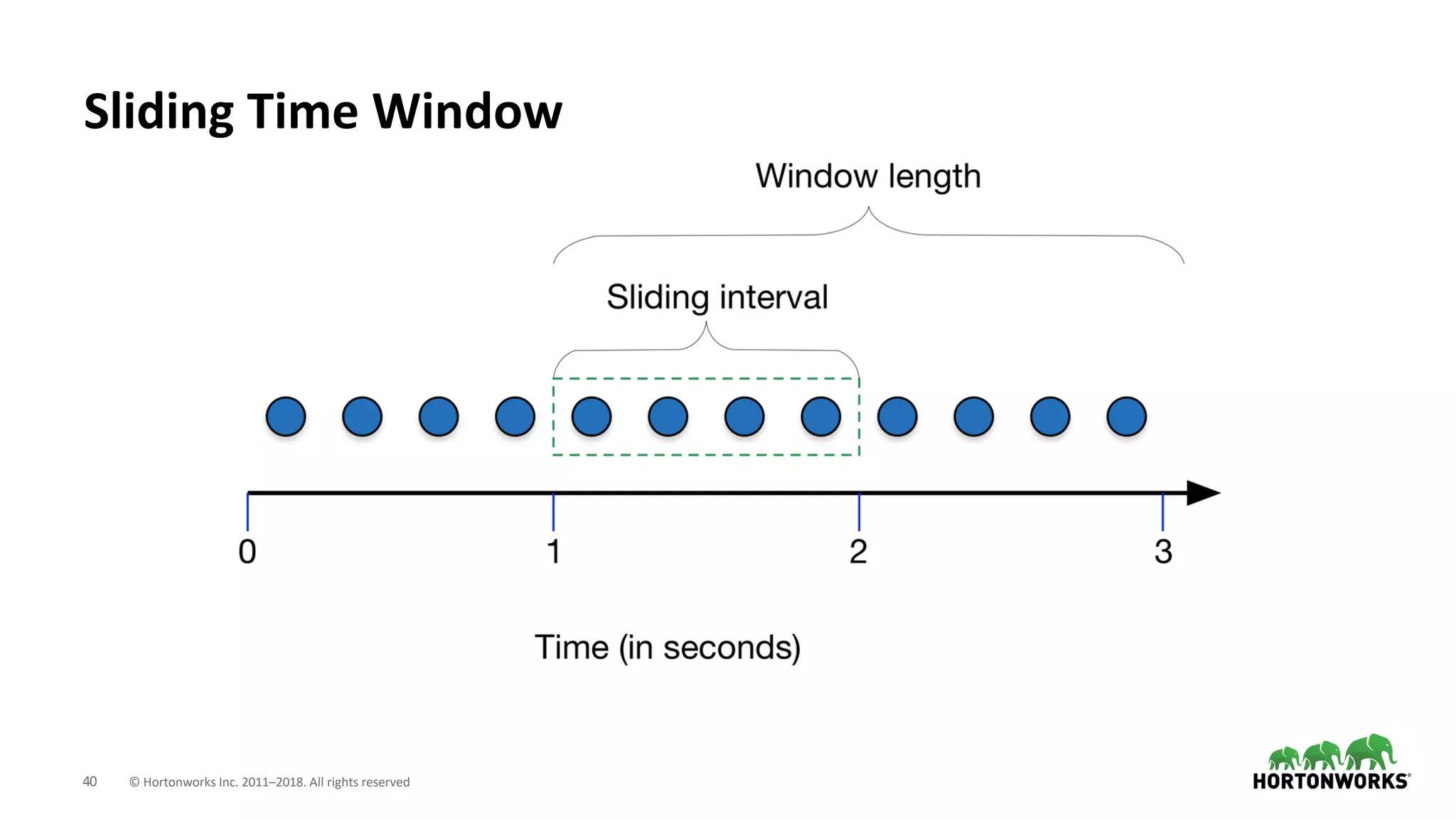
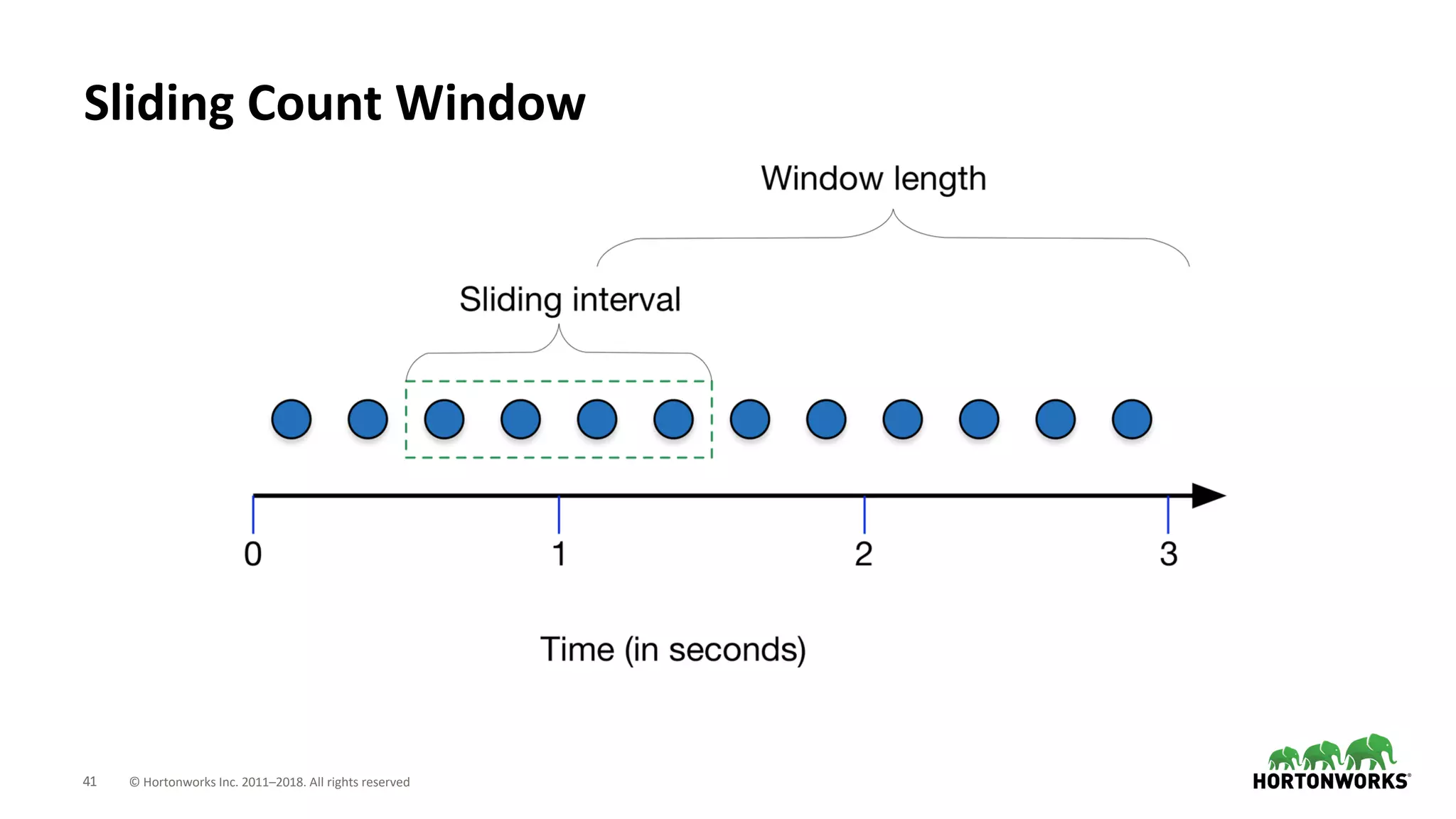


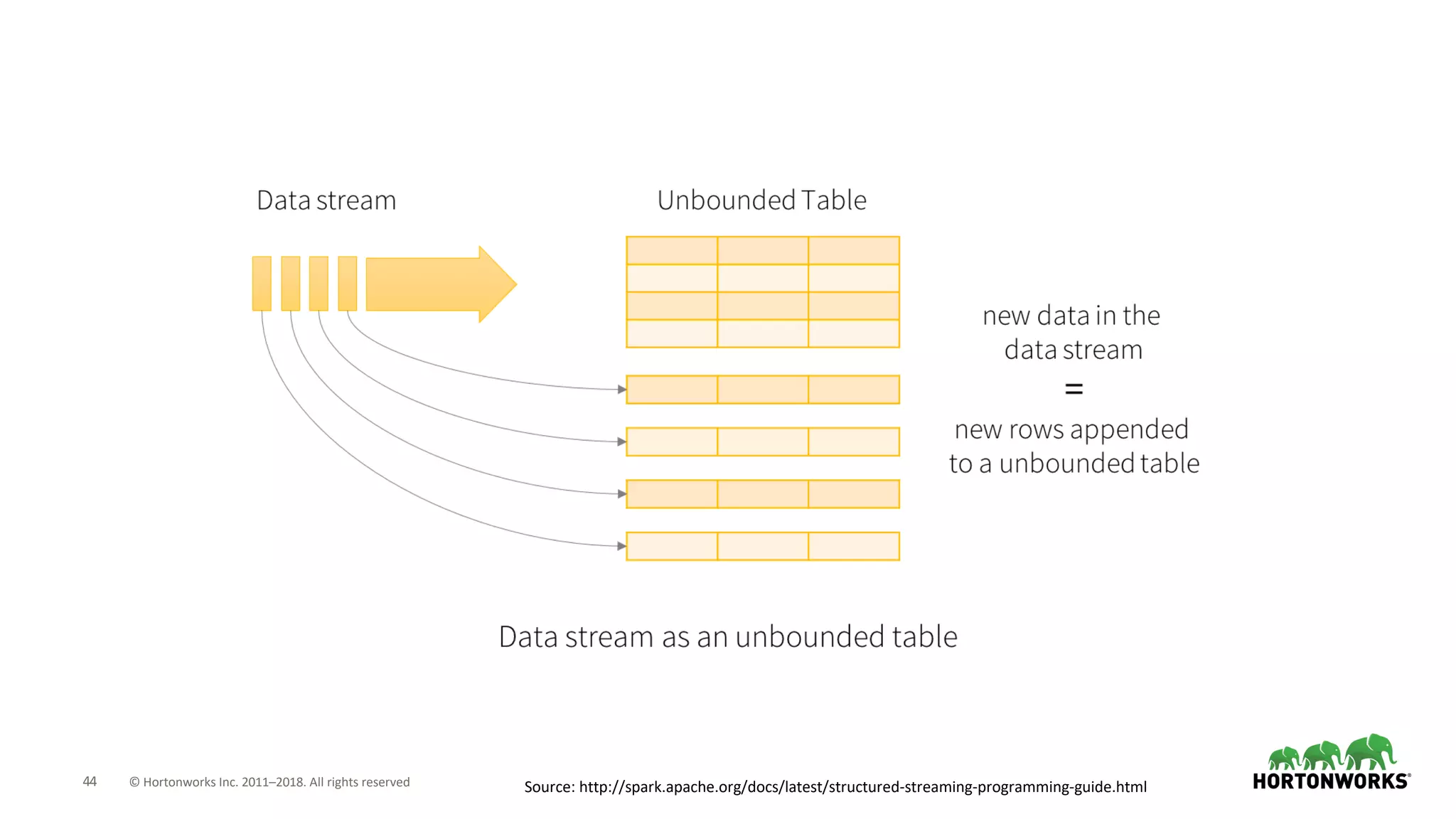
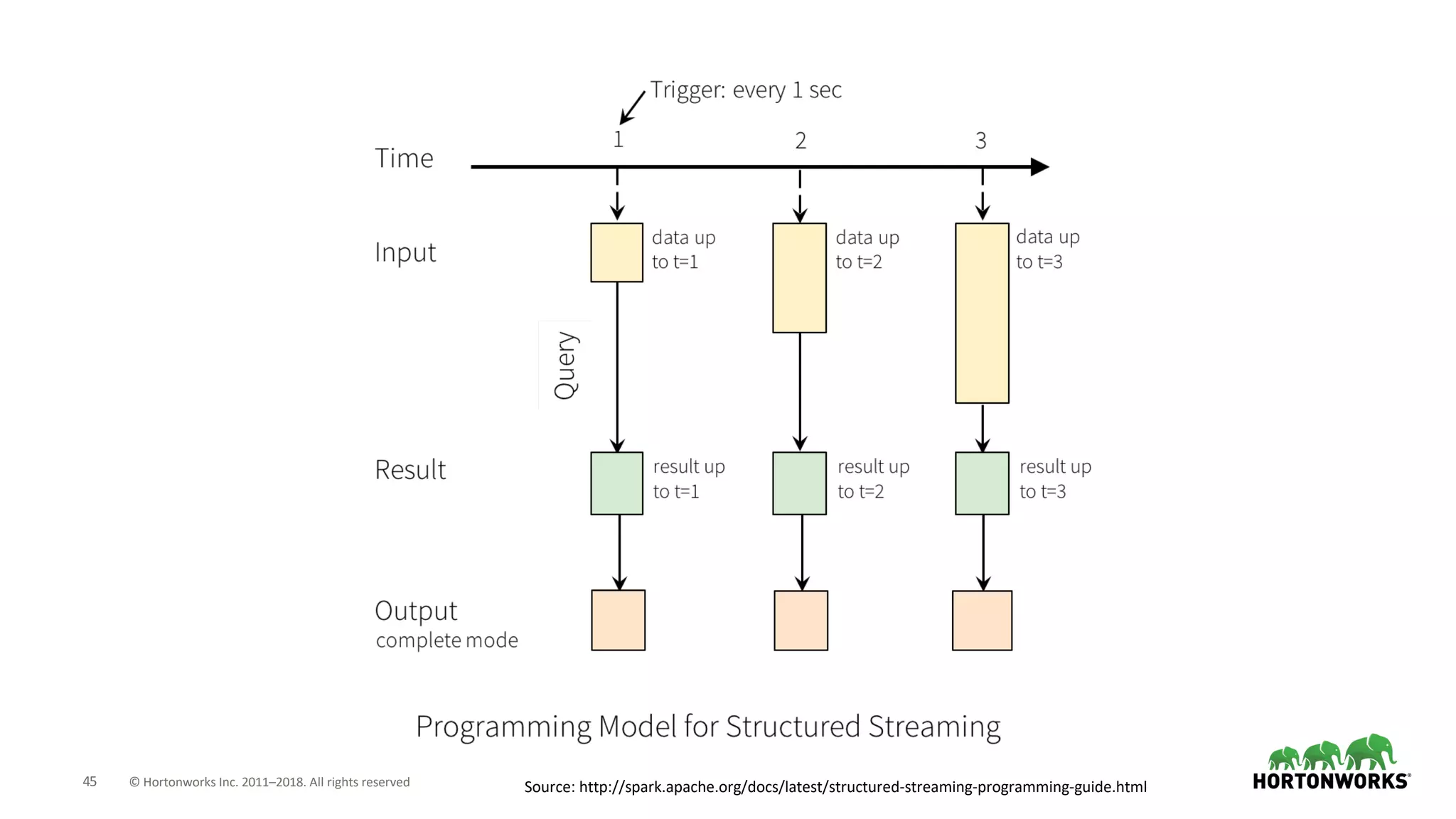
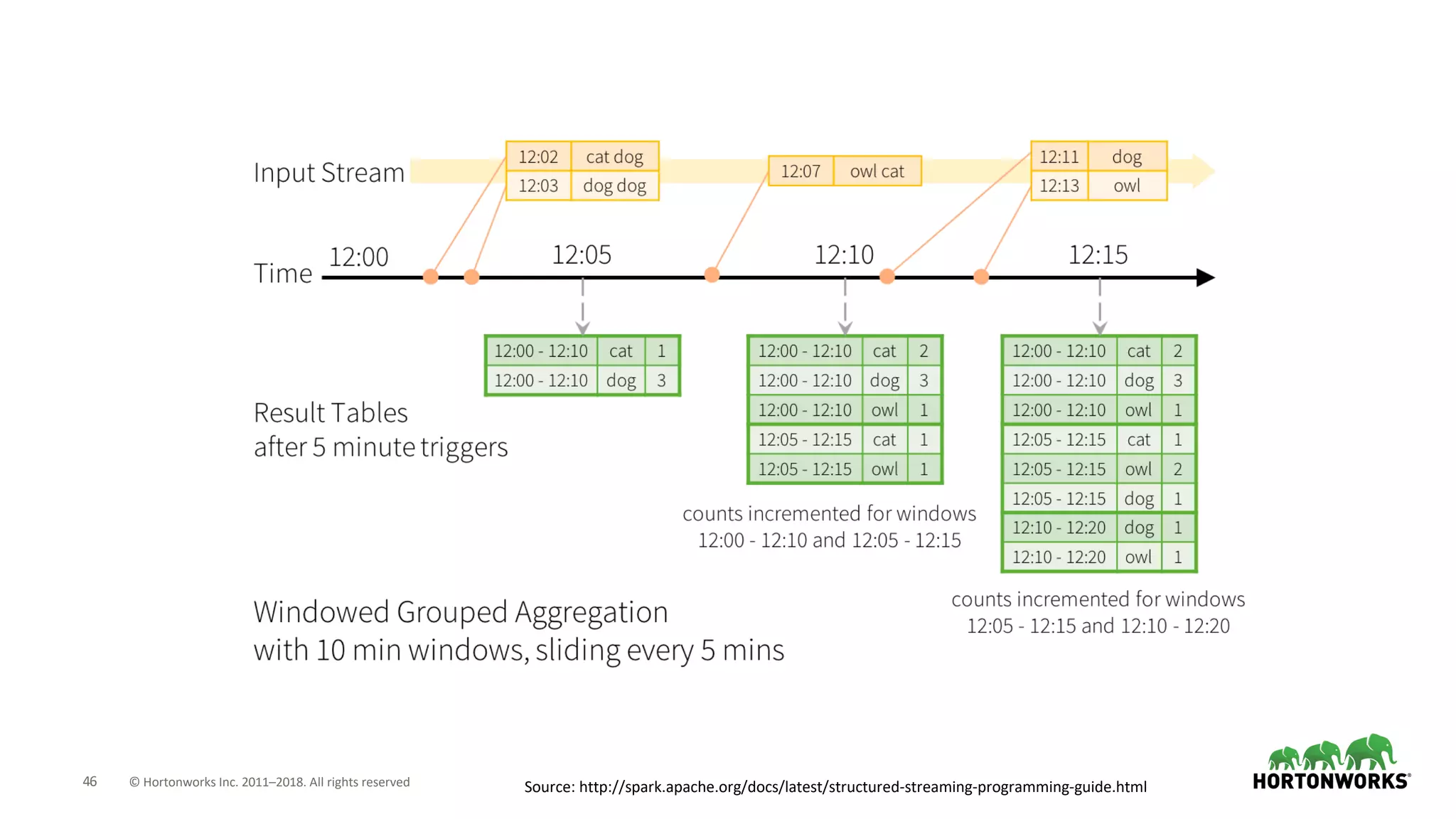
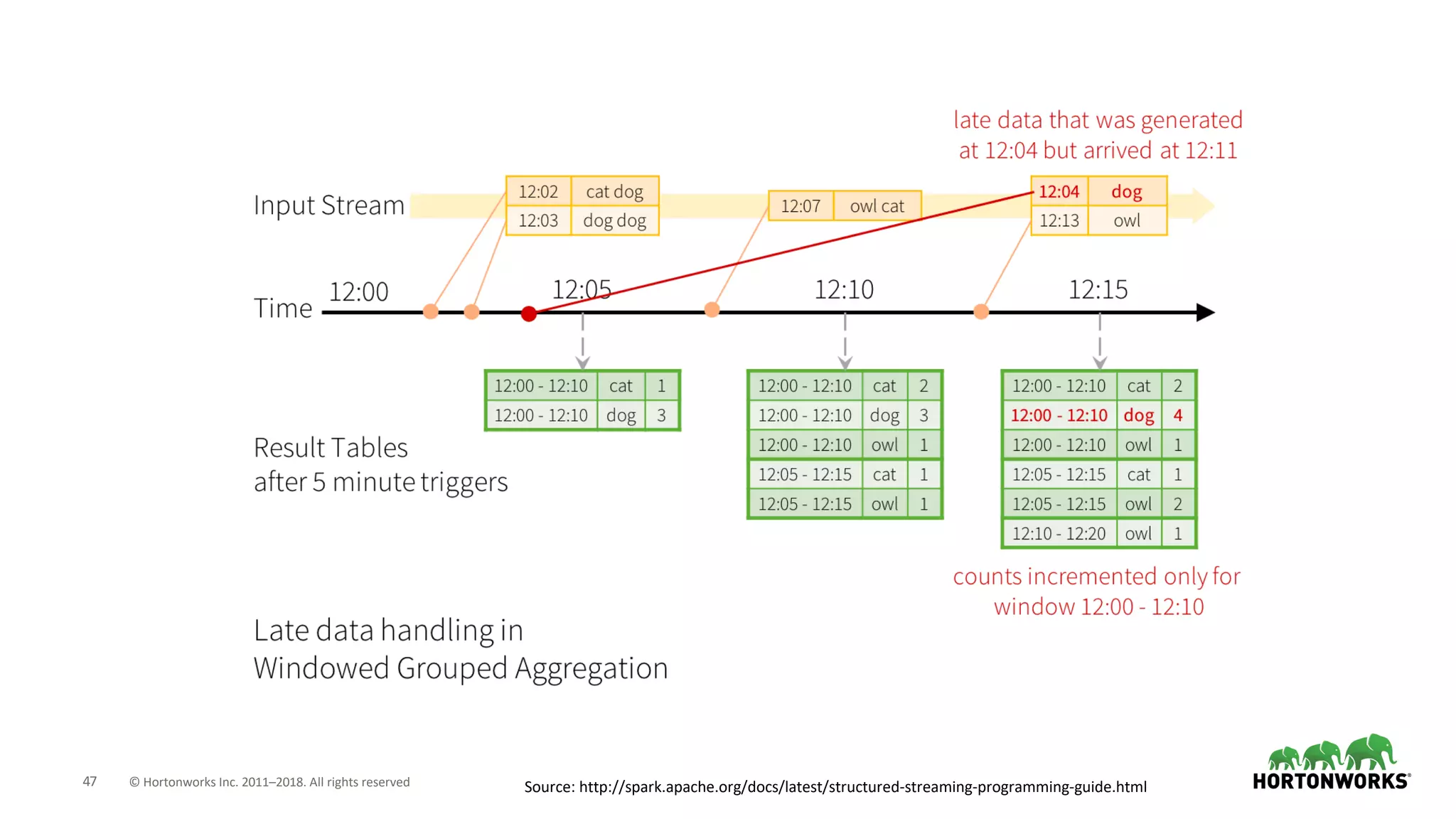
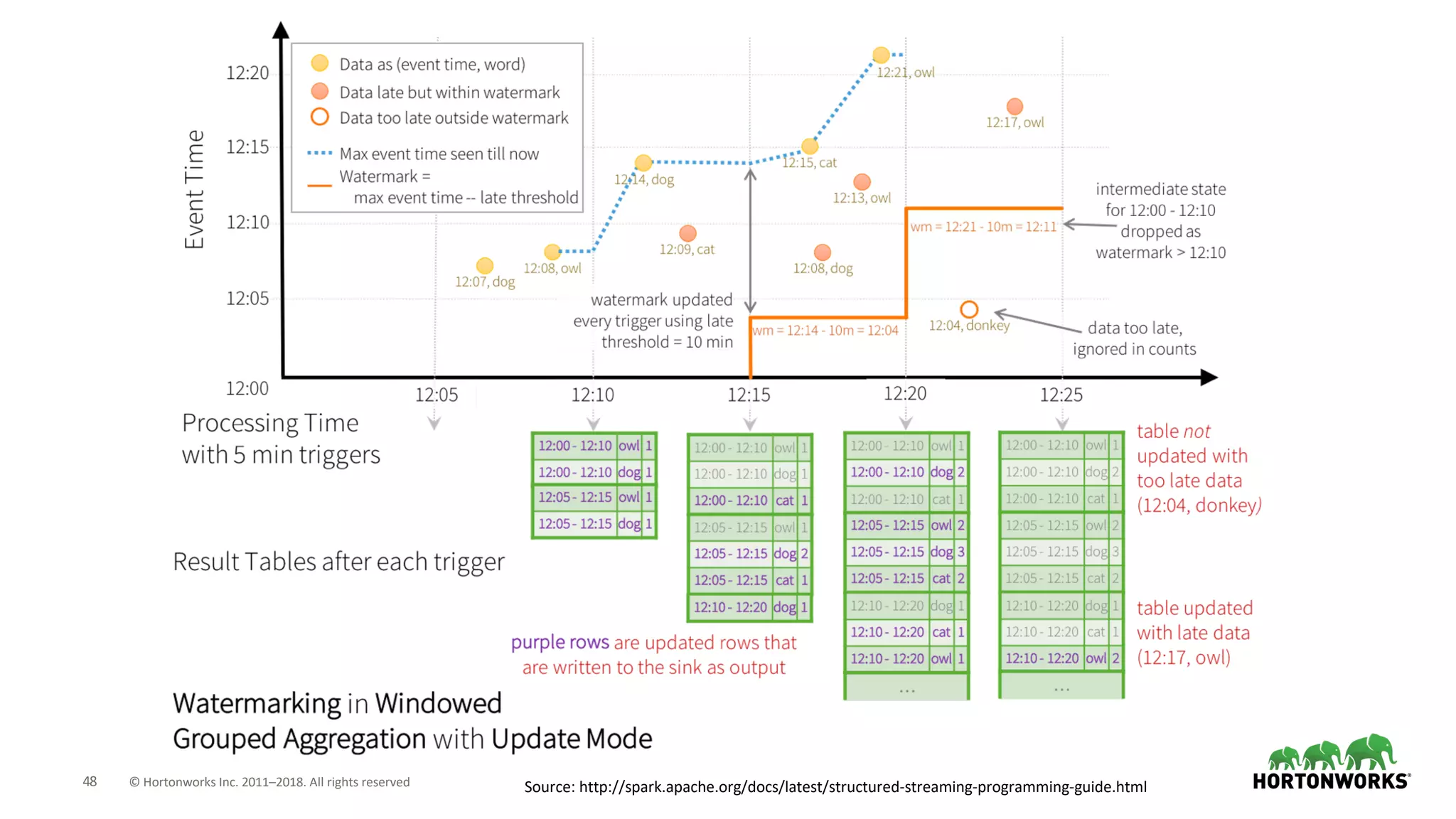
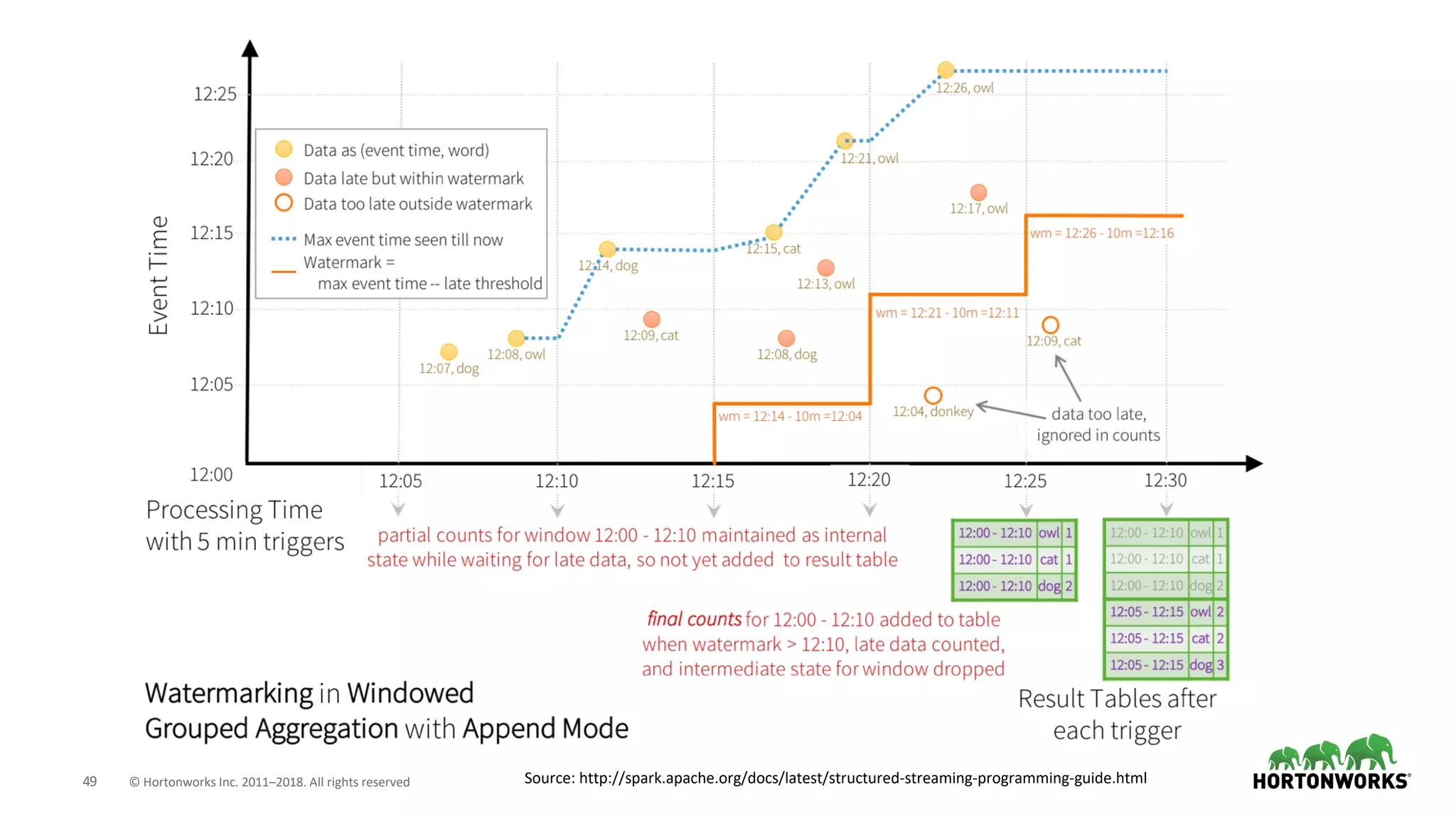






The document discusses the use of Apache NiFi and Kafka for next-generation ETL processes, highlighting their features, advantages, and positioning within dataflow management. It contrasts NiFi's capabilities in handling structured and unstructured data with traditional ETL tools, while also detailing Kafka's role as a distributed streaming platform. Key aspects include data ingestion, real-time processing, and the importance of visual command and control in managing complex data flows.













































![[253] apache ni fi](https://cdn.slidesharecdn.com/ss_thumbnails/235apachenifi-150915053924-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)





































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


