Download as PDF, PPTX






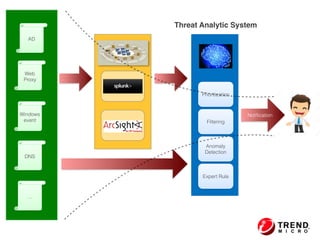

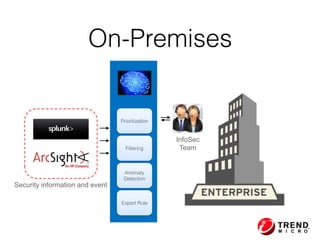
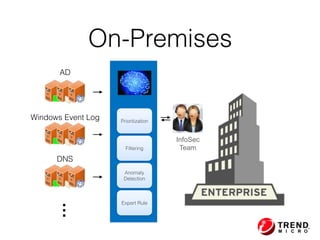










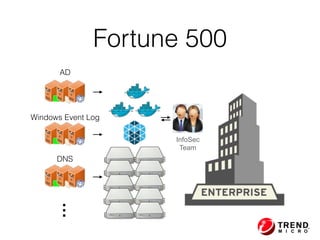

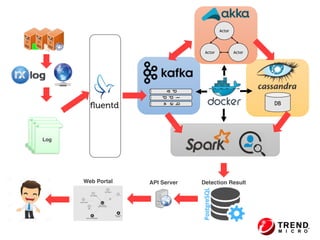
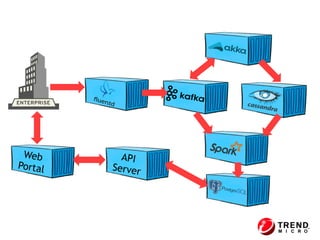
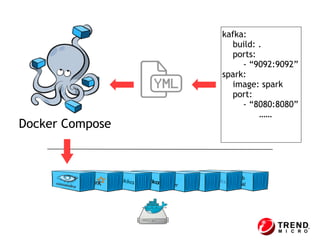

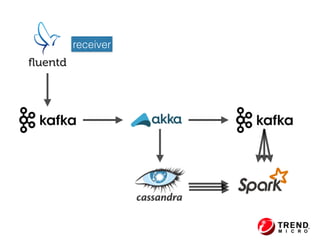
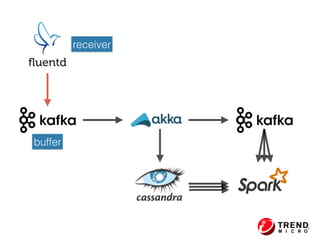
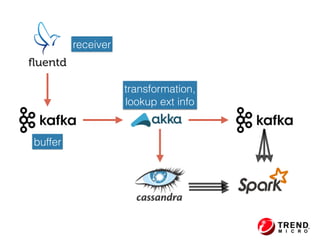
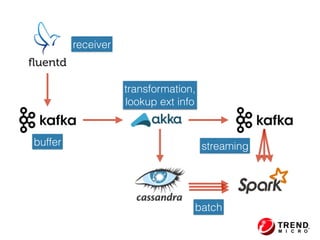





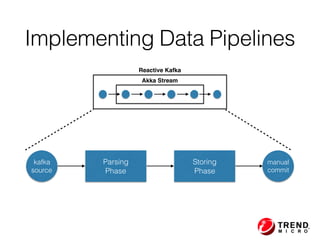
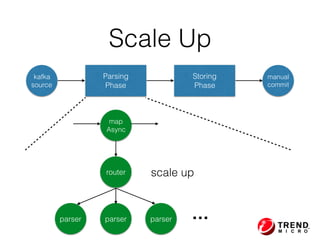
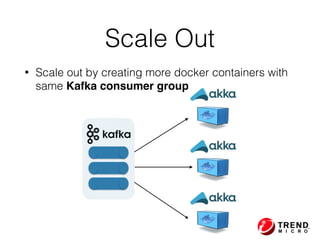

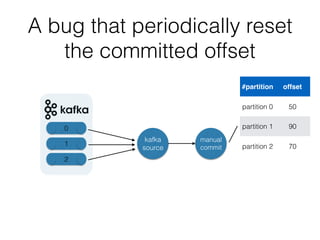
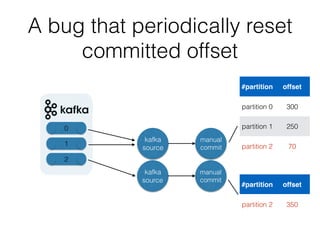
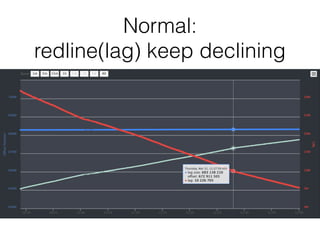
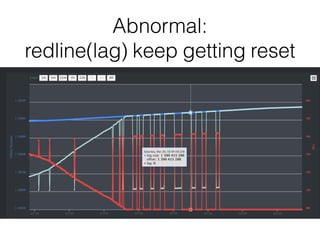


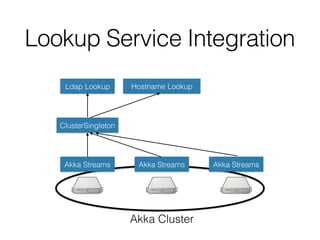
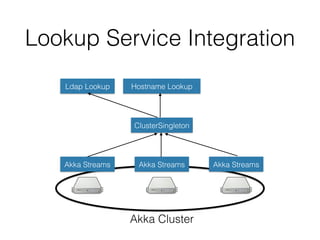
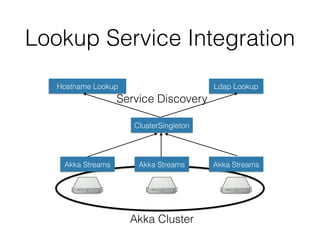
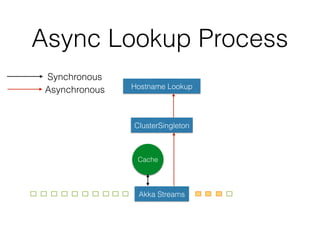
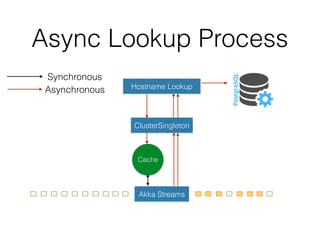
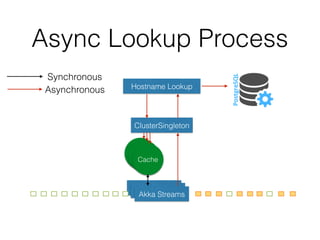



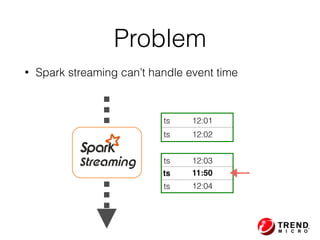
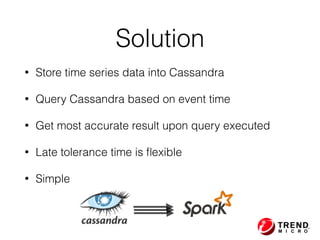








The document outlines the development of a threat analytic big data product using the SDACK architecture, which integrates Spark, Docker, Akka, Cassandra, and Kafka for efficient data processing. It addresses challenges faced by infosec teams in managing large volumes of logs and detecting anomalies, utilizing various techniques for both streaming and batch analytics. The presentation highlights the advantages of using specific technologies for scalability, stability, and accuracy in data processing and anomaly detection.











































































































