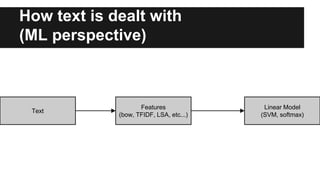
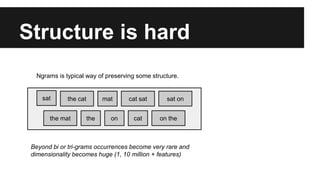
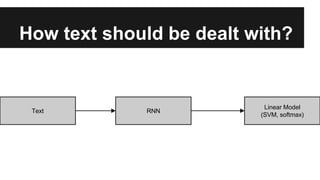
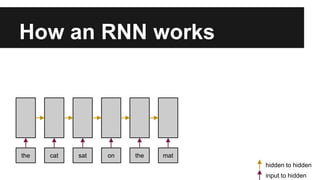
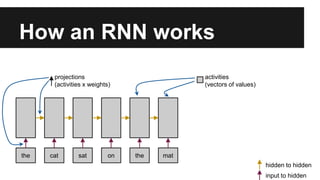
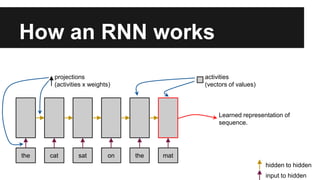
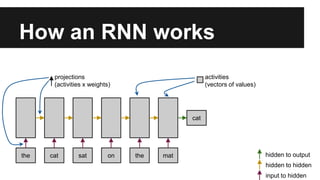
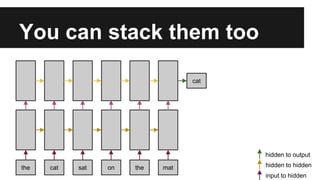
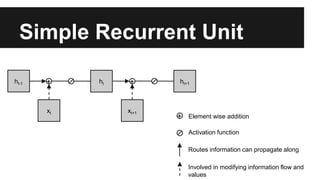
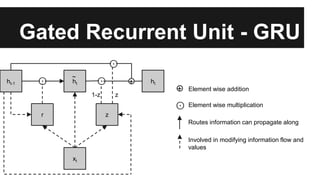
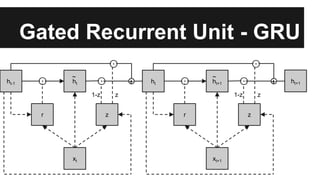
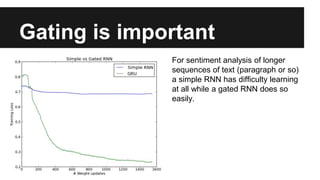
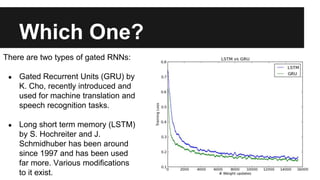
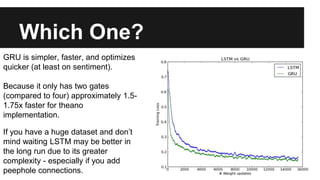
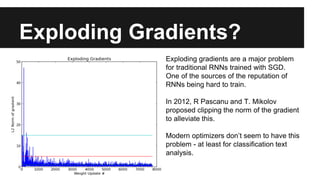
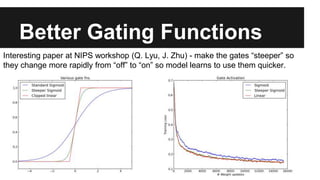
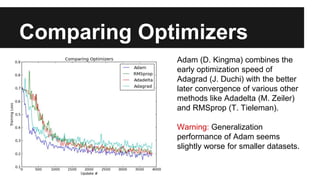
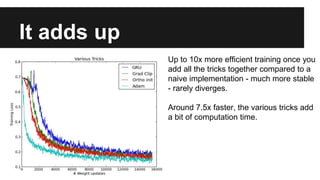
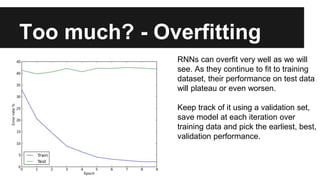
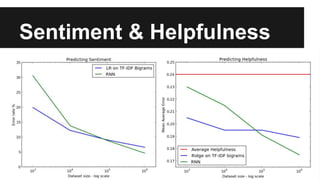
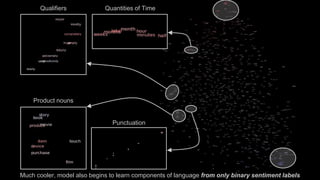
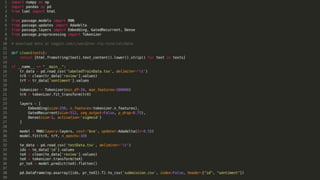
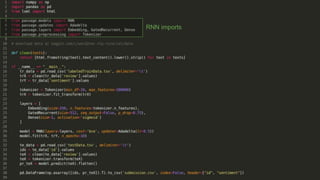
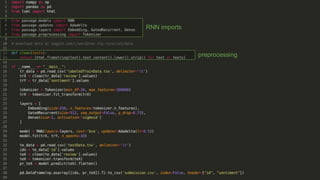
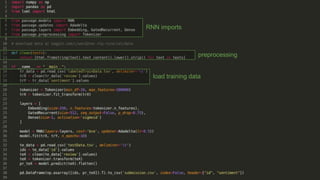
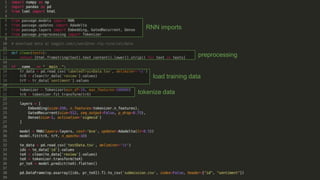
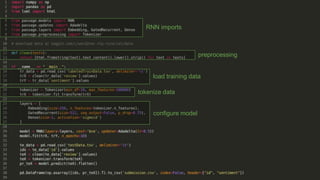
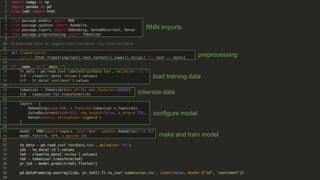
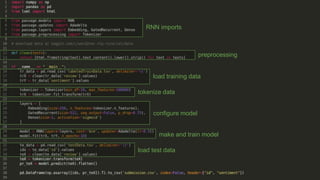
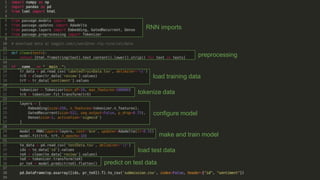
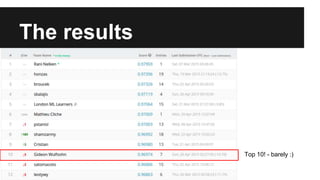
Recurrent neural networks (RNNs) are well-suited for analyzing text data because they can model sequential and structural relationships in text. RNNs use gating mechanisms like LSTMs and GRUs to address the problem of exploding or vanishing gradients when training on long sequences. Modern RNNs trained with techniques like gradient clipping, improved initialization, and optimized training algorithms like Adam can learn meaningful representations from text even with millions of training examples. RNNs may outperform conventional bag-of-words models on large datasets but require significant computational resources. The author describes an RNN library called Passage and provides an example of sentiment analysis on movie reviews to demonstrate RNNs for text analysis.
























































![_Deep learning in python Trustworthy [RNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythonrnn-251207084551-1fa069f9-thumbnail.jpg?width=640&height=640&fit=bounds)





















































