Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kohta Ishikawa
PDF, PPTX
102,130 views
Introduction to statistics
計算手法の詳細を割愛し、統計学の目的や考え方のイメージを理解することに重点を置いた、統計学初級者向け資料
Technology
◦
Read more
72
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 47
2
/ 47
3
/ 47
4
/ 47
5
/ 47
6
/ 47
7
/ 47
8
/ 47
9
/ 47
10
/ 47
11
/ 47
12
/ 47
13
/ 47
14
/ 47
15
/ 47
16
/ 47
17
/ 47
18
/ 47
19
/ 47
20
/ 47
21
/ 47
22
/ 47
23
/ 47
24
/ 47
25
/ 47
26
/ 47
27
/ 47
28
/ 47
29
/ 47
30
/ 47
31
/ 47
32
/ 47
33
/ 47
34
/ 47
35
/ 47
36
/ 47
37
/ 47
38
/ 47
39
/ 47
40
/ 47
41
/ 47
42
/ 47
43
/ 47
44
/ 47
45
/ 47
46
/ 47
47
/ 47
More Related Content
PDF
PRML輪読#2
by
matsuolab
PDF
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
by
Preferred Networks
PDF
ベータ分布の謎に迫る
by
Ken'ichi Matsui
PPTX
「操作変数法」の報告事例
by
Yoshitake Takebayashi
PDF
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
因果推論の基礎
by
Hatsuru Morita
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PRML輪読#2
by
matsuolab
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
by
Preferred Networks
ベータ分布の謎に迫る
by
Ken'ichi Matsui
「操作変数法」の報告事例
by
Yoshitake Takebayashi
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
因果推論の基礎
by
Hatsuru Morita
機械学習のためのベイズ最適化入門
by
hoxo_m
What's hot
PDF
統計的因果推論勉強会 第1回
by
Hikaru GOTO
PDF
【博士論文発表会】パラメータ制約付き特異モデルの統計的学習理論
by
Naoki Hayashi
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
PPTX
ベイズ最適化によるハイパラーパラメータ探索
by
西岡 賢一郎
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PDF
統計的学習の基礎 5章前半(~5.6)
by
Kota Mori
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PPTX
強化学習における好奇心
by
Shota Imai
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PPTX
WAICとWBICのご紹介
by
Tomoki Matsumoto
PDF
計量時系列分析の立場からビジネスの現場のデータを見てみよう - 30th Tokyo Webmining
by
Takashi J OZAKI
PDF
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
by
Deep Learning JP
PDF
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
PPTX
【DL輪読会】Generative models for molecular discovery: Recent advances and challenges
by
Deep Learning JP
PPTX
ベイズ統計モデリングと心理学
by
Shushi Namba
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PPTX
統計的学習の基礎_3章
by
Shoichi Taguchi
PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
統計的因果推論勉強会 第1回
by
Hikaru GOTO
【博士論文発表会】パラメータ制約付き特異モデルの統計的学習理論
by
Naoki Hayashi
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
ベイズ最適化によるハイパラーパラメータ探索
by
西岡 賢一郎
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
統計的学習の基礎 5章前半(~5.6)
by
Kota Mori
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
強化学習における好奇心
by
Shota Imai
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
WAICとWBICのご紹介
by
Tomoki Matsumoto
計量時系列分析の立場からビジネスの現場のデータを見てみよう - 30th Tokyo Webmining
by
Takashi J OZAKI
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
by
Deep Learning JP
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
【DL輪読会】Generative models for molecular discovery: Recent advances and challenges
by
Deep Learning JP
ベイズ統計モデリングと心理学
by
Shushi Namba
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
統計的学習の基礎_3章
by
Shoichi Taguchi
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
Viewers also liked
PDF
はじめての「R」
by
Masahiro Hayashi
PDF
RをAWSで使おう
by
Tohru Kobayashi
PPTX
リハビリテーションと人工知能
by
djyoshiro
PDF
そろそろRStudioの話
by
Kazuya Wada
PDF
人工知能のための哲学塾 第零夜「概観」 資料 (全五夜+第零夜)
by
Youichiro Miyake
PDF
10分で分かるr言語入門ver2.5
by
Nobuaki Oshiro
はじめての「R」
by
Masahiro Hayashi
RをAWSで使おう
by
Tohru Kobayashi
リハビリテーションと人工知能
by
djyoshiro
そろそろRStudioの話
by
Kazuya Wada
人工知能のための哲学塾 第零夜「概観」 資料 (全五夜+第零夜)
by
Youichiro Miyake
10分で分かるr言語入門ver2.5
by
Nobuaki Oshiro
Similar to Introduction to statistics
PDF
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
PDF
ベイズ入門
by
Zansa
PPTX
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PDF
確率統計-機械学習その前に v2.0
by
Hidekatsu Izuno
PDF
ベイズ統計入門
by
Miyoshi Yuya
PDF
PRML セミナー
by
sakaguchi050403
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
みどりぼん読書会 第4章
by
Masanori Takano
PDF
ma99992010id512
by
matsushimalab
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PPTX
model selection and information criteria part 1
by
Masafumi Enomoto
PDF
Oshasta em
by
Naotaka Yamada
PDF
PRML chap.10 latter half
by
Narihira Takuya
PDF
PRML2.1 2.2
by
Takuto Kimura
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PDF
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
PDF
3.4
by
show you
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
ベイズ入門
by
Zansa
Prml 1.3~1.6 ver3
by
Toshihiko Iio
確率統計-機械学習その前に v2.0
by
Hidekatsu Izuno
ベイズ統計入門
by
Miyoshi Yuya
PRML セミナー
by
sakaguchi050403
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
みどりぼん読書会 第4章
by
Masanori Takano
ma99992010id512
by
matsushimalab
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
model selection and information criteria part 1
by
Masafumi Enomoto
Oshasta em
by
Naotaka Yamada
PRML chap.10 latter half
by
Narihira Takuya
PRML2.1 2.2
by
Takuto Kimura
ベイズ統計学の概論的紹介
by
Naoki Hayashi
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
3.4
by
show you
Stanコードの書き方 中級編
by
Hiroshi Shimizu
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
More from Kohta Ishikawa
PDF
[Paper reading] Hamiltonian Neural Networks
by
Kohta Ishikawa
PDF
Spherical CNNs paper reading
by
Kohta Ishikawa
PDF
Model Transport: Towards Scalable Transfer Learning on Manifolds 論文紹介
by
Kohta Ishikawa
PDF
A brief explanation of Causal Entropic Forces
by
Kohta Ishikawa
PDF
量子アニーリング解説 1
by
Kohta Ishikawa
PDF
R Language Definition 2.2 to 2.3
by
Kohta Ishikawa
PDF
Nonlinear Filtering and Path Integral Method (Paper Review)
by
Kohta Ishikawa
PDF
Introduction to pairtrading
by
Kohta Ishikawa
PDF
Particle Filter Tracking in Python
by
Kohta Ishikawa
PDF
Rでisomap(多様体学習のはなし)
by
Kohta Ishikawa
PPT
PRML_2.3.1~2.3.3
by
Kohta Ishikawa
[Paper reading] Hamiltonian Neural Networks
by
Kohta Ishikawa
Spherical CNNs paper reading
by
Kohta Ishikawa
Model Transport: Towards Scalable Transfer Learning on Manifolds 論文紹介
by
Kohta Ishikawa
A brief explanation of Causal Entropic Forces
by
Kohta Ishikawa
量子アニーリング解説 1
by
Kohta Ishikawa
R Language Definition 2.2 to 2.3
by
Kohta Ishikawa
Nonlinear Filtering and Path Integral Method (Paper Review)
by
Kohta Ishikawa
Introduction to pairtrading
by
Kohta Ishikawa
Particle Filter Tracking in Python
by
Kohta Ishikawa
Rでisomap(多様体学習のはなし)
by
Kohta Ishikawa
PRML_2.3.1~2.3.3
by
Kohta Ishikawa
Introduction to statistics
1.
統計学入門 全体像のイメージ的な理解を目指して
2010年10月4日 石川康太 (ISHIKAWA Kohta) Twitter: @_kohta quantumcorgi_at_gmail.com 1
2.
ご注意 • この資料は個人的な知識をまとめたものです。作成者
の所属する組織とは一切関わりの無いものです。 • 内容は正確なものとなるよう努力していますが、作成 者の不勉強が無いとは言い切れません。不正確な内 容の発生、および本資料の内容を用いたことによるい かなる損害についても、作成者はその責任を負いませ ん。 • おかしな点や、改善点など、お気づきの際にはご指摘 いただけると幸いです。 2
3.
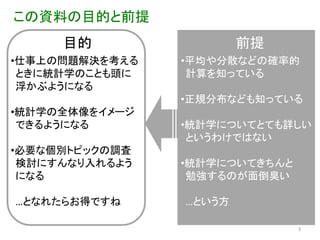
この資料の目的と前提
目的 前提 •仕事上の問題解決を考える •平均や分散などの確率的 ときに統計学のことも頭に 計算を知っている 浮かぶようになる •正規分布なども知っている •統計学の全体像をイメージ できるようになる •統計学についてとても詳しい というわけではない •必要な個別トピックの調査 検討にすんなり入れるよう •統計学についてきちんと になる 勉強するのが面倒臭い …となれたらお得ですね …という方 3
4.
概要 • 統計学とは何か? –
統計学が扱う問題とその目的 • 確率モデルとパラメータ – 統計学の基本的な道具とその使い方 • 回帰分析 – よく用いられるモデルとしての実例 • 検定 – 統計的検定の考え方 • モデル選択 – より進んだトピックとして • ベイズ統計学の初歩 – 頻度主義統計学とは異なる世界を覗く 4
5.
•
統計学とは何か? • 確率モデルとパラメータ • 回帰分析 • 検定 • モデル選択 • ベイズ統計学の初歩 5
6.
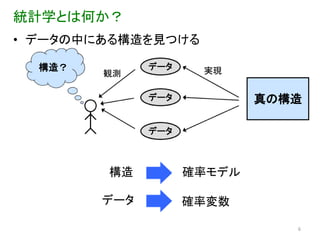
統計学とは何か? • データの中にある構造を見つける
構造? データ 実現 観測 データ 真の構造 データ 構造 確率モデル データ 確率変数 6
7.
統計学とは何か? • ランダムな現象をモデル化 –
ノイズがある – 非決定論的な現象 不確実性のモデル化 – 現象の背景がよくわからない 真の構造に近いと思われる確率モデルを 想定してデータに合わせ込む 統計学がやっているのはほとんどこれだけ (だと思います) 7
8.
• 統計学とは何か? • 確率モデルとパラメータ
– 確率モデル – 具体例 ~歪んだコイン投げ – パラメータの推定量とその性質 – 最尤法(推定量の構成) – 歪んだコイン投げの最尤推定 • 回帰分析 • 検定 • モデル選択 • ベイズ統計学の初歩 8
9.
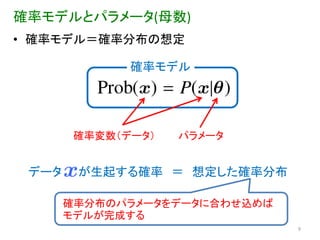
確率モデルとパラメータ(母数) • 確率モデル=確率分布の想定
確率モデル 確率変数(データ) パラメータ データ が生起する確率 = 想定した確率分布 確率分布のパラメータをデータに合わせ込めば モデルが完成する 9
10.
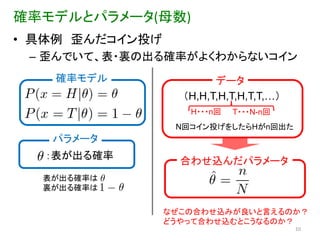
確率モデルとパラメータ(母数) • 具体例 歪んだコイン投げ
– 歪んでいて、表・裏の出る確率がよくわからないコイン 確率モデル データ (H,H,T,H,T,H,T,T,…) H・・・n回 T・・・N-n回 N回コイン投げをしたらHがn回出た パラメータ :表が出る確率 合わせ込んだパラメータ 表が出る確率は 裏が出る確率は なぜこの合わせ込みが良いと言えるのか? どうやって合わせ込むとこうなるのか? 10
11.
確率モデルとパラメータ(母数) • 推定量とその性質
推定量 データXを使って真のパラメータ値θを推定したもの はデータXの関数 データの具体的な値による になったら嬉しい データは確率変数 も確率変数! 確率変数としての の 性質を調べる必要がある の平均や分散を知りたい 11
12.
確率モデルとパラメータ(母数) • 具体例 歪んだコイン投げの推定量
:明らかにnの確率分布を考えれば良い 平均が真のパラメータ値 に一致 平均 不偏推定量 平均が真のパラメータ値に等しくなる推定量 (unbiased estimator) 推定したい各パラメータについて、不偏推定量を見つける ことができれば、データから偏りの無い推定ができる ・実際に不偏推定量を見つけるのは簡単ではない。 ・近似的不偏性で我慢することも多い。 12
13.
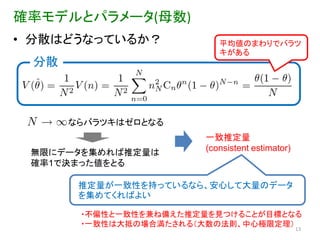
確率モデルとパラメータ(母数) • 分散はどうなっているか?
平均値のまわりでバラツ キがある 分散 ならバラツキはゼロとなる 一致推定量 無限にデータを集めれば推定量は (consistent estimator) 確率1で決まった値をとる 推定量が一致性を持っているなら、安心して大量のデータ を集めてくればよい ・不偏性と一致性を兹ね備えた推定量を見つけることが目標となる ・一致性は大抵の場合満たされる(大数の法則、中心極限定理) 13
14.
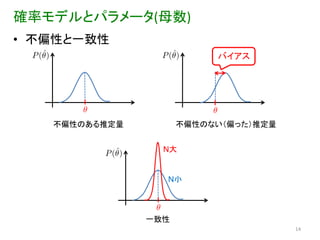
確率モデルとパラメータ(母数) • 不偏性と一致性
バイアス 不偏性のある推定量 不偏性のない(偏った)推定量 N大 N小 一致性 14
15.
確率モデルとパラメータ(母数) • 不偏推定量の分散の性質 –
一般に、推定量の分散は小さければ小さいほど良い • 分散が小さいなら真のパラメータからのズレが小さい – ところが、一般に不偏推定量の分散は一定の下限値よ り小さくすることができない(データ数固定の場合) クラメール・ラオの下限 データXが与えられたとき、不偏推定量の分散について次の不等式が成り立つ 不偏推定量の中で最も分散が小さいもの 最小分散不偏推定量 15
16.
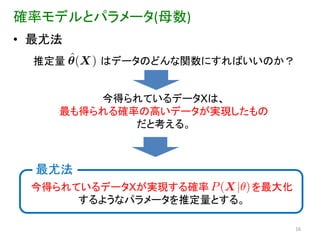
確率モデルとパラメータ(母数) • 最尤法
推定量 はデータのどんな関数にすればいいのか? 今得られているデータXは、 最も得られる確率の高いデータが実現したもの だと考える。 最尤法 今得られているデータXが実現する確率 を最大化 するようなパラメータを推定量とする。 16
17.
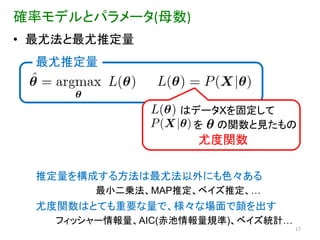
確率モデルとパラメータ(母数) • 最尤法と最尤推定量
最尤推定量 はデータXを固定して を の関数と見たもの 尤度関数 推定量を構成する方法は最尤法以外にも色々ある 最小二乗法、MAP推定、ベイズ推定、… 尤度関数はとても重要な量で、様々な場面で顔を出す フィッシャー情報量、AIC(赤池情報量規準)、ベイズ統計… 17
18.
確率モデルとパラメータ(母数) • 具体例 歪んだコイン投げの最尤推定量
データ X=(H,H,T,H,T,H,T,T,…) が起こる確率 (Hがn回出た場合) これを で微分してゼロと置くと… 最尤推定量 直観的な推定量と同じものが得られる 18
19.
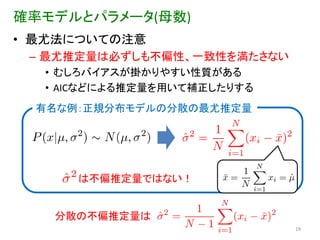
確率モデルとパラメータ(母数) • 最尤法についての注意 –
最尤推定量は必ずしも不偏性、一致性を満たさない • むしろバイアスが掛かりやすい性質がある • AICなどによる推定量を用いて補正したりする 有名な例:正規分布モデルの分散の最尤推定量 は不偏推定量ではない! 分散の不偏推定量は 19
20.
• 統計学とは何か? • 確率モデルとパラメータ •
回帰分析 – 回帰分析と線形モデル – 最小二乗法について • 検定 • モデル選択 • ベイズ統計学の初歩 20
21.
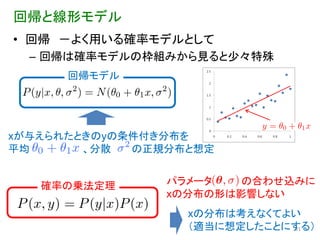
回帰と線形モデル • 回帰 -よく用いる確率モデルとして
– 回帰は確率モデルの枠組みから見ると少々特殊 回帰モデル xが与えられたときのyの条件付き分布を 平均 、分散 の正規分布と想定 確率の乗法定理 パラメータ の合わせ込みに xの分布の形は影響しない xの分布は考えなくてよい (適当に想定したことにする) 21
22.
回帰と線形モデル • 何が線形? –
パラメータについて線形 • xについては線形でなくてもよい 全て線形モデル! これを一般化するとカーネル法と呼ばれる一連の手法に繋がる データについて非線形な構造を処理する一般的な方法 カーネル多変量解析、非線形SVM(カーネルマシン)、etc… 22
23.
回帰と線形モデル • 最小二乗法と最小二乗推定量
最小二乗法 について非線形な場合は の関数 となる。 – 最小二乗推定量は線形モデルなら最尤推定量に一致 – 最小分散不偏推定量になっている – パラメータの任意の線形結合 について、 は最小分散不偏推定量(ガウス・マルコフの定理) 23
24.
•
統計学とは何か? • 確率モデルとパラメータ • 回帰分析 • 検定 – 検定とは何か?(推定と検定の違い) – 帰無仮説と対立仮説 – 検定のイメージ – 検定統計量の構成 • モデル選択 • ベイズ統計学の初歩 24
25.
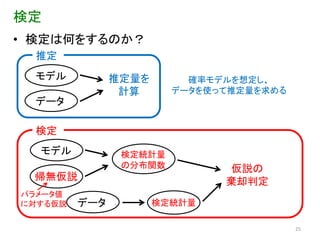
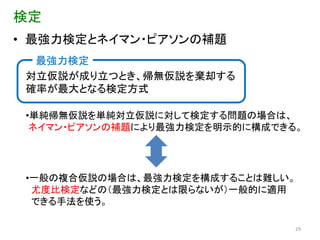
検定 • 検定は何をするのか?
推定 モデル 推定量を 確率モデルを想定し、 計算 データを使って推定量を求める データ 検定 モデル 検定統計量 の分布関数 仮説の 帰無仮説 棄却判定 パラメータ値 に対する仮説 データ 検定統計量 25
26.
検定 • 検定における帰無仮説と対立仮説 帰無仮説
正しいのかどうかを確かめたい仮説 対立仮説 帰無仮説が正しくない時に成り立つ仮説 パラメータの1点を定める仮説:単純仮説 一般の複合仮説では、検定が 複雑になったり発見的な手段を パラメータの範囲を定める仮説:複合仮説 用いる必要があったりする。 ・帰無仮説が正しいときに対立仮説を採択する誤り 第1種の誤り ・対立仮説が正しいときに帰無仮説を採択する誤り 第2種の誤り 第1種の誤りの確率を一定以下に抑えつつ、第2種の誤りの確率を最小化したい 26
27.
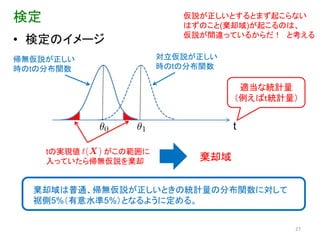
検定
仮説が正しいとするとまず起こらない はずのこと(棄却域)が起こるのは、 仮説が間違っているからだ! と考える • 検定のイメージ 帰無仮説が正しい 対立仮説が正しい 時のtの分布関数 時のtの分布関数 適当な統計量 (例えばt統計量) t tの実現値 がこの範囲に 入っていたら帰無仮説を棄却 棄却域 棄却域は普通、帰無仮説が正しいときの統計量の分布関数に対して 裾側5%(有意水準5%)となるように定める。 27
28.
検定 • 検定統計量の構成 検定統計量の例:t統計量
分散未知の正規分布における平均値パラメータの検定 (μ0は平均パラメータの帰無仮説) tは自由度(N-1)のt分布に従うことが分かっている t分布に基づく検定を構成することができる – 検定統計量の構成方法は無数にある – どの統計量を使うかで検定の良さ(検出力)が変わる 28
29.
検定 • 最強力検定とネイマン・ピアソンの補題
最強力検定 対立仮説が成り立つとき、帰無仮説を棄却する 確率が最大となる検定方式 •単純帰無仮説を単純対立仮説に対して検定する問題の場合は、 ネイマン・ピアソンの補題により最強力検定を明示的に構成できる。 •一般の複合仮説の場合は、最強力検定を構成することは難しい。 尤度比検定などの(最強力検定とは限らないが)一般的に適用 できる手法を使う。 29
30.
•
統計学とは何か? • 確率モデルとパラメータ • 回帰分析 • 検定 • モデル選択 – 回帰モデルの例 – 最尤法の限界 – AIC(赤池情報量規準) • ベイズ統計学の初歩 30
31.
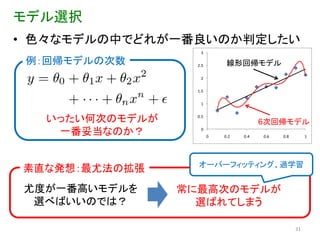
モデル選択 • 色々なモデルの中でどれが一番良いのか判定したい
3 例:回帰モデルの次数 2.5 線形回帰モデル 2 1.5 1 いったい何次のモデルが 0.5 6次回帰モデル 一番妥当なのか? 0 0 0.2 0.4 0.6 0.8 1 オーバーフィッティング、過学習 素直な発想:最尤法の拡張 尤度が一番高いモデルを 常に最高次のモデルが 選べばいいのでは? 選ばれてしまう 31
32.
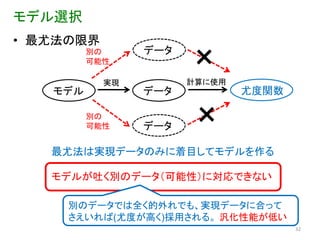
モデル選択 • 最尤法の限界
別の 可能性 データ × 実現 計算に使用 モデル データ 尤度関数 別の 可能性 データ × 最尤法は実現データのみに着目してモデルを作る モデルが吐く別のデータ(可能性)に対応できない 別のデータでは全く的外れでも、実現データに合って さえいれば(尤度が高く)採用される。 汎化性能が低い 32
33.
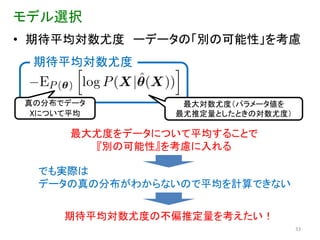
モデル選択 • 期待平均対数尤度 ーデータの「別の可能性」を考慮
期待平均対数尤度 真の分布でデータ 最大対数尤度(パラメータ値を Xについて平均 最尤推定量としたときの対数尤度) 最大尤度をデータについて平均することで 『別の可能性』を考慮に入れる でも実際は データの真の分布がわからないので平均を計算できない 期待平均対数尤度の不偏推定量を考えたい! 33
34.
モデル選択 • AIC(赤池情報量規準) -最尤法のバイアス補正 実データを用いた最大対数尤度と期待平均対数尤度の間の バイアスを近似的に計算することができる
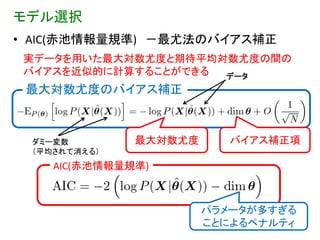
データ 最大対数尤度のバイアス補正 ダミー変数 最大対数尤度 バイアス補正項 (平均されて消える) AIC(赤池情報量規準) パラメータが多すぎる ことによるペナルティ 34
35.
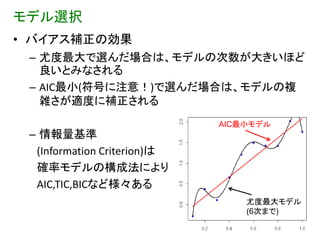
モデル選択 • バイアス補正の効果 –
尤度最大で選んだ場合は、モデルの次数が大きいほど 良いとみなされる – AIC最小(符号に注意!)で選んだ場合は、モデルの複 雑さが適度に補正される AIC最小モデル – 情報量基準 (Information Criterion)は 確率モデルの構成法により AIC,TIC,BICなど様々ある 尤度最大モデル (6次まで) 35
36.
•
統計学とは何か? • 確率モデルとパラメータ • 回帰分析 • 検定 • モデル選択 • ベイズ統計学の初歩 作成者の力量不足により、ベイズの – ベイズ統計学とは? 項目については表面的な色彩がより 強いものとなっています。 – ベイズの定理と事前分布 至らない点など、ご指摘頂ければ – ベイズ推定 幸いです。 36
37.
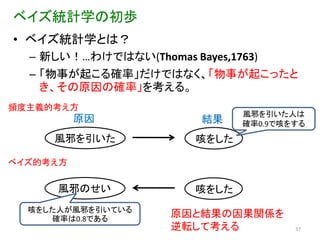
ベイズ統計学の初歩 • ベイズ統計学とは?
– 新しい!…わけではない(Thomas Bayes,1763) – 「物事が起こる確率」だけではなく、「物事が起こったと き、その原因の確率」を考える。 頻度主義的考え方 風邪を引いた人は 原因 結果 確率0.9で咳をする 風邪を引いた 咳をした ベイズ的考え方 風邪のせい 咳をした 咳をした人が風邪を引いている 確率は0.8である 原因と結果の因果関係を 逆転して考える 37
38.
ベイズ統計学の初歩 • 典型的な疑問点 –
風邪かどうかはもう決まっているので、確率も何もない んじゃないか? • (確率1で断定できるような)十分な情報があればその通り です。 • 不確実性(確率)と不完全情報(情報が足りない)を同じ に扱うという考え方です。(主観確率) – 最尤法と同じじゃない?(「結果データが起こる確率」に 着目) • 適当な前提の下で同じです。(事前分布が定数) 38
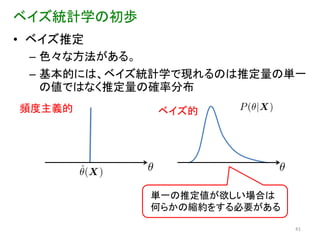
39.
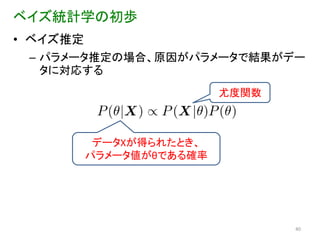
ベイズ統計学の初歩
: • ベイズの定理と事前分布 Aが起こったという条件の下で Bが起こる条件付き確率 ベイズの定理 原因(A)と結果(B)を入れ換えることができる ただし、原因Aの確率分布 を知らなければならない 事前分布 事前分布は観察前に持っている経験や情報、信念を反映 ・「経験的に、この人は0.3の確率で風邪を引いていそうだ」 ・「情報が無いのでこのメールがSPAMかどうかは五分五分だ」39
40.
ベイズ統計学の初歩 • ベイズ推定 –
パラメータ推定の場合、原因がパラメータで結果がデー タに対応する 尤度関数 データXが得られたとき、 パラメータ値がθである確率 40
41.
ベイズ統計学の初歩 • ベイズ推定 –
色々な方法がある。 – 基本的には、ベイズ統計学で現れるのは推定量の単一 の値ではなく推定量の確率分布 頻度主義的 ベイズ的 単一の推定値が欲しい場合は 何らかの縮約をする必要がある 41
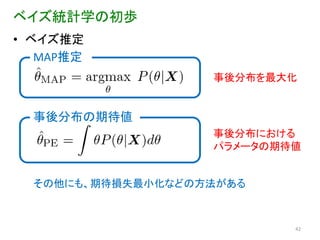
42.
ベイズ統計学の初歩 • ベイズ推定
MAP推定 事後分布を最大化 事後分布の期待値 事後分布における パラメータの期待値 その他にも、期待損失最小化などの方法がある 42
43.
ベイズ統計学の初歩 • ベイズ的な考え方は何が嬉しいのか? –
モデルの不確実性を直接扱うことができる • パラメータの(事前、事後)分布が不確実性を表現 – 柔軟なモデリングが可能 • 階層ベイズモデルなどを用いることで、より直観をストレ ートにモデル化することができる(参考文献を参照) • ベイズ的な考え方の問題点 – どこかで必ず事前分布を恣意的に決めなければならな い(無情報量事前分布とかもあるが…) – 計算が難しくなりがち • ベイズの定理を用いる際に本質的に高次元の多重積分 が必要になる …その他にも諸説があります 43
44.
まとめ • 統計学の基本的な考え方と、少しアドバンストなトピッ
クを眺めました。 • 実際は個々の項目について非常に複雑な発展的内容 があるものの、基本を押さえておけば何とか追える… んじゃないかと思います。 • 確率過程や時系列解析、学習理論、情報理論との関 連など、ここでは全く触れなかった分野もたくさんあり ます。 – でも基本は同じです! 確率モデルを考えて、データに合わせ込む 44
45.
参考文献 • 統計学全般 –
入門統計学/共立出版 • 学部1年の講義で買わされたもの。改めて読むと意外とわかりやす い。初心者向け。ネイマン・ピアソン流の古典統計学で、ベイズ的なト ピックはない。 – キーポイント確率・統計/岩波書店 • わかりやすいが範囲は基本的な内容のみで広くない。その割に中心 極限定理の証明が載っていたりする。 – 自然科学の統計学/東京大学出版会 • 記述は難しめだが、広範で深い記述。実験データ分析のトピックもあ り実戦的(たぶん)。 – 入門数理統計学/培風館 • 統計学の理論的な背景をきちんと書いている割に、同様の他書に比 べわかりやすい。部分的にしか読んでいない。 45
46.
参考文献 • モデル選択 –
統計科学のフロンティア3「モデル選択」/岩波書店 • 情報量規準に基づくモデル選択がわかりやすい。後半はより情報理 論的な話が書いてある(と思われる)。 – 情報量統計学/共立出版 • モデル選択とその周辺。古い本だが、普通の本にはあまり載ってい ないことが書いてあって面白い(と思う)。 – Model Selection and Multi-Model Inference/Springer • 情報量規準と尤度比検定など、どういう状況で何を使うべきか、実践 的な基礎が書いてある(らしい)。 • 多変量解析 – 統計科学のフロンティア1「統計学の基礎」 • 多変量解析が簡潔にまとまっている。「統計学の基礎」とは言い難い が…。 46
47.
参考文献 – カーネル多変量解析/岩波書店
• カーネル法を用いて非線形系に拡張された多変量解析の本。わかり やすいらしい。 • ベイズ統計学 – 統計科学のフロンティア4「階層ベイズモデルとその周辺」 • ベイズモデルの便利さがわかりやすく理解できる。 • 数値計算 – 統計科学のフロンティア12「計算統計2 マルコフ連鎖モンテ カルロ法とその周辺」 • サンプリングなどの数値的な手法が詳しく載っている。語り口が面白 い。 47
Download














































![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper reading] Hamiltonian Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/hamiltoniannn-200131102421-thumbnail.jpg?width=640&height=640&fit=bounds)









