Download to read offline






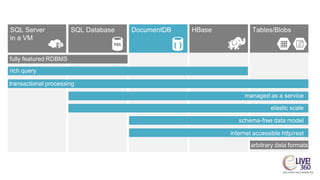

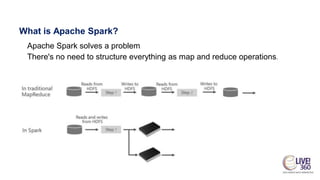




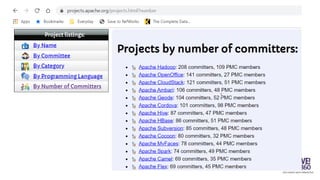




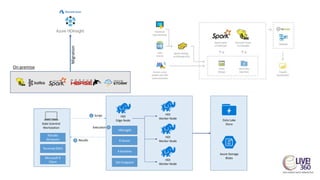
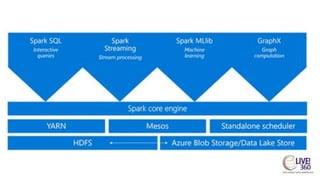


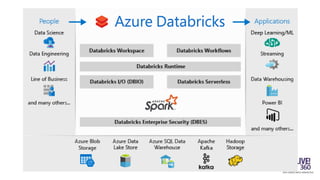



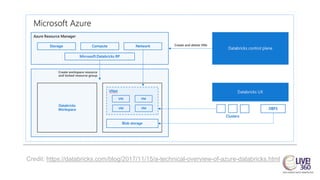
















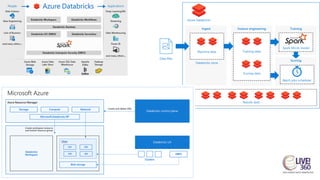


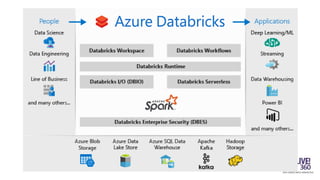



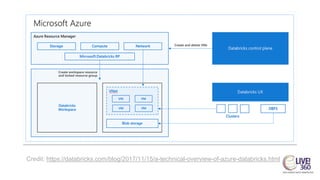
















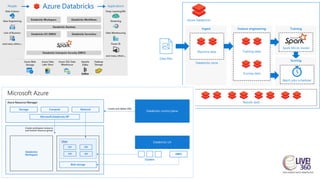

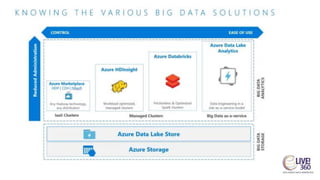
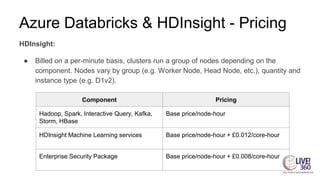
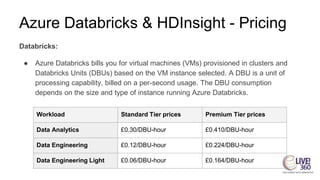








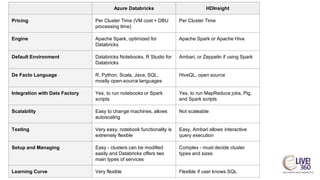
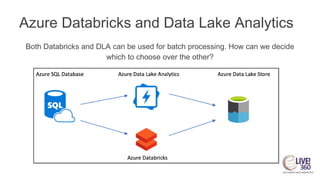


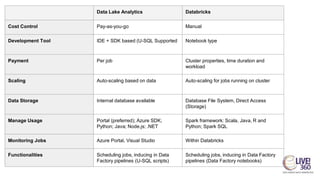


The document provides an overview of big data technologies, focusing on Apache Spark and Azure Databricks. It highlights the capabilities of these platforms for processing large datasets, real-time analytics, and machine learning integration, while also discussing their cost efficiencies and features. The document compares Databricks with HDInsight, emphasizing Databricks' user-friendly interface and collaborative environment, as well as details about pricing and performance.






















































































