Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
itoyan110
PDF, PPTX
29,544 views
Rで実験計画法 前編
This slide was presented in Tokyo.R #16.It describes about design of experiment with R.
Technology
◦
Read more
37
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 39
2
/ 39
3
/ 39
4
/ 39
5
/ 39
6
/ 39
7
/ 39
Most read
8
/ 39
9
/ 39
10
/ 39
11
/ 39
12
/ 39
13
/ 39
14
/ 39
15
/ 39
16
/ 39
17
/ 39
18
/ 39
19
/ 39
20
/ 39
21
/ 39
22
/ 39
23
/ 39
24
/ 39
25
/ 39
26
/ 39
27
/ 39
28
/ 39
29
/ 39
Most read
30
/ 39
31
/ 39
32
/ 39
33
/ 39
34
/ 39
35
/ 39
36
/ 39
37
/ 39
Most read
38
/ 39
39
/ 39
More Related Content
PDF
Rで実験計画法 後編
by
itoyan110
PDF
実験計画法入門 Part 2
by
haji mizu
PDF
20130716 はじパタ3章前半 ベイズの識別規則
by
koba cky
PDF
科学と機械学習のあいだ:変量の設計・変換・選択・交互作用・線形性
by
Ichigaku Takigawa
PPTX
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
PPTX
連続変量を含む条件付相互情報量の推定
by
Joe Suzuki
PDF
Stan超初心者入門
by
Hiroshi Shimizu
Rで実験計画法 後編
by
itoyan110
実験計画法入門 Part 2
by
haji mizu
20130716 はじパタ3章前半 ベイズの識別規則
by
koba cky
科学と機械学習のあいだ:変量の設計・変換・選択・交互作用・線形性
by
Ichigaku Takigawa
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
連続変量を含む条件付相互情報量の推定
by
Joe Suzuki
Stan超初心者入門
by
Hiroshi Shimizu
What's hot
PDF
実験計画法入門 Part 4
by
haji mizu
PDF
MLaPP 5章 「ベイズ統計学」
by
moterech
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
DOCX
マハラノビス距離とユークリッド距離の違い
by
wada, kazumi
PDF
基礎からのベイズ統計学 輪読会資料 第1章 確率に関するベイズの定理
by
Ken'ichi Matsui
PDF
ベイズ統計入門
by
Miyoshi Yuya
ZIP
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
PDF
ベイズモデリングと仲良くするために
by
Shushi Namba
PDF
MCMCサンプルの使い方 ~見る・決める・探す・発生させる~
by
. .
PDF
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
PDF
多重代入法の書き方 公開用
by
Koichiro Gibo
PDF
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
PDF
Chapter7 回帰分析の悩みどころ
by
itoyan110
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
比例ハザードモデルはとってもtricky!
by
takehikoihayashi
PDF
Stanの便利な事後処理関数
by
daiki hojo
PPTX
重回帰分析で交互作用効果
by
Makoto Hirakawa
PDF
決定木学習
by
Mitsuo Shimohata
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
実験計画法入門 Part 4
by
haji mizu
MLaPP 5章 「ベイズ統計学」
by
moterech
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
マハラノビス距離とユークリッド距離の違い
by
wada, kazumi
基礎からのベイズ統計学 輪読会資料 第1章 確率に関するベイズの定理
by
Ken'ichi Matsui
ベイズ統計入門
by
Miyoshi Yuya
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
ベイズモデリングと仲良くするために
by
Shushi Namba
MCMCサンプルの使い方 ~見る・決める・探す・発生させる~
by
. .
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
多重代入法の書き方 公開用
by
Koichiro Gibo
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
Chapter7 回帰分析の悩みどころ
by
itoyan110
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
階層モデルの分散パラメータの事前分布について
by
hoxo_m
比例ハザードモデルはとってもtricky!
by
takehikoihayashi
Stanの便利な事後処理関数
by
daiki hojo
重回帰分析で交互作用効果
by
Makoto Hirakawa
決定木学習
by
Mitsuo Shimohata
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
Similar to Rで実験計画法 前編
PDF
統計学の基礎の基礎
by
Ken'ichi Matsui
PDF
R Study Tokyo03
by
Yohei Sato
PDF
一般化線形混合モデル isseing333
by
Issei Kurahashi
PDF
外れ値
by
Shintaro Fukushima
PDF
Rによるデータサイエンス:12章「時系列」
by
Nagi Teramo
PDF
パターン認識02 k平均法ver2.0
by
sleipnir002
PPTX
13.01.20. 第1回DARM勉強会資料#4
by
Yoshitake Takebayashi
PDF
第1回R勉強会@東京
by
Yohei Sato
PPT
020 1変数の集計
by
t2tarumi
PDF
20130223_集計・分析の基礎@アンケート研究会
by
Takanori Hiroe
PPT
K070k80 点推定 区間推定
by
t2tarumi
PDF
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
PDF
Stat r 9_principal
by
fusion2011
PDF
ビジネス基礎講座:統計学入門 introduction to statistics
by
Masaaki Nabeshima
PPTX
第二回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
LET2015 National Conference Seminar
by
Mizumoto Atsushi
PPT
K030 appstat201203 2variable
by
t2tarumi
PDF
Tokyor24 doradora09
by
Nobuaki Oshiro
PPT
K020 appstat201202
by
t2tarumi
DOCX
Ⅱ. データ分析編 2017
by
wada, kazumi
統計学の基礎の基礎
by
Ken'ichi Matsui
R Study Tokyo03
by
Yohei Sato
一般化線形混合モデル isseing333
by
Issei Kurahashi
外れ値
by
Shintaro Fukushima
Rによるデータサイエンス:12章「時系列」
by
Nagi Teramo
パターン認識02 k平均法ver2.0
by
sleipnir002
13.01.20. 第1回DARM勉強会資料#4
by
Yoshitake Takebayashi
第1回R勉強会@東京
by
Yohei Sato
020 1変数の集計
by
t2tarumi
20130223_集計・分析の基礎@アンケート研究会
by
Takanori Hiroe
K070k80 点推定 区間推定
by
t2tarumi
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
Stat r 9_principal
by
fusion2011
ビジネス基礎講座:統計学入門 introduction to statistics
by
Masaaki Nabeshima
第二回統計学勉強会@東大駒場
by
Daisuke Yoneoka
LET2015 National Conference Seminar
by
Mizumoto Atsushi
K030 appstat201203 2variable
by
t2tarumi
Tokyor24 doradora09
by
Nobuaki Oshiro
K020 appstat201202
by
t2tarumi
Ⅱ. データ分析編 2017
by
wada, kazumi
More from itoyan110
PDF
絶対に描いてはいけないグラフ入りスライド24枚
by
itoyan110
PDF
データ解析のための統計モデリング入門 1~2章
by
itoyan110
PDF
Chapter9 一歩進んだ文法(前半)
by
itoyan110
PDF
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2021
by
itoyan110
PDF
2018年6月期 統計検定2級&準1級 対策スライド
by
itoyan110
PDF
Rで確認しながら解く統計検定2級
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2023
by
itoyan110
PDF
Reviewing Let's Note CF-FV3 (レッツノート CF-FV3 をレビューする)
by
itoyan110
PDF
レッツノートを業務用途にカスタマイズする
by
itoyan110
PDF
コイン投げの分析を一捻り (Japan.R 2013 LT)
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2017
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2018
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2019
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2024 (The graph on this IR is amazing! Listed companies in J...
by
itoyan110
PDF
NagoyaStat #5 ご挨拶と前回の復習
by
itoyan110
PDF
NagoyaStat #4 ご挨拶と前回の復習
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2016
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2015
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2020
by
itoyan110
絶対に描いてはいけないグラフ入りスライド24枚
by
itoyan110
データ解析のための統計モデリング入門 1~2章
by
itoyan110
Chapter9 一歩進んだ文法(前半)
by
itoyan110
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
このIRのグラフがすごい!上場企業2021
by
itoyan110
2018年6月期 統計検定2級&準1級 対策スライド
by
itoyan110
Rで確認しながら解く統計検定2級
by
itoyan110
このIRのグラフがすごい!上場企業2023
by
itoyan110
Reviewing Let's Note CF-FV3 (レッツノート CF-FV3 をレビューする)
by
itoyan110
レッツノートを業務用途にカスタマイズする
by
itoyan110
コイン投げの分析を一捻り (Japan.R 2013 LT)
by
itoyan110
このIRのグラフがすごい!上場企業2017
by
itoyan110
このIRのグラフがすごい!上場企業2018
by
itoyan110
このIRのグラフがすごい!上場企業2019
by
itoyan110
このIRのグラフがすごい!上場企業2024 (The graph on this IR is amazing! Listed companies in J...
by
itoyan110
NagoyaStat #5 ご挨拶と前回の復習
by
itoyan110
NagoyaStat #4 ご挨拶と前回の復習
by
itoyan110
このIRのグラフがすごい!上場企業2016
by
itoyan110
このIRのグラフがすごい!上場企業2015
by
itoyan110
このIRのグラフがすごい!上場企業2020
by
itoyan110
Recently uploaded
PDF
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
PDF
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
PDF
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
PDF
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
PPTX
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
Rで実験計画法 前編
1.
Rで実験計画法(前編) @ito_yan E-mail:1mail2itoh3@gmail.com
2011.08.27 Tokyo.R #16
2.
2 はじめに • 所属する組織の意見・見解ではありません • つまらなかったら睡眠学習や復習に当てましょう •
コメント歓迎します(メール等も含めて) • 僕と勉強会に出て、実験計画法使いになってよ! • Web上に掲載するに当たり一部修正しています
3.
3 自己紹介 • twitterID :
@ito_yan • お仕事 • QA(品質保証)がメイン • データマイニングツール開発 • Rに初めて触れて5年 • まどか☆マギカのアニメ版は観てません(爆 • 漫画版読みました(爆
4.
4 今日の話題 • 一元配置、二元配置 • 第3回でも出てきているが、1年半ぶりに復習 •
交互作用 • 二元配置と方格の関係 • ラテン方格、グレコ・ラテン方格 • 直交表による実験は次回お話します
5.
5 実験計画法とは • 少ない実験回数で、効率よく推定する手法 •
フィッシャーの農場での実験がはじまり • 肥料のやり方、土壌が作物の成長にどのような影響を与 えるか調べた • 応用例 • 品質管理(長寿命製品の製造) • 自然科学
6.
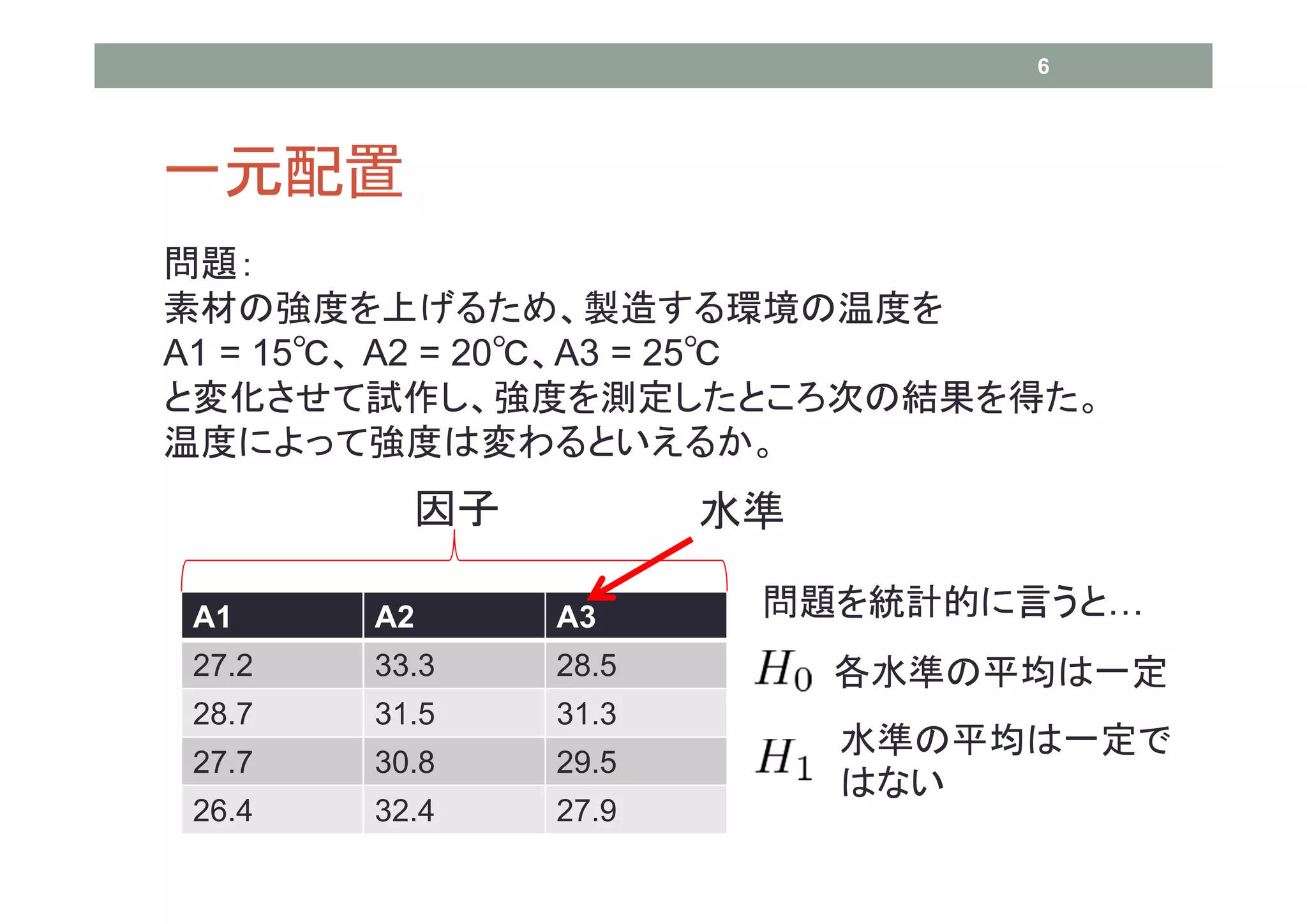
6 一元配置 問題: 素材の強度を上げるため、製造する環境の温度を A1 = 15℃、
A2 = 20℃、A3 = 25℃ と変化させて試作し、強度を測定したところ次の結果を得た。 温度によって強度は変わるといえるか。 因子 水準 A1 A2 A3 問題を統計的に言うと… 27.2 33.3 28.5 各水準の平均は一定 28.7 31.5 31.3 水準の平均は一定で 27.7 30.8 29.5 はない 26.4 32.4 27.9
7.
7 Rによる分析
lev data • データフレームでデータを表現 A1 27.2 data <- c(27.2,28.7,27.7,26.4, A1 28.7 33.3,31.5,30.8,32.4, A1 27.7 28.5,31.3,29.5,27.9) A1 26.4 lev <- c(rep("A1",4),rep("A2",4),rep("A3",4)) A2 33.3 exp.data <- data.frame(lev=lev,data=data) A2 31.5 A2 30.8 A2 32.4 A3 28.5 A3 31.3 A3 29.5 A3 27.9
8.
8 傾向の把握その1 • boxplot関数の利用 boxplot(data~lev,data=exp.data,col="lightblue")
左図より、水準ごとに平均 は違うのではと推測される 第3四分位点から箱の長さの1.5 倍以内の最大値 第3四分位点 中央値 第1分位点 第1四分位点から箱の長さの1.5 倍以内の最小値
9.
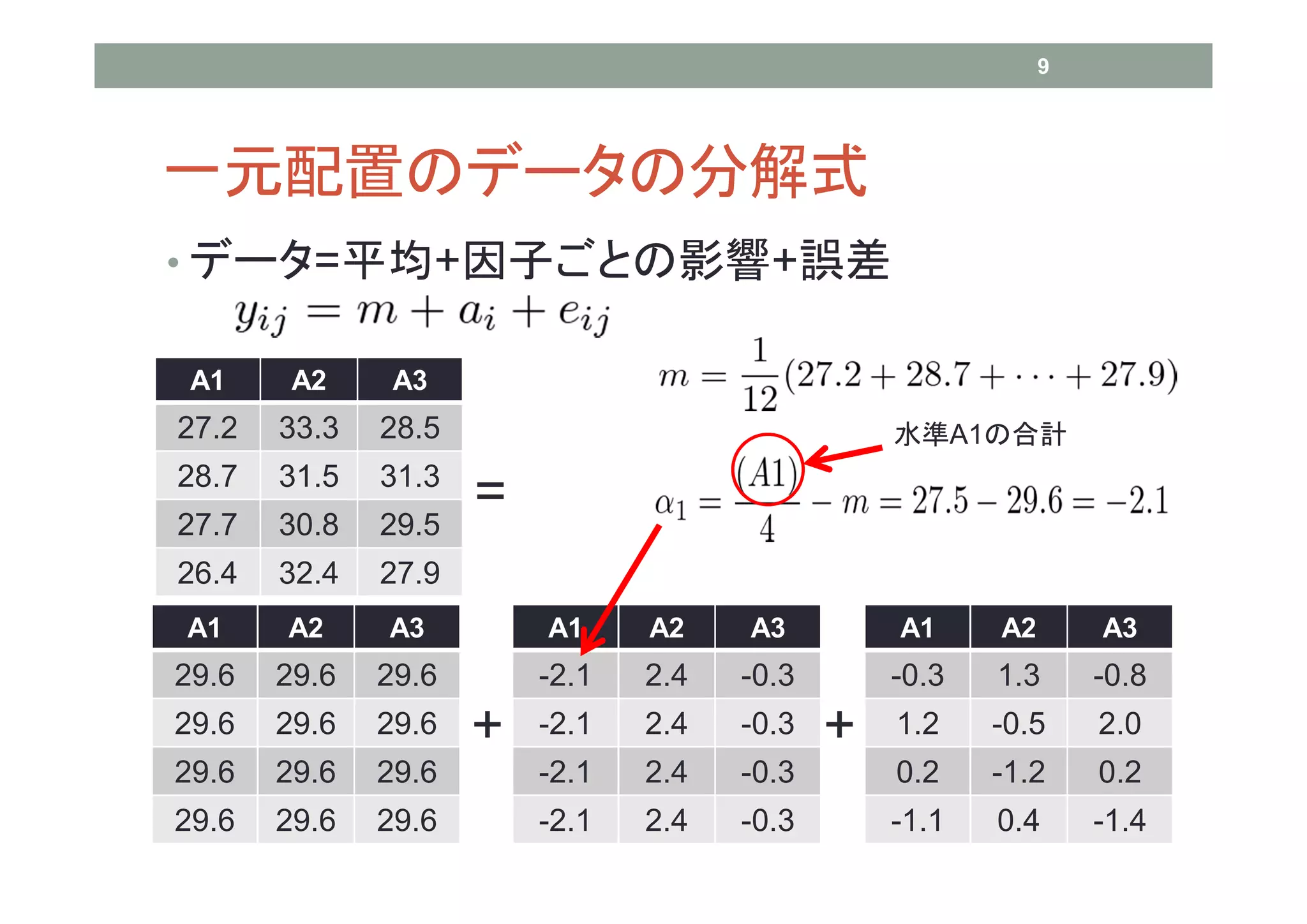
9 一元配置のデータの分解式 • データ=平均+因子ごとの影響+誤差 A1
A2 A3 27.2 33.3 28.5 水準A1の合計 28.7 31.5 31.3 27.7 30.8 29.5 = 26.4 32.4 27.9 A1 A2 A3 A1 A2 A3 A1 A2 A3 29.6 29.6 29.6 -2.1 2.4 -0.3 -0.3 1.3 -0.8 29.6 29.6 29.6 + -2.1 2.4 -0.3 + 1.2 -0.5 2.0 29.6 29.6 29.6 -2.1 2.4 -0.3 0.2 -1.2 0.2 29.6 29.6 29.6 -2.1 2.4 -0.3 -1.1 0.4 -1.4
10.
10 データの分解式に関する性質 • 因子の水準による効果の総和は0 • -2.1+2.4-0.3=0 •
誤差の総和は各水準毎に0 • -0.3+1.2+0.2-1.1=0 • 1.3-0.5-1.2+0.4=0 • -0.8+2.0+0.2-1.4=0
11.
11 変動に関する用語 • 全変動(Sum of
Square, SS) • 全データの二乗和 • 平均変動(Correlation Term, CT, 修正変動) • 全データの平均の二乗和 • 因子変動(主効果) • 因子による効果の二乗和 • 誤差変動 • 平均変動、主効果で説明できない部分 • 測定器、測定者、偶然による誤差
12.
12 データの二乗和 •
イメージは下図のように全データに^2をつけるだけ A1 A2 A3 27.2^2 33.3^2 28.5^2 28.7^2 31.5^2 31.3^2 27.7^2 30.8^2 29.5^2 = 26.4^2 32.4^2 27.9^2 A1 A2 A3 A1 A2 A3 A1 A2 A3 (-0.3)^2 1.3^2 (-0.8)^2 29.6^2 + (-2.1)^2 2.4^2 -0.3^2 1.2^2 + 0.2^2 -0.5^2 2.0^2 -1.2^2 0.2^2 (-1.1)^2 0.4^2 (-1.4)^2
13.
13 データに対する分解式
二乗和分解の式 自由度の分解式 (12 = 1 + 2 + 9)
14.
14 一元配置の分散分析表 result <- summary(aov(data~lev,data=exp.data))
有意である > result Df Sum Sq Mean Sq F value Pr(>F) lev 2 41.04 20.52 14.25 0.001625 ** Residuals 9 12.96 1.44 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 DF・・・自由度 SumSq・・・要因変動 MeanSq・・・1自由度あたりの要因変動(41.04/2、12.96/9) Fvalue・・・MeanSqを誤差の要因変動で割った値(20.52/1.44) Pr・・・P値
15.
15 分散分析のイメージ • 水準の違いによる散らばり(σ1^2)は誤差の散ら ばり(σ2^2)よりも大きいと言えるか? • 分散比が1より大きい(σ1^2/σ2^2
>1)となれば、水 準の違いによる値の散らばりは、誤差の散らばりよ り大きいと言える →水準により測定値が変化すると言える! (誤差の範囲での変化とはいえない) • 2つのデータ集合の分散比を調べるのはF検定 • データの散らばりは正規分布に従っていると仮定 • F分布はカイ二乗分布から構成されている で二乗和を求めるのはこのため
16.
16 区間推定 • 有意な因子による影響を調べる
1.44 • 最適な組に対する推定に興味があるため 各水準の平均 各水準の繰り返し回数4
17.
17 なぜ分散分析なのか • t検定の繰り返しで差の有意性を調べるのは? •
有意水準5%でn回検定すると1-0.95^nの確率で第 一種の誤り(違うのに正しいと言ってしまう)を犯して しまう →第一種の誤りが5%より大きくなるのでダメ (多重性の問題) • 本当にダメ? 4水準であれば =6 より5/6%が有意水準 • ボンフェローニ法という手法がある • 5%/(t検定を行う回数)を有意水準としたt検定 • 手軽だが、かなり厳しめに見積もる傾向がある
18.
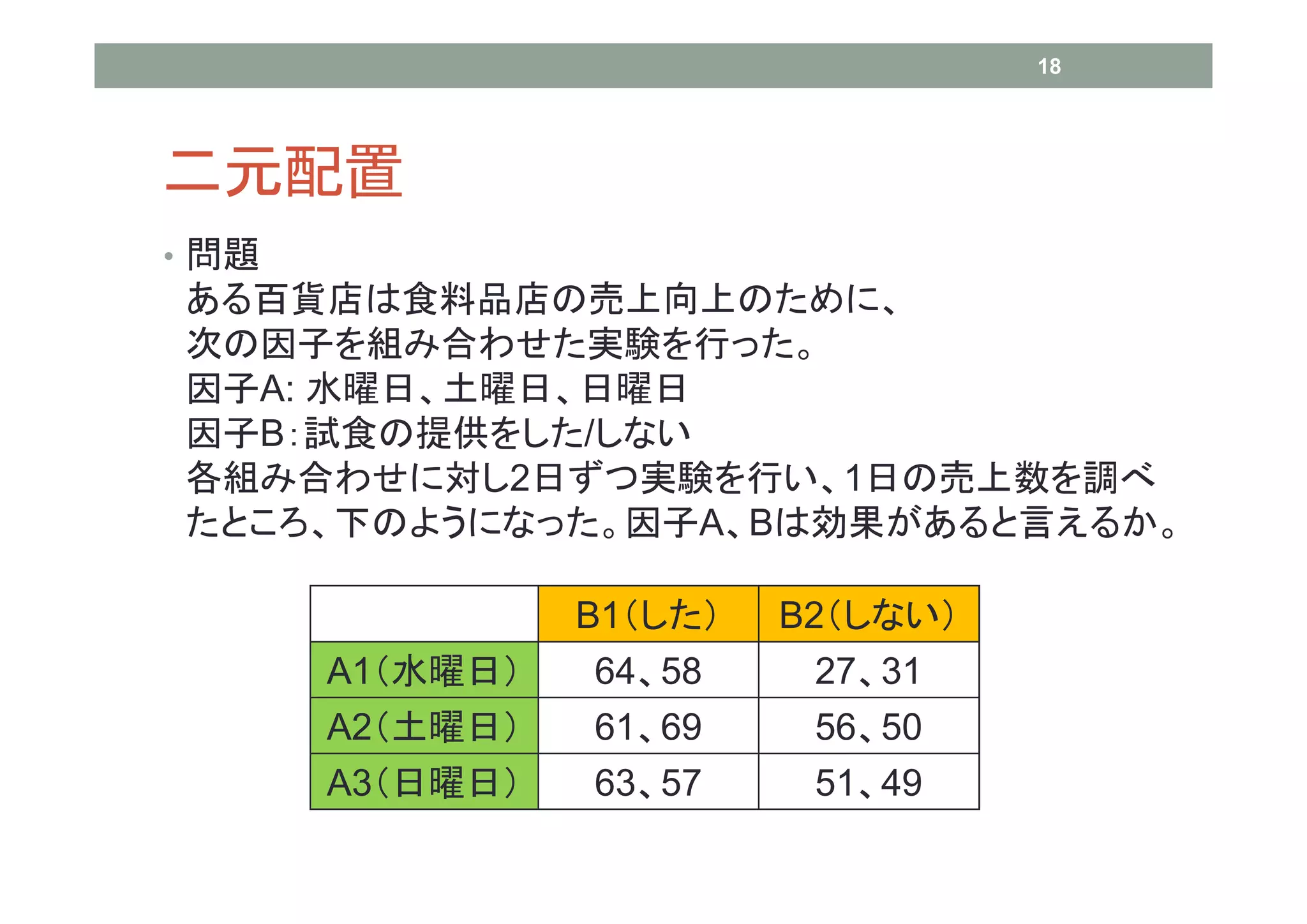
18 二元配置 • 問題 ある百貨店は食料品店の売上向上のために、 次の因子を組み合わせた実験を行った。 因子A: 水曜日、土曜日、日曜日 因子B:試食の提供をした/しない 各組み合わせに対し2日ずつ実験を行い、1日の売上数を調べ たところ、下のようになった。因子A、Bは効果があると言えるか。
B1(した) B2(しない) A1(水曜日) 64、58 27、31 A2(土曜日) 61、69 56、50 A3(日曜日) 63、57 51、49
19.
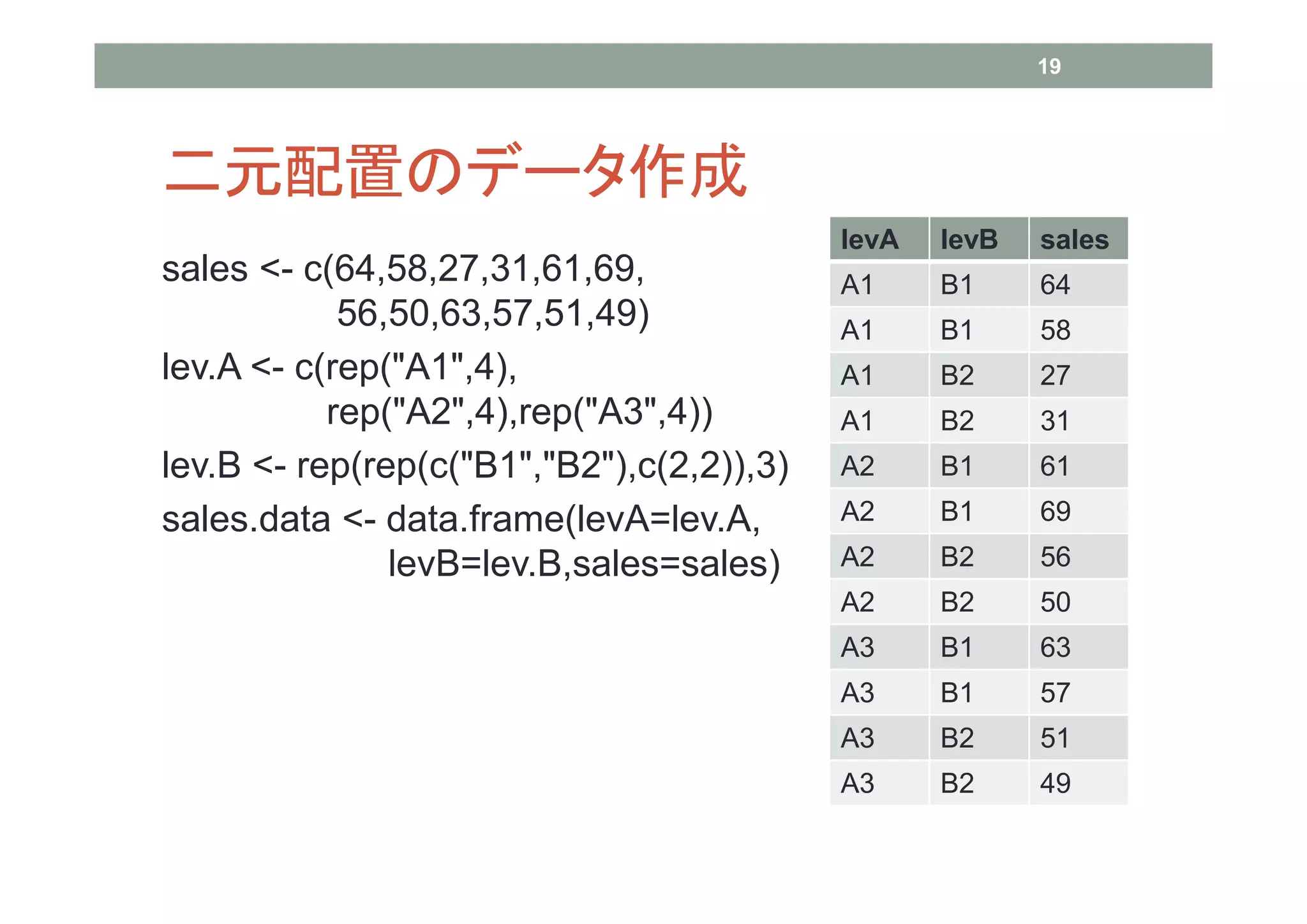
19 二元配置のデータ作成
levA levB sales sales <- c(64,58,27,31,61,69, A1 B1 64 56,50,63,57,51,49) A1 B1 58 lev.A <- c(rep("A1",4), A1 B2 27 rep("A2",4),rep("A3",4)) A1 B2 31 lev.B <- rep(rep(c("B1","B2"),c(2,2)),3) A2 B1 61 sales.data <- data.frame(levA=lev.A, A2 B1 69 levB=lev.B,sales=sales) A2 B2 56 A2 B2 50 A3 B1 63 A3 B1 57 A3 B2 51 A3 B2 49
20.
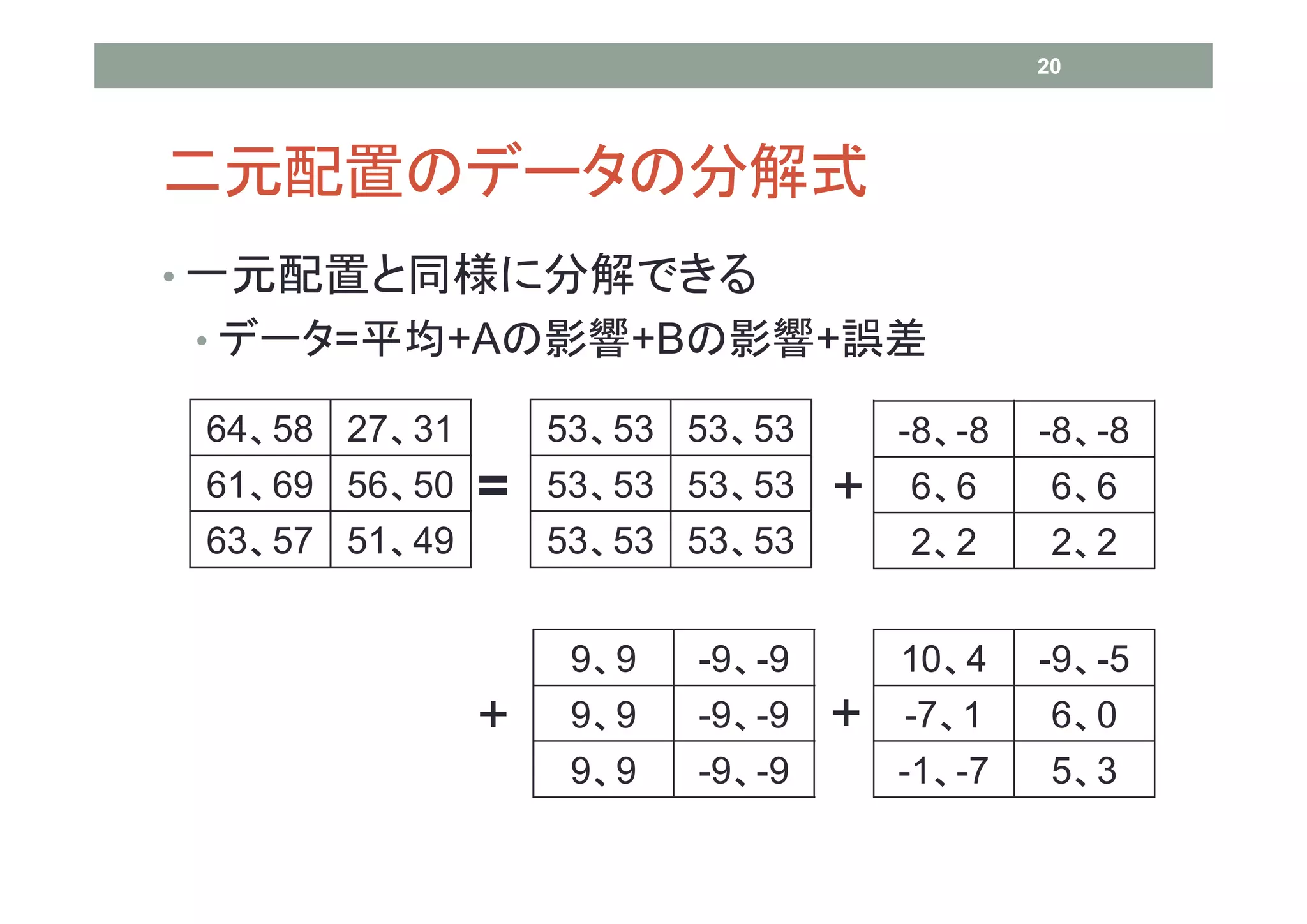
20 二元配置のデータの分解式 • 一元配置と同様に分解できる • データ=平均+Aの影響+Bの影響+誤差
64、58 27、31 53、53 53、53 -8、-8 -8、-8 61、69 56、50 = 53、53 53、53 + 6、6 6、6 63、57 51、49 53、53 53、53 2、2 2、2 9、9 -9、-9 10、4 -9、-5 + 9、9 -9、-9 + -7、1 6、0 9、9 -9、-9 -1、-7 5、3
21.
21 二元配置の変動計算 一元配置と同様に計算可能
やはり二乗和分解できる 自由度も分解可能
22.
22 二元配置の分散分析表 summary(aov(sales~levA+levB,data=sales.data)) > summary(aov(sales~levA+levB,data=sales.data))
Df Sum Sq Mean Sq F value Pr(>F) 有意 levA 2 416 208 4.2449 0.055399 . levB 1 972 972 19.8367 0.002128 ** Residuals 8 392 49 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 結論:試食の提供の有無は売上に 影響があると言える! →これで十分な分析なのか?No!
23.
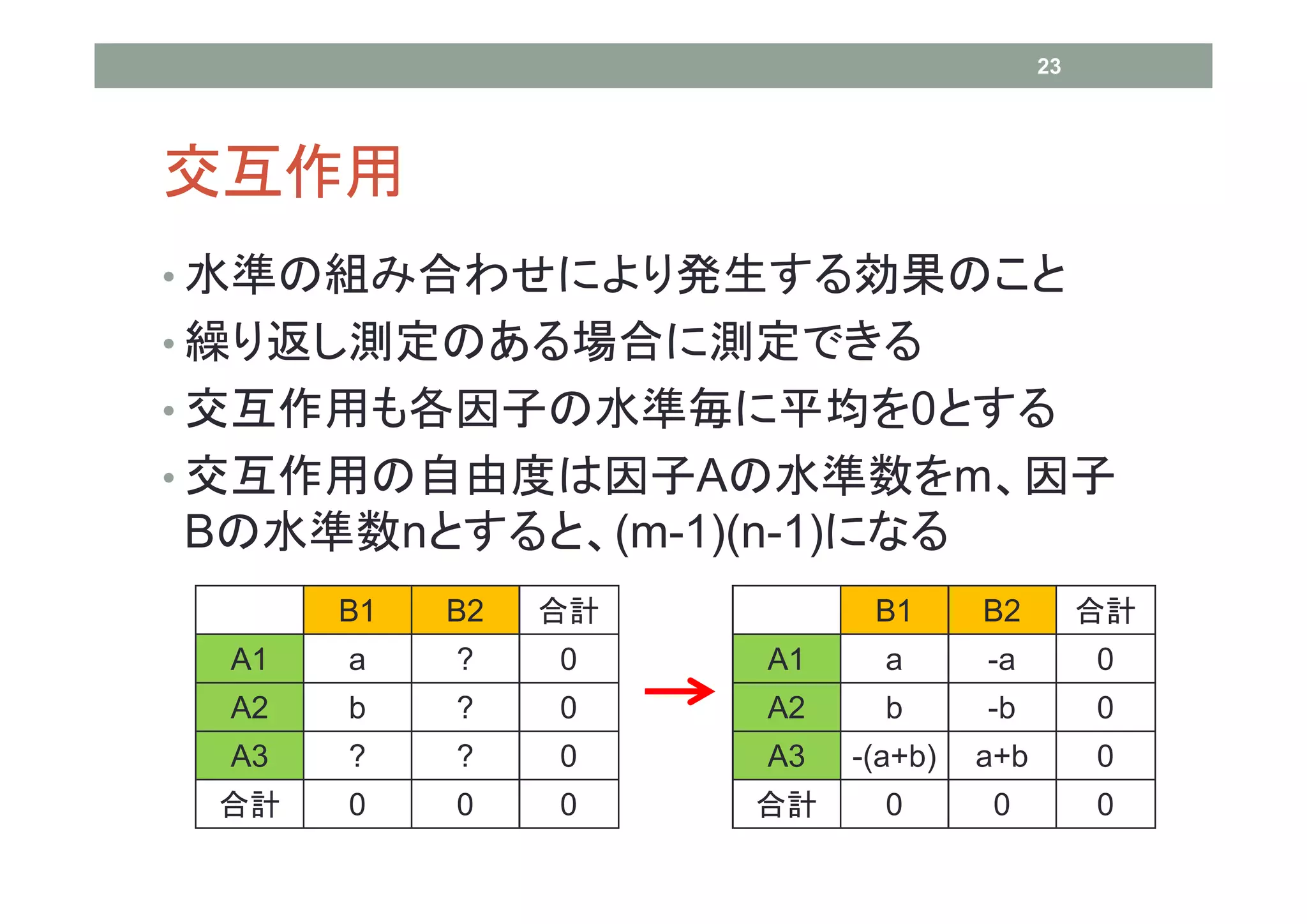
23 交互作用 • 水準の組み合わせにより発生する効果のこと • 繰り返し測定のある場合に測定できる •
交互作用も各因子の水準毎に平均を0とする • 交互作用の自由度は因子Aの水準数をm、因子 Bの水準数nとすると、(m-1)(n-1)になる B1 B2 合計 B1 B2 合計 A1 a ? 0 A1 a -a 0 A2 b ? 0 A2 b -b 0 A3 ? ? 0 A3 -(a+b) a+b 0 合計 0 0 0 合計 0 0 0
24.
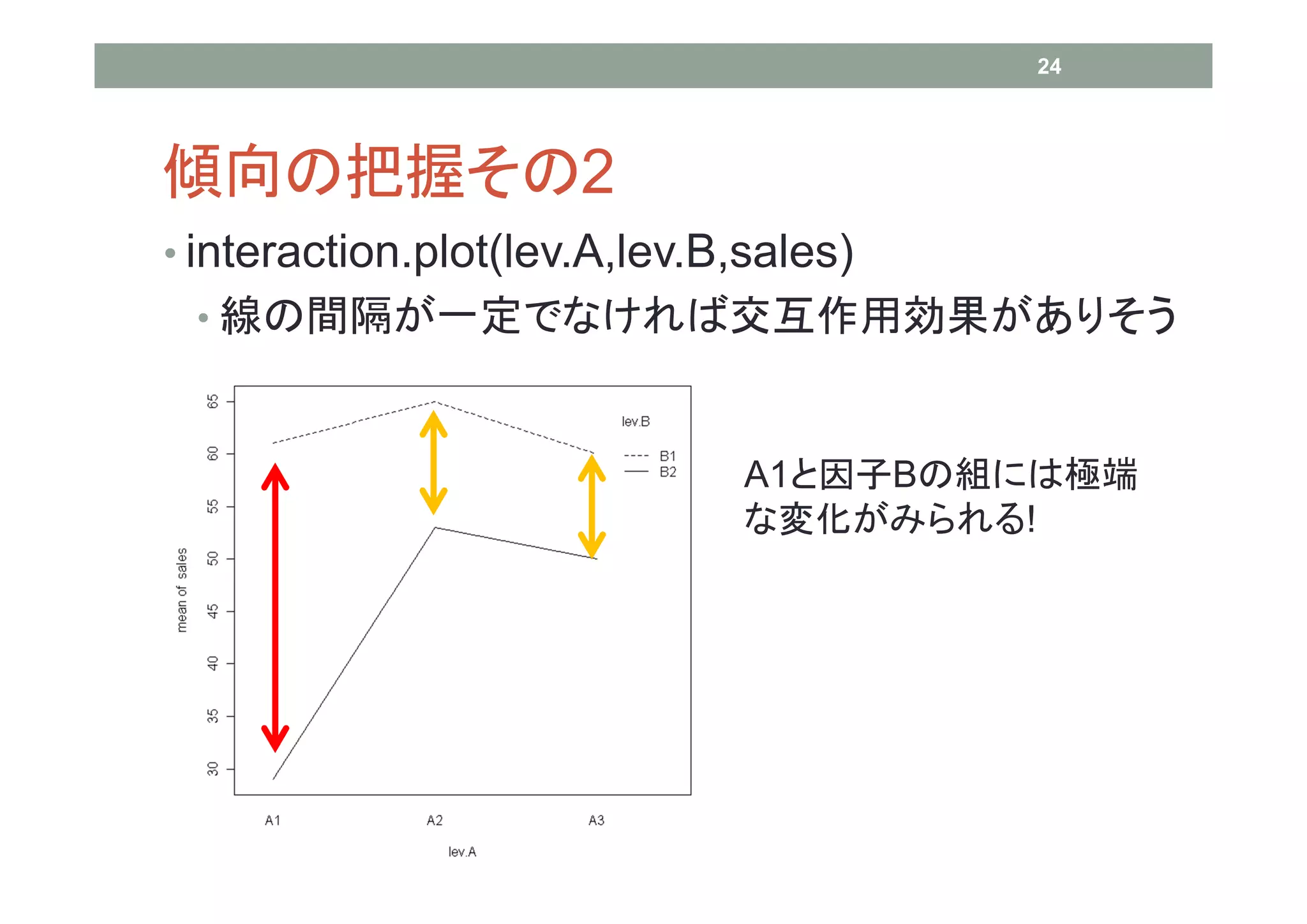
24 傾向の把握その2 • interaction.plot(lev.A,lev.B,sales) •
線の間隔が一定でなければ交互作用効果がありそう A1と因子Bの組には極端 な変化がみられる!
25.
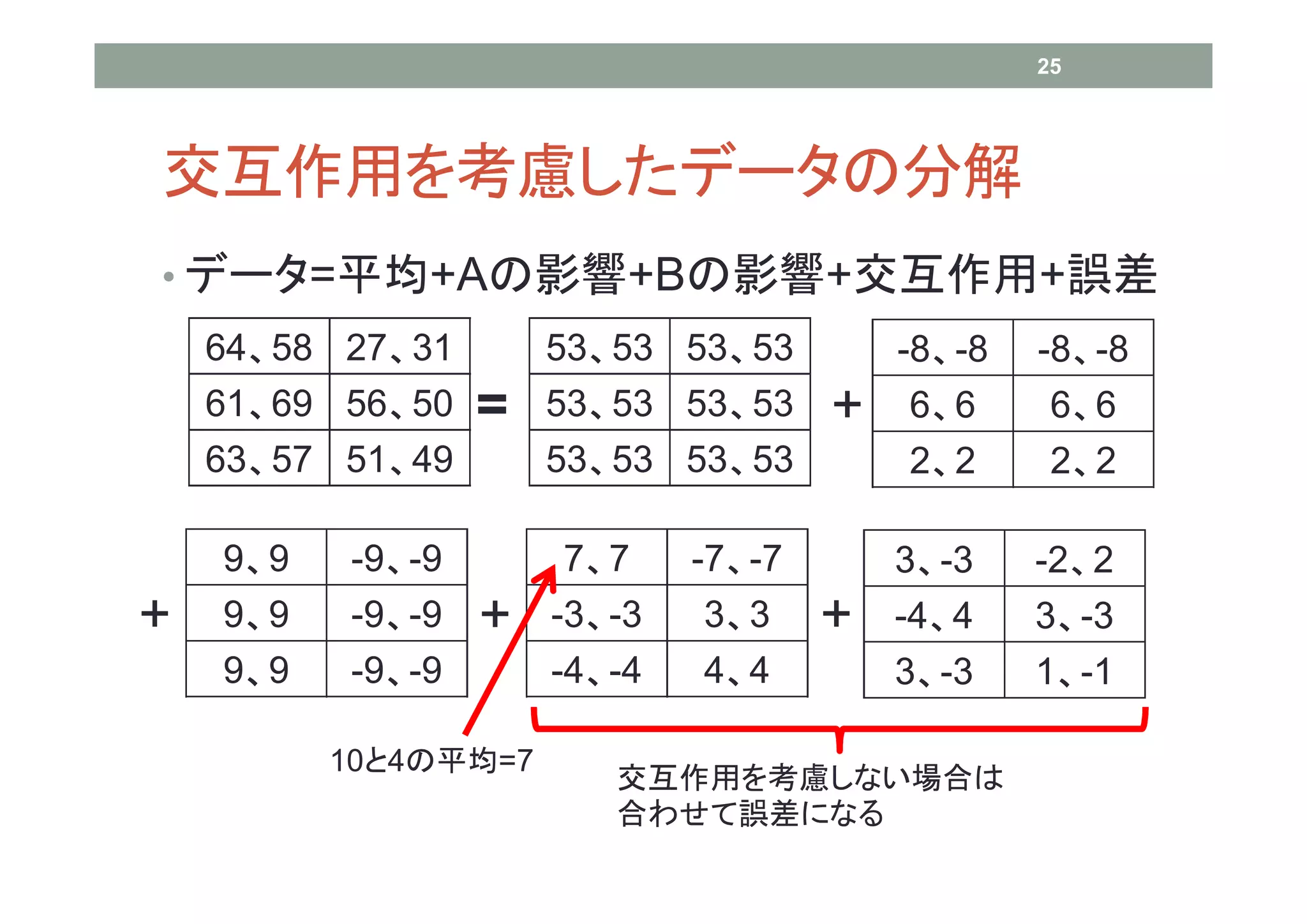
25 交互作用を考慮したデータの分解 • データ=平均+Aの影響+Bの影響+交互作用+誤差
64、58 27、31 53、53 53、53 -8、-8 -8、-8 61、69 56、50 = 53、53 53、53 + 6、6 6、6 63、57 51、49 53、53 53、53 2、2 2、2 9、9 -9、-9 7、7 -7、-7 3、-3 -2、2 + 9、9 -9、-9 + -3、-3 3、3 + -4、4 3、-3 9、9 -9、-9 -4、-4 4、4 3、-3 1、-1 10と4の平均=7 交互作用を考慮しない場合は 合わせて誤差になる
26.
26 交互作用を考慮した分散分析表 summary(aov(sales~levA+levB+levA:levB,data=sales.data)) or summary(aov(sales~levA*levB,data=sales.data))
Df Sum Sq Mean Sq F value Pr(>F) levA 2 416 208 13.00 0.0065918 ** levB 1 972 972 60.75 0.0002351 *** levA:levB 2 296 148 9.25 0.0146878 * Residuals 6 96 16 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 • 曜日と試食提供の有無の組合せも効果がある • 交互作用項ができたことで、残差の自由度以上に、 残差変動が減っている→交互作用は無視できない
27.
27 多元配置から方格を用いた実験へ • 多元配置の問題点 • 実験回数が指数的に増える
• n元配置で、k水準の実験を行うと最低k^n回必要 • ラテン方陣を用いるとある程度解決する • グレコ・ラテン方陣を使うと、更に効率よく実験可能
28.
28 ラテン方陣 • n*nの正方格子にn種類の文字を入れる • どの行方向、列方向にもすべての文字が1個ずつ
現れる C1 C2 C3 C2 C3 C1 C3 C1 C2
29.
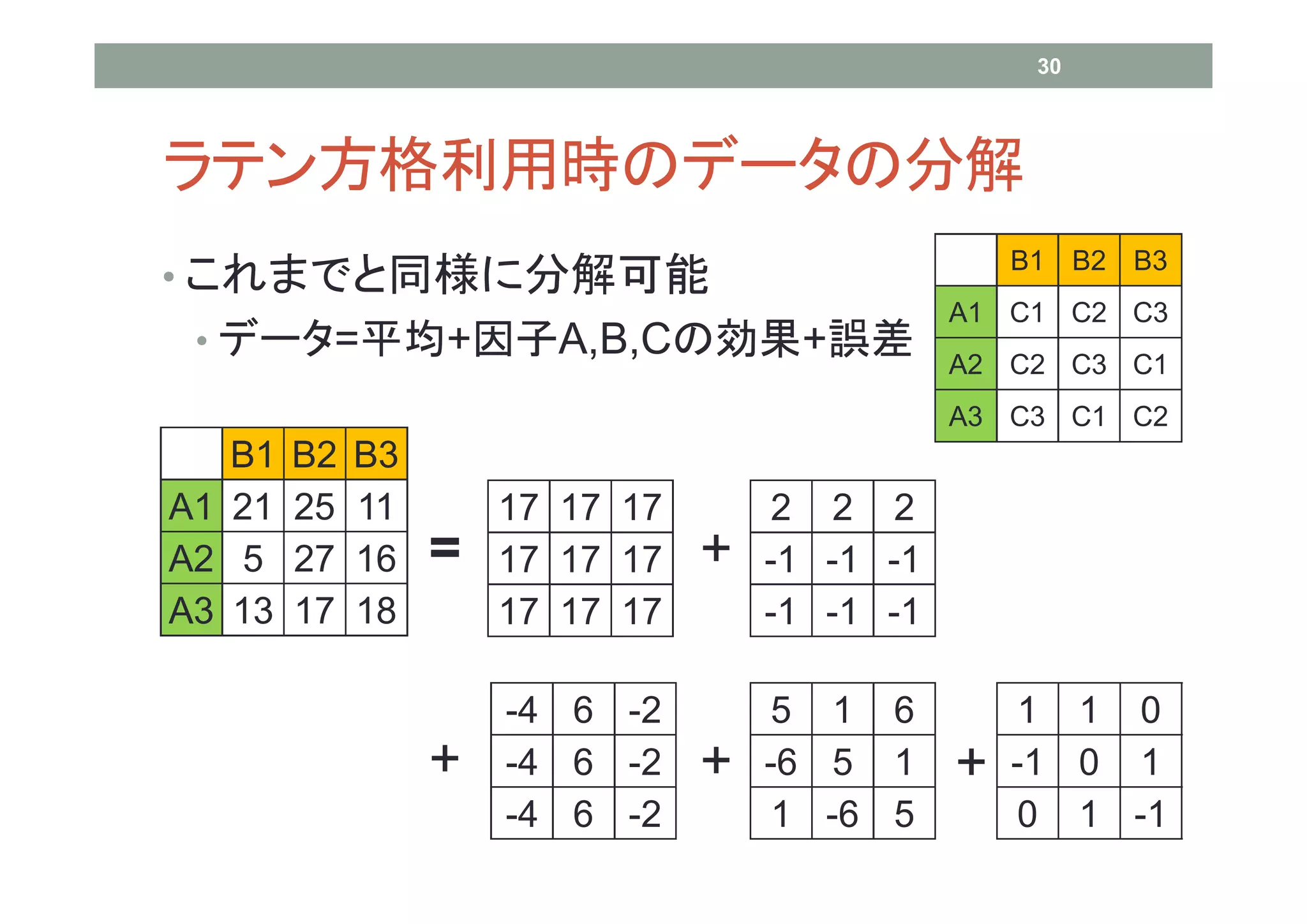
29 ラテン方格と二元配置の関係
B1 B2 B3 ラテン方陣を用いた実験計 画をラテン方格という A1 C1 C2 C3 どの因子のどの水準に着目し A2 C2 C3 C1 ても、他の因子の水準が同数 実験されている A3 C3 C1 C2 (バランスが取れているという) バランスが取れていると、データ ラテン方陣は二元配置 の分解式が容易に作成できる に組み込むことができる
30.
30 ラテン方格利用時のデータの分解
B1 B2 B3 • これまでと同様に分解可能 A1 C1 C2 C3 • データ=平均+因子A,B,Cの効果+誤差 A2 C2 C3 C1 A3 C3 C1 C2 B1 B2 B3 A1 21 25 11 17 17 17 2 2 2 A2 5 27 16 = 17 17 17 + -1 -1 -1 A3 13 17 18 17 17 17 -1 -1 -1 -4 6 -2 5 1 6 1 1 0 + -4 6 -2 + -6 5 1 + -1 0 1 -4 6 -2 1 -6 5 0 1 -1
31.
31 グレコ・ラテン方陣
バランスが取れている α β γ δ a c d b αa βc γd δb β α δ γ b d c a 重ねる βb αd δc γa γ δ α β c a b d γc δa αb βd δ γ β α d b a c δd γb βa αc 直交・・・重ねたときに同じ文字の組み合わせがない 2個のラテン方陣の関係 • グレコ・ラテン方陣はラテン方陣を重ねたもの • 4水準4因子の実験が16回でできる(4元配置は4^4=256回)
32.
32 グレコ・ラテン方格で水準設定
B1 B2 B3 B4 A1 C1D1 C2D3 C3D4 C4D2 A2 C2D2 C1D4 C4D3 C3D1 A3 C3D3 C4D1 C1D2 C2D4 A4 C4D4 C3D2 C2D1 C1D3 グレコ・ラテン方陣で因子Cの水準にはギリシャ文字、 因子Dの水準にはアルファベットを割り当てる。 上の例では、以下のように水準を割り当てた。 α:C1、β:C2、γ:C3、δ:C4、a:D1、b:D2、c:D3、d:D4 データの分解や分散分析表の作り方はこれまでと同じ
33.
33 残差の寄せ集め(プーリング) • 分散分析表を作成した後に、不要と判明した因子 を誤差に取り込む • F値が1~2以下のものが対象になる
• 測定に伴う誤差程度しか分散がないから →因子が測定にまったく影響していない • 1自由度当たりの誤差変動は増えず、誤差の自由 度が増えるため、検定で有意になるためのF値が 小さくなる • 意味のある実験結果が得られる可能性が増す • 特に誤差の自由度が少ないときに有効
34.
34 方格から直交表へ • 二元配置に組み込めるk水準の因子はk-1個まで • k^2回の実験でk水準の因子がk+1個まで調べられる •
ただしk=p^s(pは素数、sは正の整数)の場合しか配 置が知られていない • k水準の因子がk+1個まで調べられる配置を整理し たものを直交表とよぶ
35.
35 実験計画法の原則(by フィッシャー) • 反復
• 誤差を評価できるようにする • 無作為化 • 慣れを防ぐ • 時間的・空間的な要因を排除する(気温・季節など) • 局所管理 • 要因以外の要素を極力一定にする • 例:生物の成長実験では体格が同じ個体を使う これまでの実験は、実はランダムに実験するべき内容 であることに注意!
36.
36 まとめ • 一元配置、二元配置の計算方法を紹介した • Rの出力結果を手計算で求めることもできる •
問題によっては交互作用を考えることがある • 方格を用いると、実験回数が多元配置より大幅 に減らせる
37.
37 参考資料 • よくわかる実験計画法(著:中村 義作) •
Rと分散分析(金明哲先生のWebページ) • http://mjin.doshisha.ac.jp/R/12.html • 統計学入門(東京大学出版会) • 自然科学の統計学(東京大学出版会)
38.
38 ご清聴ありがとうございました
39.
39 補足:因子変動の計算 • 実はデータの分解式を作らなくてもよい • 以下の式で計算可能
Download