Download as PDF, PPTX











































![Copyright © GREE, Inc. All Rights Reserved.
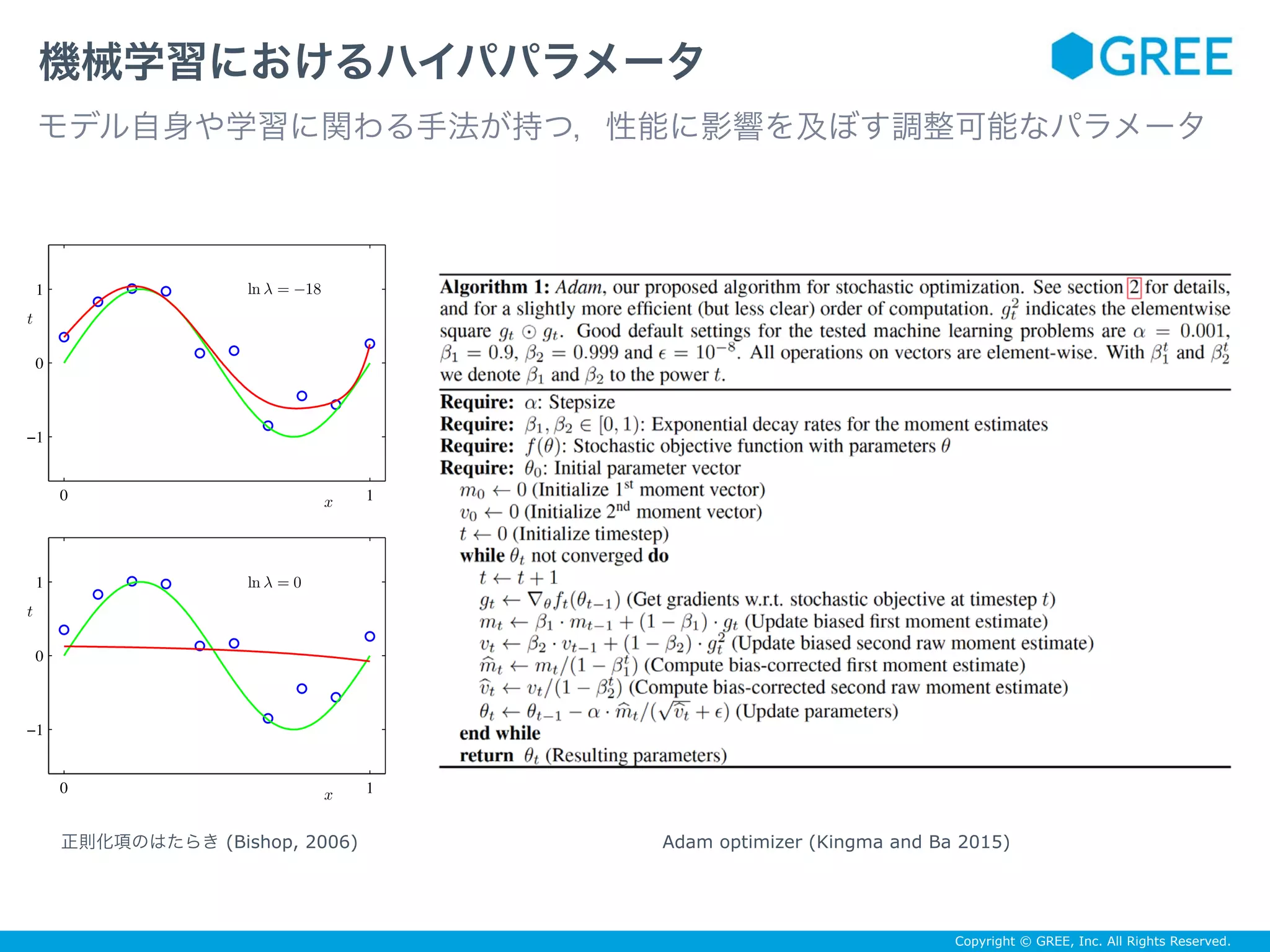
ベイズ最適化
mとkを決めれば,過去の観測から未観測点の関数値を予測できる
ガウス分布の性質とSchurの公式から導出される (Rasmussen and Williams 2005; Bishop 2006)
データがないとまともに予測できないので,ランダムサーチなどでデータを集めて初期化しておく
P(fϵ(λt+1
) | λ1
, λ2
, . . . , λt+1
) = N(µt(λt+1
), σ2
t (λt+1
) + σ2
n),
µt(λt+1
) = k⊤
[K + σ2
nI]−1
[f(λ1
) f(λ2
) · · · f(λt
)]⊤
,
σ2
t (λt+1
) = k(λt+1
, λt+1
) − k⊤
[K + σ2
nI]−1
k
where
k = [k(λt+1
, λ1
) k(λt+1
, λ2
) · · · k(λt+1
, λt
)]⊤
,
K =
⎡
⎢
⎣
k(λ1
, λ1
) · · · k(λ1
, λt
)
...
...
...
k(λt
, λ1
) · · · k(λt
, λt
)
⎤
⎥
⎦ .](https://image.slidesharecdn.com/miru6-180821073229/75/slide-54-2048.jpg)


![Copyright © GREE, Inc. All Rights Reserved.
サロゲートの計算量削減
近年の研究動向
[K + σ2
nI]−1
• ガウス過程回帰のボトルネック:
• 近似計算 (Quiñonero-Candela et al. 2007; Titsias 2009)
• 計算量が相対的に少ないサロゲート
• ランダムフォレスト (Hutter et al. 2011)
• DNN (Snoek et al. 2015)](https://image.slidesharecdn.com/miru6-180821073229/75/slide-58-2048.jpg)



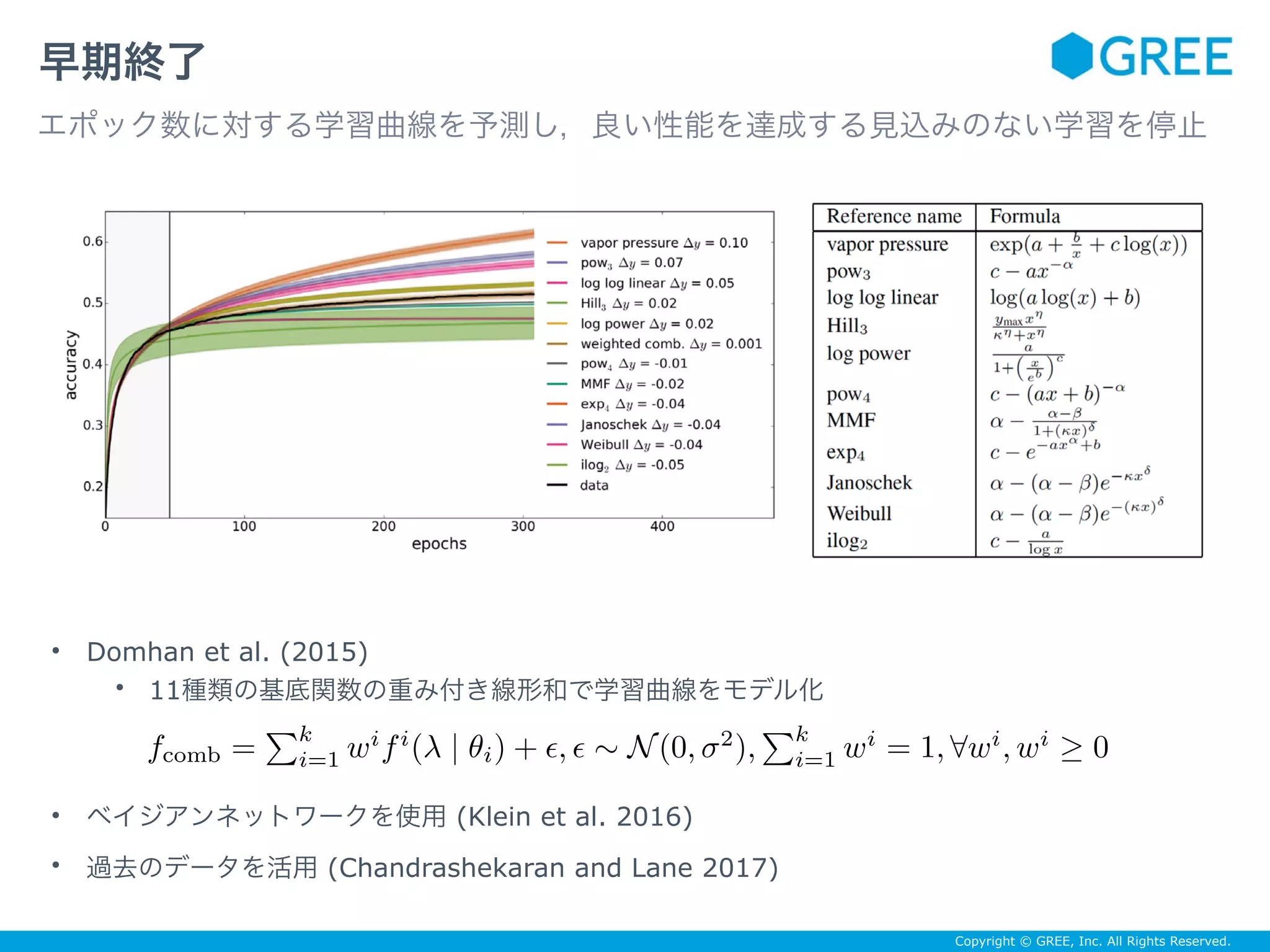






![Copyright © GREE, Inc. All Rights Reserved.
CNNのハイパパラメータ最適化 (Ozaki et al. 2017)
以下を5つの手法でハイパパラメータ最適化する
Name Description Range
x1 Learning rate (= 0.1x1
) [1, 4]
x2 Momentum (= 1 − 0.1x2
) [0.5, 2]
x3 L2 weight decay [0.001, 0.01]
x∗
4 FC1 units [256, 1024]
Integer parameters are marked with ∗
.
データセット:MNIST
ネットワーク:LeNet,Batch-Normalized Maxout Network in Network
タスク:文字認識(10クラス分類)
Name Description Range
x1 Learning rate (= 0.1x1
) [0.5, 2]
x2 Momentum (= 1 − 0.1x2
) [0.5, 2]
x3 L2 weight decay [0.001, 0.01]
x4 Dropout 1 [0.4, 0.6]
x5 Dropout 2 [0.4, 0.6]
x6 Conv 1 initialization deviation [0.01, 0.05]
x7 Conv 2 initialization deviation [0.01, 0.05]
x8 Conv 3 initialization deviation [0.01, 0.05]
x9 MMLP 1-1 initialization deviation [0.01, 0.05]
x10 MMLP 1-2 initialization deviation [0.01, 0.05]
x11 MMLP 2-1 initialization deviation [0.01, 0.05]
x12 MMLP 2-2 initialization deviation [0.01, 0.05]
x13 MMLP 3-1 initialization deviation [0.01, 0.05]
x14 MMLP 3-2 initialization deviation [0.01, 0.05]
Batch-Normalized Mahout Network in Network
(Chang and Chen 2015)
MMLP (Maxout Multi Layer Perceptron)
LeNet (LeCun et al. 1998)
MNIST (LeCun and Cortes, 2010)](https://image.slidesharecdn.com/miru6-180821073229/75/slide-70-2048.jpg)




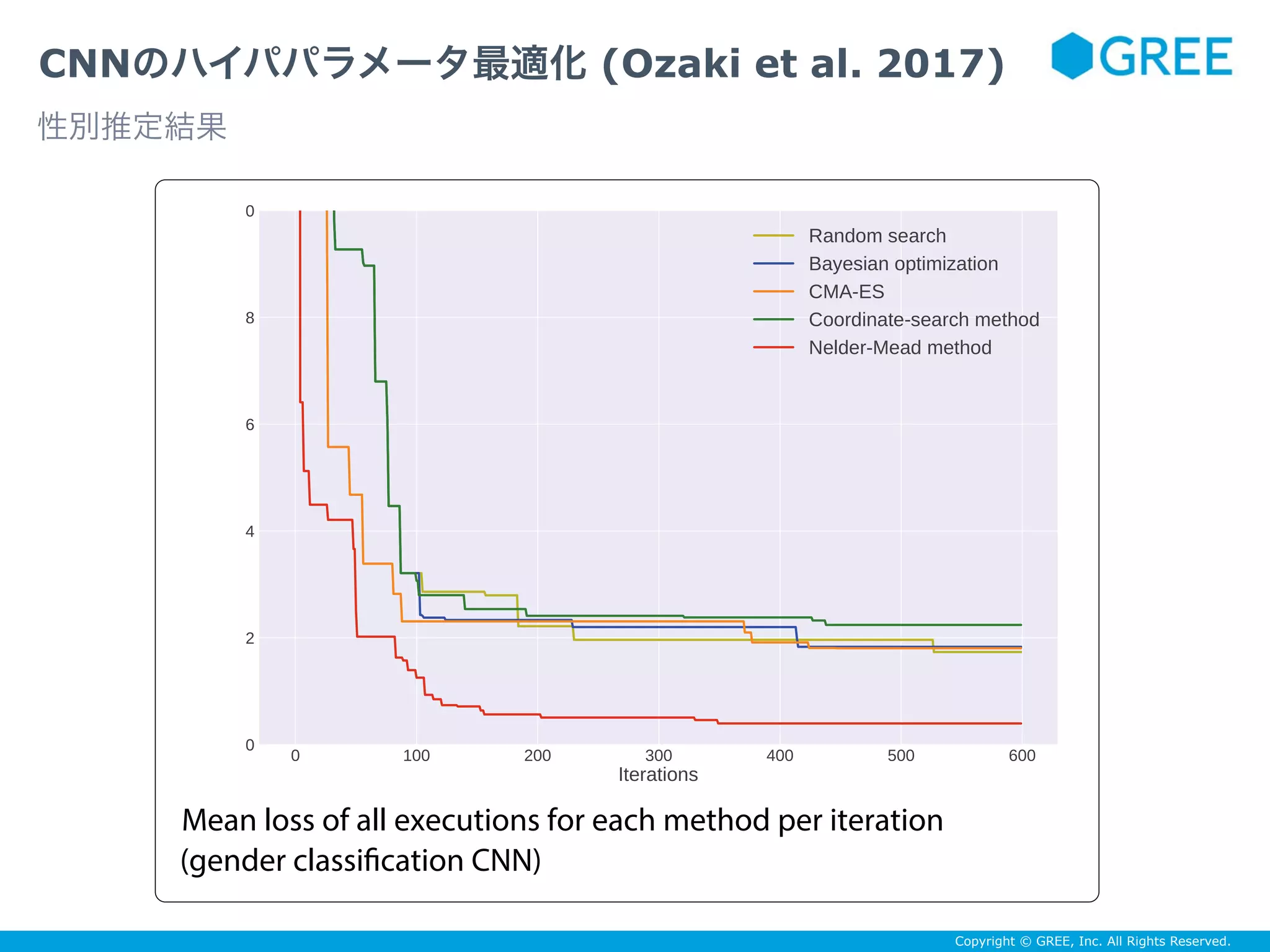
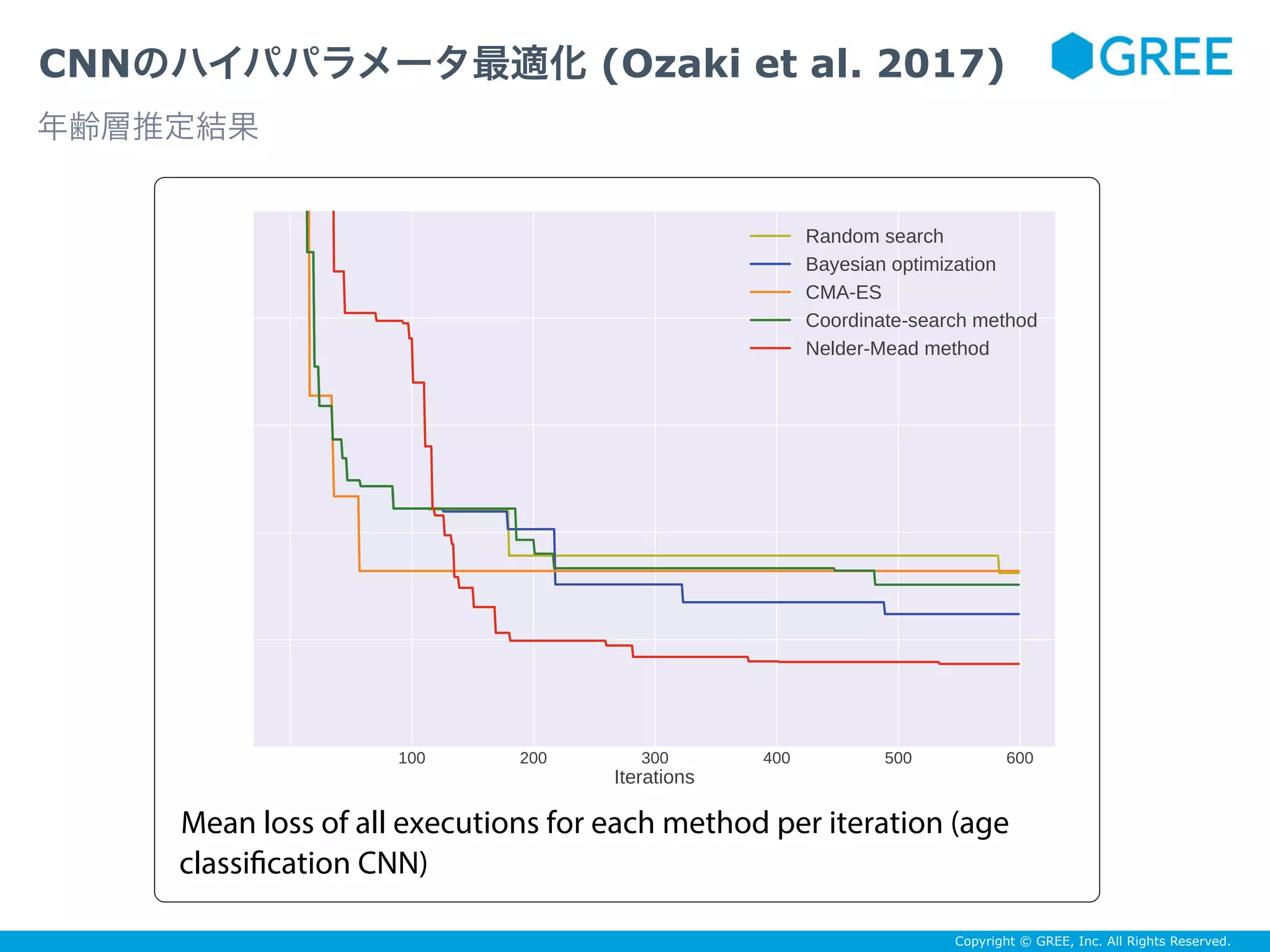
![Copyright © GREE, Inc. All Rights Reserved.
CNNのハイパパラメータ最適化 (Ozaki et al. 2017)
データセット:Adience benchmark
ネットワーク:Gil and Tal (2015)
タスク:
(1)性別推定(2クラス分類)
(2)年齢層推定(8クラス分類)
Name Description Range
x1 Learning rate (= 0.1x1
) [1, 4]
x2 Momentum (= 1 − 0.1x2
) [0.5, 2]
x3 L2 weight decay [0.001, 0.01]
x4 Dropout 1 [0.4, 0.6]
x5 Dropout 2 [0.4, 0.6]
x∗
6 FC 1 units [512, 1024]
x∗
7 FC 2 units [256, 512]
x8 Conv 1 initialization deviation [0.01, 0.05]
x9 Conv 2 initialization deviation [0.01, 0.05]
x10 Conv 3 initialization deviation [0.01, 0.05]
x11 FC 1 initialization deviation [0.001, 0.01]
x12 FC 2 initialization deviation [0.001, 0.01]
x13 FC 3 initialization deviation [0.001, 0.01]
x14 Conv 1 bias [0, 1]
x15 Conv 2 bias [0, 1]
x16 Conv 3 bias [0, 1]
x17 FC 1 bias [0, 1]
x18 FC 2 bias [0, 1]
x∗
19 Normalization 1 localsize (= 2x19 + 3) [0, 2]
x∗
20 Normalization 2 localsize (= 2x20 + 3) [0, 2]
x21 Normalization 1 alpha [0.0001, 0.0002]
x22 Normalization 2 alpha [0.0001, 0.0002]
x23 Normalization 1 beta [0.5, 0.95]
x24 Normalization 2 beta [0.5, 0.95]
Integer parameters are marked with ∗
.
Adience benchmark (Eran et al. 2014)](https://image.slidesharecdn.com/miru6-180821073229/75/slide-75-2048.jpg)











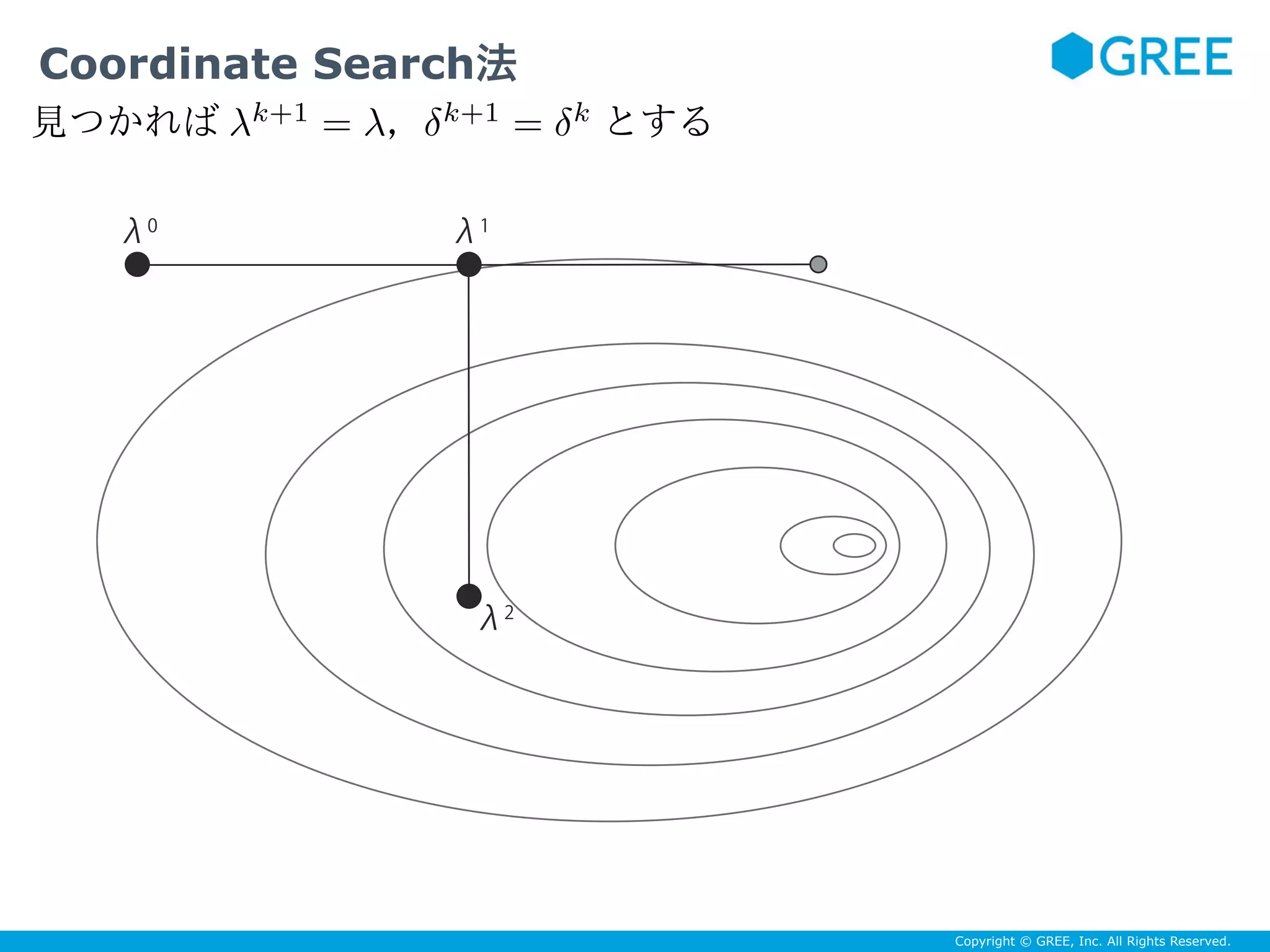
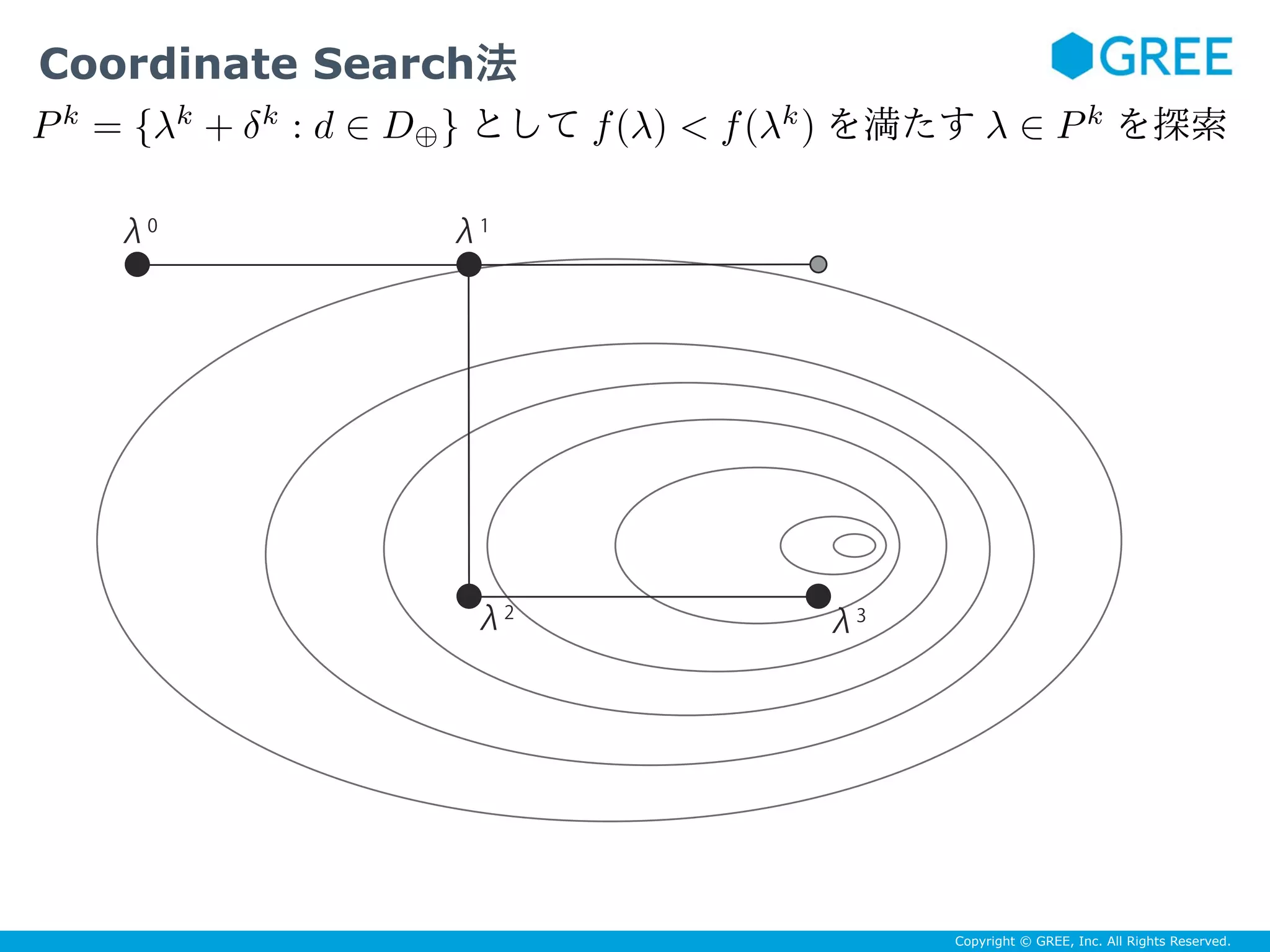











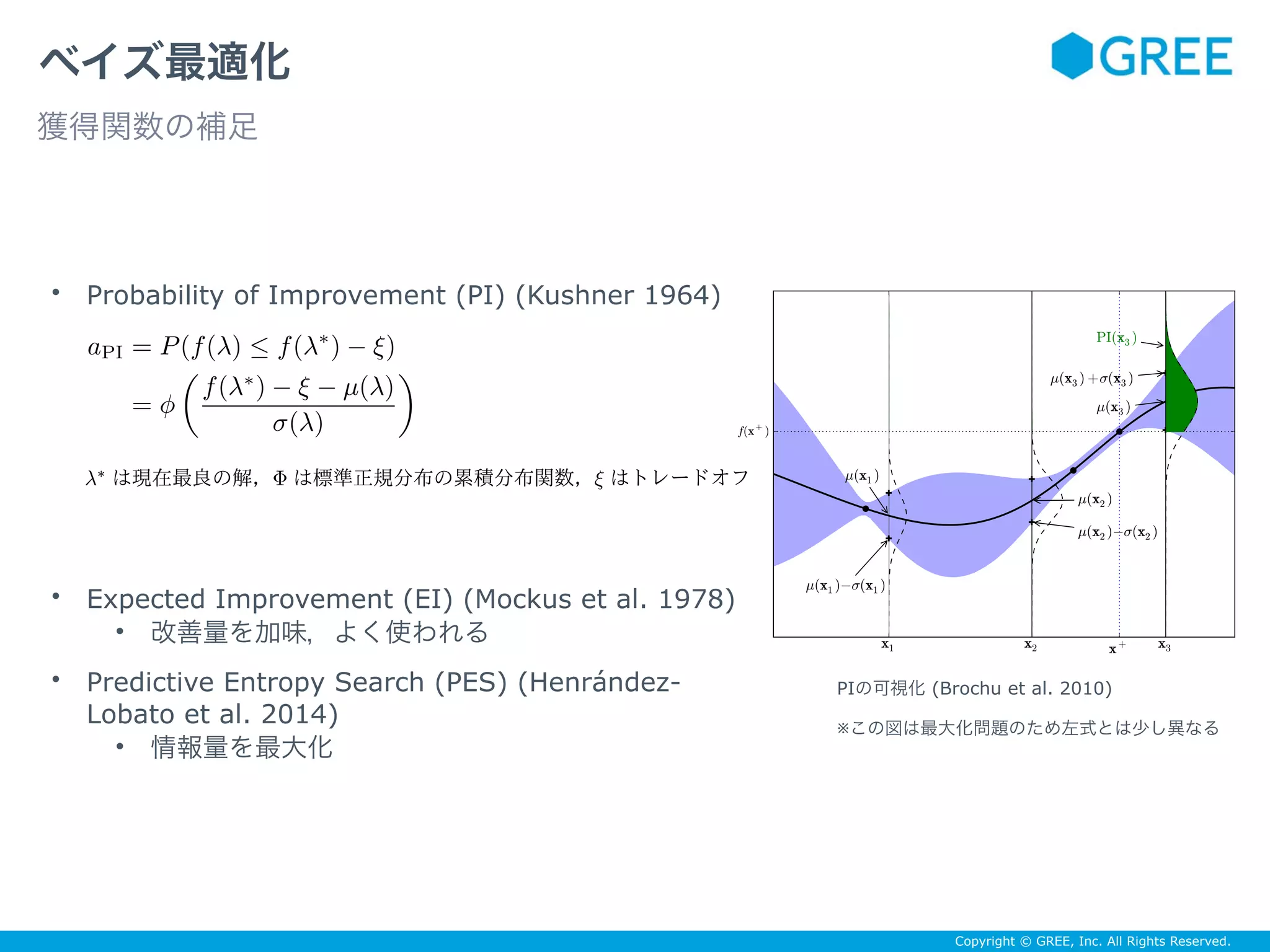



![Copyright © GREE, Inc. All Rights Reserved.
Christopher M. Bishop. Pattern recognition and machine learning. Information science and statistics. Springer, New York, 2006. ISBN
978-0-387-31073-2.
Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. arXiv:1412.6980 [cs], December 2014. URL http://arxiv.org/abs/
1412.6980. arXiv:1412.6980.
He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition.
2016.
Frank Hutter, Jörg Lücke, and Lars Schmidt-Thieme. Beyond Manual Tuning of Hyperparameters. KI - Künstliche Intelligenz, 29(4):329–337,
November 2015. ISSN 0933-1875, 1610-1987. doi: 10.1007/s13218-015-0381-0. URL http://link.springer.com/10.1007/s13218-015-0381-0.
Stefan Falkner, Aaron Klein, and Frank Hutter. Practical hyperparameter optimization for
deep learning, 2018a. URL https://openreview.net/forum?id=HJMudFkDf.
Jesse Dodge, Kevin Jamieson, and Noah A. Smith. Open Loop Hyperparameter Optimization and Determinantal Point Processes. arXiv:1706.01566
[cs, stat], June 2017. URL http://arxiv.org/abs/1706.01566. arXiv: 1706.01566.
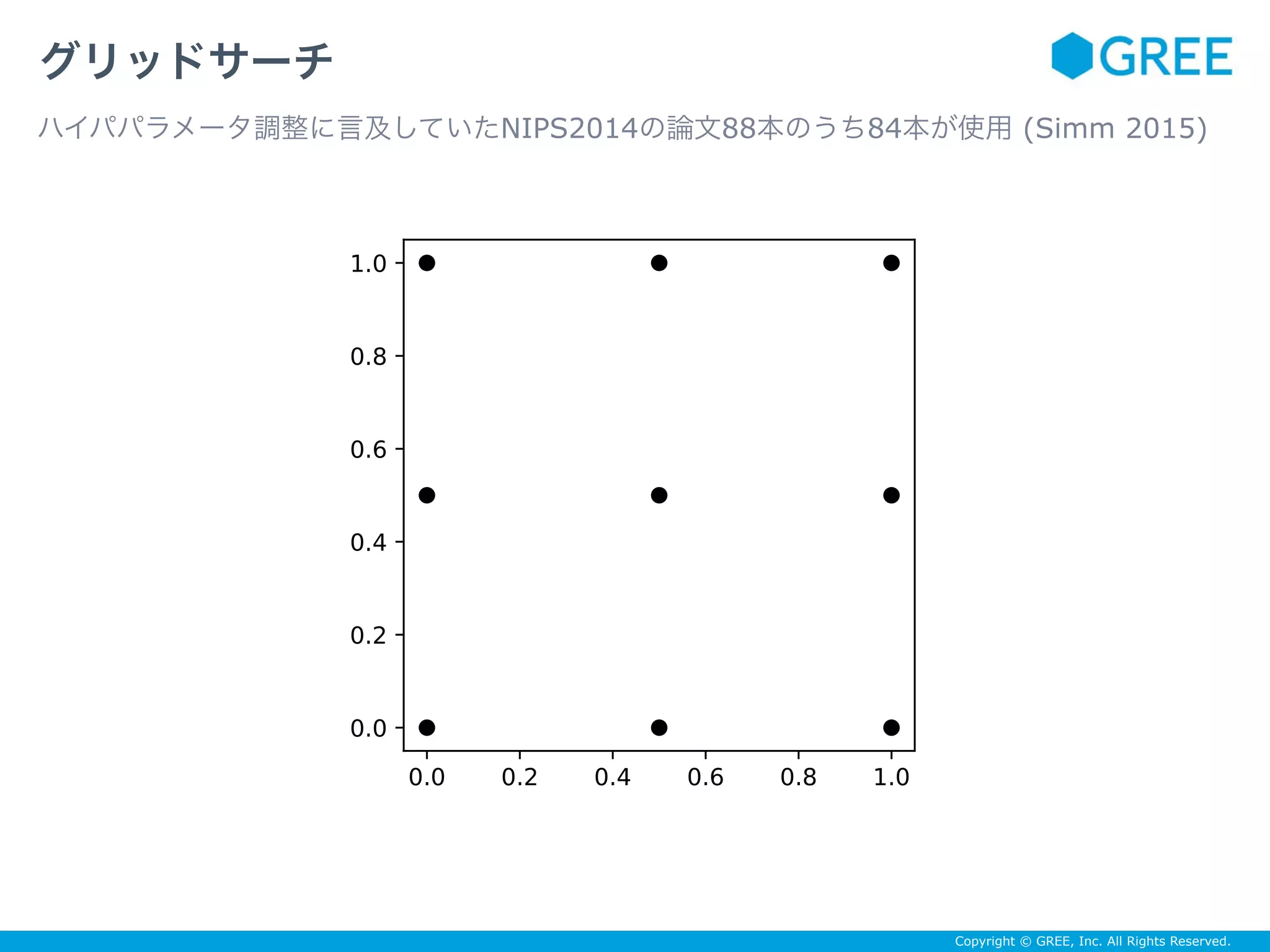
Jaak Simm. Survey of hyperparameter optimization in NIPS2014, 2015. URL https://github.com/jaak-s/nips2014-survey.
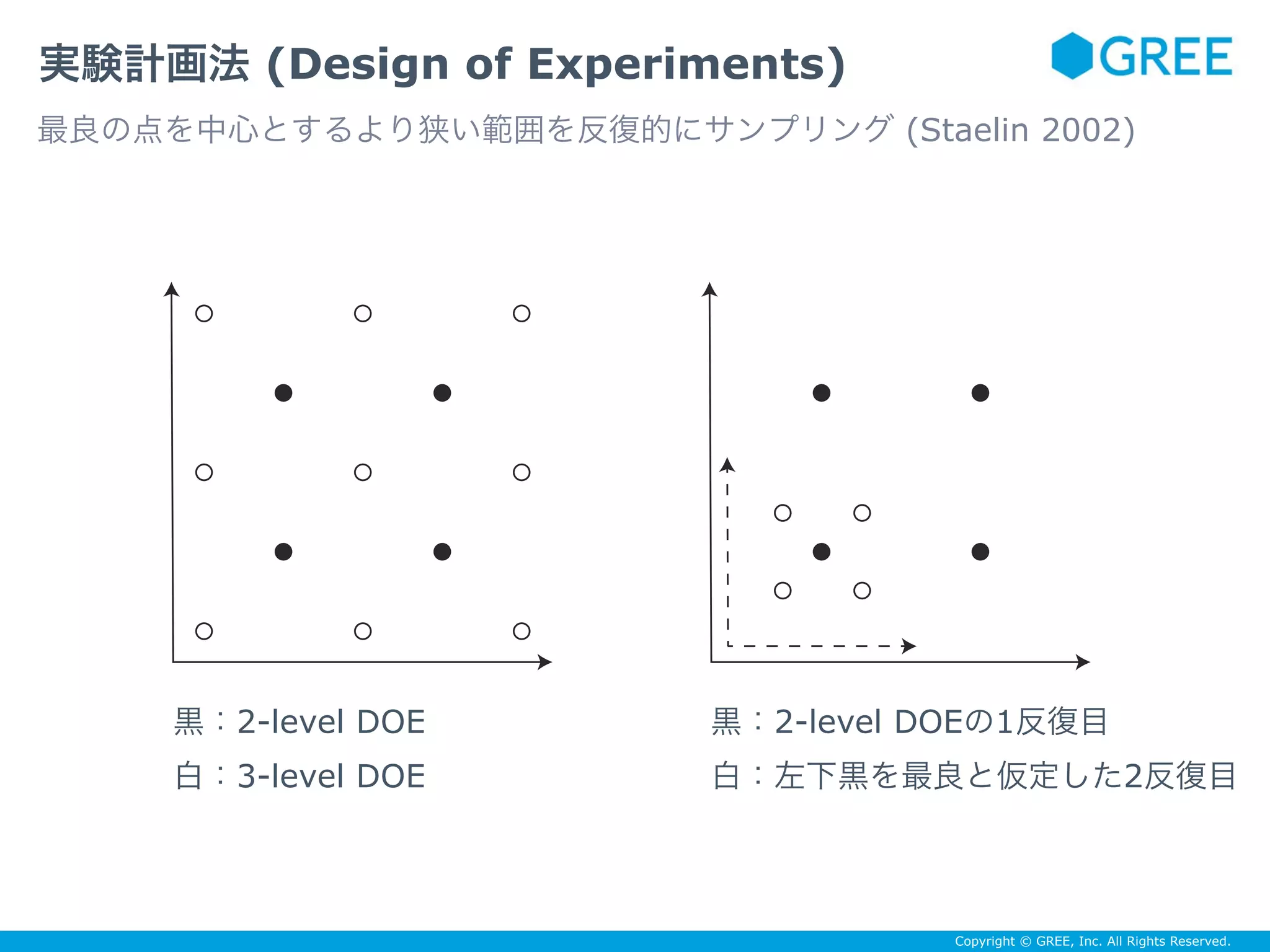
Carl Staelin. Parameter selection for support vector machines. 2002. URL http://www.hpl.hp.com/techreports/2002/HPL-2002-354R1.html.
James Bergstra and Yoshua Bengio. Random search for hyper-parameter optimization. J. Mach. Learn. Res., 13:281–305, February 2012. ISSN
1532-4435. URL http://dl.acm.org/citation.cfm?id=2188385.2188395.
Frank Hutter, Holger Hoos, and Kevin Leyton-Brown. An efficient approach for assessing hyperparameter importance. In Proceedings of the 31st
International Conference on International Conference on Machine Learning - Volume 32, ICML’14, pages I—754–I—762. JMLR.org, 2014. URL
http://dl.acm.org/citation.cfm?id=3044805.3044891.
参考文献](https://image.slidesharecdn.com/miru6-180821073229/75/slide-107-2048.jpg)
![Copyright © GREE, Inc. All Rights Reserved.
Chris Fawcett and Holger H. Hoos. Analysing differences between algorithm configurations through ablation. Journal of Heuristics, 22(4):431–458,
Aug 2016. ISSN 1572-9397. doi:10.1007/s10732-014-9275-9. URL https://doi.org/10.1007/s10732-014-9275-9.
Andre Biedenkapp, Marius Lindauer, Katharina Eggensperger, Frank Hutter, ChrisFawcett, and Holger Hoos. Efficient parameter importance analysis
via ablation with surrogates, 2017. URL https://aaai.org/ocs/index.php/AAAI/AAAI17/paper/view/14750.
Jan N van Rijn and Frank Hutter. An empirical study of hyperparameter importance across datasets. In AutoML@PKDD/ECML, 2017a.
Jan N van Rijn and Frank Hutter. Hyperparameter importance across datasets. arXiv preprint arXiv:1710.04725, 2017b.
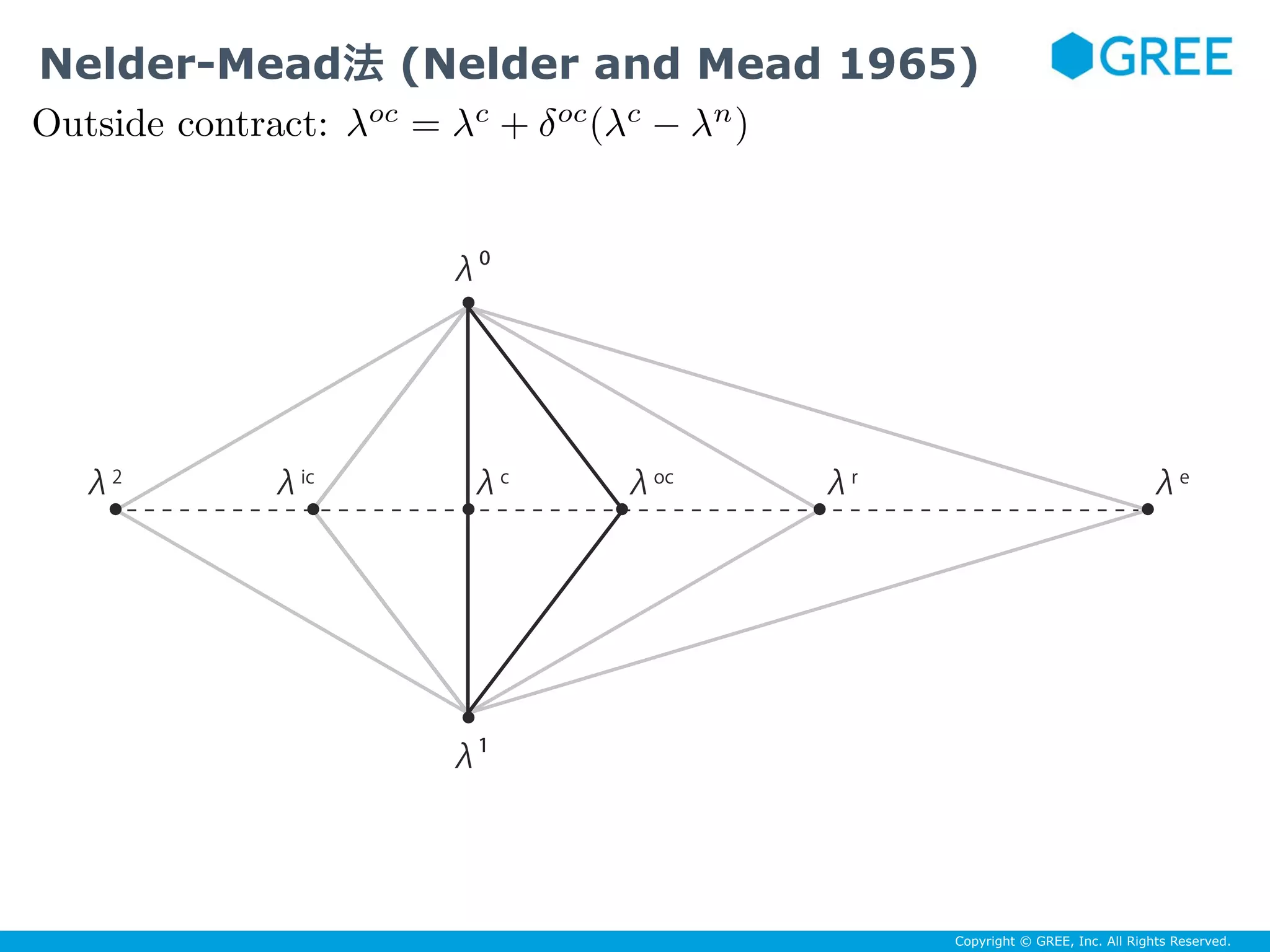
J. A. Nelder and R. Mead. A Simplex Method for Function Minimization. The Computer Journal, 7(4):308–313, January 1965. ISSN 0010-4620,
1460-2067. doi: 10.1093/comjnl/7.4.308. URL https://academic.oup.com/comjnl/article-lookup/doi/10.1093/comjnl/7.4.308.
Andrew R. Conn, Katya Scheinberg, and Luis N. Vicente. Introduction to Derivative-Free Optimization. Society for Industrial and Applied Mathematics,
January 2009. ISBN 978-0-89871-668-9 978-0-89871-876-8. doi: 10.1137/1.9780898718768. URL http://epubs.siam.org/doi/book/
10.1137/1.9780898718768.
Charles Audet and Warren Hare. Derivative-Free and Blackbox Optimization. Springer Series in Operations Research and Financial Engineering.
Springer International Publishing, Cham, 2017. ISBN 978-3-319-68912-8 978-3-319-68913-5. doi: 10.1007/978-3-319-68913-5. URL http://
link.springer.com/10.1007/978-3-319-68913-5.
Fuchang Gao and Lixing Han. Implementing the Nelder-Mead simplex algorithm with adaptive parameters. Computational Optimization and
Applications, 51(1):259–277, January 2012. ISSN 0926-6003, 1573-2894. doi: 10.1007/s10589-010-9329-3. URL http://link.springer.com/10.1007/
s10589-010-9329-3.
Hiva Ghanbari and Katya Scheinberg. Black-Box Optimization in Machine Learning with Trust Region Based Derivative Free Algorithm. arXiv:
1703.06925 [cs], March 2017. URL http://arxiv.org/abs/1703.06925. arXiv: 1703.06925.
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms. In Advances in neural
information processing systems, pages 2951–2959, 2012.
参考文献](https://image.slidesharecdn.com/miru6-180821073229/75/slide-108-2048.jpg)
![Copyright © GREE, Inc. All Rights Reserved.
Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Sequential Model-Based Optimization for General Algorithm Configuration. In Carlos A. Coello Coello, editor, Learning and
Intelligent Optimization, pages 507–523, Berlin, Heidelberg, 2011. Springer Berlin Heidelberg. ISBN 978-3-642-25566-3.
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. Algorithms for hyperparameter optimization. In Proceedings of the 24th International Conference on Neural
Information Processing Systems, NIPS’11, pages 2546–2554, USA, 2011. Curran Associates Inc. ISBN 978-1-61839-599-3. URL http://dl.acm.org/citation.cfm?id=2986459.2986743.
Jasper Snoek, Oren Rippel, Kevin Swersky, Ryan Kiros, Nadathur Satish, Narayanan Sundaram, Md. Mostofa Ali Patwary, Prabhat Prabhat, and Ryan P. Adams. Scalable bayesian
optimization using deep neural networks. In Proceedings of the 32Nd International Conference on International Conference on Machine Learning - Volume 37, ICML’15, pages 2171–
2180. JMLR.org, 2015. URL http://dl.acm.org/citation.cfm?id=3045118.3045349.
Carl Edward Rasmussen and Christopher K. I. Williams. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning). The MIT Press, 2005. ISBN
026218253X.32
Eric Brochu, Vlad M. Cora, and Nando de Freitas. A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical
Reinforcement Learning. arXiv:1012.2599 [cs], December 2010. URL http://arxiv.org/abs/1012.2599. arXiv: 1012.2599.
Niranjan Srinivas, Andreas Krause, Sham M. Kakade, and Matthias W. Seeger. Information-theoretic regret bounds for gaussian process optimization in the bandit setting. IEEE
Transactions on Information Theory, 58:3250–3265, 2012.
J. Quiñonero-Candela, CE. Rasmussen, and CKI. Williams. Approximation Methods for Gaussian Process Regression, pages 203–223. Neural Information Processing. MIT Press,
Cambridge, MA, USA, September 2007.
Michalis Titsias. Variational learning of inducing variables in sparse gaussian processes. In
David van Dyk and Max Welling, editors, Proceedings of the Twelth International Conference on Artificial Intelligence and Statistics, volume 5 of Proceedings of Machine Learning
Research, pages 567–574, Hilton Clearwater Beach Resort, Clearwater Beach, Florida USA, 16–18 Apr 2009. PMLR. URL http://proceedings.mlr.press/v5/titsias09a.html.
Amar Shah and Zoubin Ghahramani. Parallel predictive entropy search for batch global optimization of expensive objective functions. In Proceedings of the 28th International
Conference on Neural Information Processing Systems - Volume 2, NIPS’15, pages 3330–3338, Cambridge, MA, USA, 2015. MIT Press. URL http://dl.acm.org/citation.cfm?
id=2969442.2969611.
Javier Gonzalez, Zhenwen Dai, Philipp Hennig, and Neil Lawrence. Batch bayesian optimization via local penalization. In Arthur Gretton and Christian C. Robert, editors, Proceedings
of the 19th International Conference on Artificial Intelligence and Statistics, volume 51 of Proceedings of Machine Learning Research, pages 648–657, Cadiz, Spain, 09–11 May 2016.
PMLR. URL http://proceedings.mlr.press/v51/gonzalez16a.html.
参考文献](https://image.slidesharecdn.com/miru6-180821073229/75/slide-109-2048.jpg)
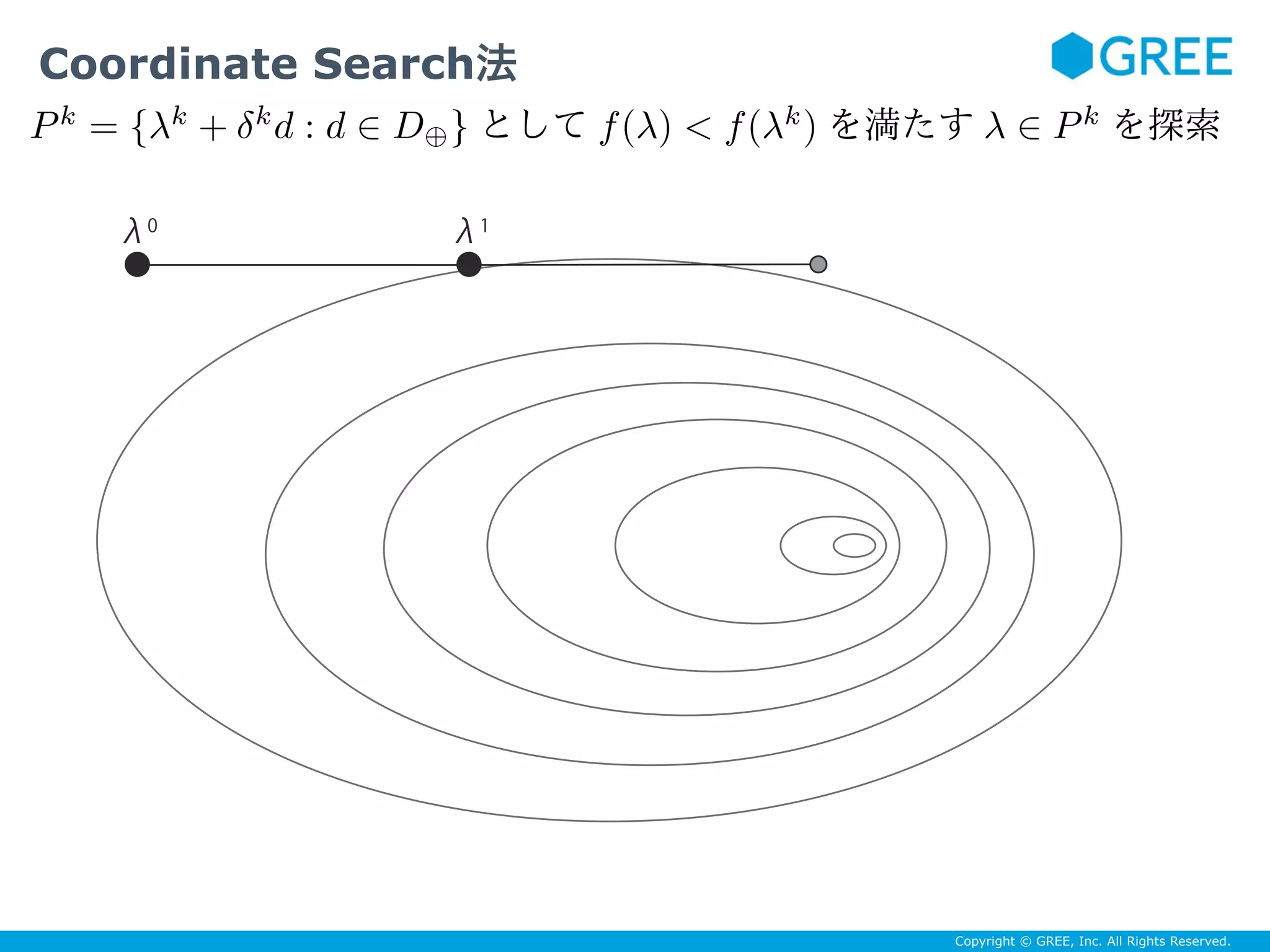
![Copyright © GREE, Inc. All Rights Reserved.
Tarun Kathuria, Amit Deshpande, and Pushmeet Kohli. Batched Gaussian Process Bandit Optimization via Determinantal Point Processes. arXiv:1611.04088 [cs],
November 2016. URL http://arxiv.org/abs/1611.04088. arXiv: 1611.04088.
Kirthevasan Kandasamy, Akshay Krishnamurthy, Jeff Schneider, and Barnabas Poczos. Parallelised bayesian optimisation via thompson sampling. In Amos Storkey
and Fernando
Perez-Cruz, editors, Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 of Proceedings of Machine Learning
Research, pages 133–142, Playa Blanca, Lanzarote, Canary Islands, 09–11 Apr 2018. PMLR. URL http://proceedings.mlr.press/v84/kandasamy18a.html.
Emile Contal, David Buffoni, Alexandre Robicquet, and Nicolas Vayatis. Parallel gaussian process optimization with upper confidence bound and pure exploration. In
Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases - Volume 8188, ECML PKDD 2013, pages 225–240, New York,
NY, USA, 2013. Springer-Verlag New York, Inc. ISBN 978-3-642-40987-5. doi: 10.1007/978-3-642-40988-2_15. URL http://dx.doi.org/10.1007/978-3-642-40988-2_15.
Thomas Desautels, Andreas Krause, and Joel W. Burdick. Parallelizing Exploration-Exploitation Tradeoffs in Gaussian Process Bandit Optimization. Journal of Machine
Learning Research, 15:4053–4103, 2014. URL http://jmlr.org/papers/v15/desautels14a.html.
Erik A. Daxberger and Bryan Kian Hsiang Low. Distributed batch Gaussian process optimization. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th
International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 951–960, International Convention Centre, Sydney,
Australia, 06–11 Aug 2017. PMLR. URL http://proceedings.mlr.press/v70/daxberger17a.html.
Zi Wang, Chengtao Li, Stefanie Jegelka, and Pushmeet Kohli. Batched high-dimensional Bayesian optimization via structural kernel learning. In Doina Precup and Yee
Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 3656–
3664, International Convention Centre, Sydney, Australia, 06–11 Aug 2017. PMLR. URL http://proceedings.mlr.press/v70/wang17h.html.
Zi Wang, Clement Gehring, Pushmeet Kohli, and Stefanie Jegelka. Batched large-scalebayesian optimization in high-dimensional spaces. In Amos Storkey and
Fernando Perez-Cruz, editors, Proceedings of the Twenty-First nternational Conference on Artificial Intelligence and Statistics, volume 84 of Proceedings of Machine
Learning Research, pages 745–754, Playa Blanca, Lanzarote, Canary Islands, 09–11 Apr 2018b. PMLR. URL http://proceedings.mlr.press/v84/wang18c.html.
Ran Rubin. New Heuristics for Parallel and Scalable Bayesian Optimization. arXiv:1807.00373 [cs, stat], July 2018. URL http://arxiv.org/abs/1807.00373. arXiv:
1807.00373.
Watanabe, Shinji, and Jonathan Le Roux. Black box optimization for automatic speech recognition. 2014.
Loshchilov, Ilya, and Frank Hutter. CMA-ES for Hyperparameter Optimization of Deep Neural Networks. 2016.
参考文献](https://image.slidesharecdn.com/miru6-180821073229/75/slide-110-2048.jpg)
![Copyright © GREE, Inc. All Rights Reserved.
Michael Meissner, Michael Schmuker, and Gisbert Schneider. Optimized Particle Swarm Optimization (OPSO) and its application to artificial neural network
training. BMC Bioinformatics, 7(1):125, March 2006. ISSN 1471-2105. doi: 10.1186/1471-2105-7-125. URL https://doi.org/10.1186/1471-2105-7-125.
Shih-Wei Lin, Shih-Chieh Chen, Wen-Jie Wu, and Chih-Hsien Chen. Parameter determination and feature selection for back-propagation network by
particle swarm optimization. Knowledge and Information Systems, 21(2):249–266, November 2009. ISSN 0219-3116. doi: 10.1007/s10115-009-0242-y.
URL https://doi.org/10.1007/s10115-009-0242-y.
Pablo Ribalta Lorenzo, Jakub Nalepa, Luciano Sanchez Ramos, and José Ranilla Pastor. Hyper-parameter selection in deep neural networks using parallel
particle swarm optimization. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, pages 1864–1871. ACM, 2017.
Fei Ye. Particle swarm optimization-based automatic parameter selection for deep neural networks and its applications in large-scale and high-
dimensional data. PLOS ONE, 12 (12):1–36, 2017. doi: 10.1371/journal.pone.0188746. URL https://doi.org/10.1371/journal.pone.0188746.
F. H. F. Leung, H. K. Lam, S. H. Ling, and P. K. S. Tam. Tuning of the structure and parameters of a neural network using an improved genetic algorithm.
Neural Networks, IEEE Transactions on, 14(1):79–88, February 2003. doi: 10.1109/tnn.2002.804317. URL http://dx.doi.org/10.1109/tnn.2002.804317.
Steven R Young, Derek C Rose, Thomas P Karnowski, Seung-Hwan Lim, and Robert M Patton. Optimizing deep learning hyper-parameters through an
evolutionary algorithm. In Proceedings of the Workshop on Machine Learning in High-Performance Computing Environments, page 4. ACM, 2015.
Wei Fu, Tim Menzies, and Xipeng Shen. Tuning for software analytics: Is it really necessary? Information and Software Technology, 76:135 – 146, 2016a.
ISSN 0950-5849. doi: https://doi.org/10.1016/j.infsof.2016.04.017. URL http://www.sciencedirect.com/science/article/pii/S0950584916300738.
Wei Fu, Vivek Nair, and Tim Menzies. Why is Differential Evolution Better than Grid Search for Tuning Defect Predictors? arXiv:1609.02613 [cs, stat],
September 2016b. URL http://arxiv.org/abs/1609.02613. arXiv: 1609.02613.
Samantha Hansen. Using deep q-learning to control optimization hyperparameters. arXiv preprint arXiv:1602.04062, 2016.
Irwan Bello, Barret Zoph, Vijay Vasudevan, and Quoc V Le. Neural optimizer search with reinforcement learning. In International Conference on Machine
Learning, pages 459–468, 2017.
参考文献](https://image.slidesharecdn.com/miru6-180821073229/75/slide-111-2048.jpg)
![Copyright © GREE, Inc. All Rights Reserved.
Xingping Dong, Jianbing Shen, Wenguan Wang, Yu Liu, Ling Shao, and Fatih Porikli. Hyperparameter optimization for tracking with continuous deep q-learning. In Proceedings of
the IEEE Conference on Computer Vision and Pattern Recognition, pages 518–527, 2018.
Dougal Maclaurin, David Duvenaud, and Ryan P. Adams. Gradient-based hyperparameter optimization through reversible learning. In Proceedings of the 32Nd International
Conference on International Conference on Machine Learning - Volume 37, ICML’15, pages 2113–2122. JMLR.org, 2015. URL http://dl.acm.org/citation.cfm?id=3045118.3045343.
Jelena Luketina, Mathias Berglund, Klaus Greff, and Tapani Raiko. Scalable gradientbased tuning of continuous regularization hyperparameters. In Proceedings of the 33rd
International Conference on International Conference on Machine Learning - Volume 48, ICML’16, pages 2952–2960. JMLR.org, 2016. URL http://dl.acm.org/citation.cfm?
id=3045390.3045701.
Fabian Pedregosa. Hyperparameter optimization with approximate gradient. In Proceedings of the 33rd International Conference on International Conference on Machine Learning -
Volume 48, ICML’16, pages 737–746. JMLR.org, 2016. URL http://dl.acm.org/citation.cfm?id=3045390.3045469.
Luca Franceschi, Michele Donini, Paolo Frasconi, and Massimiliano Pontil. On hyperparameter optimization in learning systems. In Proceedings of the 5th International Conference
on Learning Representations (Workshop Track), 2017a.
Luca Franceschi, Michele Donini, Paolo Frasconi, and Massimiliano Pontil. A Bridge Between Hyperparameter Optimization and Larning-to-learn. arXiv:1712.06283 [cs, stat],
December 2017b. URL http://arxiv.org/abs/1712.06283. arXiv: 1712.06283.
Luca Franceschi, Michele Donini, Paolo Frasconi, and Massimiliano Pontil. Forward and reverse gradient-based hyperparameter optimization. In Doina Precup and Yee Whye Teh,
editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1165–1173, International
ConventionCentre, Sydney, Australia, 06–11 Aug 2017c. PMLR. URL http://proceedings.mlr. press/v70/franceschi17a.html.
Luca Franceschi, Paolo Frasconi, Saverio Salzo, Riccardo Grazzi, and Massimiliano Pontil. Bilevel programming for hyperparameter optimization and meta-learning. In Jennifer Dy
and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 1563–1572,
Stockholmsmässan, Stockholm Sweden, 10–15 Jul 2018a. PMLR. URL http://proceedings.mlr.press/v80/franceschi18a.html.
Luca Franceschi, Riccardo Grazzi, Massimiliano Pontil, Saverio Salzo, and Paolo Frasconi. Far-ho: A bilevel programming package for hyperparameter optimization and
metalearning. CoRR, abs/1806.04941, 2018b. URL http://arxiv.org/abs/1806.04941.
Tobias Domhan, Jost Tobias Springenberg, and Frank Hutter. Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves. In
Proceedings of the 24th International Conference on Artificial Intelligence, IJCAI’15, pages 3460–3468. AAAI Press, 2015. ISBN 978-1-57735-738-4. URL http://dl.acm.org/
citation.cfm?id=2832581.2832731.
参考文献](https://image.slidesharecdn.com/miru6-180821073229/75/slide-112-2048.jpg)
![Copyright © GREE, Inc. All Rights Reserved.
Aaron Klein, Stefan Falkner, Jost Tobias Springenberg, and Frank Hutter. Learning curve prediction with bayesian neural networks. 2016.
Akshay Chandrashekaran and Ian R. Lane. Speeding up Hyper-parameter Optimization by Extrapolation of Learning Curves Using Previous Builds.
In Michelangelo Ceci, Jaakko Hollmén, Ljupčo Todorovski, Celine Vens, and Sašo Džeroski, editors, Machine Learning and Knowledge Discovery in
Databases, pages 477–492, Cham, 2017. Springer International Publishing. ISBN 978-3-319-71249-9.
Tobias Hinz, Nicolás Navarro-Guerrero, Sven Magg, and Stefan Wermter. Speeding up the hyperparameter optimization of deep convolutional neural
networks. International Journal of Computational Intelligence and Applications, page 1850008, 2018.
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hyperband: A Novel Bandit-Based Approach to
Hyperparameter Optimization. Journal of Machine Learning Research, 18(185):1–52, 2018. URL http://jmlr.org/papers/v18/16-558.html.
Hadrien Bertrand, Roberto Ardon, Matthieu Perrot, and Isabelle Bloch. Hyperparameter optimization of deep neural networks : Combining
hyperband with bayesian model selection. 2017.
Stefan Falkner, Aaron Klein, and Frank Hutter. Bohb: Robust and efficient hyperparameter optimization at scale. In International Conference on
Machine Learning, pages 1436–1445, 2018b.
Jiazhuo Wang, Jason Xu, and Xuejun Wang. Combination of Hyperband and Bayesian Optimization for Hyperparameter Optimization in Deep
Learning. arXiv:1801.01596 [cs], January 2018a. URL http://arxiv.org/abs/1801.01596. arXiv: 1801.01596.
Jungtaek Kim, Saehoon Kim, and Seungjin Choi. Learning to Warm-Start Bayesian Hyperparameter Optimization. ArXiv e-prints, October 2017.
Jungtaek Kim, Saehoon Kim, and Seungjin Choi. Learning to transfer initializations for bayesian hyperparameter optimization. arXiv preprint arXiv:
1710.06219, 2017.
T Gomes, P Miranda, R Prudêncio, C Soares, and A Carvalho. Combining meta-learning and optimization algorithms for parameter selection. In 5 th
PLANNING TO LEARN WORKSHOP WS28 AT ECAI 2012, page 6. 2012.
参考文献](https://image.slidesharecdn.com/miru6-180821073229/75/slide-113-2048.jpg)





The document discusses hyperparameter optimization in machine learning models. It introduces various hyperparameters that can affect model performance, and notes that as models become more complex, the number of hyperparameters increases, making manual tuning difficult. It formulates hyperparameter optimization as a black-box optimization problem to minimize validation loss and discusses challenges like high function evaluation costs and lack of gradient information.







![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)


















































