Recommended
ODP
ODP
PDF
R language definition3.1_3.2
DOCX
PDF
PDF
PDF
パターン認識 第12章 正則化とパス追跡アルゴリズム
PDF
Haskell勉強会 14.1〜14.3 の説明資料
PDF
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
すごいHaskell読書会 in 大阪 2週目 #5 第5章:高階関数 (2)
PDF
PPTX
PPT
PDF
PPT
PDF
Casual learning machine_learning_with_excel_no7
PDF
PPT
12-11-30 Kashiwa.R #5 初めてのR Rを始める前に知っておきたい10のこと
PDF
PDF
PDF
[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門
PDF
PPTX
PDF
Intoroduction of Pandas with Python
More Related Content
ODP
ODP
PDF
R language definition3.1_3.2
DOCX
PDF
PDF
PDF
パターン認識 第12章 正則化とパス追跡アルゴリズム
PDF
Haskell勉強会 14.1〜14.3 の説明資料
What's hot
PDF
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
すごいHaskell読書会 in 大阪 2週目 #5 第5章:高階関数 (2)
PDF
PPTX
PPT
PDF
PPT
PDF
Casual learning machine_learning_with_excel_no7
PDF
Similar to 第2回R勉強会1
PPT
12-11-30 Kashiwa.R #5 初めてのR Rを始める前に知っておきたい10のこと
PDF
PDF
PDF
[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門
PDF
PPTX
PDF
Intoroduction of Pandas with Python
PDF
PDF
第8回 大規模データを用いたデータフレーム操作実習(2)
PDF
R Language Definition 2.2 to 2.3
PDF
PPTX
PPT
PDF
PDF
PDF
PDF
PDF
PDF
10分で分かるr言語入門ver2.2 13 0223
PDF
10分で分かるr言語入門ver2.9 14 0920
More from Paweł Rusin
PDF
Workflow and development in globally distributed mobile teams
ODP
ODP
ODP
ODP
ODP
第2回R勉強会1 1. パヴェウ・ルシ
ン
株式会社ブリリアントサー
ビス
第2回R勉強会
Rのデータ型について
2. 自己紹介
Paweł Rusin (パヴェウ・ルシン)
pawel.rusin@brilliantservice.co.jp
Facebook: Paweł Rusin
(iofar@o2.pl)
会社:
株式会社ブリリアントサービス
業務:
データマイニング
3. R言語のデータ型
数値型
文字列
ブーリアン型
ベクター
列挙型
リスト
配列
データフレーム
(関数)
4. 数値型
> 42
[1] 42
> -273.15
[1] -273.15
> 2.3e4
[1] 23000
複素数:
> Inf
> 1+1i
[1] Inf
[1] 1+1i
> Inf*100000000000000000
sqrt(-4+0i)
[1] Inf
[1] 0+2i
5. ブーリアン型
> A=TRUE
> B=FALSE
> A==B
[1] FALSE
> A=T #A=TRUE
> B=F #B=FALSE 予約語:
> T = FALSE #できる > FALSE = TRUE
> F = TRUE #できる 以下にエラー FALSE = TRUE :
>T 代入の左辺が不正(do_set)です
[1] FALSE
>F
[1] TRUE
6. 文字列
> string = "This is typical string"
[1] "This is typical string"
文字列の変化:
コマンド 結果
toupper(string) [1] "THIS IS TYPICAL STRING"
gsub("i","o",string) [1] "Thos os typocal strong"
strsplit(string,"i") [[1]]
[1] "Th" "s " "s ntyp" "cal nstr" "ng"
substr(string,4,12) [1] "s is typi"
nchar(string) [1] 22
> cat("This nis nformatted nstring")
This
Is
Formatted
string
7. 1
ベクター: 2 3 4 5 ... x
ベクターという:
● 順番に並べている値のセット
● ベクターには同じような値は要らなければいけない:
1 2 3 4 5 ... x
数値:
7 123 32 -32 0
1 2 3 4 ... x
文字列:
“This” “is” “character” “vec”
1 2 3 4 ... x
ブーリアン値:
TRUE FALSE TRUE FALSE
8. ベクターの作り
方:
vector(mode = "", length = ) c(..., recursive=FALSE)
> vector("integer", 3) > c(1,2,3,4,5)
[1] 0 0 0 [1] 1 2 3 4 5
> integer(3) > c(1:5) # ==1:5
[1] 0 0 0 [1] 1 2 3 4 5
> character(3) > c(5:1) # ==5:1
[1] "" "" "" [1] 5 4 3 2 1
> logical(3) > c(1:5-1) # ==1:5-1
[1] FALSE FALSE FALSE [1] 0 1 2 3 4
seq(...)
rep(x...)
> seq(1,12, by=3)
> rep(1:3,each=2)
[1] 1 4 7 10
[1] 1 1 2 2 3 3
> seq(12,1, by=-3)
[1] 12 9 6 3
9. ベクターの要素をとり方:
> x=-5:-1
>x
[1] -5 -4 -3 -2 -1
> x[3]
[1] -3
> x[2:4]
[1] -4 -3 -2
> x[-2]
[1] -5 -3 -2 -1
> x[c(TRUE,FALSE,FALSE,TRUE,FALSE)]
[1] -5 -2
> x[c(x>-3)]
[1] -2 -1
10. ベクターの名札
1
first
1 2
second 3
third ... x
7 123 32
> y = c(first=1,second=2,third=3) > names(y) = c(„raz”,”dwa”,”trzy”)
>y >y
first second third raz dwa trzy
1 2 3 1 2 3
> y["second"] > names(y)
second [1] raz dwa trzy
2
> y[c("first","third")]
first third
1 3
11. リスト
リストとベターの中に違う?
●
リストでいろいろなデータ型を一緒に使える:
● 数値
● 文字列
● ボーリアン値
● ベクター
● ほかのリストや配列やデータフレームなど
1
age 2
name 3
married 4
languages ... x
27 “Pawel” FALSE “Polish” ?
“English”
“Japanese”
●
リストのデータに名礼を付いて”$”で別の要素が使
12. リスト
> myList = list(27,"Pawel",FALSE,c("Polish","English","Japanese"))
> myList
。。。
> names(myList) =c("age","name","married","languages")
> myList
。。。
> myList =
list(age=27,name="Pawel",married=FALSE,languages=c("Polish","English","Japan
ese"))
> myList
。。。
> myList[2]
$name
[1] "Pawel"
> myList[2]= ”changed”
> myList$name
13. リスト
> myList[4]
$languages
[1] "Polish" "English" "Japanese"
> myList[4] = "x"
> myList[4]
$languages
[1] "x"
> myList[4] = c(”Polish”,”English”,”Japanese”)
警告メッセージ:
In myList[4] = c("Polish", "English", "Japanese") :
置き換えるべき項目数が,置き換える数の倍数ではありませんでした
> myList[[4]] = c(”Polish”,”English”,”Japanese”)
> myList[4]
$languages
[1] "Polish" "English" "Japanese"
> myList[[4]][1]
14. 列挙型
factor(x = character(), levels, labels = levels,
exclude = NA, ordered = is.ordered(x))
> colours = factor(c("白","黒","青","青","白"))
[1] 白 黒 青 青 白
Levels: 黒 青 白
> colours = factor(c("白","黒","青","青","白"), ordered=TRUE)
[1] 白 黒 青 青 白
Levels: 黒 < 青 < 白
> summary(colours)
黒青白
1 2 2
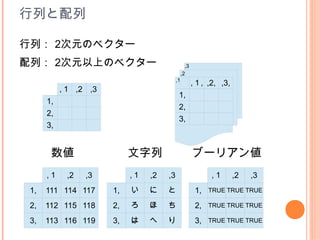
15. 行列と配列
行列: 2次元のベクター
配列: 2次元以上のベクター ,3
,2
,1
,1, ,2, ,3,
,1 ,2 ,3
1,
1,
2,
2,
3,
3,
数値 文字列 ブーリアン値
,1 ,2 ,3 ,1 ,2 ,3 ,1 ,2 ,3
1, 111 114 117 1, い に と 1, TRUE TRUE TRUE
2, 112 115 118 2, ろ ほ ち 2, TRUE TRUE TRUE
3, 113 116 119 3, は へ り 3, TRUE TRUE TRUE
16. 行列と配列
matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE,
dimnames = NULL)
array(data = NA, dim = length(data), dimnames = NULL)
> myMatrix =
matrix(111:119,3,3) > myMatrix[-4]
> myMatrix [1] 111 112 113 115 116 117
[,1] [,2] [,3] 118 119
[1,] 111 114 117 > myMatrix[] = 0
[2,] 112 115 118 > myMatrix
[3,] 113 116 119 [,1] [,2] [,3]
> myMatrix[7] [1,] 0 0 0
[1] 117 [2,] 0 0 0
> myMatrix[,2]
[3,] 0 0 0
[1] 114 115 116
> myMatrix[2] > myMatrix = 0
[1] 112 > myMatrix
> myMatrix[2,] [1] 0
[1] 112 115 118
17. 配列と行列
> myMatrix = matrix(111:119,3,3) apply(myMatrix,1,mean)
> colnames(myMatrix) = [1] 57.0 104.5 58.0
c(„first”,”second”,”third”) apply(myMatrix,2,sum)
> myMatrix = myMatrix/2 [1] 268.0 272.5 118.0
> myMatrix[2,] = myMatrix[2,]+100 x=1:3
> myMatrix[8] = myMatrix[8]*0 myMatrix = cbind(myMatrix,x)
> myMatrix MyMatrix
first second third first second third x
[1,] 55.5 57.0 58.5 [1,] 55.5 57.0 58.5 1
[2,] 156.0 157.5 0.0 [2,] 156.0 157.5 0.0 2
[3,] 56.5 58.0 59.5 [3,] 56.5 58.0 59.5 3
データを接する:
● cbind(x=,y=)
● rbind(x=,y=)
● merge(x=,y=,by=,all=)
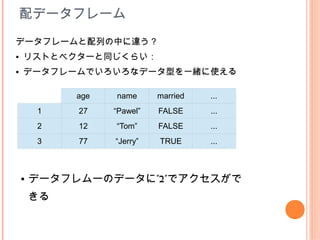
18. 配データフレーム
データフレームと配列の中に違う?
● リストとベクターと同じくらい:
● データフレームでいろいろなデータ型を一緒に使える
age name married ...
1 27 “Pawel” FALSE ...
2 12 “Tom” FALSE ...
3 77 “Jerry” TRUE ...
● データフレムーのデータに”$”でアクセスがで
きる
19. データフレームインポート
data.frame(..., row.names = NULL, check.rows = FALSE,
check.names = TRUE,
stringsAsFactors = default.stringsAsFactors())
> MyDataFrame = data.frame(myMatrix)
read.table(file, header = FALSE, sep = "", quote = ""'", dec = ".", row.names, col.names,
as.is = !stringsAsFactors, na.strings = "NA", colClasses = NA, nrows = -1, skip = 0,
check.names = TRUE, fill = !blank.lines.skip, strip.white = FALSE, blank.lines.skip = TRUE,
comment.char = "#", allowEscapes = FALSE, flush = FALSE, stringsAsFactors =
default.stringsAsFactors(), fileEncoding = "", encoding = "unknown", text)
データフレームを取り込 データフレームを保存す
む: る:
● read.table(file) ● write.table(object,file)
● read.csv(file) ● write.csv(object,file)
● read.delim(file) ● write.delim(object,file)
20. データフレーム
データフレームをエディ
ト:
● edit(dataFrame)
● fix(dataFrame)
● data.entry(dataFrame)
データフレームをプレ
ヴュー:
● head(dataFrame)
● tail(dataFrame)
● Colnames(dataFrame)
● Rownames(dataFrame)
● summary(dataFrame)
● table(dataFrame)
21. ベク
ブーリアン型 リス
ター
ト
ご 清 聴 あ りが と うご ざ い ま し た
列挙
文字列 型
R を 共 に 勉 強 し ま し ょ う!
数値型 配列
データフレー
ム





![数値型
> 42
[1] 42
> -273.15
[1] -273.15
> 2.3e4
[1] 23000
複素数:
> Inf
> 1+1i
[1] Inf
[1] 1+1i
> Inf*100000000000000000
sqrt(-4+0i)
[1] Inf
[1] 0+2i](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-4-320.jpg)
![ブーリアン型
> A=TRUE
> B=FALSE
> A==B
[1] FALSE
> A=T #A=TRUE
> B=F #B=FALSE 予約語:
> T = FALSE #できる > FALSE = TRUE
> F = TRUE #できる 以下にエラー FALSE = TRUE :
>T 代入の左辺が不正(do_set)です
[1] FALSE
>F
[1] TRUE](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-5-320.jpg)
![文字列
> string = "This is typical string"
[1] "This is typical string"
文字列の変化:
コマンド 結果
toupper(string) [1] "THIS IS TYPICAL STRING"
gsub("i","o",string) [1] "Thos os typocal strong"
strsplit(string,"i") [[1]]
[1] "Th" "s " "s ntyp" "cal nstr" "ng"
substr(string,4,12) [1] "s is typi"
nchar(string) [1] 22
> cat("This nis nformatted nstring")
This
Is
Formatted
string](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-6-320.jpg)

![ベクターの作り
方:
vector(mode = "", length = ) c(..., recursive=FALSE)
> vector("integer", 3) > c(1,2,3,4,5)
[1] 0 0 0 [1] 1 2 3 4 5
> integer(3) > c(1:5) # ==1:5
[1] 0 0 0 [1] 1 2 3 4 5
> character(3) > c(5:1) # ==5:1
[1] "" "" "" [1] 5 4 3 2 1
> logical(3) > c(1:5-1) # ==1:5-1
[1] FALSE FALSE FALSE [1] 0 1 2 3 4
seq(...)
rep(x...)
> seq(1,12, by=3)
> rep(1:3,each=2)
[1] 1 4 7 10
[1] 1 1 2 2 3 3
> seq(12,1, by=-3)
[1] 12 9 6 3](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-8-320.jpg)
![ベクターの要素をとり方:
> x=-5:-1
>x
[1] -5 -4 -3 -2 -1
> x[3]
[1] -3
> x[2:4]
[1] -4 -3 -2
> x[-2]
[1] -5 -3 -2 -1
> x[c(TRUE,FALSE,FALSE,TRUE,FALSE)]
[1] -5 -2
> x[c(x>-3)]
[1] -2 -1](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-9-320.jpg)
![ベクターの名札
1
first
1 2
second 3
third ... x
7 123 32
> y = c(first=1,second=2,third=3) > names(y) = c(„raz”,”dwa”,”trzy”)
>y >y
first second third raz dwa trzy
1 2 3 1 2 3
> y["second"] > names(y)
second [1] raz dwa trzy
2
> y[c("first","third")]
first third
1 3](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-10-320.jpg)

![リスト
> myList = list(27,"Pawel",FALSE,c("Polish","English","Japanese"))
> myList
。。。
> names(myList) =c("age","name","married","languages")
> myList
。。。
> myList =
list(age=27,name="Pawel",married=FALSE,languages=c("Polish","English","Japan
ese"))
> myList
。。。
> myList[2]
$name
[1] "Pawel"
> myList[2]= ”changed”
> myList$name](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-12-320.jpg)
![リスト
> myList[4]
$languages
[1] "Polish" "English" "Japanese"
> myList[4] = "x"
> myList[4]
$languages
[1] "x"
> myList[4] = c(”Polish”,”English”,”Japanese”)
警告メッセージ:
In myList[4] = c("Polish", "English", "Japanese") :
置き換えるべき項目数が,置き換える数の倍数ではありませんでした
> myList[[4]] = c(”Polish”,”English”,”Japanese”)
> myList[4]
$languages
[1] "Polish" "English" "Japanese"
> myList[[4]][1]](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-13-320.jpg)
![列挙型
factor(x = character(), levels, labels = levels,
exclude = NA, ordered = is.ordered(x))
> colours = factor(c("白","黒","青","青","白"))
[1] 白 黒 青 青 白
Levels: 黒 青 白
> colours = factor(c("白","黒","青","青","白"), ordered=TRUE)
[1] 白 黒 青 青 白
Levels: 黒 < 青 < 白
> summary(colours)
黒青白
1 2 2](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-14-320.jpg)
![行列と配列
matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE,
dimnames = NULL)
array(data = NA, dim = length(data), dimnames = NULL)
> myMatrix =
matrix(111:119,3,3) > myMatrix[-4]
> myMatrix [1] 111 112 113 115 116 117
[,1] [,2] [,3] 118 119
[1,] 111 114 117 > myMatrix[] = 0
[2,] 112 115 118 > myMatrix
[3,] 113 116 119 [,1] [,2] [,3]
> myMatrix[7] [1,] 0 0 0
[1] 117 [2,] 0 0 0
> myMatrix[,2]
[3,] 0 0 0
[1] 114 115 116
> myMatrix[2] > myMatrix = 0
[1] 112 > myMatrix
> myMatrix[2,] [1] 0
[1] 112 115 118](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-16-320.jpg)
![配列と行列
> myMatrix = matrix(111:119,3,3) apply(myMatrix,1,mean)
> colnames(myMatrix) = [1] 57.0 104.5 58.0
c(„first”,”second”,”third”) apply(myMatrix,2,sum)
> myMatrix = myMatrix/2 [1] 268.0 272.5 118.0
> myMatrix[2,] = myMatrix[2,]+100 x=1:3
> myMatrix[8] = myMatrix[8]*0 myMatrix = cbind(myMatrix,x)
> myMatrix MyMatrix
first second third first second third x
[1,] 55.5 57.0 58.5 [1,] 55.5 57.0 58.5 1
[2,] 156.0 157.5 0.0 [2,] 156.0 157.5 0.0 2
[3,] 56.5 58.0 59.5 [3,] 56.5 58.0 59.5 3
データを接する:
● cbind(x=,y=)
● rbind(x=,y=)
● merge(x=,y=,by=,all=)](https://image.slidesharecdn.com/21-130401030319-phpapp02/85/2-R-1-17-320.jpg)





























![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門](https://cdn.slidesharecdn.com/ss_thumbnails/rlecturehamada100213-100216161757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















