Downloaded 86 times





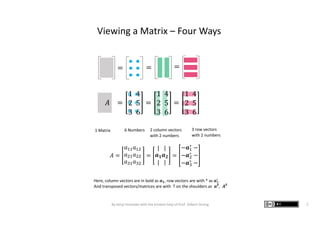
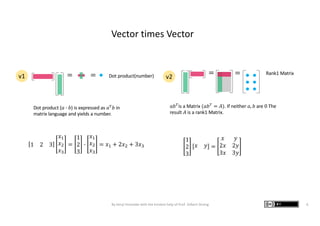
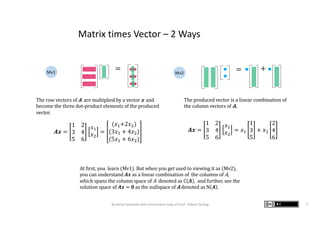
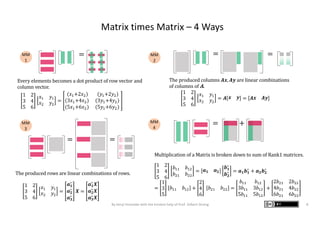
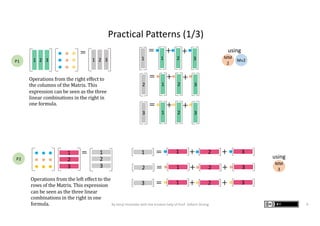
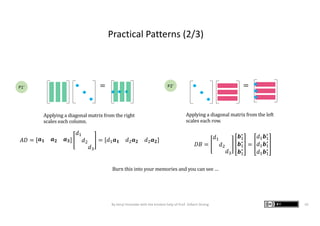
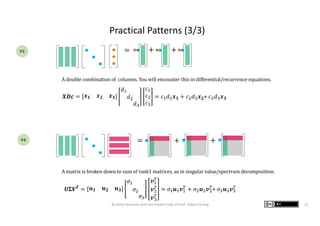
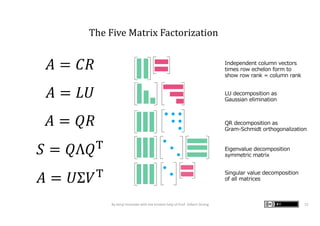

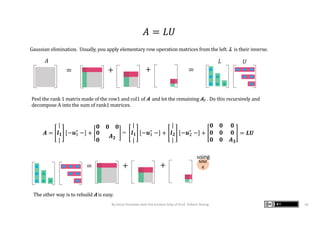





The document presents graphic notes summarizing Professor Gilbert Strang's book 'Linear Algebra for Everyone,' aimed at providing an intuitive understanding of linear algebra concepts through visual illustrations. It highlights key topics such as matrix operations, different multiplication methods, and various matrix factorizations including SVD. Additionally, it serves as an educational resource with links to complementary MIT course materials.

















![Math pdf [eDvArDo]](https://cdn.slidesharecdn.com/ss_thumbnails/mathpdf-140627082926-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























![MATH 564 Advanced Mathematics for Data Science[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/math564advancedmathematicsfordatascience1-250915112031-c023a536-thumbnail.jpg?width=640&height=640&fit=bounds)







































