Download as PDF, PPTX









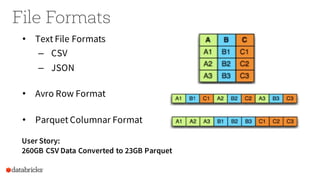

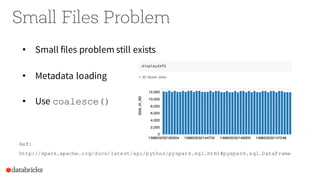




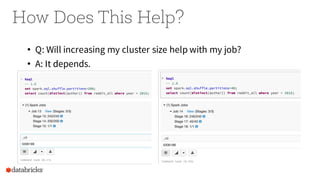

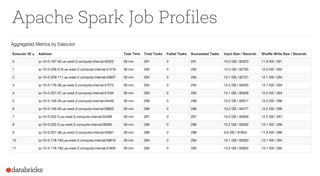
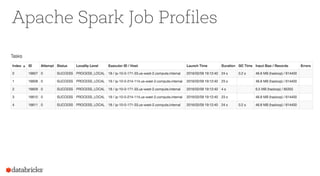
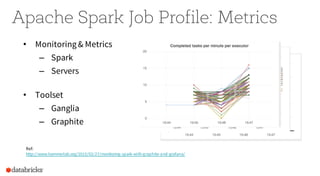







Operational Tips for Deploying Apache Spark provides an overview of Apache Spark configuration, pipeline design best practices, and debugging techniques. It discusses how to configure Spark through command line options, programmatically, and Hadoop configs. It also covers topics like file formats, compression codecs, partitioning, and monitoring Spark jobs. The document provides tips on common issues like OutOfMemoryErrors, debugging SQL queries, and tuning shuffle partitions.
































































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)









