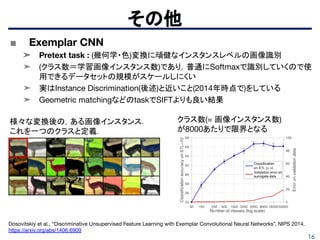
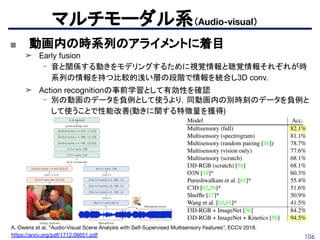
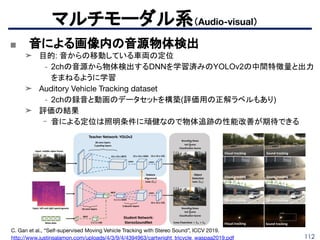
■ 画像から音声を予測
➤ 画像からの音声予測がオブジェクトとシーンに関する情報を学習していることに着
目して、学習した特徴量を画像認識に適用させる。
➤(a)画像から(c)音声特徴量を予測
➤ Fast R-CNNの事前学習に適用したけど、ImageNetとは差がある。
➤ 論文紹介:Ambient Sound Provides Supervision for Visual Learning(CV勉強会ECCV…
マルチモーダル系
➁
⑤
Andrew Owens et al, “Ambient Sound Provides Supervision for Visual Learning”, ECCV 2016.
https://arxiv.org/pdf/1608.07017.pdf
27
28.
28
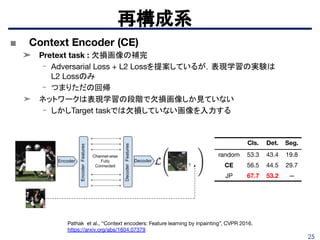
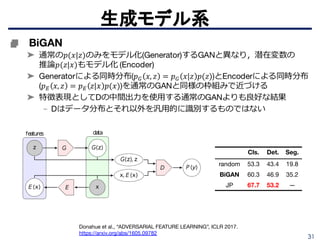
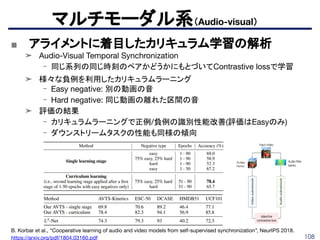
■ グレースケール画像を自動的にカラー化
➤ 各ピクセルを取り、その周囲を見て、もっともらしい色の分布(ヒストグラム)
を予測
➤CNNを用いて意味解析とローカリゼーションを
カラー化システムに組み込む。
➤ 基本ネットワークにはVGG16を用いている。
- 事前学習はImageNetなど。
再構成系
Larsson, Gustav et al, “Learning Representations for Automatic Colorization”, ECCV 2016.
https://arxiv.org/pdf/1603.06668.pdf
Fig. 2: System overview. We process a grayscale image through a deep convolutional
architecture (VGG) [37] and take spatially localized multilayer slices (hypercolumns) [15, 26, 28],
as per-pixel descriptors. We train our system end-to-end for the task of predicting hue and
chroma distributions for each pixel p given its hypercolumn descriptor. These predicted
distributions determine color assignment at test time.
29.
29
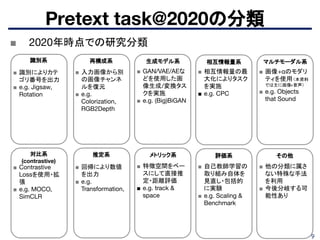
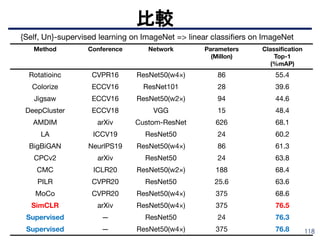
■ 大規模な画像データに対してグラフベースの分析を活用
➤ グラフ分析により画像間の根本的な意味の類似性を発見できるはず
➤各画像をノードとして、各最近傍マッチングペアをエッジとして表すことによ
り、k-最近傍(k -NN)グラフを作成
➤ 教師なし特徴学習と半教師あり学習の設定で、提案する教師なし制約マイニ
ング手法の有効性を示している。
その他
D. Li et al., “Unsupervised Visual Representation Learning by Graph-Based Consistent Constraints.” ECCV 2016.
https://faculty.ucmerced.edu/mhyang/papers/eccv16_feature_learning.pdf
Pascal Voc 2007での比較
32
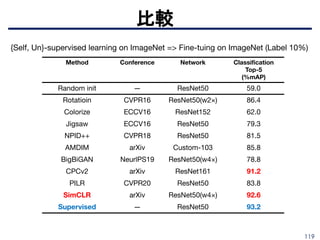
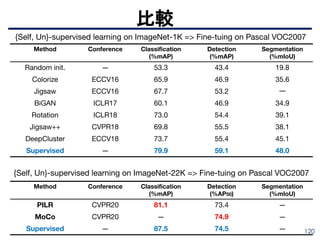
■ TextTopicNet
➤ マルチモーダル(テキスト&イメージ)ドキュメントの大規模コーパスをマイニ
ングすることにより、視覚的特徴の自己教師学習を実行することを提案
➤テキストコーパスに対して、よく知られたトピックモデリング手法(LDA) に
よって発見された非表示の意味構造を活用
- (1)相関するテキストと画像のペアで構成されるデータセットのテキス
トコーパスに関するトピックモデルを学習
- (2)深いCNNモデルをトレーニングして、画像のピクセルから直接テキ
スト表現(トピック確率)を予測
マルチモーダル系
L.Gomez et al., “Self-supervised learning of visual features through embedding images into text topic spaces”, CVPR2017.
https://arxiv.org/pdf/1705.08631.pdf
Figure 1: Our CNN learns to predict the semantic context in which images appear as illustration. Given an illustrated article we project its
textual information into the topic-probability space provided by a topic modeling framework. Then we use this semantic level
representation as the supervisory signal for CNN training
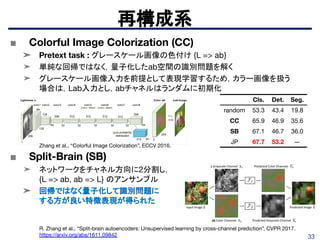
Table 3 compares our results for image classification and object detection
on PASCAL with different self-supervised learning algorithms.
34
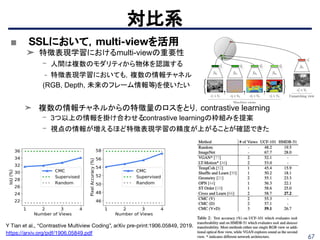
■ Split-Brain Autoencoders
➤ネットワークをチャネル方向に半分に分割して、2つの互いに素なサブネット
ワークを作成。各サブネットワークは、別のサブセットからのデータの1つの
サブセットに対して予測を実行するようにトレーニングされる。
➤ Fast R-CNNを使用し、セグメンテーションは、20の対象オブジェクトの1つ
または背景のいずれかであるオブジェクトクラスのピクセル単位のラベリン
グされているものでの評価もしている。
➤ Lab画像だけでなく、RGB-Dデータに対してもSplit-Brain Autoencodersが
有効だと示す。
再構成系
R. Zhang et al., "Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction", CVPR2017.
https://arxiv.org/abs/1611.09842
(Left) Images Half of the network predicts color channels from grayscale, and the other half predicts grayscale from color.
(Right) RGB-D Images Half of the network predicts depth from images
35.
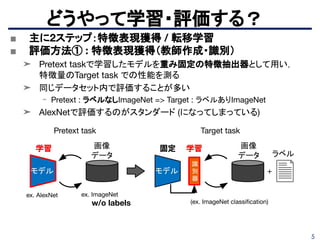
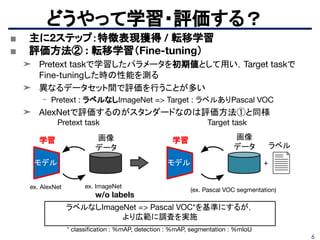
■ モーションベースのセグメンテーションを使用してオブジェクト検
出に応用している。
➤ Pretexttask : 動画のモーションを利用して付られたセグメントラベルを使用したセ
グメンテーション
➤ 計算やデータの制約による分析をして、約27Mの相関フレームを使用すると
ImageNetで訓練したのと同等の結果を示す。
https://people.eecs.berkeley.edu/~pathak/unsupervised_video/
再構成系
➁
⑤
D. Pathak et al., "Learning Features by Watching Objects Move," CVPR2017.
https://people.eecs.berkeley.edu/~pathak/papers/cvpr17.pdf 35
36.
36
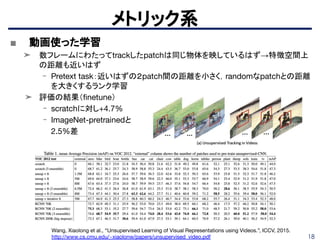
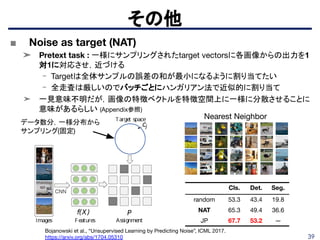
■ Pretext taskとして自動カラー化の可能性
➤打倒 ImageNet pretrainを目指し,自動カラー化の可能性を模索
➤ 損失、ネットワークアーキテクチャ、
およびトレーニングの詳細の重要性を調査している。
➤ カラーとグレースケールの差や、アーキテクチャ別にランダムな
初期値を設けた場合と、カラー画像のpre-trainの比較をしている。
再構成系
➁
⑤
Larsson Gustav et al., “Colorization as a Proxy Task for Visual Understanding”, CVPR 2017.
https://arxiv.org/pdf/1703.04044.pdf
58
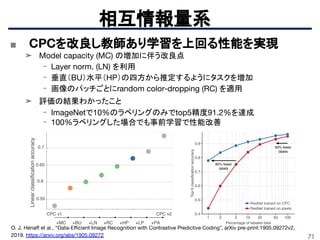
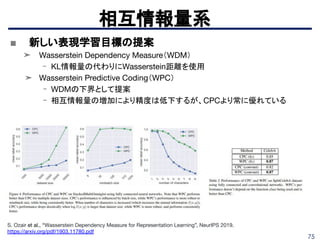
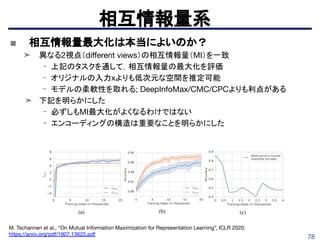
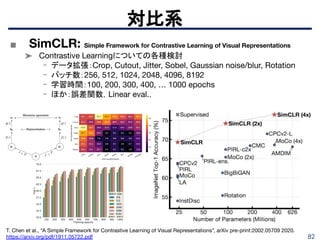
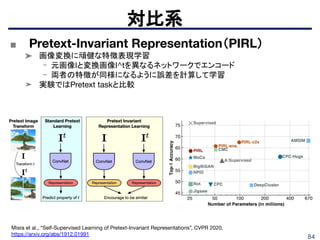
相互情報量系
Devon Hajelm etal., “Learning deep representations by mutual information estimation and maximization”, arXiv
pre-print:1808.06670, 2018. https://arxiv.org/abs/1808.06670
Tiny ImageNetにおいて教師ありに近い精度
59.
59
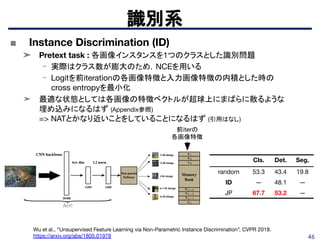
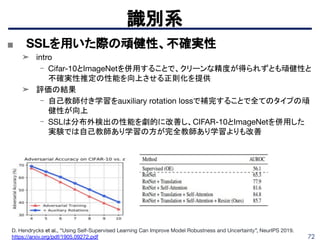
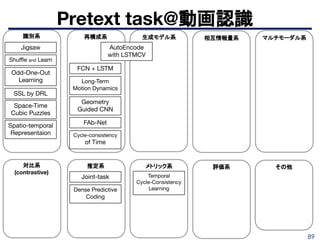
識別系
Ali Diba, VivekSharma, Luc Van Gool, Rainer Stiefelhagen, “DynamoNet: Dynamic Action and Motion Network”, ICCV 2019.
https://arxiv.org/pdf/1904.11407.pdf
■ DynamoNet: Dynamic Action and Motion Network
➤ 現在までのフレームにおける人物の行動から次のフレームにおける行動を予測す
ることで特定の行動特有の学習し、高次な特徴表現を獲得
➤ 動画識別と次フレーム予測をマルチタスク学習
95
再構成系
■ Geometry GuidedCNN
➤ 2ステップで学習
- 1st Pretext task: sythetic imageでoptical flowを学習
- 使いやすDBでflowを学習できる
- 2nd Pretext task: 3D moviesでdisparity map(depth)を学習
- real domainに寄せる
- 2ndを学習するときに1stを忘れないように蒸留とLwFを活用
➤ SceneRecogで従来手法よりも高い性能を発揮
- 1stと2ndをどちらもやることで精度が向上
- ImageNetとのensembleで精度向上(異なる部分を見てる)
C Gan et. al, “Geometry Guided Convolutional Neural Networks for Self-Supervised Video Representation
Learning”, CVPR 2018. http://ai.ucsd.edu/~haosu/papers/cvpr18_geometry_predictive_learning.pdf
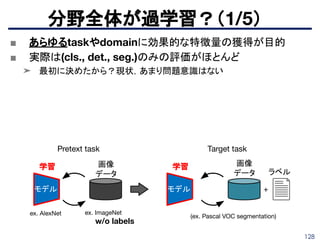
96.
96
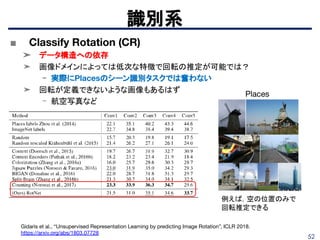
識別系
■ 訓練用データのシャッフルを強化学習で最適化
➤ JigsawやShuffle&Learnでは
シャッフルしたパッチやフレームを入力し、正しい順序を識別
-これまではシャッフルの仕方は固定
- 本研究ではRLで訓練中のCNNの状態に合ったシャッフルを行う
➤ 空間・時間領域ごとにDRLを学習
- DRLはシャッフルした後の順序を出力
- 報酬はval error、状態はsoftmaxをgather staticsticsしたもの
➤ DRL: 2 FC layers, CNN: CaffeNet
B Brattoli et. al., “Improving Spatiotemporal Self-Supervision by Deep Reinforcement Learning”, ECCV 2018.
https://arxiv.org/abs/1807.11293
97.
97
再構成系
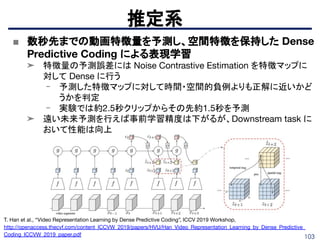
■ Facial Attributes-Net(FAb-Net)
➤ Pretext task: sourceフレームとtargetフレームを入力して
targetフレームを生成する
- encoderは顔のアトリビュートをembeddingする
- decoderはsourceとtargetのembeddingのcaoncatから
sourceからtargetへの変化を推定し、
bilinear samplingでtargetを生成する
- Curriculum Leaningを使用(バッチの損失でランクを設定)
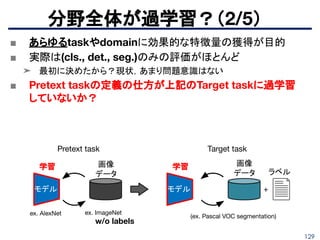
➤ ランドマーク・ポーズ推定等で教師ありに近い性能を発揮
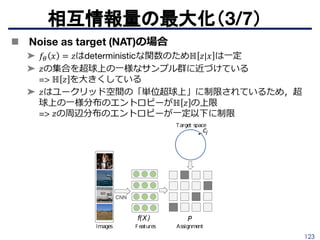
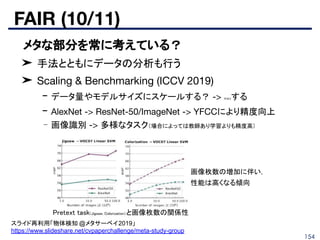
Wiles O. et. al., “Self-supervised learning of a facial attribute embedding from video”, BMVC 2018.
http://www.robots.ox.ac.uk/~vgg/publications/2018/Wiles18a/wiles18a.pdf
98.
98
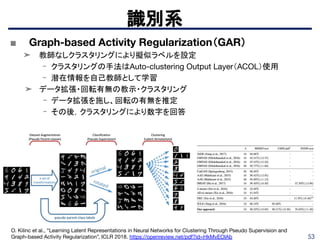
識別系
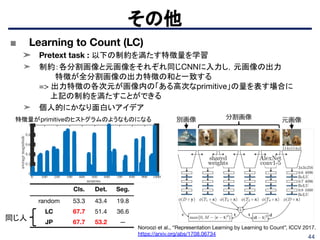
■ Space-Time CubicPuzzles
➤ Pretext task: 時間方向と空間方向のタスクを同時学習(左図参照)
- 時間方向(フレーム並べ替え): 59.3@UCF101
- 空間方向(Jigsaw Puzzle): 58.5@UCF101
➤ 3D CNNを高度に学習(右表参照)
- C3Dにて60.6@UCF101, 28.3@HMDB51
- 3D ResNet-18にて65.8@UCF101, 33.7@HMDB51
D. Kim et al., “Self-Supervised Video Representation Learning with Space-Time Cubic Puzzles,” AAAI 2019.
https://arxiv.org/pdf/1811.09795.pdf
Pretext taskのイメージ図.空間(Jigsaw Puzzle)と時間(フ
レーム並べ替え)を同時に実行する.動画像の特性をうまく
利用した学習体系となっている.
Pretext taskにSpace-Time Cubic Puzzles(3D ST-puzzle)を用いた結果
を表示.従来ではUCF101にて50%代であったが,精度を大幅に向上する
ことに成功した.
99.
99
識別系
■ 人間の認知システムに倣った動き推定タスク
➤ pretexttask : 動画の1フレームをパッチに分割し,動きが最大のパッチ・
動きの多様性が最大のパッチ・動きが最小のパッチを推定
- 人間は動きが最も大きい部分(物体)と動きが最も小さい部分(背景)を
分けて近くすることに着目
- 様々なパッチ分割(格子状・
放射状など)で検証
- 行動認識,シーン理解などの
タスクにおいてSSLのSOTAを更新
J.Wang et al, “Self-supervised Spatio-temporal Representation Learning for VIdeos by predicting motion and appearance
statistics”, CVPR2019. https://arxiv.org/pdf/1904.03597.pdf
100.
100
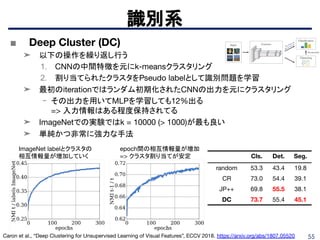
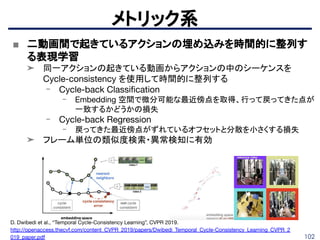
再構成系
X Wang etal., “Learning Correspondence from the Cycle-consistency of Time”, CVPR 2019.
https://arxiv.org/pdf/1904.11407.pdf
■ Cycle-consistency of Time
➤ 動画内のパッチを逆再生である時点までトラッキングし,開始時点まで再びトラッキ
ング
→ 開始時と終了時のパッチの空間座標のユークリッド距離を最小化する
cycle-consistency loss(左図)
➤ mask, pose等複数のpropagationタスクで自己教師の中でSOTA
DAVIS-2017でのmask propagationの評価
143
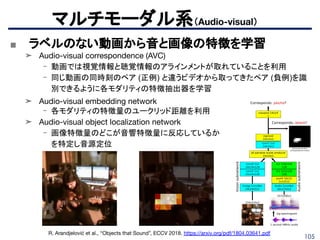
■ Cross-modal SSLを先導
➤MIT CSAILでPh.D,現在は同Reserach Scientist
➤ Speech/spoken languageとvisualのcross-modalに早くか
ら着手 (ASRU2015)
➤ ECCVとACLにfirst1本ずつ(ICASSP, Interspeech等多数)
➤ 代表的な論文
David Harwath(6/7)
- Deep Multimodal Semantic Embeddings for
Speech and Images (ASRU 2015)
- Unsupervised Learning of Spoken Language
with Visual Context (NIPS 2016)
- Jointly discovering visual objects and spoken
words from raw sensory input (ECCV 2018)
- Learning Hierarchical Discrete Linguistic Units
from Visually-Grounded Speech (ICLR 2019)
https://people.csail.mit.edu/
dharwath/
144.
144
■ CV・マルチビュー幾何学の第一人者
➤ Univ.of Oxford, VGGの教授
➤ DeepMindにも所属・提携している
➤ Mulitple View Geometry in Computer Vision著者
- R. Hartley氏との共著でCV分野において不朽の名作
- 数学の説明が素晴らしい!
➤ VGGNetの著者でもある(CVなら大体なんでもすごい!)
➤ 動画系のSSLも空間特徴・数学の観点から攻めている印象
➤ 代表的な論文
- Very Deep Convolutional Networks for Large-Scale Image Recognition
(ICLR 2015)
- Multiple view geometry in computer vision
(Cambridge University Press 2000)
- The pascal visual object classes (VOC) challenge
(International Journal of Computer Vision 2010)
- Temporal Cycle Consistency Learning (CVPR 2019)
- Two-stream convolutional networks for action recognition in videos
(NeurIPS 2014)
Andrew Zisserman(7/7)
https://www.robots.ox.ac.uk/~az/
157
■ VGGの代表研究
➤ MultipleView Geometry in Computer Vision
- 研究ではないが,不朽の名作にしてMulti-view Geometryの入門書
- CVのカメラ幾何について詳細に解説
- R. Hartley, A. Zisserman, “Multiple View Geometry in Computer Vision”, Cambridge University Press.
➤ VGGNet
- GoogLeNetと並びDeeper Networkの走り(その後ResNetへ継承)
- StyleTransferやAdversarial Examplesでは現在も使用され研究が進め
られている
- K. Simonyan, A. Zisserman, “Very Deep Convolutional Networks for Large-scale Image Recognition”, in NIPS 2014.
➤ Pascal VOC
- 物体検出において最初のデファクトスタンダード
- 物体検出の研究が劇的に進捗する礎となった
- M. Everingham, L. V. Gool, C. Williams, J. Winn, A. Zisserman, “The Pascal Visual Object Classes (VOC) Challenge”, in IJCV 2010.
VGG(2/5)
158.
158
■ 最近の自己教師学習や関連研究
➤ SingleImage Self-supervision(論文サマリ参照)
- 1枚,もしくは少量(10〜100枚)の画像から自己教師学習
- 初期層(Conv1, 2)は1枚の画像から十分学習可能と判断
➤ Deep Image Prior
- 画像の事前情報からノイズ等を除去して再構成
- 画像の自然さと再構成誤差を計算して学習
➤ Learnable PINS: Cross-Modal Embeddings for Person Identity
- 音声と顔の動画のペアデータを用いて個人を識別できる埋め込み空
間を人手のラベリングなしで獲得
➤ その他多数!
VGG(3/5)
Yuki M. Asano et al., “A Critical Analysis of Self-supervision, or What We Can Learn From a Single Image”, ICLR 2020/05.
https://openreview.net/forum?id=B1esx6EYvr
D. Ulyanov et al., “Deep Image Prior”, CVPR 2018.
https://sites.skoltech.ru/app/data/uploads/sites/25/2018/04/deep_image_prior.pdf
A. Nagrani et al., “Learnable PINS: Cross-Modal Embeddings for Person Identity”, ECCV 2018.
https://arxiv.org/pdf/1805.00833.pdf





![8
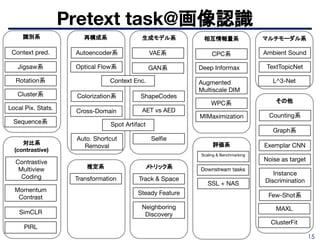
Pretext task@2018の分類
Context pred.
識別系 再構成系 生成モデル系 その他
Spot Artifact
Colorization
Split-brain
VAE系
GAN系
Instance
Discrimination
Jigsaw
Jigsaw++
Rotation
Counting
■ 2018前半までの研究を分類 ([Noroozi+, ICCV17]参照)
■ 便宜上の分類であることに注意
➤ アイデアベースの手法が多いこともあり,分類が非常に困難
Autoencoder系
Context Encoder
Noise as target
Exemplar CNN
http://hirokatsukataoka.net/temp/cvpaper.challenge/SSL_0929_final.pdf より引用](https://image.slidesharecdn.com/meta-ssl-200430082709/85/Self-Supervised-Learning-8-320.jpg)














![28
■ グレースケール画像を自動的にカラー化
➤ 各ピクセルを取り、その周囲を見て、もっともらしい色の分布(ヒストグラム)
を予測
➤ CNNを用いて意味解析とローカリゼーションを
カラー化システムに組み込む。
➤ 基本ネットワークにはVGG16を用いている。
- 事前学習はImageNetなど。
再構成系
Larsson, Gustav et al, “Learning Representations for Automatic Colorization”, ECCV 2016.
https://arxiv.org/pdf/1603.06668.pdf
Fig. 2: System overview. We process a grayscale image through a deep convolutional
architecture (VGG) [37] and take spatially localized multilayer slices (hypercolumns) [15, 26, 28],
as per-pixel descriptors. We train our system end-to-end for the task of predicting hue and
chroma distributions for each pixel p given its hypercolumn descriptor. These predicted
distributions determine color assignment at test time.](https://image.slidesharecdn.com/meta-ssl-200430082709/85/Self-Supervised-Learning-28-320.jpg)





























































































![FAIR (9/11)
153
■ FAIRのデータ基盤
➤ Facebook/Instagramを使用
➤ SNSを用いた弱教師によるPre-trainの実行(下図)
- Hashtagでラベル付/スケール増加
- 35億枚の画像により特徴表現学習(Instagram-3.5B; IG-3.5B)
- 2019年は動画版を作成(Instagram-65M; IG-65M)
[Mahajan+, ECCV18]
FBはSNSのHashtagでラベル付けなし,弱教師付き
の3.5B枚画像DB構築
https://arxiv.org/abs/1911.12667
IG-65MはCross-Modal
Deep Clustering (XDC)
にも使用
スライド再利用「物体検知 @メタサーベイ2019」
https://www.slideshare.net/cvpaperchallenge/meta-study-group](https://image.slidesharecdn.com/meta-ssl-200430082709/85/Self-Supervised-Learning-153-320.jpg)









![164
■ ~2018からの差分
➤ JigSaw, rotationなどのアイディアベースの学習をさらに発展させたもの
の展開
- 思いつくような手法は出尽くし,それらをさらに改善するという流れ?
➤ マルチモーダル系の台頭
- 人間の特徴学習に習って五感を全て使おう!という考え
- データさえ揃えば新規性になるという手軽さ
➤ 距離学習など,より理論的にいい表現学習を目指した研究が増えてきたか
も?
- 数学勢の参入も近い
メタサーベイのメモ [Bonus Slide]](https://image.slidesharecdn.com/meta-ssl-200430082709/85/Self-Supervised-Learning-164-320.jpg)
![165
■ 動画認識のためのSSLの論文を読んで感じたこと
➤ 動画データセットのほうが画像のみの物よりタスクを複雑にできる
- フレーム順序/OFを学習に用いることで、
時間方向の成分を見るようになっていそう
- 画像認識のためのSSLでも使えそう(実際にあった)
➤ 動画認識のPretext taskはまだアイディア出しの段階?
- 他の手法を改善したようなものが少ないため
- 手法の変遷:
→フレームをシャッフル
→オプティカルフロー / 未来のフレームを予測
→複数のタスクを組み合わせる
- 最近はロスを工夫するものも出てきているみたい
- 各手法を評価している論文は少なそう
➤ 動画認識のSSLならアイディア・改良・評価の論文に
まだチャンスがありそう
メタサーベイのメモ [Bonus Slide]](https://image.slidesharecdn.com/meta-ssl-200430082709/85/Self-Supervised-Learning-165-320.jpg)














![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]One Model To Learn Them All](https://cdn.slidesharecdn.com/ss_thumbnails/dljp20170714ono-170714005853-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)


