Download as PDF, PPTX







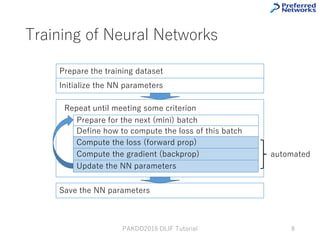
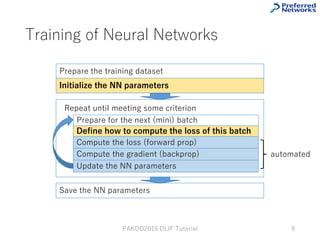




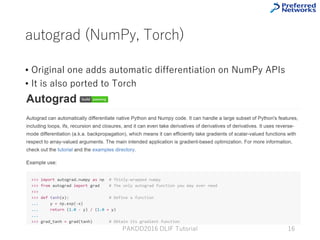


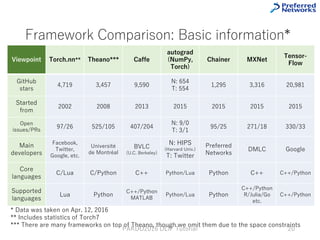

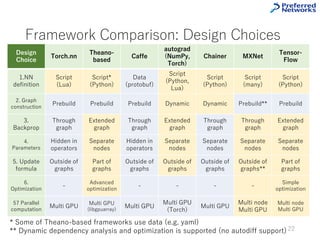









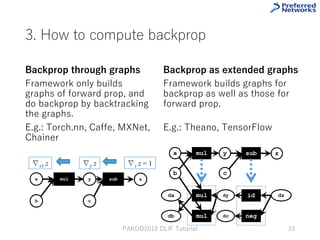


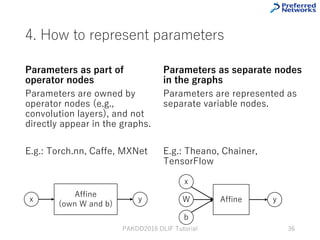









This tutorial provides an overview of deep learning frameworks, focusing on the design choices that differentiate them, including how neural networks are defined and how computational graphs are constructed. It highlights several frameworks like TensorFlow, Theano, and PyTorch, discussing their strengths and weaknesses in relation to performance and ease of use. The conclusion emphasizes the importance of selecting a framework that aligns with user preferences and requirements for deep learning tasks.






















































































