Download to read offline







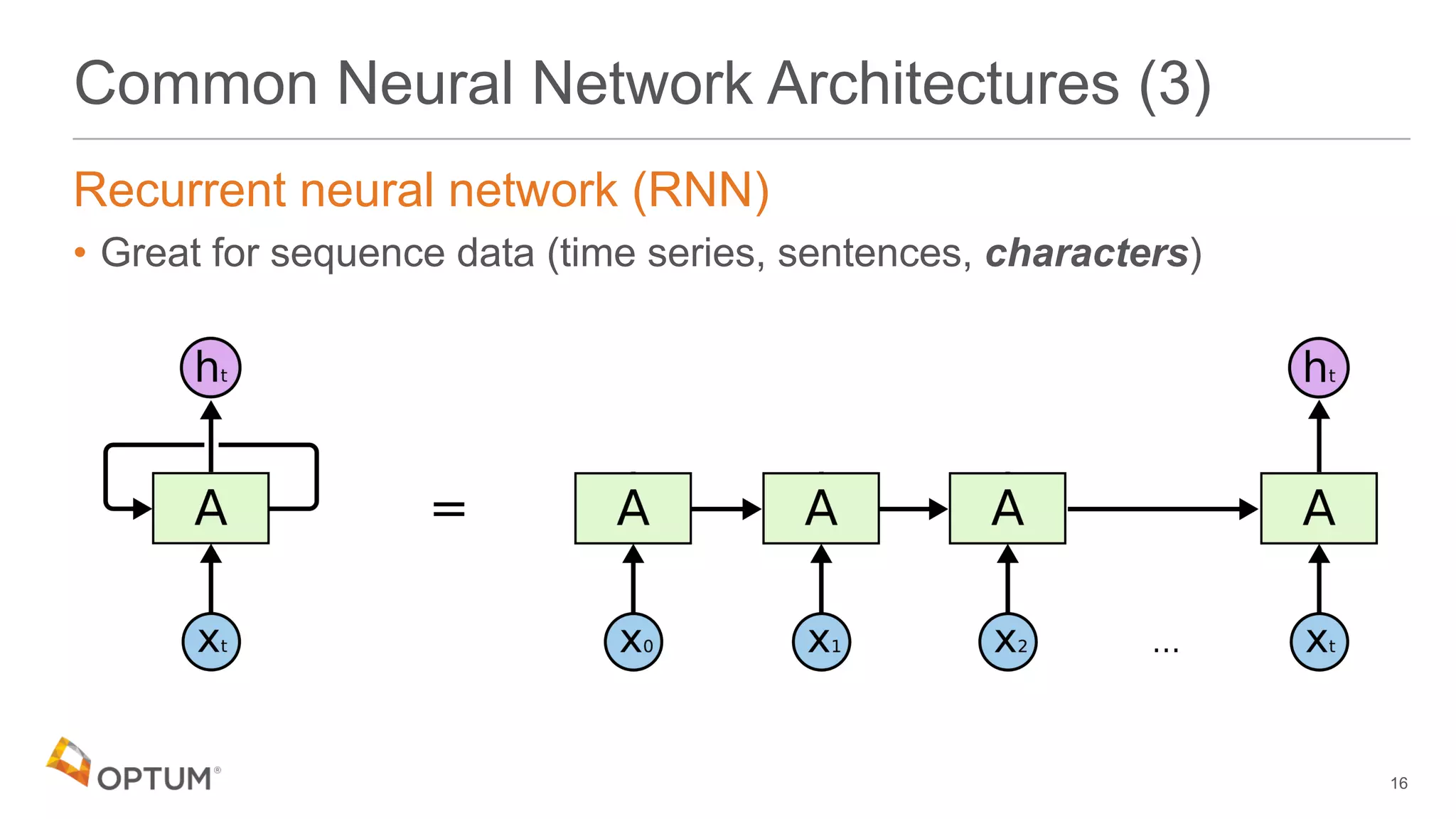
![RNNs for Text
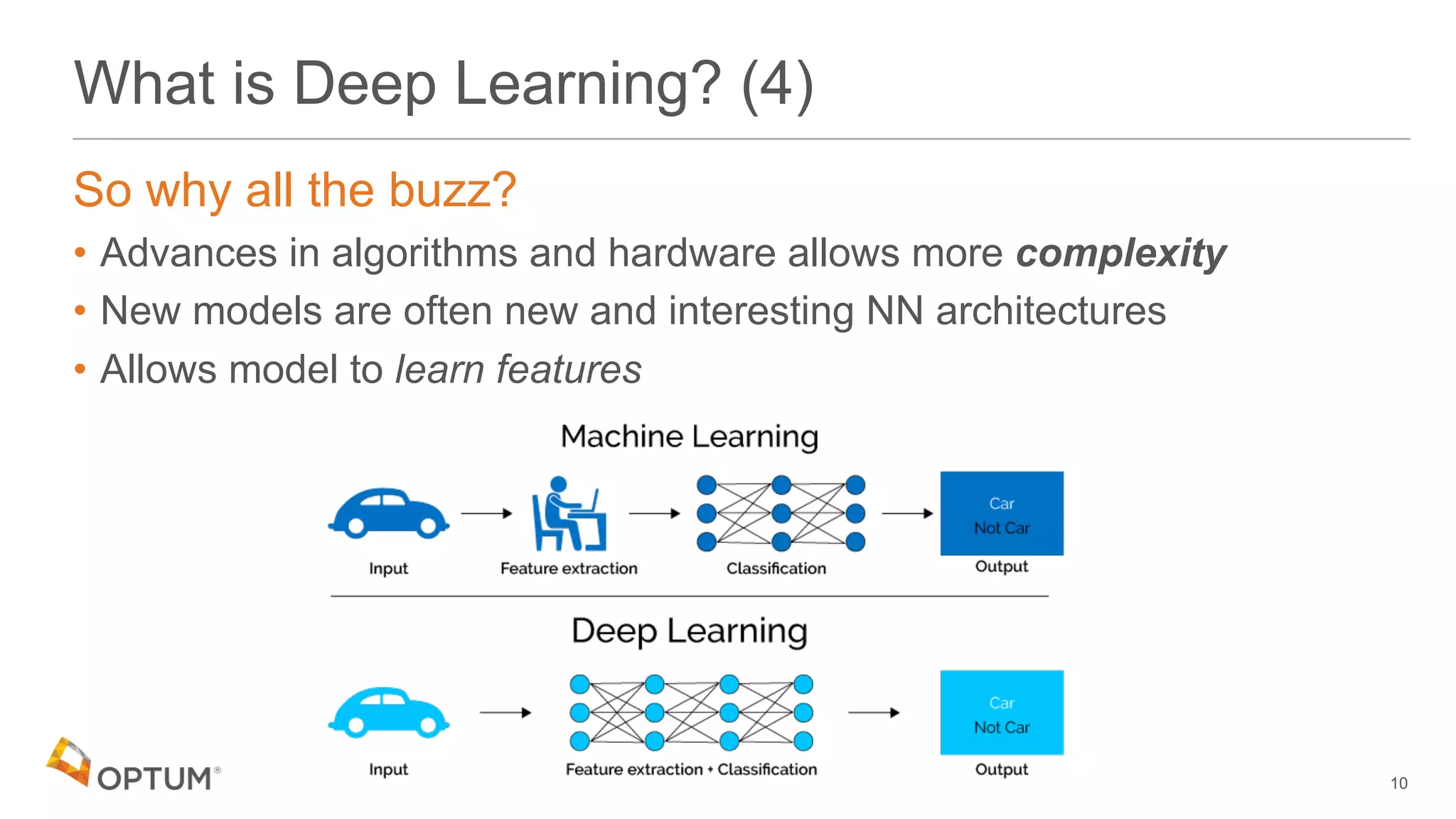
Word level RNN
• Input sequence is an array or words:
Character level RNN
• Input sequence is an array or characters:
17
'the quick brown fox jumped…' ['the','quick','brown',…]
'the quick brown fox jumped…' ['t','h','e',' ','q',…]](https://image.slidesharecdn.com/deepdomain-180531210834/75/Deep-Domain-17-2048.jpg)




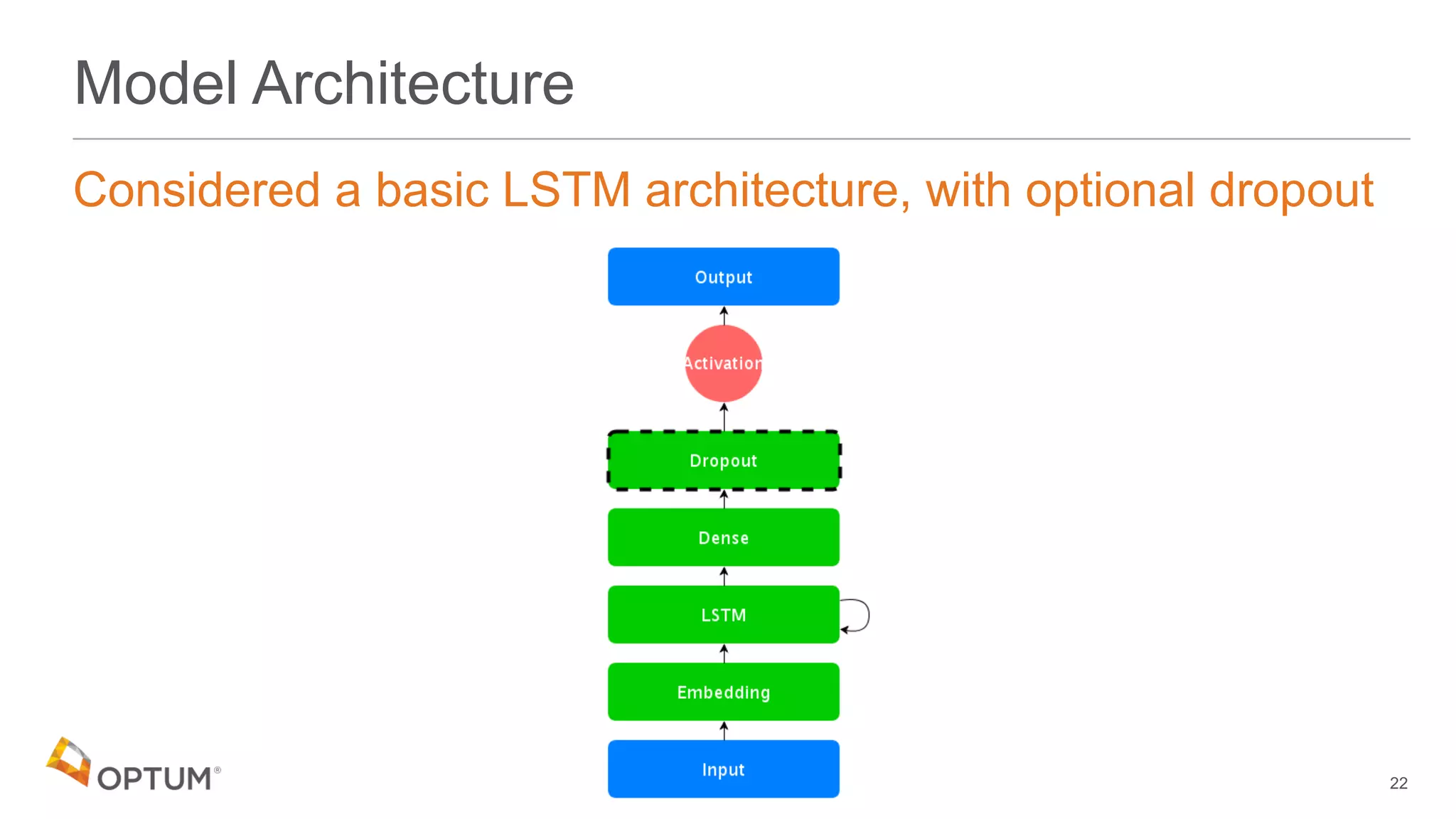
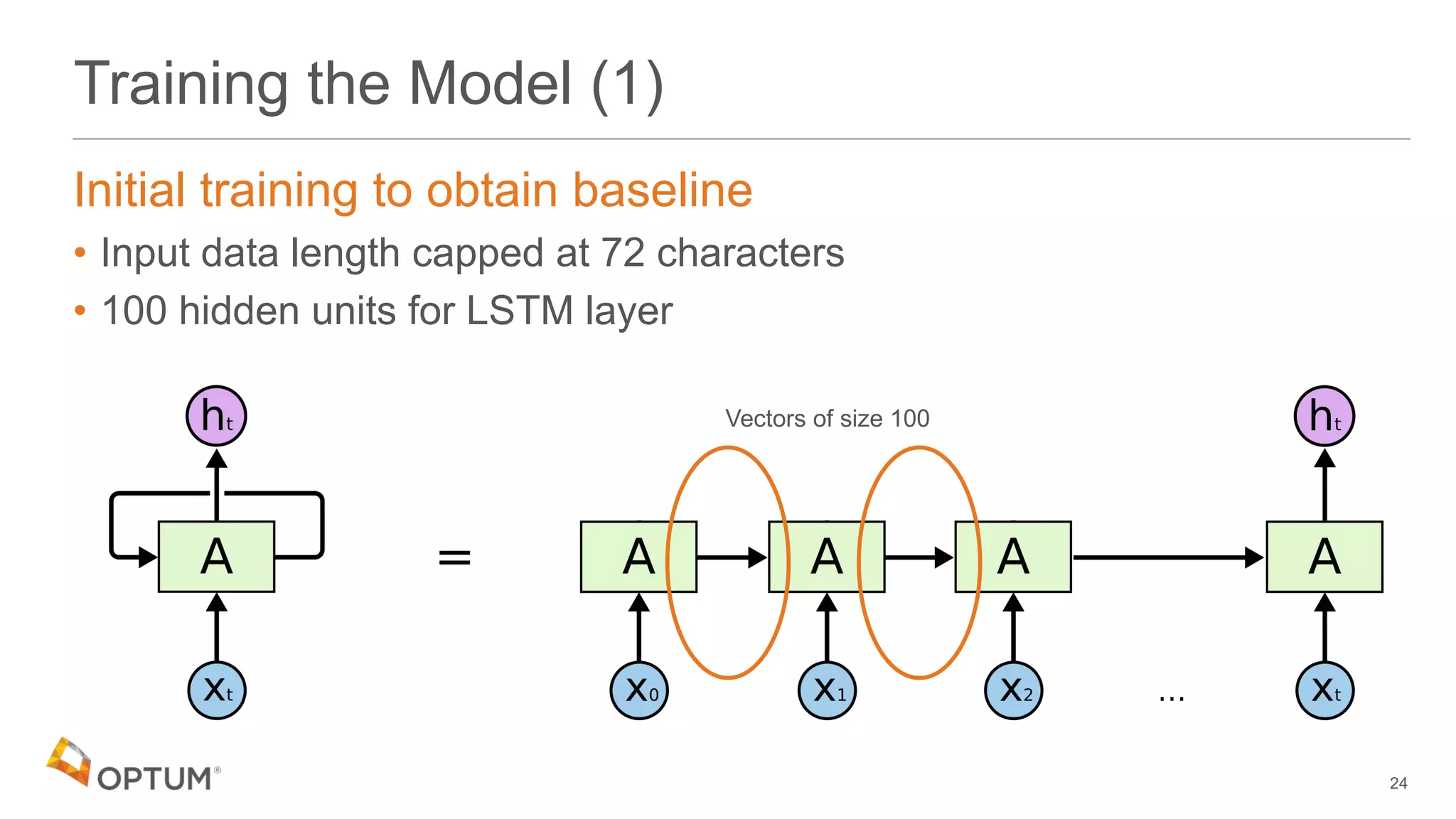
![Training the Model (1)
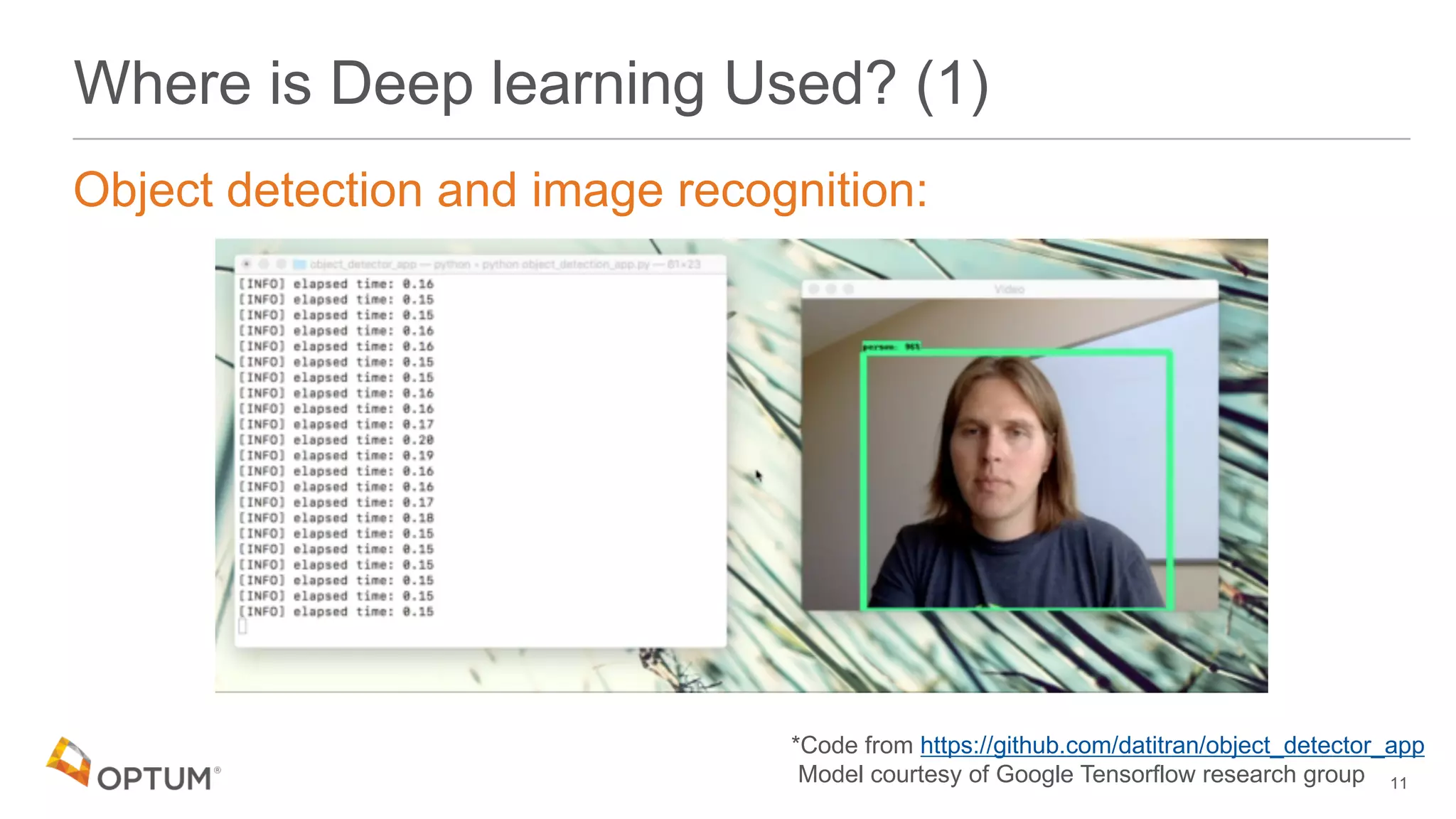
Initial training to obtain baseline
• Input data length capped at 72 characters
23
'the quick brown fox jumped…' ['t','h','e',' ','q',…]
72 characters max](https://image.slidesharecdn.com/deepdomain-180531210834/75/Deep-Domain-23-2048.jpg)

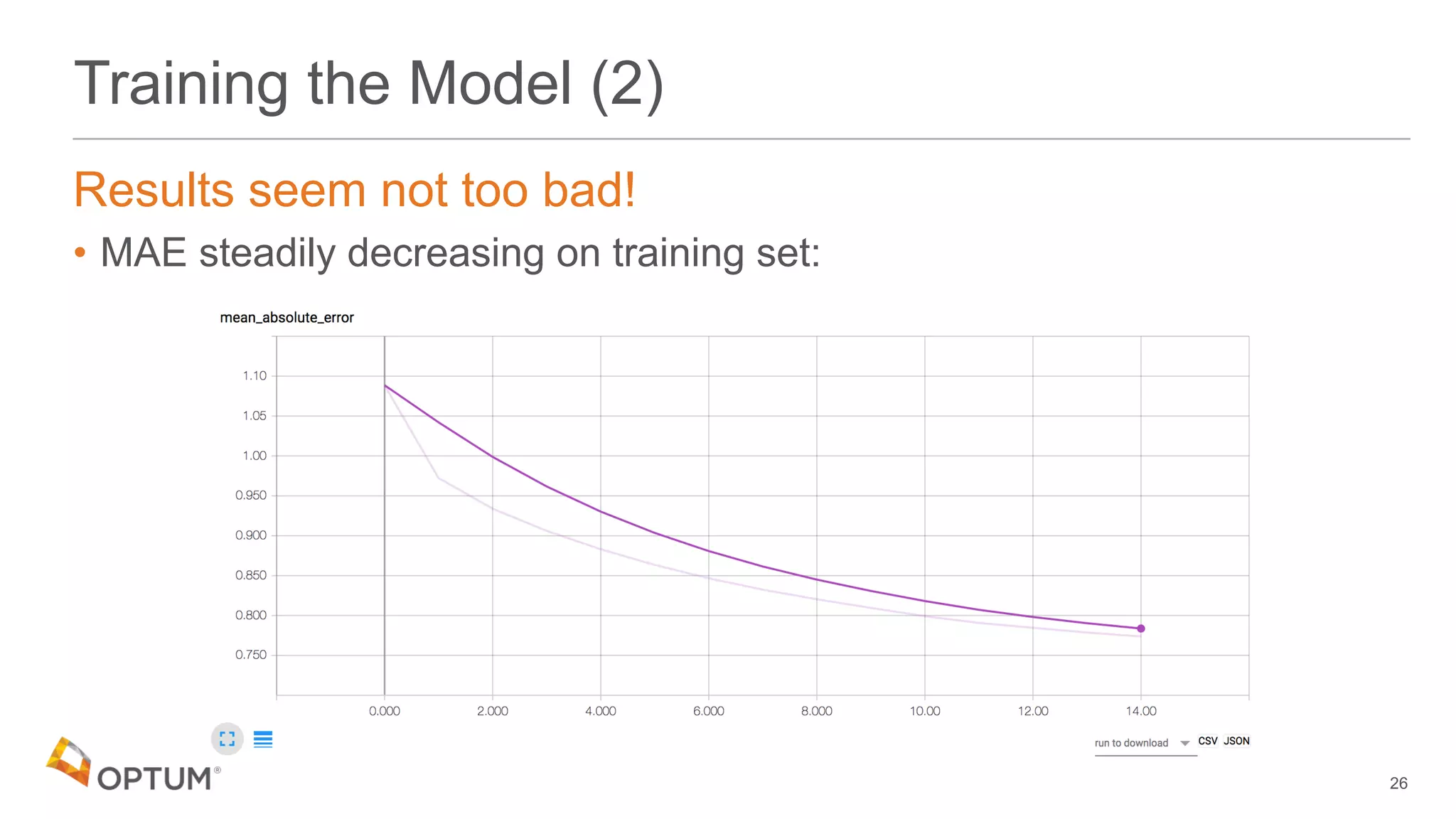
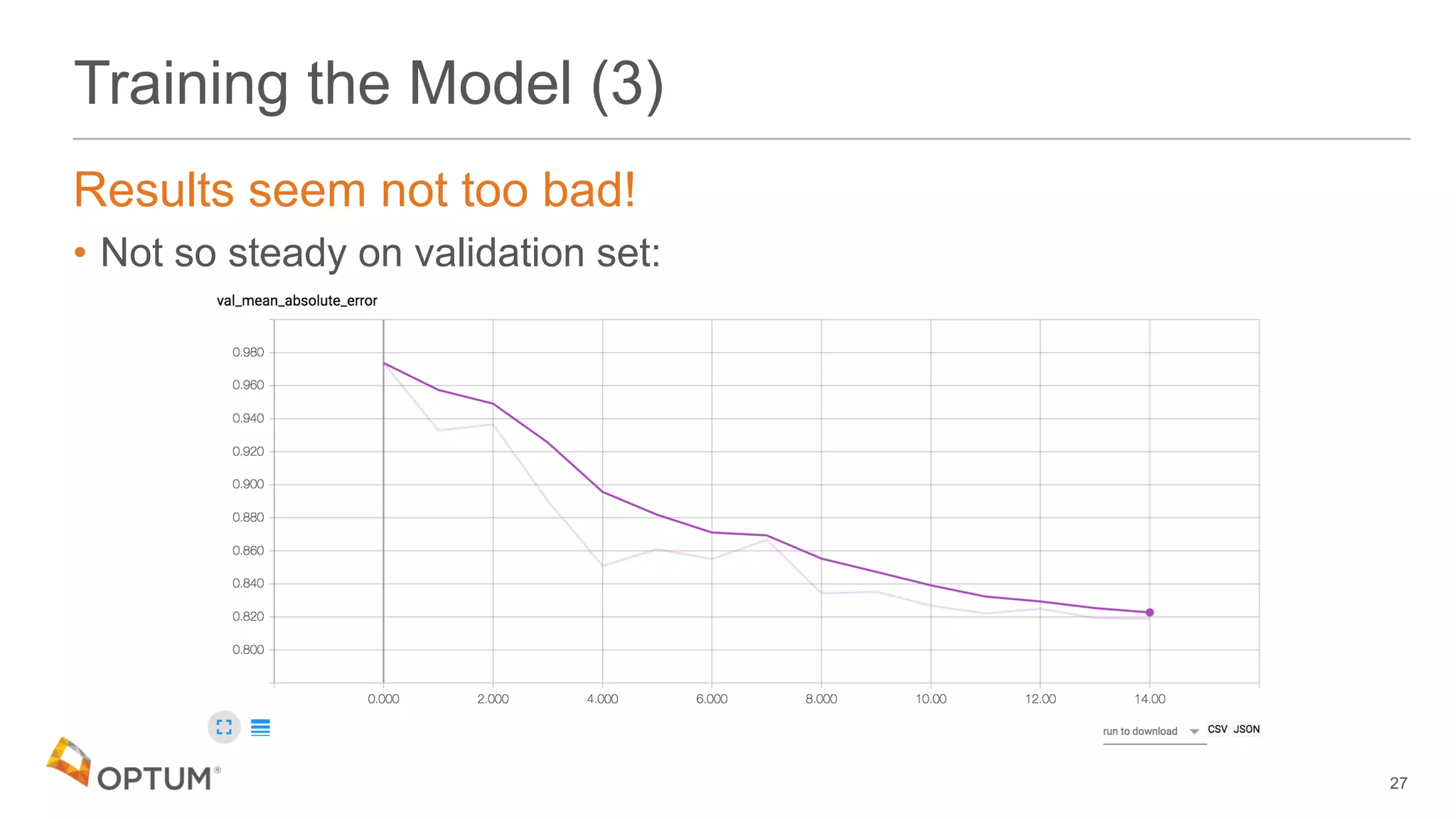
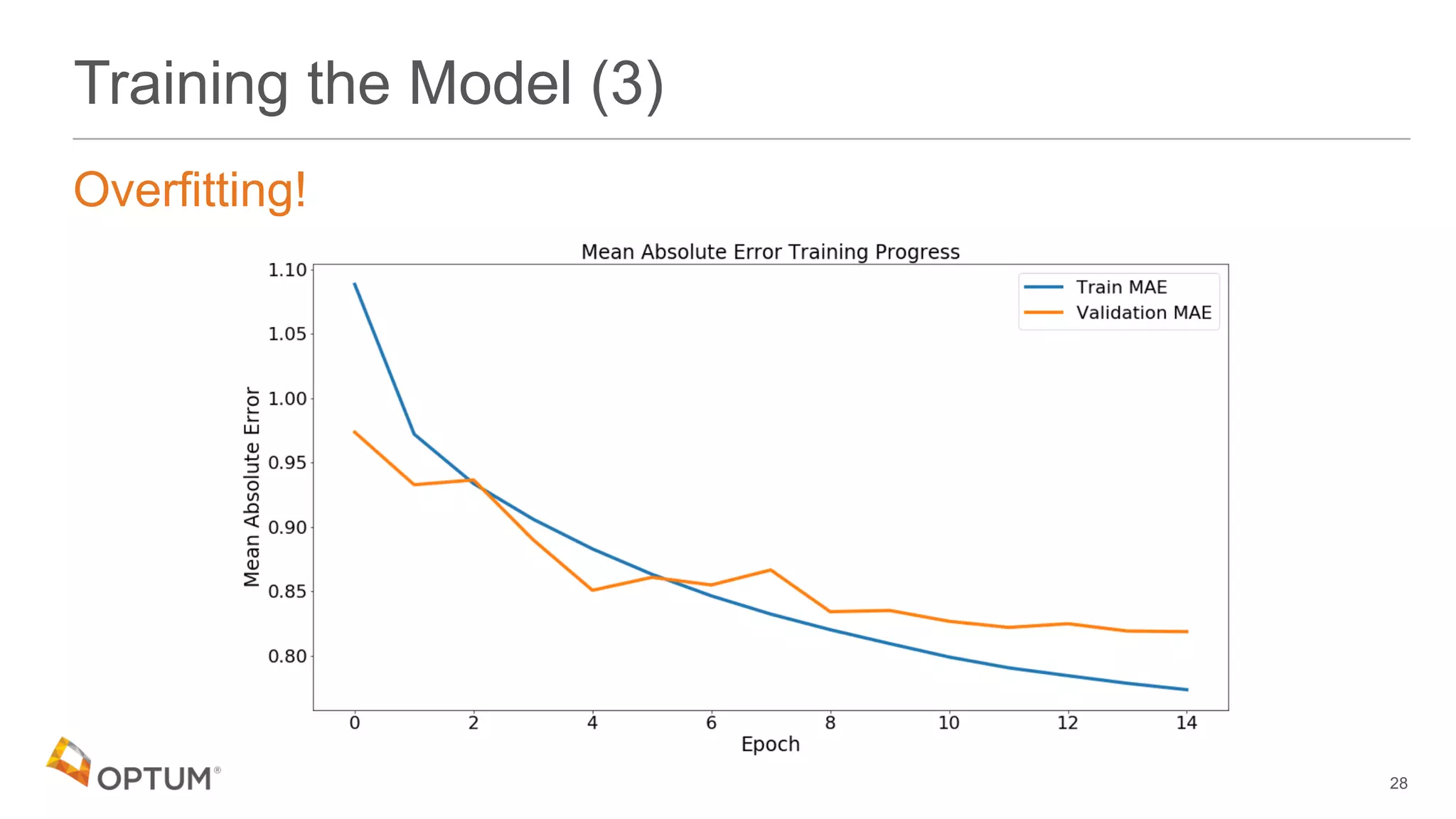
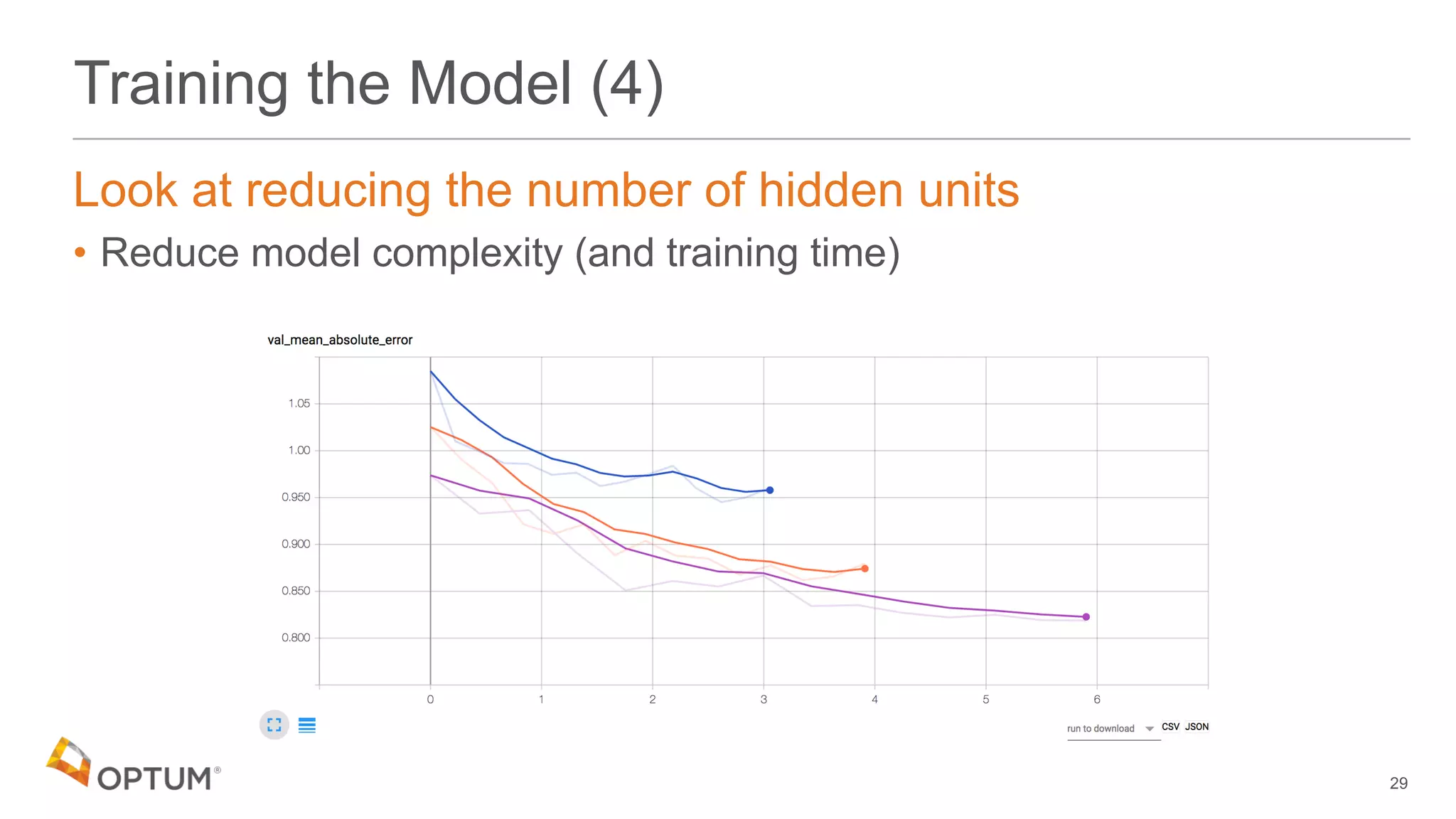
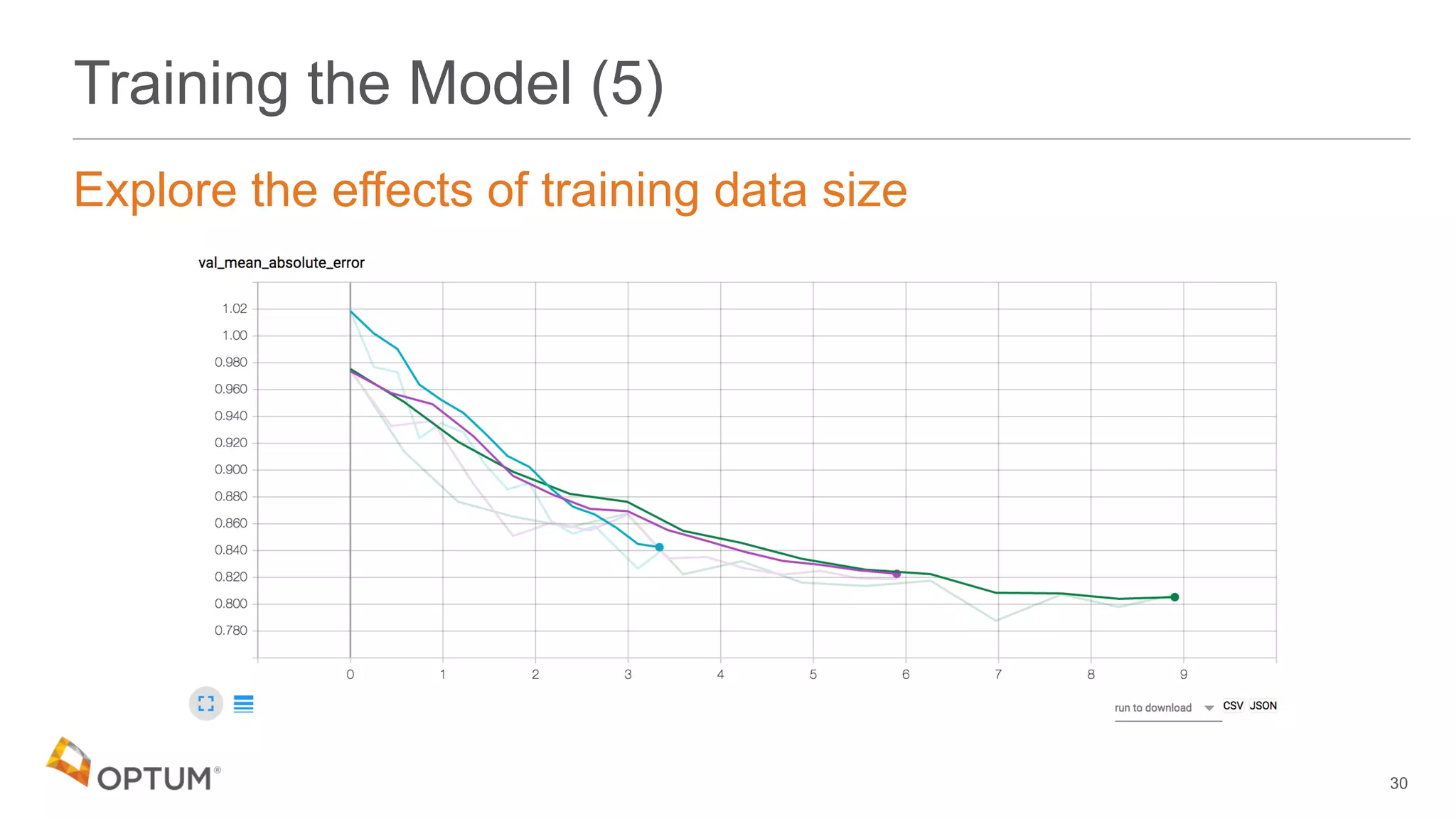
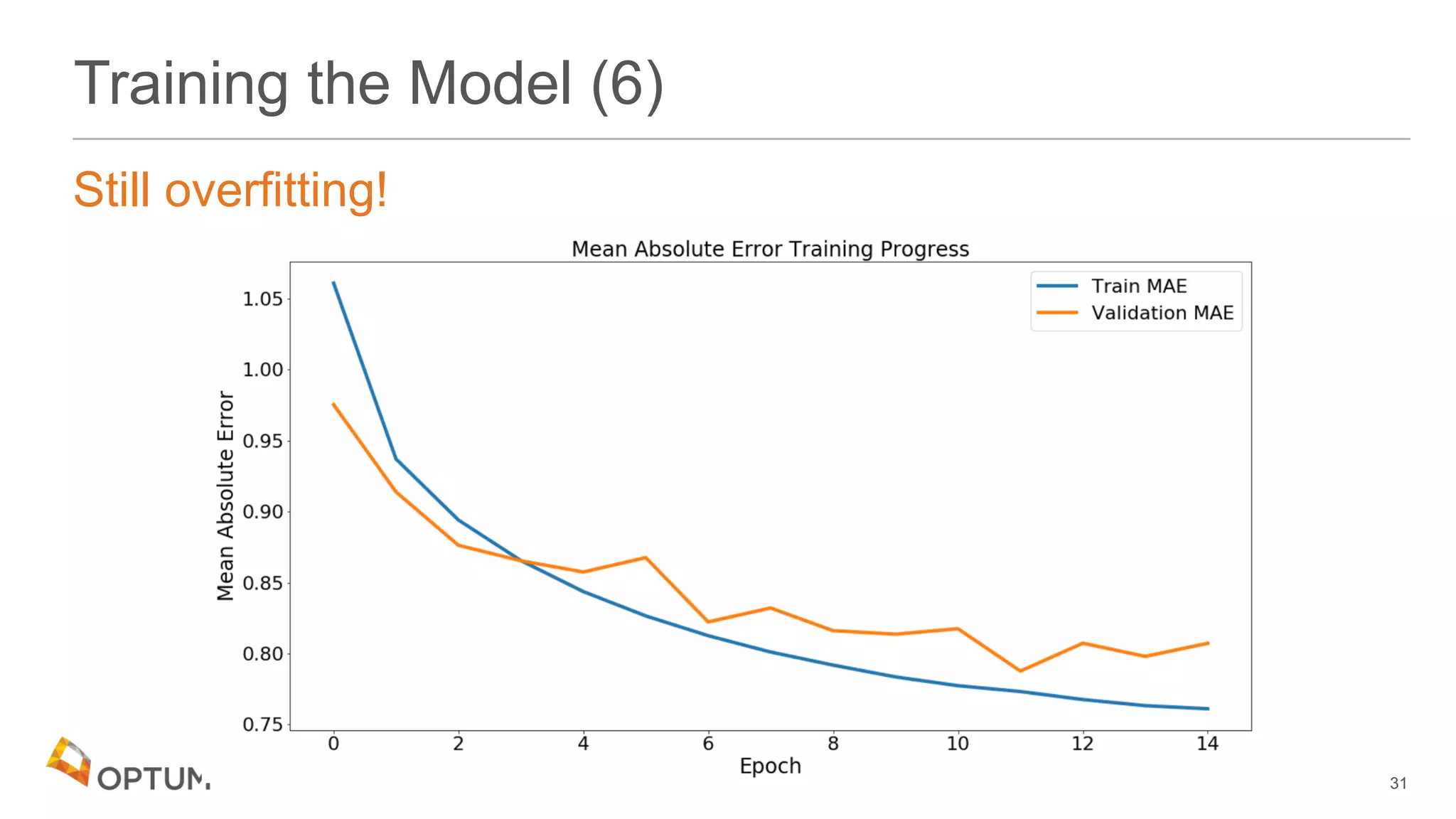
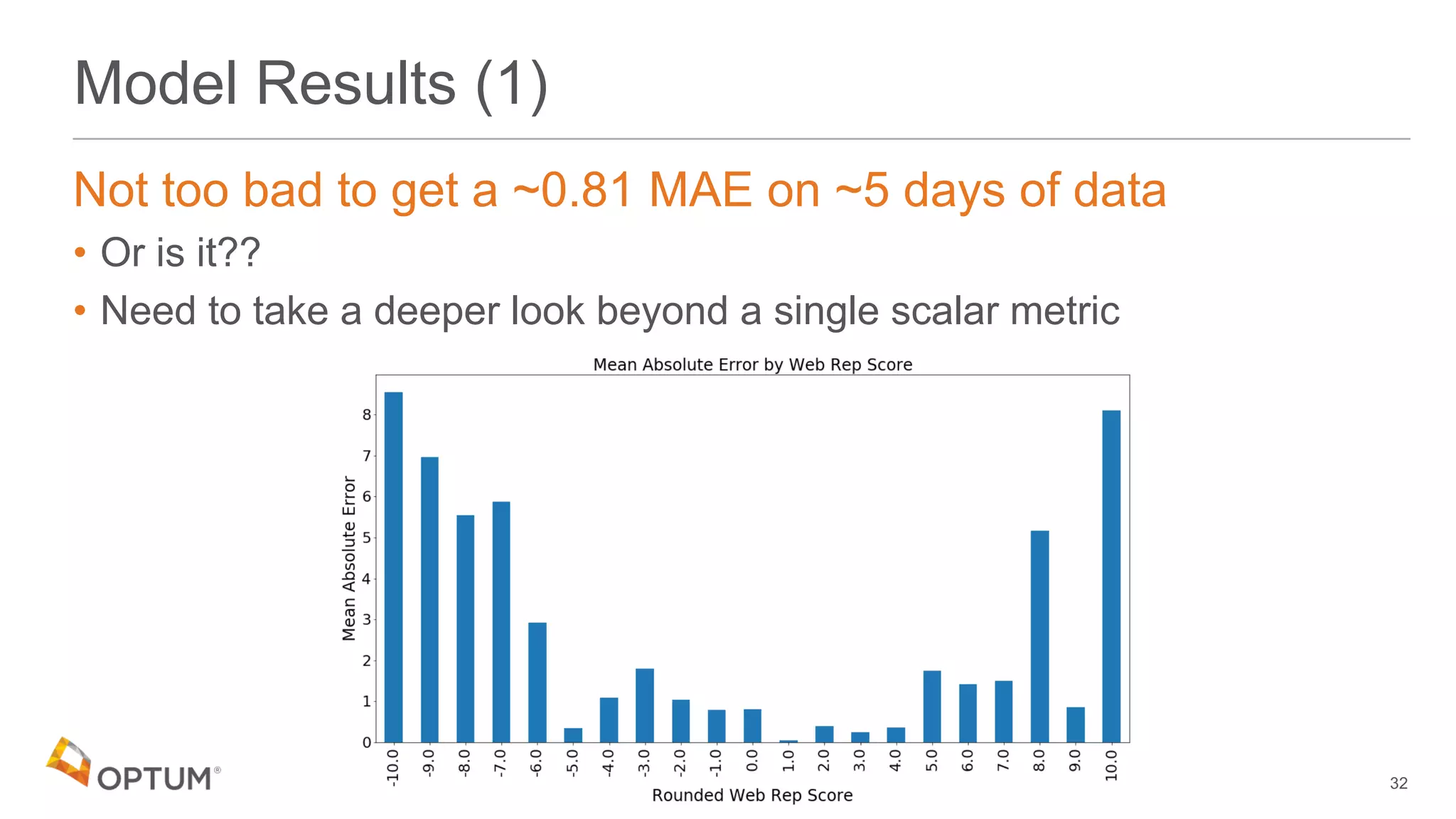



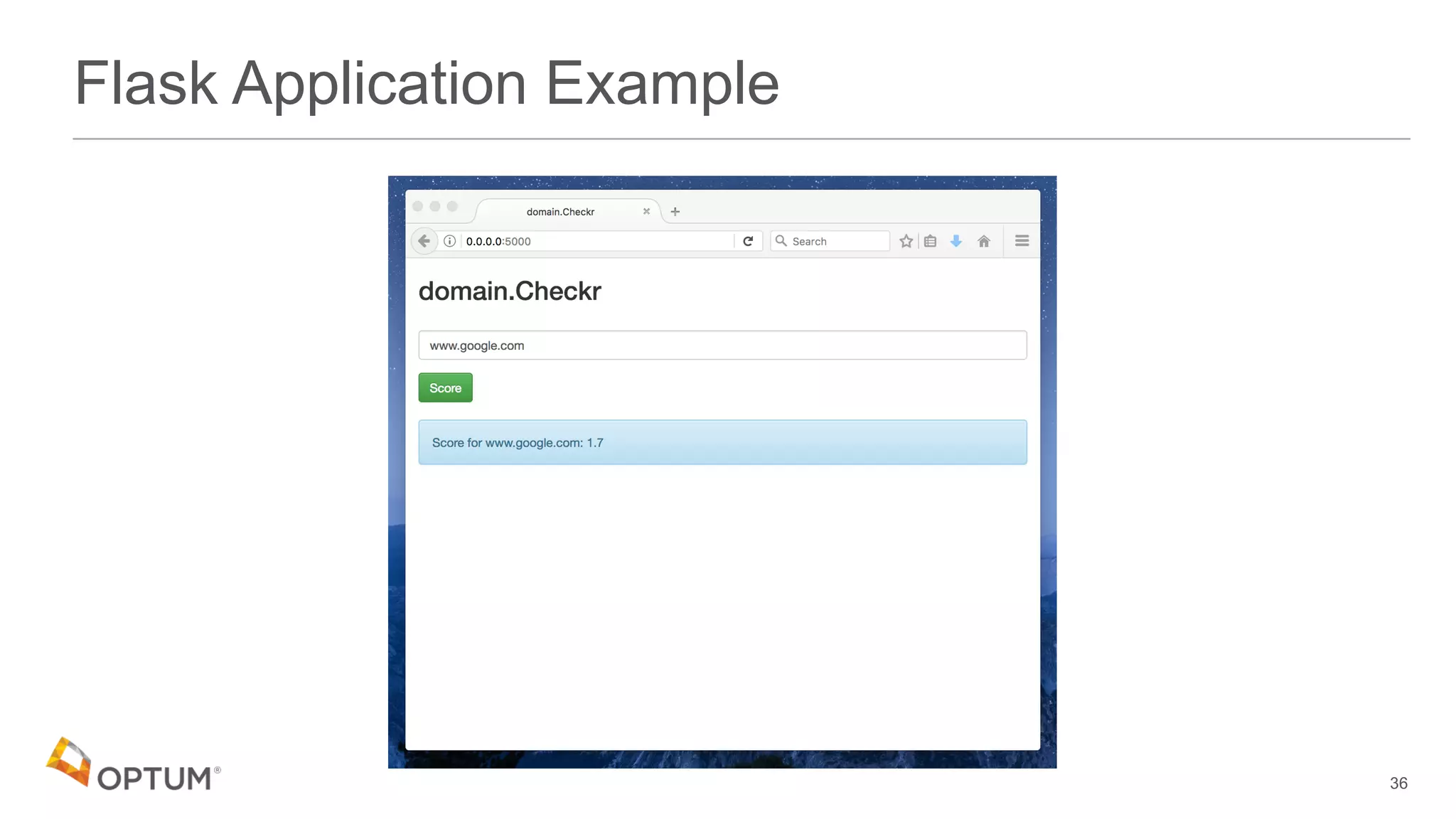



This document discusses using deep learning models to generate text-based regression scores for web domain reputation. It motivates using deep learning models to supplement existing reputation scores for new domains and provide data enrichment. The document outlines preprocessing input domain text data, describing common neural network architectures, and training an initial LSTM model on a dataset of 1.6 million domains and their reputation scores. It discusses results, opportunities for improvement, and options for model deployment.










































































