Download as PDF, PPTX



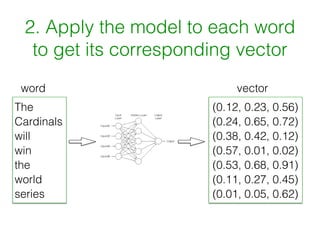




Word2vec works by using documents to train a neural network model to learn word vectors that encode the words' semantic meanings. It trains the model to predict a word's context by learning vector representations of words. It then represents sentences as the average of the word vectors, and constructs a similarity matrix between sentences to score them using PageRank to identify important summary sentences.













































![[Emnlp] what is glo ve part iii - towards data science](https://cdn.slidesharecdn.com/ss_thumbnails/emnlpwhatisglovepartiii-towardsdatascience-200228052047-thumbnail.jpg?width=640&height=640&fit=bounds)





















