Downloaded 243 times





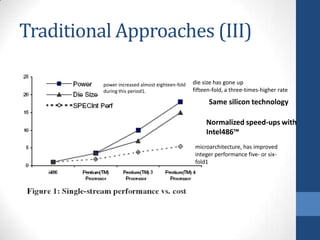


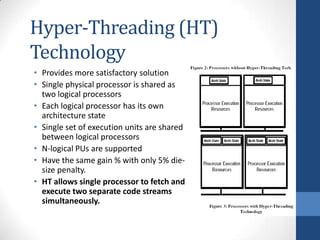


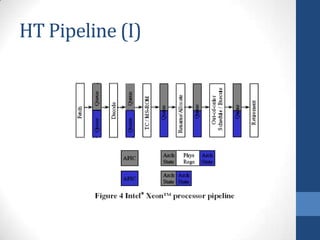
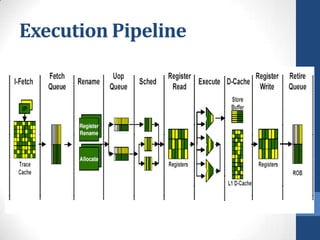
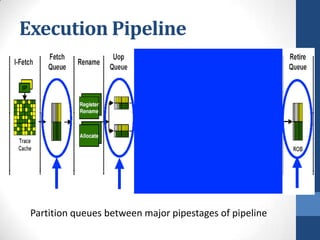
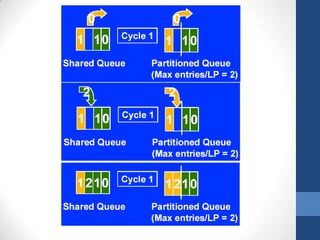
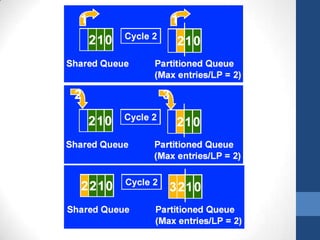
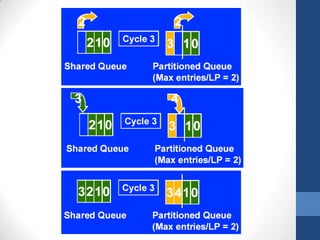

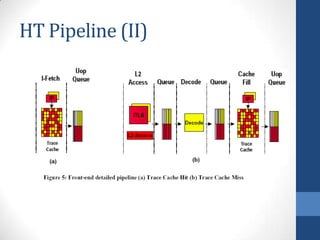
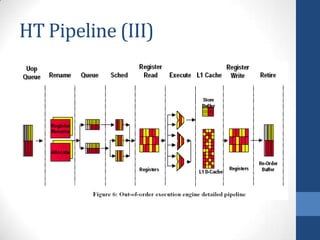


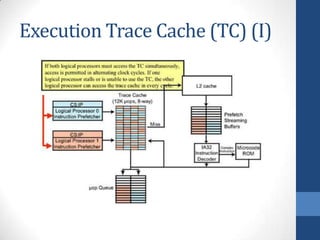

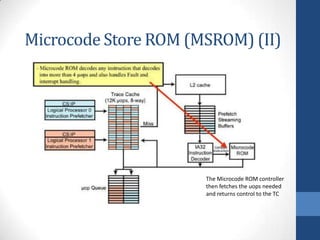






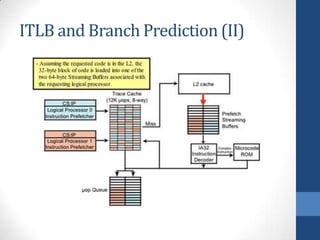
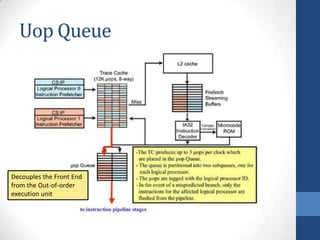
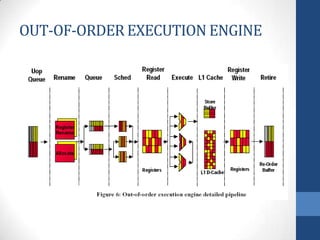






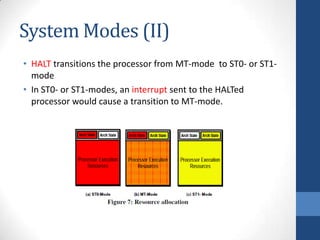

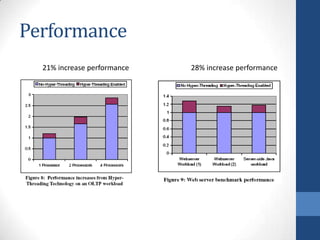




Intel's Hyper-Threading Technology enables a single processor to appear as two logical processors, enhancing performance by allowing simultaneous code execution. Introduced with the Pentium 4 Xeon processor, it minimizes die area while optimizing for thread-level parallelism and resource sharing. Hyper-Threading has been shown to improve performance by up to 30% in server applications and is supported by several operating systems.























































































