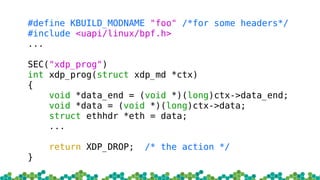
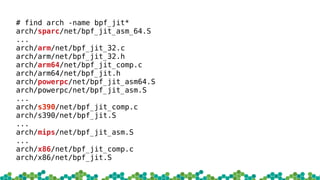
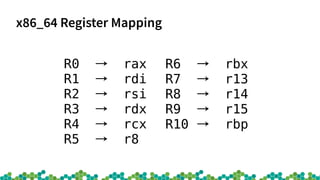
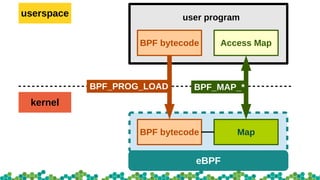
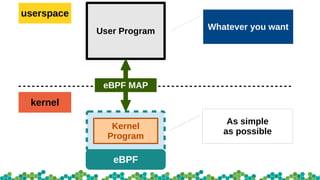
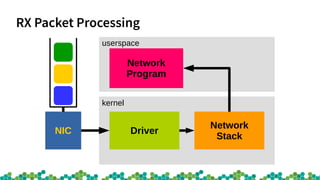
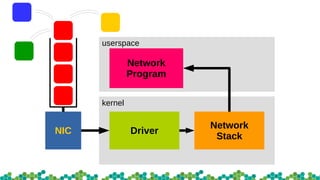
This document provides an introduction to eBPF and XDP. It discusses the history of BPF and how it evolved into eBPF. Key aspects of eBPF covered include the instruction set, JIT compilation, verifier, helper functions, and maps. XDP is introduced as a way to program the data plane using eBPF programs attached early in the receive path. Example use cases and performance benchmarks for XDP are also mentioned.







![BPF ASM
ldh [12]
jne #0x800, drop
ldb [23]
jneq #1, drop
# get a random uint32 number
ld rand
mod #4
jneq #1, drop
ret #-1
drop: ret #0](https://image.slidesharecdn.com/introduction-to-ebpf-and-xdp-171211161748/85/Introduction-to-eBPF-and-XDP-8-320.jpg)
![BPF Bytecode
struct sock_filter code[] = {
{ 0x28, 0, 0, 0x0000000c },
{ 0x15, 0, 8, 0x000086dd },
{ 0x30, 0, 0, 0x00000014 },
{ 0x15, 2, 0, 0x00000084 },
{ 0x15, 1, 0, 0x00000006 },
{ 0x15, 0, 17, 0x00000011 },
{ 0x28, 0, 0, 0x00000036 },
{ 0x15, 14, 0, 0x00000016 },
{ 0x28, 0, 0, 0x00000038 },
{ 0x15, 12, 13, 0x00000016 },
...
};](https://image.slidesharecdn.com/introduction-to-ebpf-and-xdp-171211161748/85/Introduction-to-eBPF-and-XDP-9-320.jpg)





















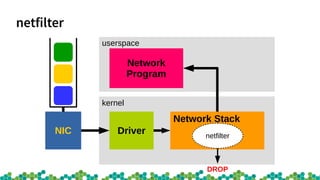
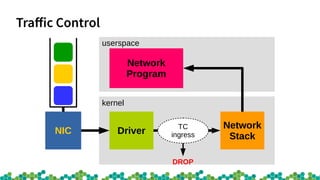
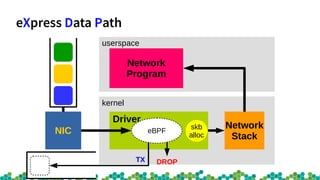

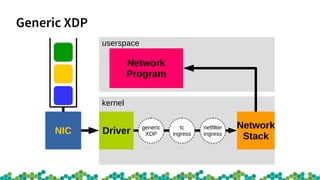
![virtnet_poll [virtio_net]() {
receive_buf [virtio_net]() {
receive_mergeable [virtio_net]() {
bpf_prog_run_xdp();----------------------Native XDP
page_to_skb [virtio_net]() {
__napi_alloc_skb() {
__build_skb();
}
skb_put();
}
}
skb_gro_reset_offset();
tcp4_gro_receive() {
tcp_gro_receive();
}
netif_receive_skb_internal() {
netif_receive_generic_xdp();------------generic XDP
__netif_receive_skb() {
__netif_receive_skb_core() {
sch_handle_ingress();----------------TC ingress
nf_ingress();-----------------Netfilter Ingress
ip_rcv() {
nf_hook_slow() {----Netfilter RAW Pre-routing](https://image.slidesharecdn.com/introduction-to-ebpf-and-xdp-171211161748/85/Introduction-to-eBPF-and-XDP-43-320.jpg)
![ipv4_conntrack_defrag [nf_defrag_ipv4]();
ipv4_conntrack_in [nf_conntrack_ipv4]() {
nf_conntrack_in [nf_conntrack]() {
ipv4_get_l4proto [nf_conntrack_ipv4]();
__nf_ct_l4proto_find [nf_conntrack]();
tcp_error [nf_conntrack]() {
nf_ip_checksum();
}
nf_ct_get_tuple [nf_conntrack]() {
ipv4_pkt_to_tuple [nf_conntrack_ipv4]();
tcp_pkt_to_tuple [nf_conntrack]();
}
hash_conntrack_raw [nf_conntrack]();
__nf_conntrack_find_get [nf_conntrack]();
tcp_get_timeouts [nf_conntrack]();
tcp_packet [nf_conntrack]() {
tcp_in_window [nf_conntrack]() {
nf_ct_seq_offset [nf_conntrack]();
tcp_options.isra.11 [nf_conntrack]();
}
__nf_ct_refresh_acct [nf_conntrack]();
}
}](https://image.slidesharecdn.com/introduction-to-ebpf-and-xdp-171211161748/85/Introduction-to-eBPF-and-XDP-44-320.jpg)
![}
}
ip_rcv_finish() {
tcp_v4_early_demux();
ip_route_input_noref();
ip_local_deliver() {------routing decisions
nf_hook_slow() {---Netfilter filter Input
ipt_do_table [ip_tables]();
ipv4_helper [nf_conntrack_ipv4]();
ipv4_confirm [nf_conntrack_ipv4]();
}
ip_local_deliver_finish() {
raw_local_deliver();
tcp_v4_rcv() {------L4 Protocol Handler
tcp_filter() {
security_sock_rcv_skb();
}
tcp_prequeue();
tcp_v4_do_rcv() {
tcp_rcv_state_process() {
tcp_parse_options();
tcp_ack() {
...](https://image.slidesharecdn.com/introduction-to-ebpf-and-xdp-171211161748/85/Introduction-to-eBPF-and-XDP-45-320.jpg)