ブースティングはアンサンブル学習の一つです。アンサンブル学習では、性能の低い学習器を組み合わせて、高性能な学習器を作ります。教師あり機械学習の問題設定の復習から始めて、バギングやブースティングのアルゴリズムについて解説します。 レトリバセミナーで話したときの動画はこちらです: https://www.youtube.com/watch?v=SJtdG62691g




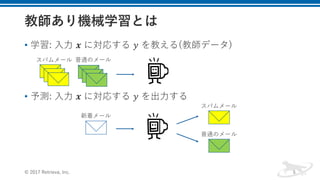
![• 分類
• y がカテゴリ値
• スパム判定(y: スパム、スパムじゃない)
• 記事分類(y: 政治、スポーツ、エンタメ、…)
• …
• 回帰
• y が実数値
• 電⼒消費予測(y: 18.5[kWh/⽇])
• 株価予測(y: 20000[円])
• ….
© 2017 Retrieva, Inc. 6](https://image.slidesharecdn.com/random-171012053933/85/slide-6-320.jpg)
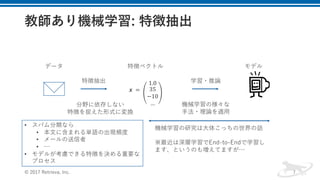










![• 1. 学習データの重み𝑤1を初期化する。 𝑤1 =
-
]
, 𝑓𝑜𝑟 𝑖 = 1, … , 𝑁
• 2. m = 1, …, M繰り返す
• 重み付き誤分類率𝜖Q(0 ≤ 𝜖Q ≤ 0.5)の最も⼩さい弱学習器𝑓Q(𝒙)を学習
する
• 𝜖Q = ∑ 𝑤1
H
1R- [𝑦1 ≠ 𝑓Q 𝒙1 ]
• 弱学習器の重み𝛼Qを計算する
• 𝛼Q =
-
T
log
-fgh
gh
• データの重み𝑤1を更新する
• 𝑤1 = 𝑤1 ∗
-
jh
𝑒fklmh(𝒙l) 𝑓𝑜𝑟 𝑖 = 1, … , 𝑁 ただし、正規化定数は、𝑍Q =
∑ 𝑒fkomh(𝒙o)H
pR-
© 2017 Retrieva, Inc. 23
⼊⼒: 学習データ= 𝒙-, 𝑦- , … , 𝒙H, 𝑦H
弱学習器の数 = M
出⼒: 学習器 𝐹 𝒙 = 𝑠𝑖𝑔𝑛(∑ 𝛼Q 𝑓Q(𝒙))O
QR-](https://image.slidesharecdn.com/random-171012053933/85/slide-23-320.jpg)



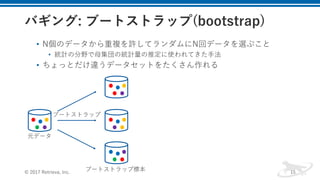
![• 1. 学習データの重み𝑤1を初期化する。 𝑤1 =
-
]
, 𝑓𝑜𝑟 𝑖 = 1, … , 𝑁
• 2. m = 1, …, M繰り返す
• 重み付き誤分類率𝜖Q(0 ≤ 𝜖Q ≤ 0.5)の最も⼩さい弱学習器𝑓Q(𝒙)を学習
する
• 𝜖Q = ∑ 𝑤1
H
1R- [𝑦1 ≠ 𝑓Q 𝒙1 ]
• 弱学習器の重み𝛼Qを計算する
• 𝛼Q =
-
T
log
-fgh
gh
• データの重み𝑤1を更新する
• 𝑤1 = 𝑤1 ∗
-
jh
𝑒fklmh(𝒙l) 𝑓𝑜𝑟 𝑖 = 1, … , 𝑁 ただし、正規化定数は、𝑍Q =
∑ 𝑒fkomh(𝒙o)H
pR-
© 2017 Retrieva, Inc. 28
⼊⼒: 学習データ= 𝒙-, 𝑦- , … , 𝒙H, 𝑦H
弱学習器の数 = M
出⼒: 学習器 𝐹 𝒙 = 𝑠𝑖𝑔𝑛(∑ 𝛼Q 𝑓Q(𝒙))O
QR-](https://image.slidesharecdn.com/random-171012053933/85/slide-28-320.jpg)






![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2](https://cdn.slidesharecdn.com/ss_thumbnails/chapter12slides-200211153032-thumbnail.jpg?width=640&height=640&fit=bounds)

























