Download to read offline






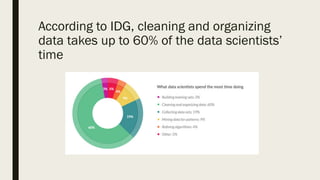

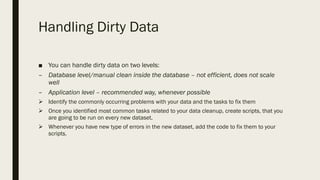



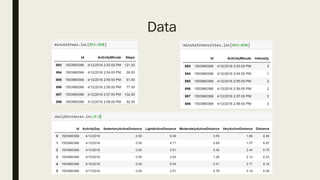

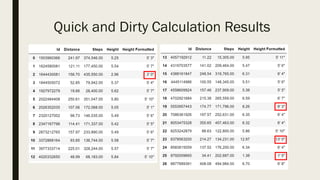
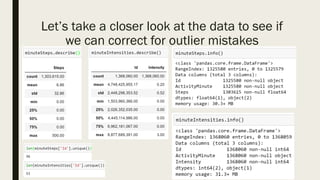

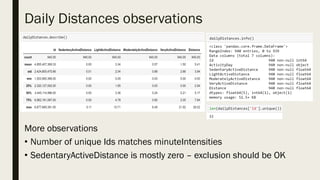

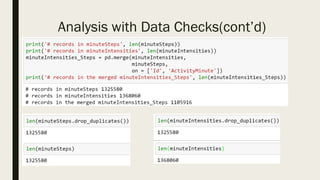















The document discusses the impact of dirty data on data analysis, particularly in spreadsheet formats like Excel, emphasizing the prevalence of issues such as duplicates, missing values, and outliers. It presents methods to handle and clean data, including single and multiple imputation techniques, and introduces the concept of 'tidy data' for effective organization. A case study using a Fitbit dataset illustrates the effects of data quality on analysis outcomes.























































































