Download to read offline






























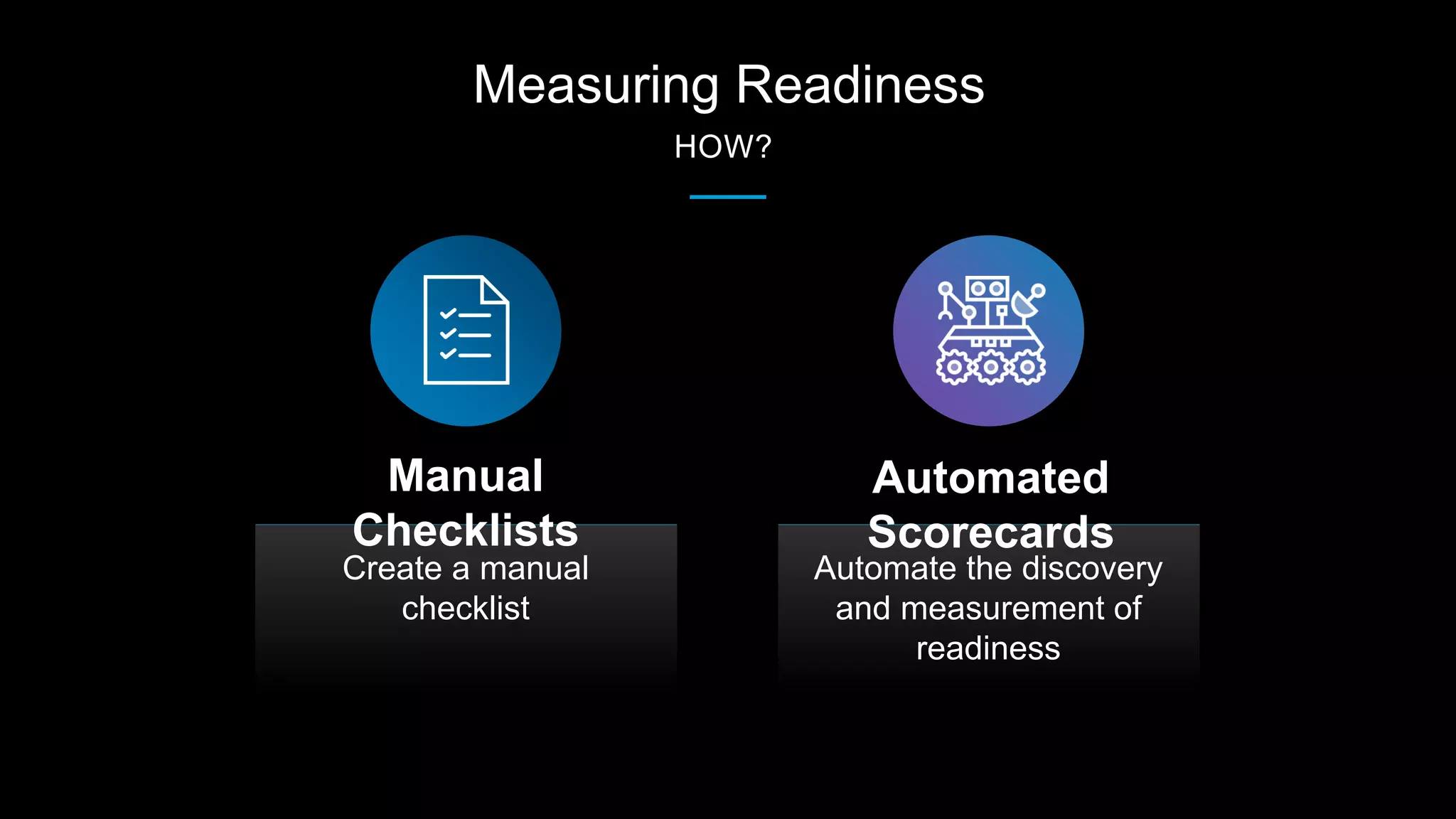
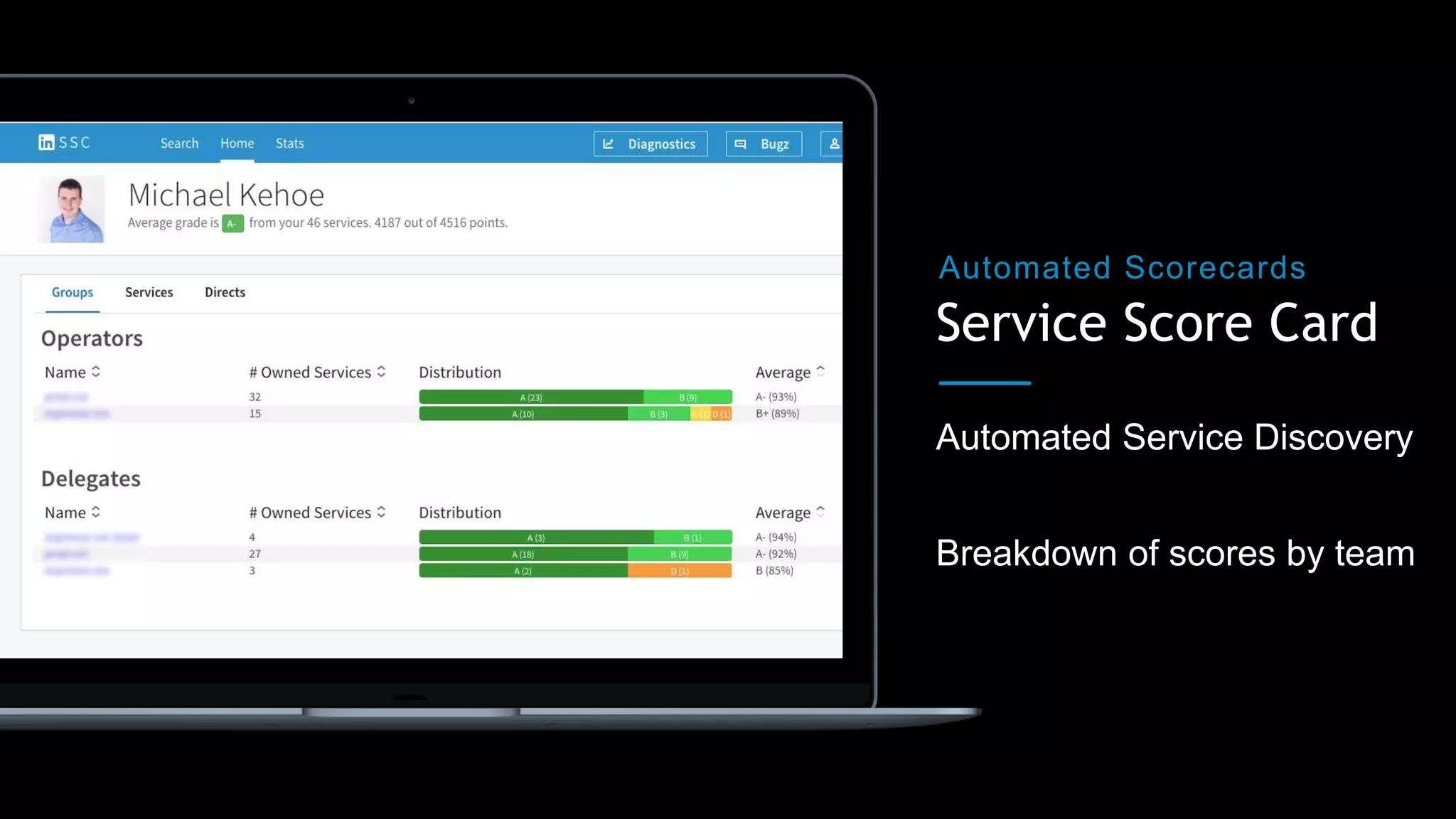
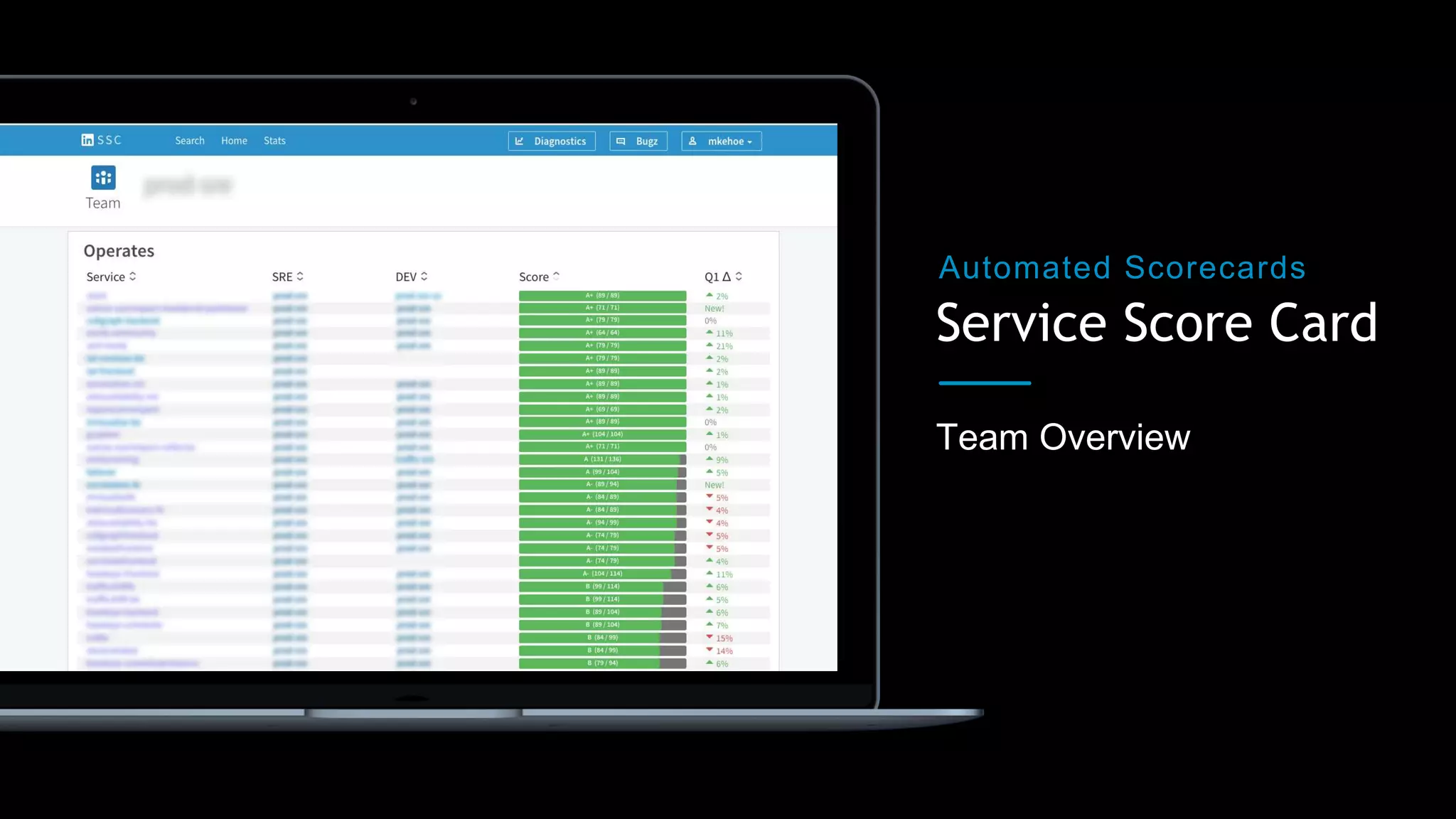
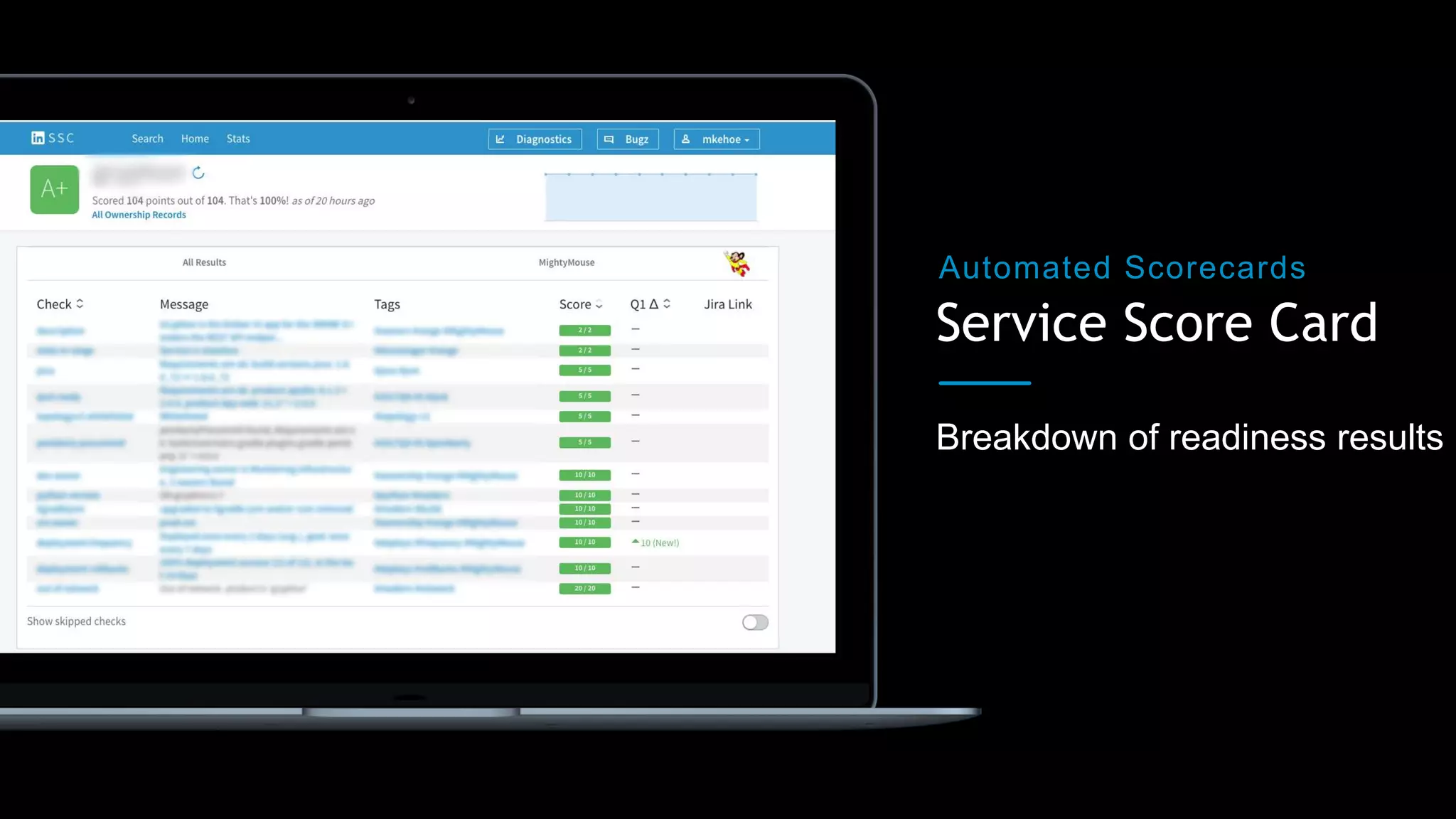

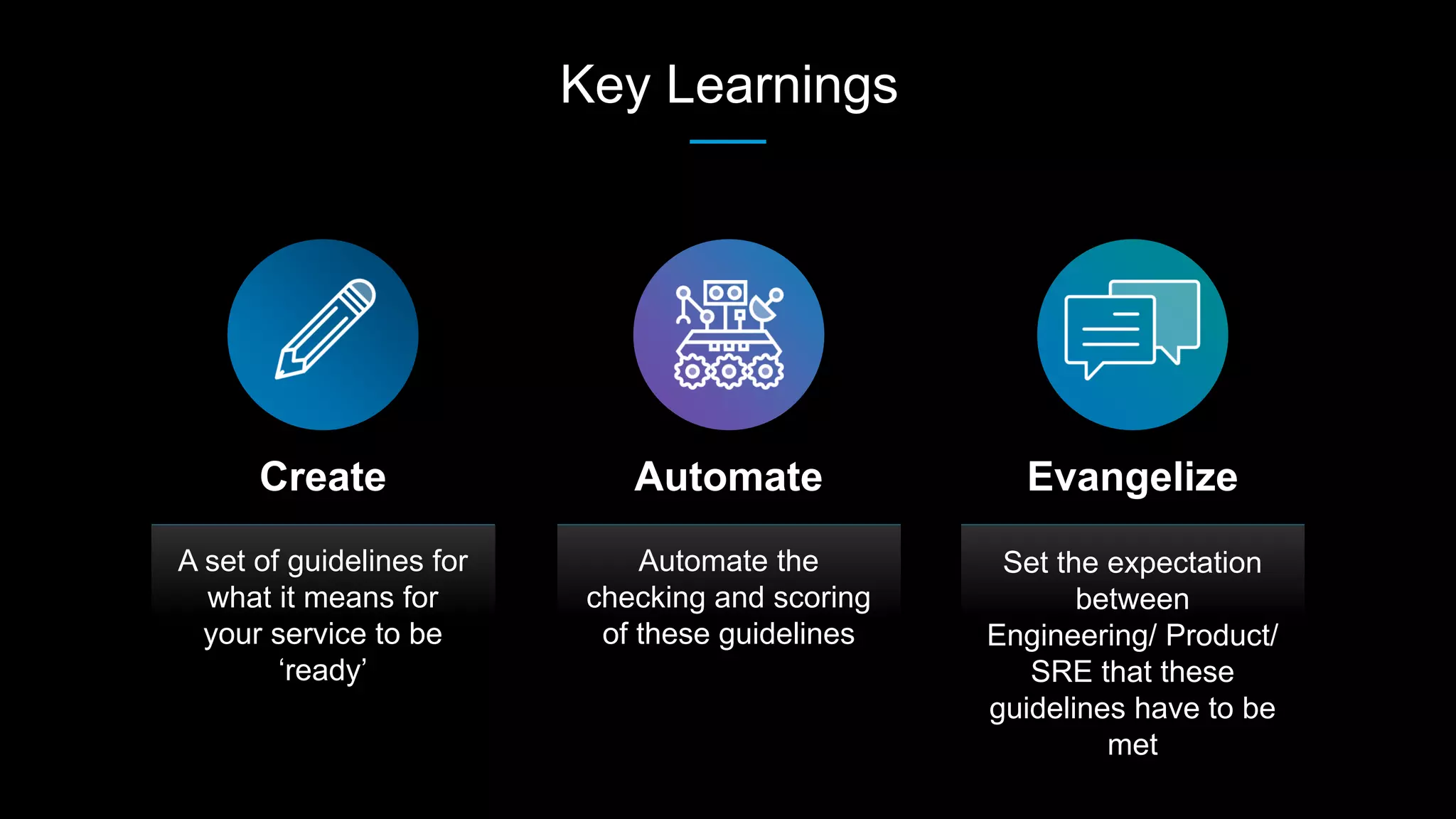



The document outlines best practices for building production-ready microservices, emphasizing tenets such as stability, reliability, scalability, fault tolerance, monitoring, and documentation. It provides guidelines for creating measurable benchmarks and the importance of standardization in assessing service readiness. Key learnings include automating the checking of readiness guidelines and establishing clear expectations among engineering, product, and site reliability engineering teams.























































































