Download to read offline























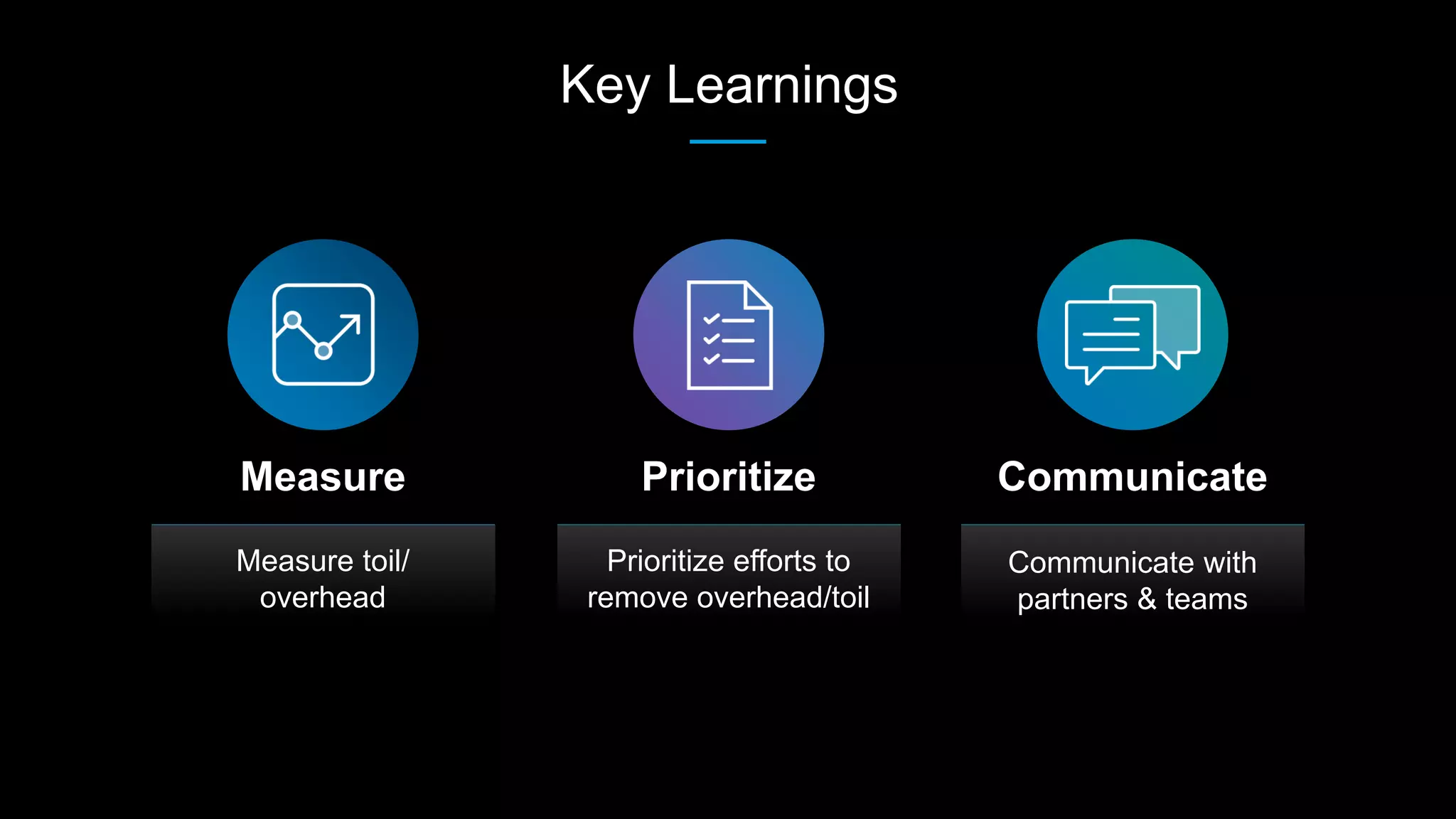



This document summarizes Michael Kehoe's experience being loaned out to SRE teams at LinkedIn to help with various issues. It describes three scenarios: 1) A team lacked resource allocation documentation and had a backlog, 2) A new service had technical debt and complex performance issues, 3) A database team lacked automation and had alert fatigue. To build success, the document recommends defining problem areas, success criteria, acquiring needed resources, and planning short and long-term. It also stresses communicating expectations with clients/partners. Key learnings are to measure toil, prioritize reducing it, and communicate effectively.
















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)



