Download to read offline







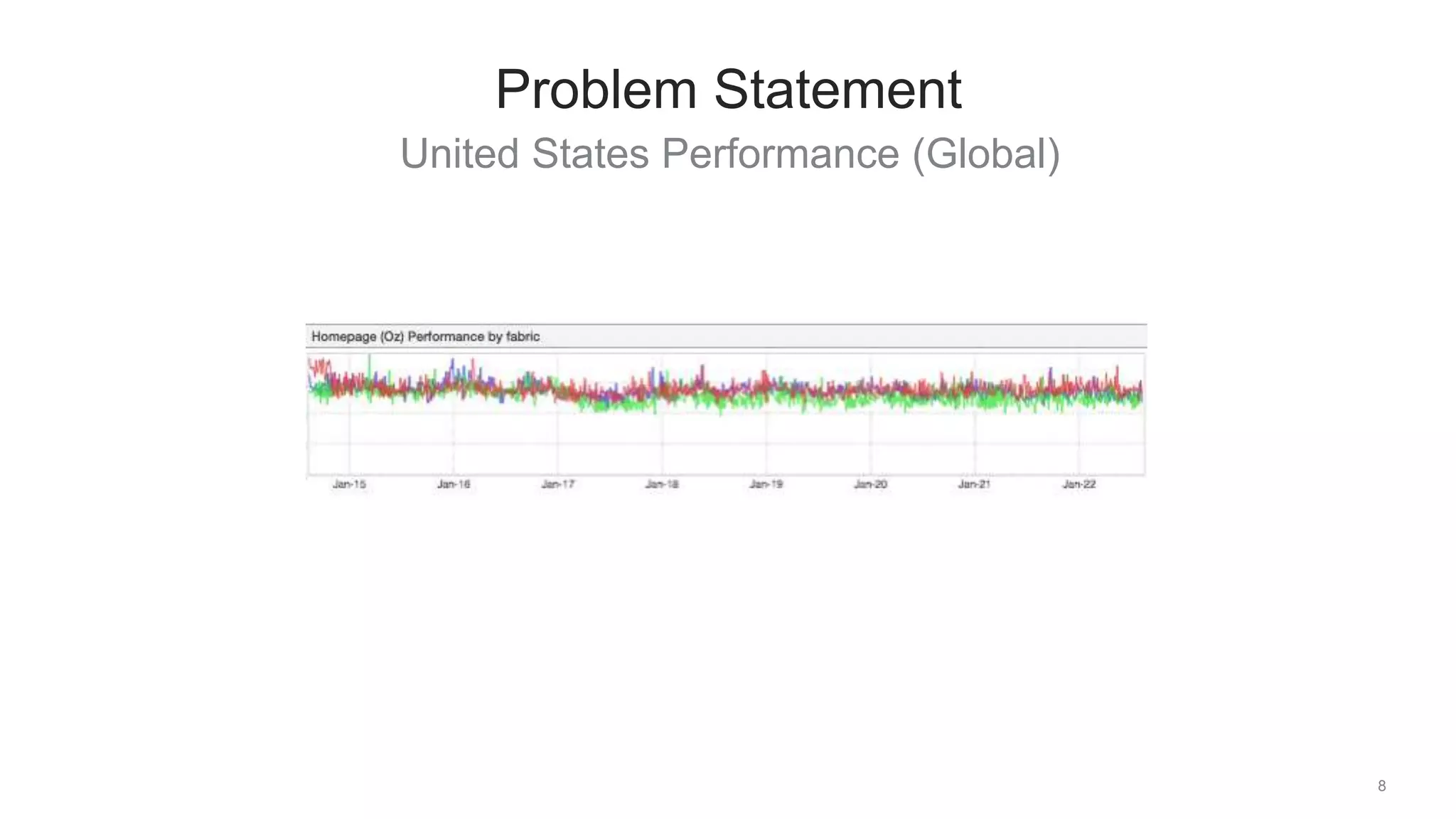

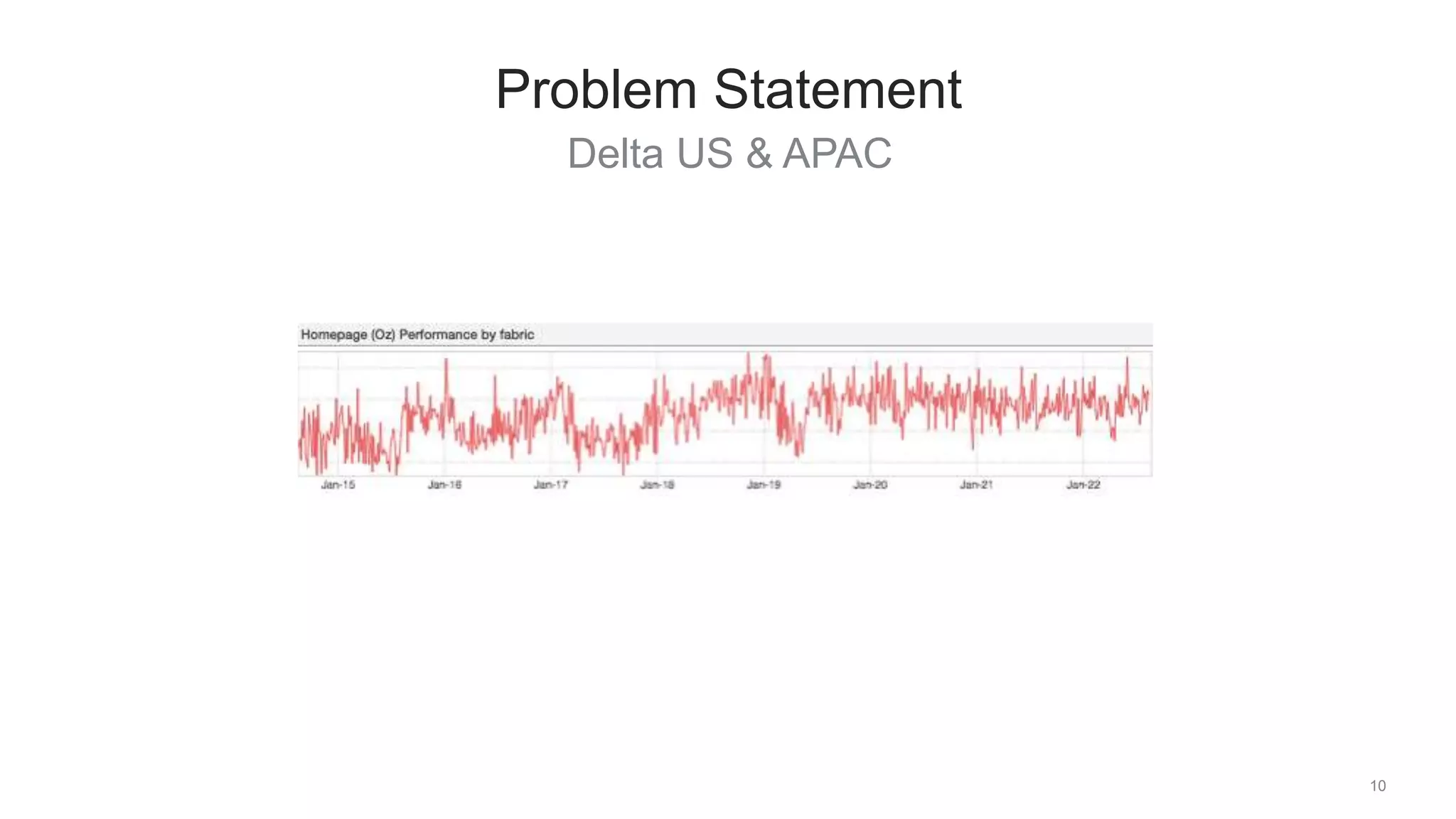

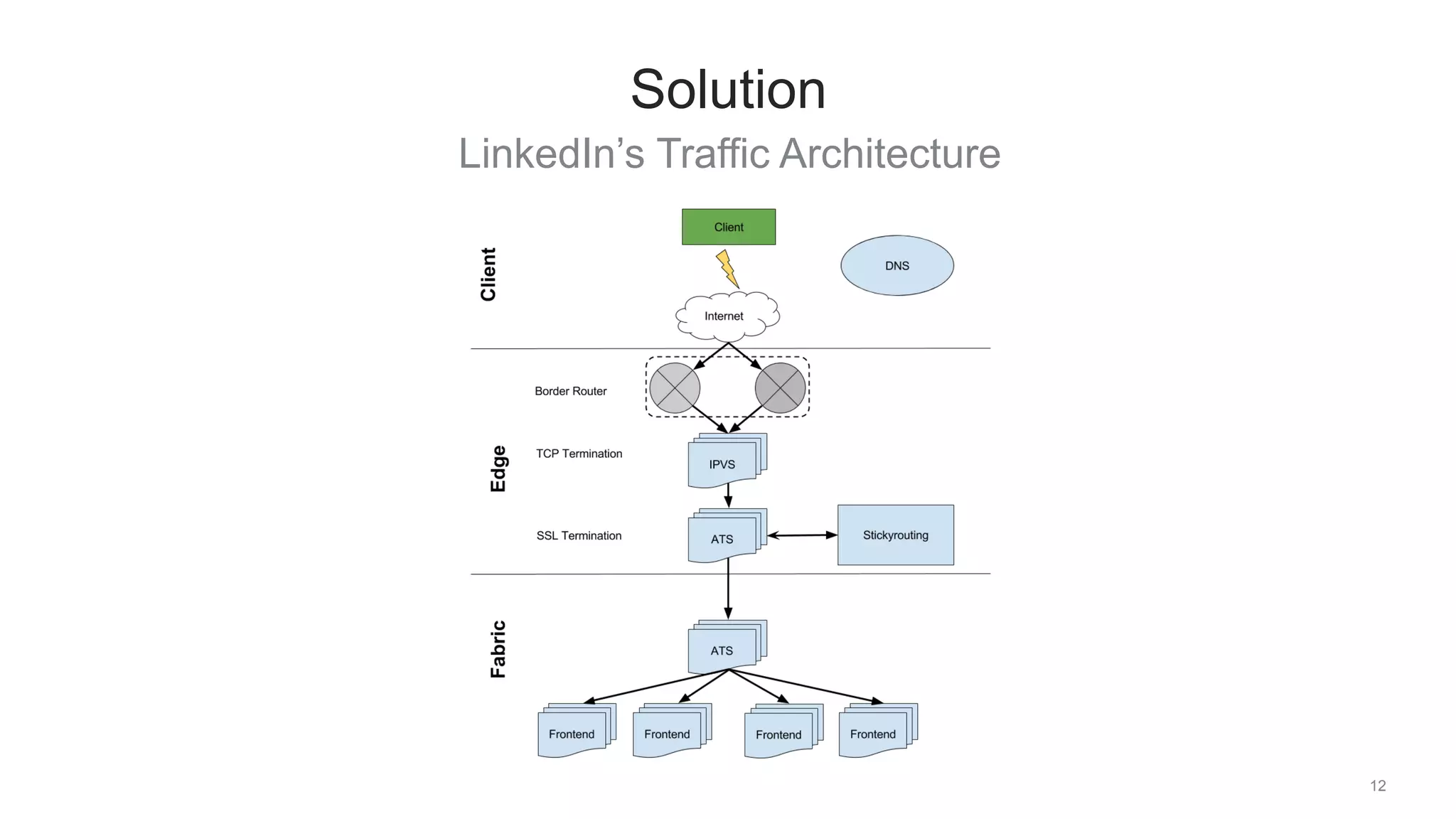




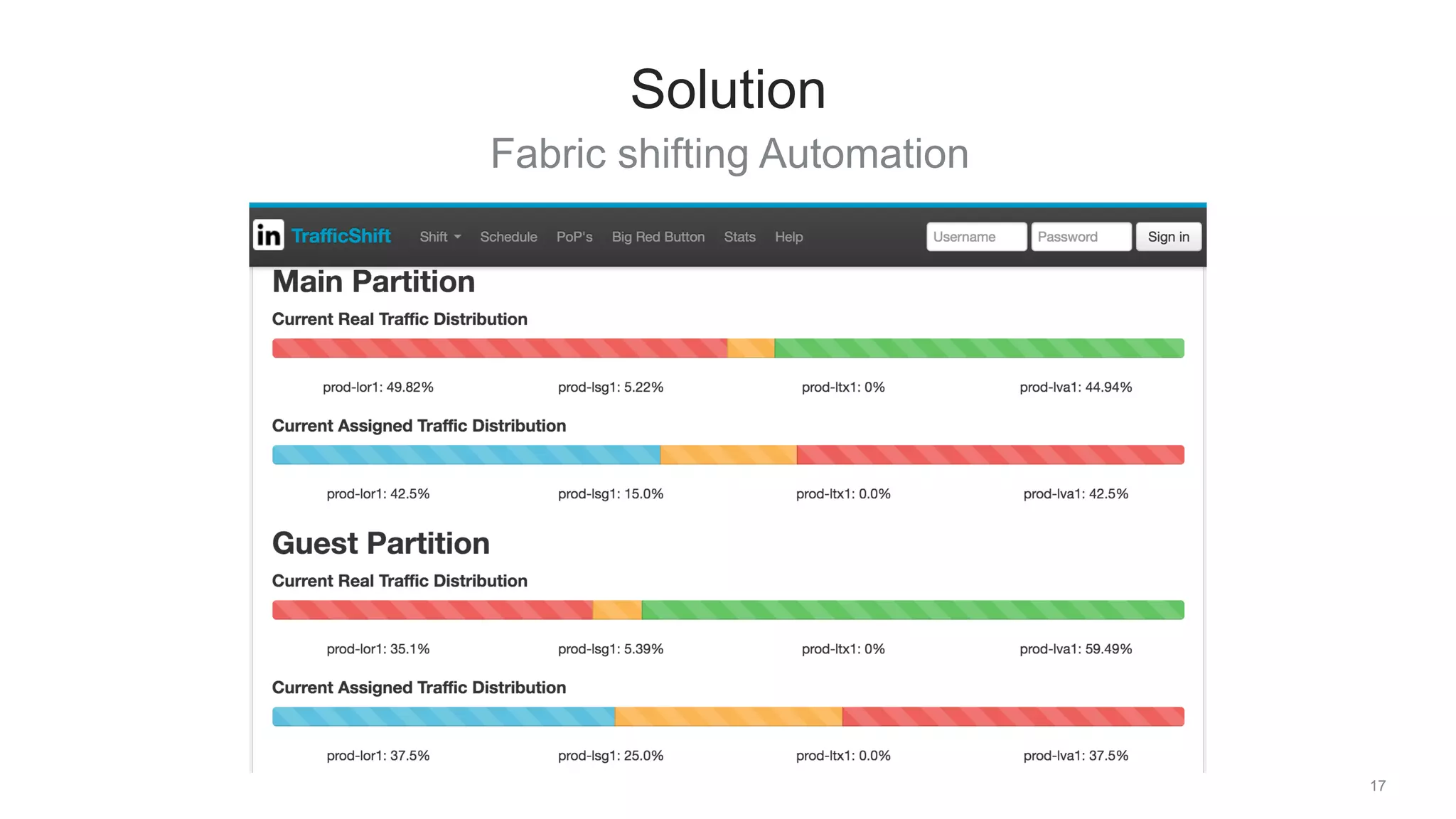
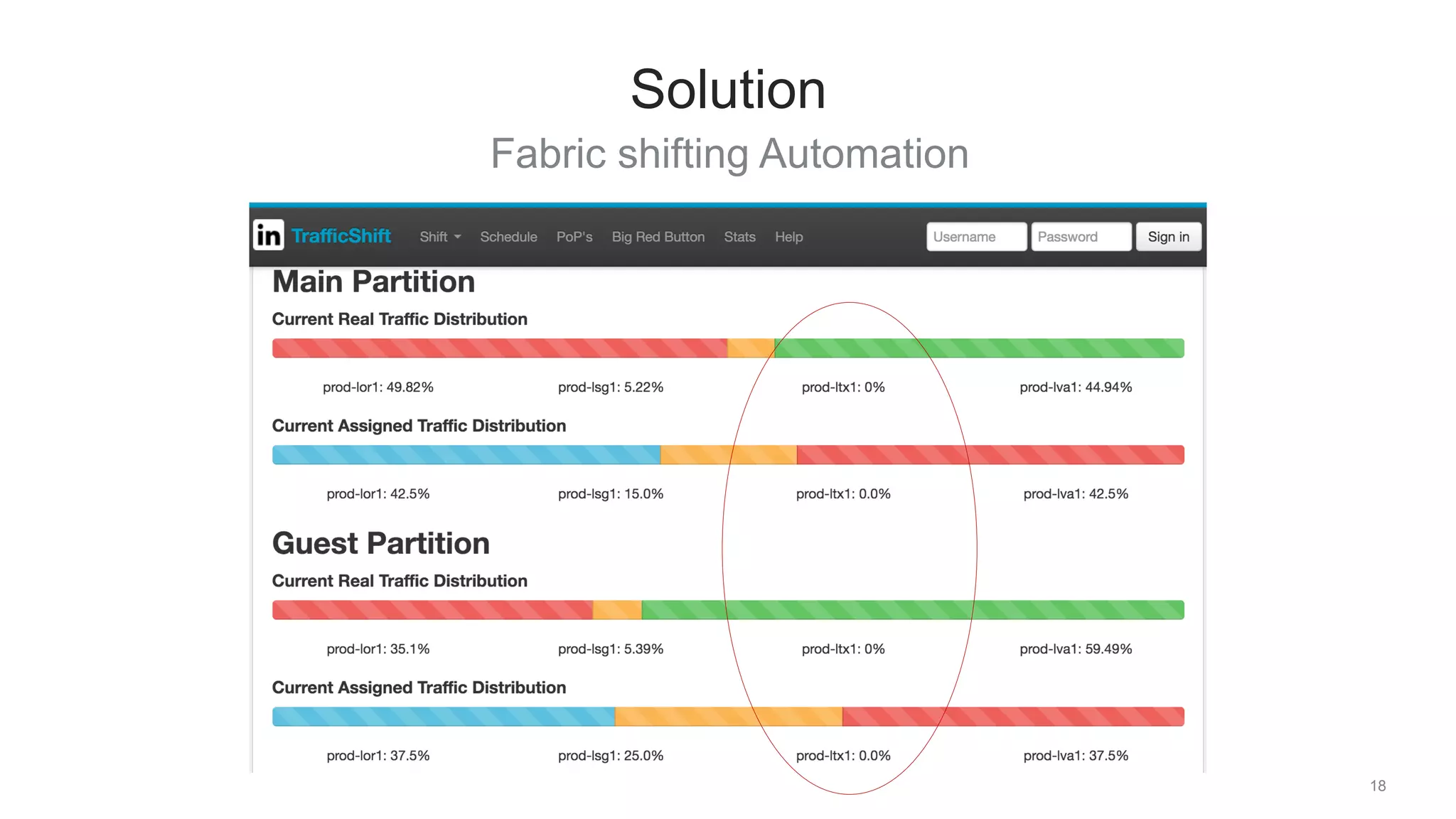








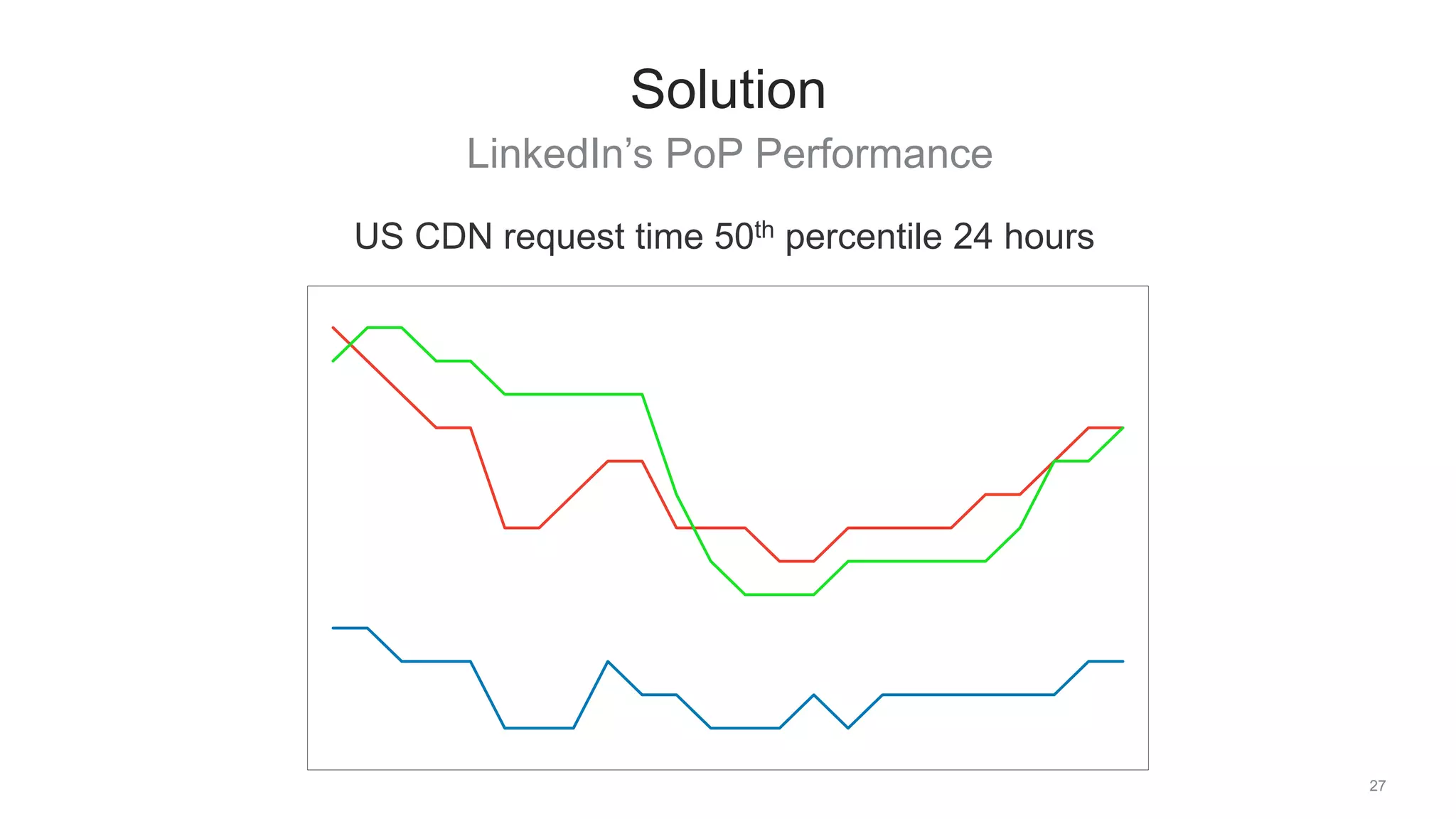
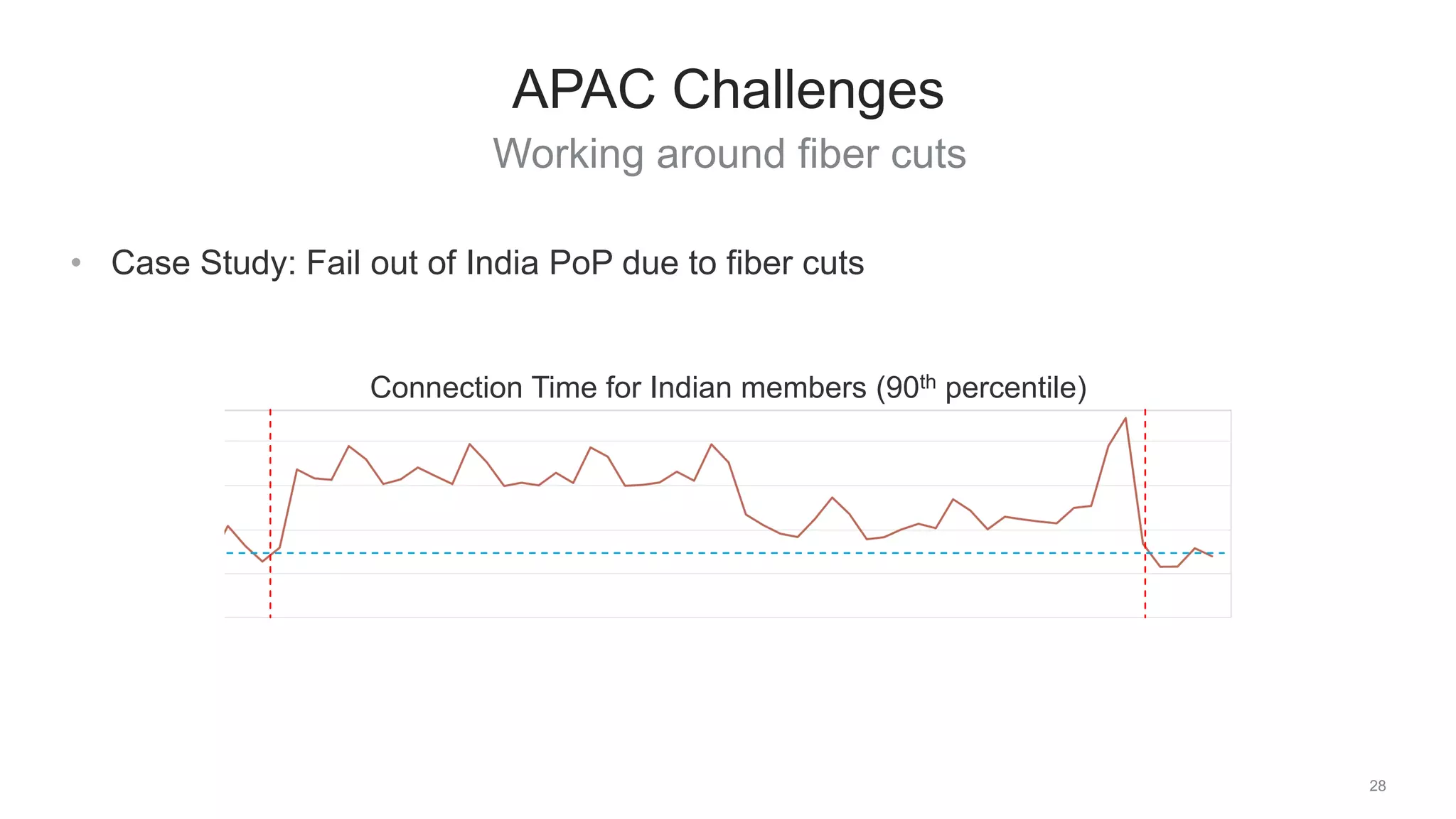


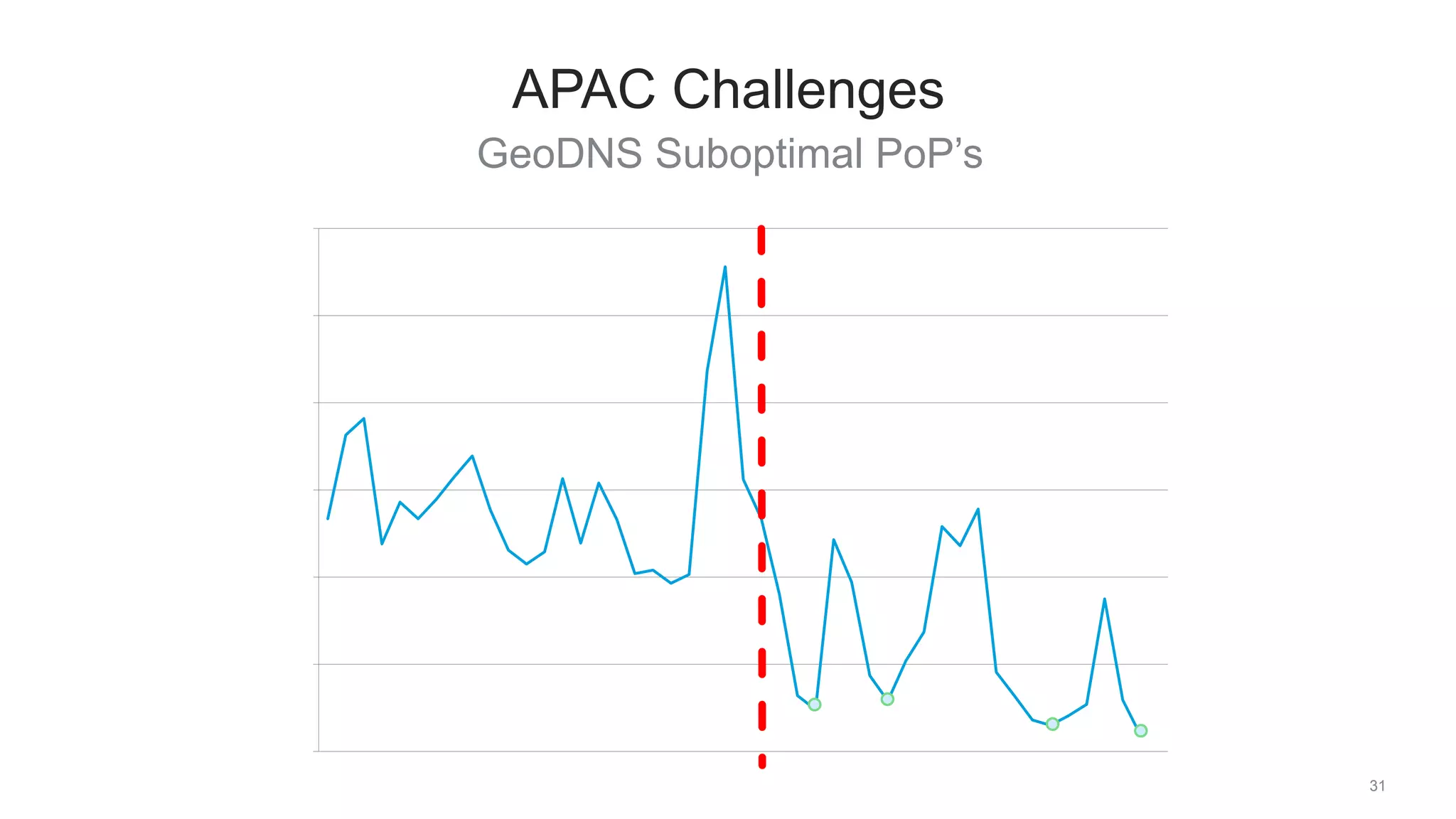





The document discusses traffic management solutions at LinkedIn to enhance performance and resilience against failures. It covers methods such as datacenter shifting, POP steering, and challenges specific to the APAC region while emphasizing the importance of site speed on user engagement and revenue. Additionally, it highlights the benefits of IPv6 over IPv4 in improving request times for mobile users.













![[Webinar] AWS Monitoring with Site24x7](https://cdn.slidesharecdn.com/ss_thumbnails/site24x7-awsmonitoringwithsite24x704thnov2015-151105060402-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

























































































