Download as PDF, PPTX



![Apiary in numbers
» Apiary users: 336,786 Apiary API projects: 440,178
» Apiary engineers: 19
» Apiary platform engineers: 10 + 4
» Apiary SREs: 4
» App deploys: 15 (per week)
» Parsing service invocations [1 day]: ~200k
» CI build: ~19 min (8 parallel workers)
5](https://image.slidesharecdn.com/sredevops-czjug-2018-05-21-180522053221/75/SRE-in-Apiary-5-2048.jpg)











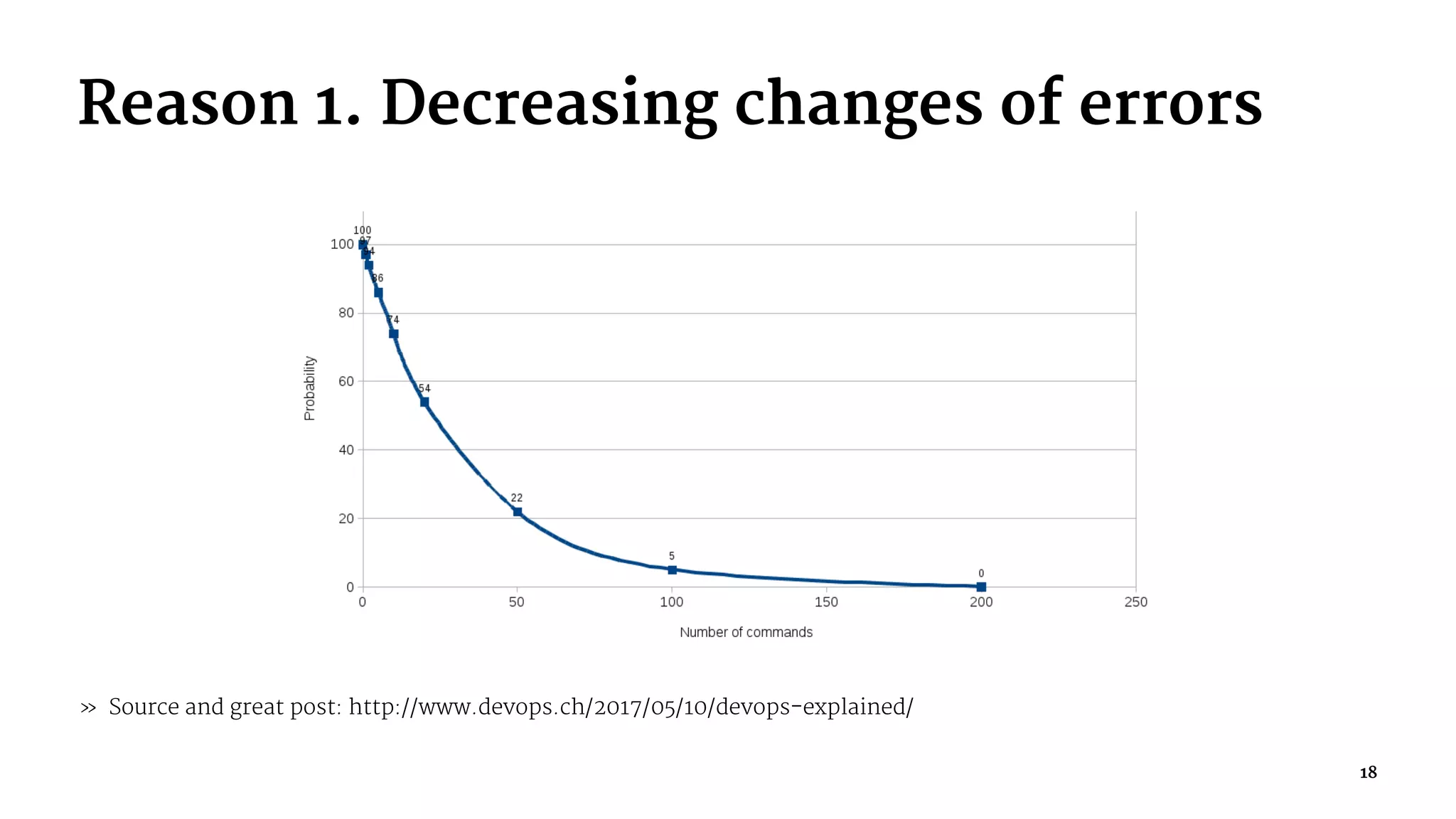











The document discusses Site Reliability Engineering (SRE) at Apiary. It provides details on Apiary's SRE team size and growth over time, their focus on culture over tools, shared responsibility for the platform, monitoring everything, gradual changes through continuous delivery, and emphasis on automation, on-call processes, incident response, and learning from postmortems. The goal of SRE is to decrease errors, eliminate toil, and focus on creative engineering work that improves reliability, performance, and scalability.




























![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)


























































