Downloaded 136 times









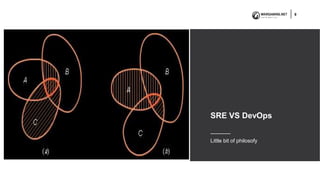



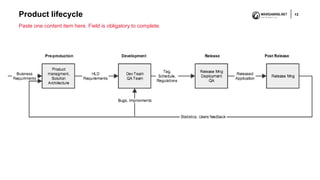








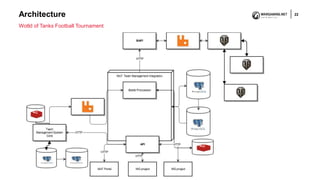



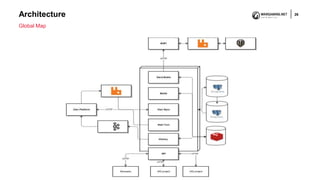





The document discusses the differences and similarities between Site Reliability Engineering (SRE) and DevOps, emphasizing their roles in creating reliable software systems. It explains how SRE focuses on engineering principles to enhance system reliability throughout the product lifecycle, while DevOps promotes collaboration between developers and IT professionals for efficient software delivery. Ultimately, it concludes that both approaches aim for similar outcomes but through varied methodologies.






























![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)

































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)












