Downloaded 180 times






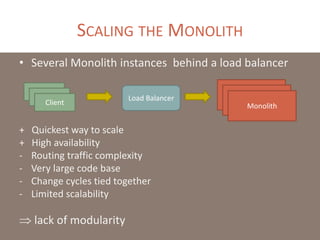
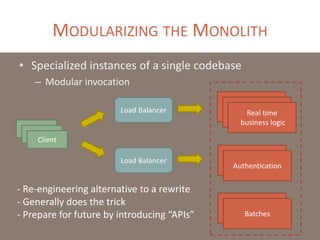

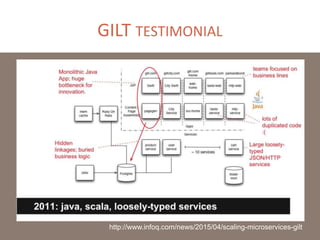
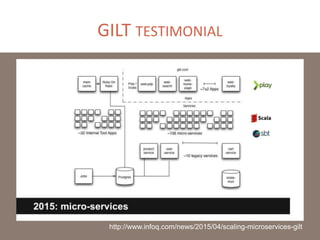

















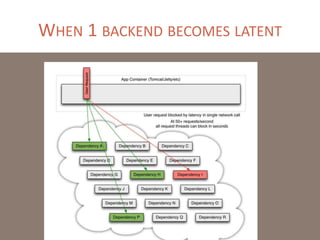
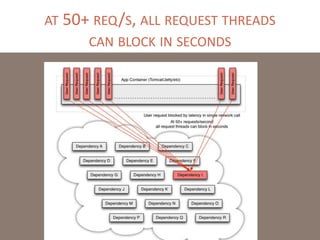
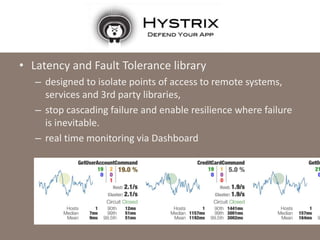
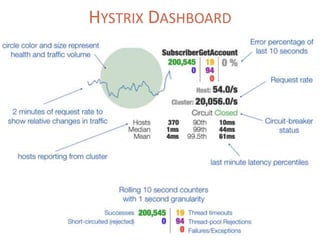
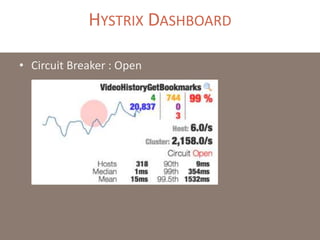
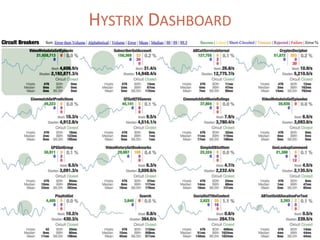


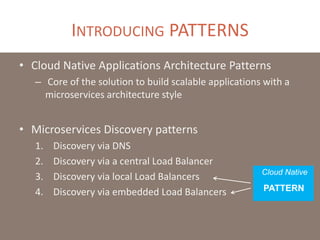

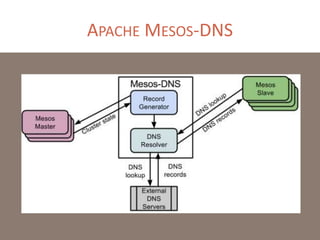

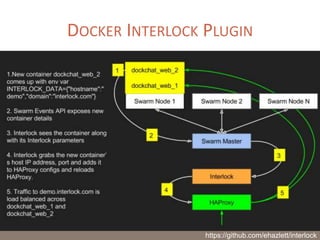

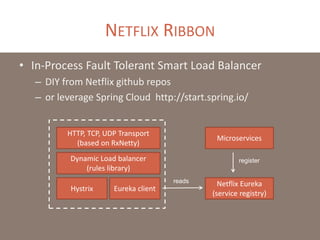

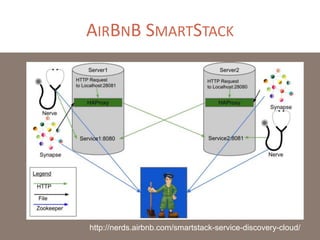



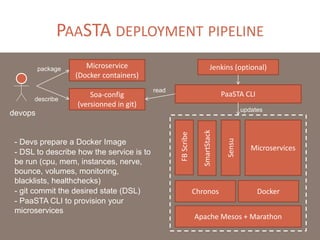
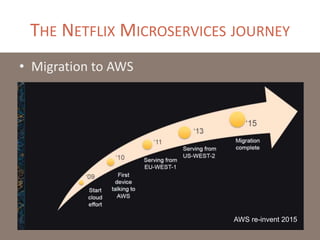

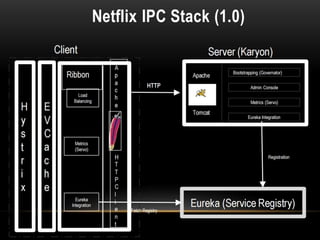
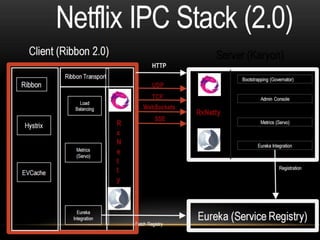

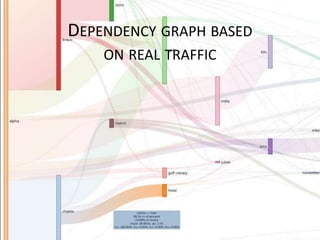
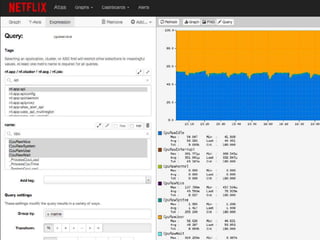
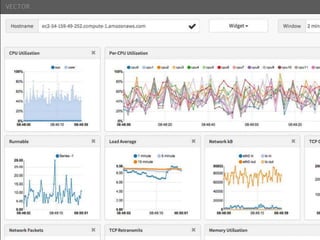
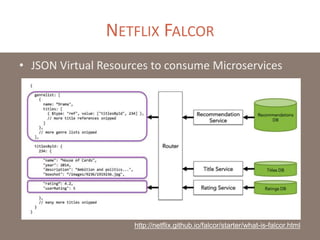


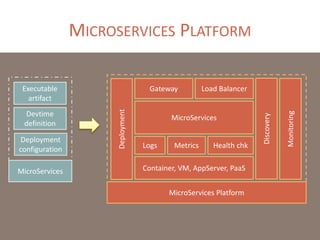
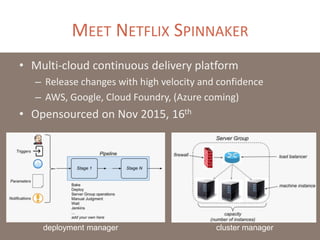
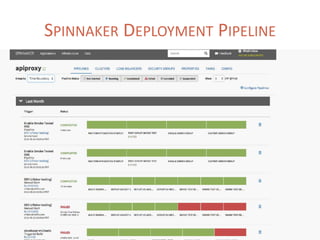
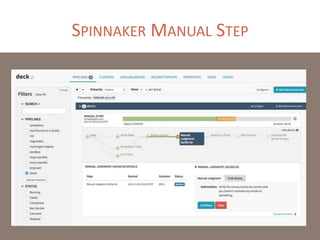
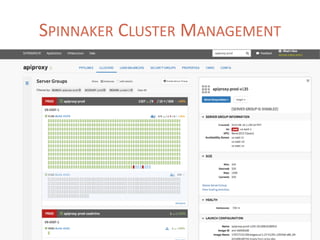
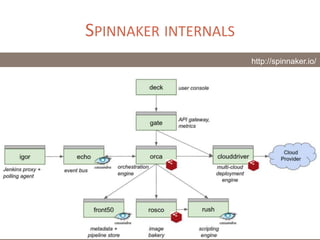



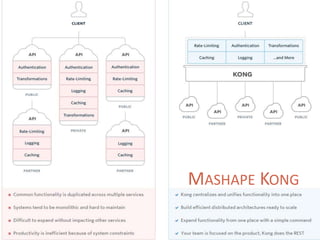



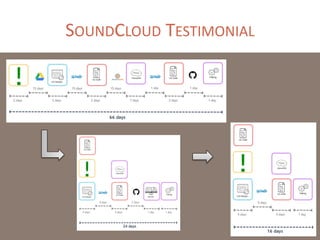
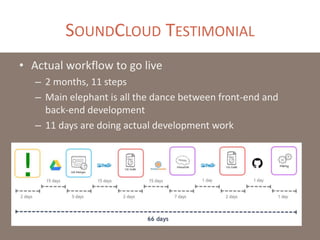
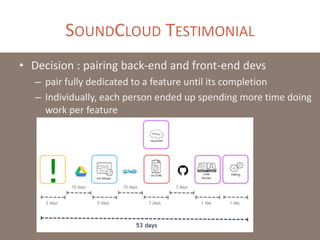
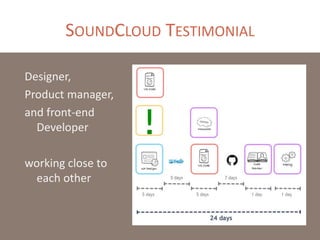












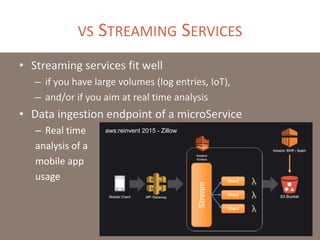














The document provides a comprehensive overview of microservices architecture, highlighting its advantages over monolithic applications and discussing cloud-native patterns, resilience, service discovery, and organizational changes required for successful implementation. It explores case studies from industry pioneers like Netflix and Amazon, elaborating on best practices for microservices development, deployment, and management tools. Additionally, it emphasizes the importance of team ownership and flexibility within an organization to adapt to the evolving demands of microservices-based applications.




















![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=640&height=640&fit=bounds)






















































































