Download as PDF, PPTX

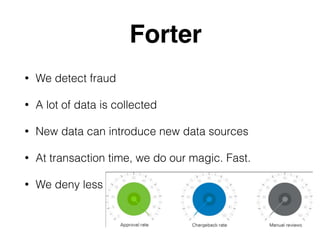






















The document outlines the operational aspects of a data processing framework using Storm, detailing its components such as spouts and bolts, as well as the challenges of managing high throughput and low latency decision-making systems. It emphasizes the importance of data validity, monitoring, and scalability in processing streams of data efficiently. Additionally, it highlights specific implementation strategies, such as state management, caching, and error handling to optimize performance.























































































