Downloaded 511 times









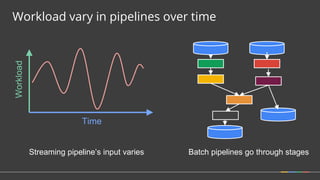
![How do refinements relate?
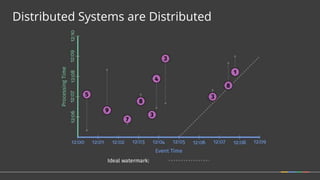
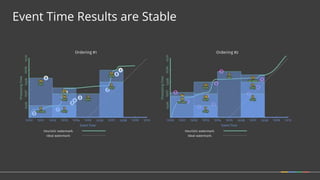
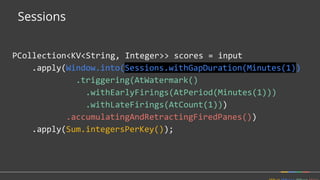
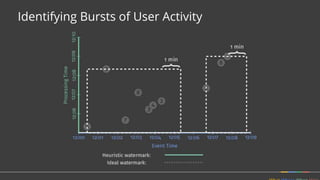
• How should multiple outputs per window accumulate?
• Appropriate choice depends on consumer.
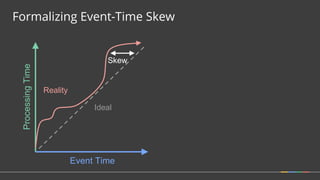
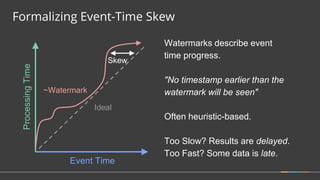
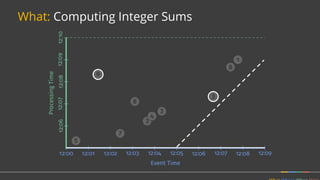
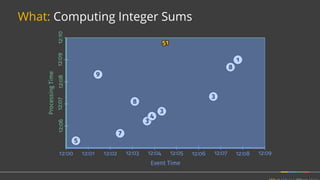
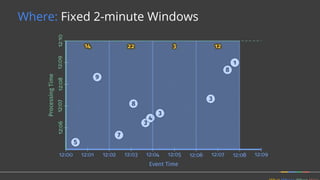
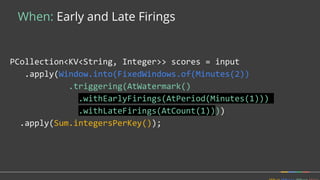
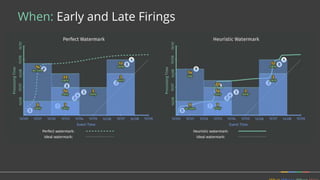
Firing Elements
Speculative [3]
Watermark [5, 1]
Late [2]
Last Observed
Total Observed
Discarding
3
6
2
2
11
Accumulating
3
9
11
11
23
Acc. & Retracting
3
9, -3
11, -9
11
11
(Accumulating & Retracting not yet implemented.)](https://image.slidesharecdn.com/june30410googlebonaci-160711213841/85/Apache-Beam-A-unified-model-for-batch-and-stream-processing-data-27-320.jpg)
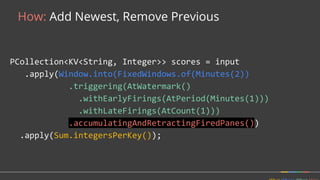
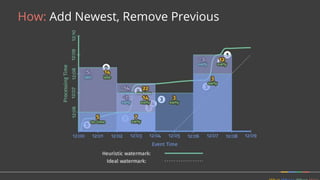











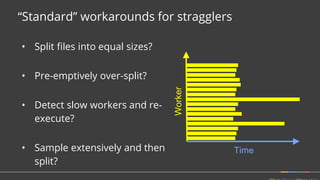

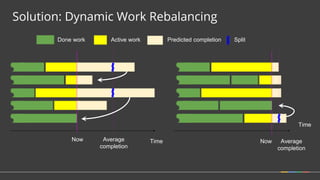
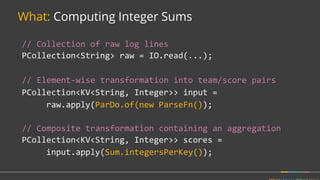
![Solution: Dynamic work rebalancing
class MyReader
extends BoundedReader<T> {
[...]
getFractionConsumed() { }
splitAtFraction(...) { }
}
class MySource
extends BoundedSource<T> {
[...]
splitIntoBundles() { }
getEstimatedSizeBytes() { }
}](https://image.slidesharecdn.com/june30410googlebonaci-160711213841/85/Apache-Beam-A-unified-model-for-batch-and-stream-processing-data-51-320.jpg)

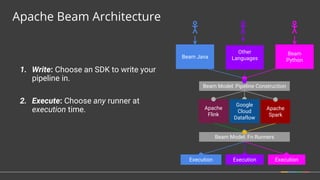




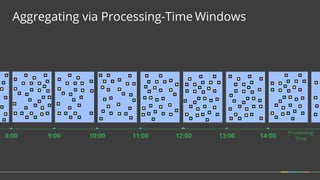
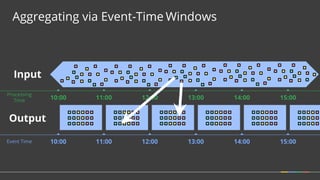
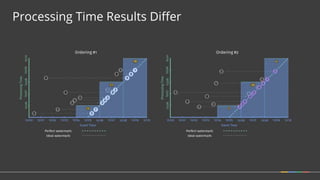
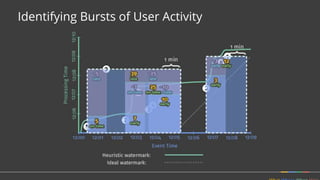

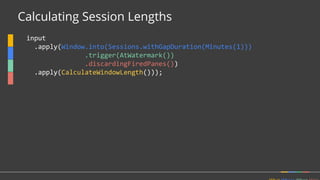
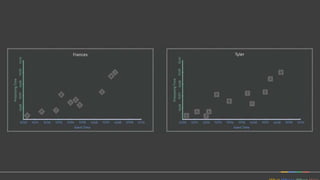
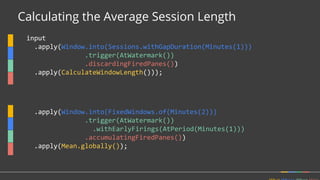

Apache Beam is a unified programming model for batch and streaming data processing. It defines concepts for describing what computations to perform (the transformations), where the data is located in time (windowing), when to emit results (triggering), and how to accumulate results over time (accumulation mode). Beam aims to provide portable pipelines across multiple execution engines, including Apache Flink, Apache Spark, and Google Cloud Dataflow. The talk will cover the key concepts of the Beam model and how it provides unified, efficient, and portable data processing pipelines.


























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)












