Download as PDF, PPTX








![Java SDK
public static void main(String[] args) {
// Create a pipeline parameterized by commandline flags.
Pipeline p = Pipeline.create(PipelineOptionsFactory.fromArgs(arg));
p.apply(TextIO.Read.from("/path/to...")) // Read input.
.apply(new CountWords()) // Do some processing.
.apply(TextIO.Write.to("/path/to...")); // Write output.
// Run the pipeline.
p.run();
}](https://image.slidesharecdn.com/introductiontoapachebeam-160317200042/85/Introduction-to-Apache-Beam-10-320.jpg)


![Beam Runners
Google Cloud Dataflow Apache Flink* Apache Spark*
[*] With varying levels of fidelity.
The Apache Beam (http://beam.incubator.apache.org) site will have more details soon.
?
Other Runner*
(local, OSGi, …)](https://image.slidesharecdn.com/introductiontoapachebeam-160317200042/85/Introduction-to-Apache-Beam-13-320.jpg)




![User Game - Gaming - UserScore - Parse Event Fn
static class ParseEventFn extends DoFn<String, GameActionInfo> {
// Log and count parse errors.
private static final Logger LOG = LoggerFactory.getLogger(ParseEventFn.class);
private final Aggregator<Long, Long> numParseErrors =
createAggregator("ParseErrors", new Sum.SumLongFn());
@Override
public void processElement(ProcessContext c) {
String[] components = c.element().split(",");
try {
String user = components[0].trim();
String team = components[1].trim();
Integer score = Integer.parseInt(components[2].trim());
Long timestamp = Long.parseLong(components[3].trim());
GameActionInfo gInfo = new GameActionInfo(user, team, score, timestamp);
c.output(gInfo);
} catch (ArrayIndexOutOfBoundsException | NumberFormatException e) {
numParseErrors.addValue(1L);
LOG.info("Parse error on " + c.element() + ", " + e.getMessage());
}
}
}](https://image.slidesharecdn.com/introductiontoapachebeam-160317200042/85/Introduction-to-Apache-Beam-18-320.jpg)





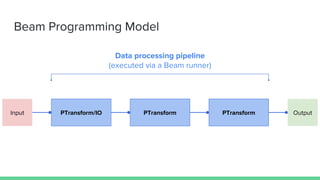
Apache Beam is a unified programming model for batch and stream processing that allows data processing pipelines to be executed across various backends using different runners, such as Apache Flink, Spark, and Google Cloud Dataflow. It provides a portable and extensible framework with features like event windowing, triggers, and custom input/output sources, enabling real-time processing and advanced data manipulation. The document outlines the Beam programming model, various SDKs, example use cases, and the evolution of the technology within the Apache ecosystem.



































































