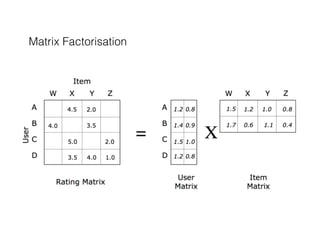
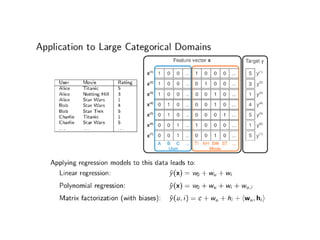
This document discusses matrix factorization techniques. Matrix factorization involves decomposing a large, sparse matrix into more compact, ordered matrices. Common factorization methods include singular value decomposition (SVD), principal component analysis (PCA), and non-negative matrix factorization (NMF). NMF decomposes a matrix into two lower rank, non-negative matrices. It can reduce space needed to store data compared to SVD. The document provides an example of using NMF to factorize a user-item rating matrix to make recommendations.







































![[Paper] attention mechanism(luong)](https://cdn.slidesharecdn.com/ss_thumbnails/paperattentionmechanismluong-210508090926-thumbnail.jpg?width=640&height=640&fit=bounds)

































































