Downloaded 33 times



















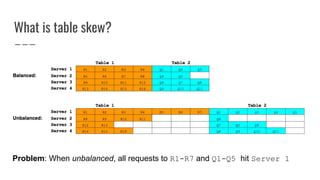






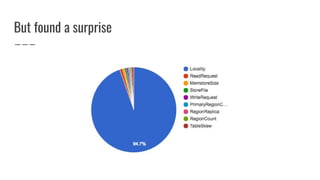
![New table skew cost function (HBASE-17707)
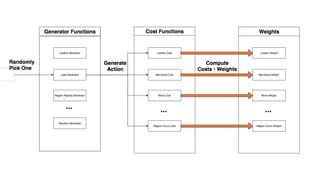
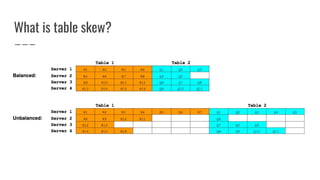
● Computes number of moves/swaps required to evenly
distribute each table’s regions
● Outputs a value between [0, 1] proportional to the number
of moves required](https://image.slidesharecdn.com/improvinghbaseavailabilityinamulti-tenantenvironment-170620190602/85/HBaseCon2017-Improving-HBase-availability-in-a-multi-tenant-environment-39-320.jpg)
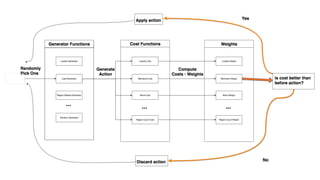
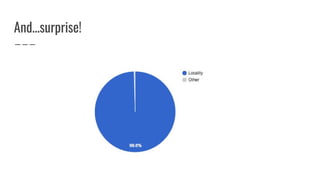
![New table skew cost function (HBASE-17707)
● Computes number of moves/swaps required to evenly
distribute each table’s regions
● Outputs a value between [0, 1] proportional to the number
of moves required
● Analogous to “edit distance” between two words](https://image.slidesharecdn.com/improvinghbaseavailabilityinamulti-tenantenvironment-170620190602/85/HBaseCon2017-Improving-HBase-availability-in-a-multi-tenant-environment-40-320.jpg)


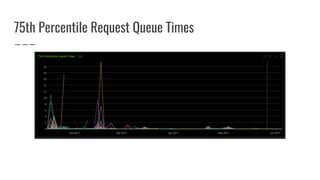
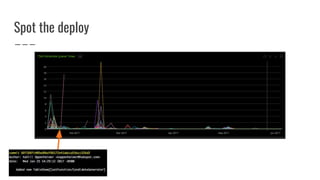
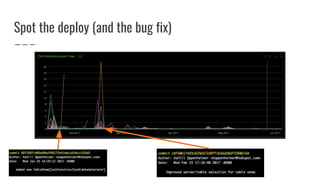


























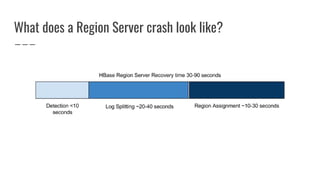
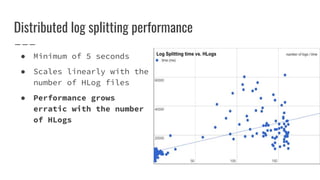
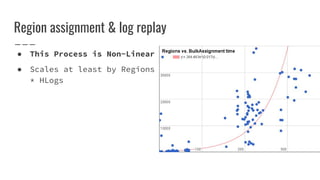
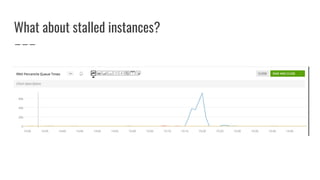
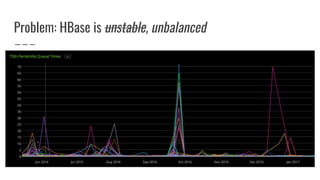
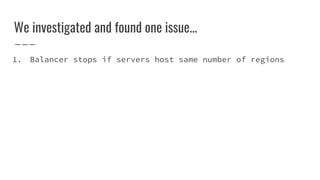
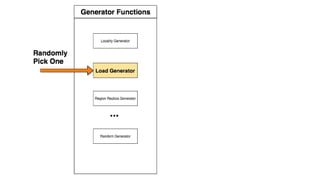
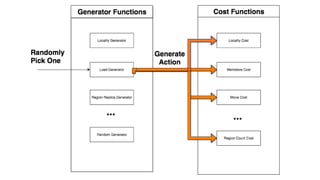
The document discusses improvements made by Hubspot's Big Data Team to increase the availability of HBase in a multi-tenant environment. It outlines reducing the cost of region server failures by improving mean time to recovery, addressing issues that slowed recovery, and optimizing the load balancer. It also details eliminating workload-driven failures through service limits and improving hardware monitoring to reduce impacts of failures. The changes resulted in 8-10x faster balancing, reduced recovery times from 90 to 30 seconds, and consistently achieving 99.99% availability across clusters.



















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)


