Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning Lab(ディープラーニング・ラボ)
30,304 views
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
日本マイクロソフト株式会社 山口順也 氏
Technology
◦
Read more
55
Save
Share
Embed
Embed presentation
Download
Downloaded 265 times
1
/ 60
2
/ 60
Most read
3
/ 60
4
/ 60
5
/ 60
6
/ 60
7
/ 60
8
/ 60
9
/ 60
10
/ 60
11
/ 60
12
/ 60
13
/ 60
14
/ 60
15
/ 60
16
/ 60
17
/ 60
18
/ 60
19
/ 60
20
/ 60
21
/ 60
22
/ 60
23
/ 60
24
/ 60
25
/ 60
26
/ 60
27
/ 60
28
/ 60
29
/ 60
30
/ 60
31
/ 60
32
/ 60
33
/ 60
34
/ 60
35
/ 60
36
/ 60
37
/ 60
38
/ 60
39
/ 60
40
/ 60
41
/ 60
42
/ 60
43
/ 60
44
/ 60
45
/ 60
Most read
46
/ 60
47
/ 60
48
/ 60
49
/ 60
50
/ 60
51
/ 60
52
/ 60
53
/ 60
54
/ 60
55
/ 60
56
/ 60
57
/ 60
58
/ 60
59
/ 60
60
/ 60
Most read
More Related Content
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
関数データ解析の概要とその方法
by
Hidetoshi Matsui
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PDF
2 3.GLMの基礎
by
logics-of-blue
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
ベイズ統計入門
by
Miyoshi Yuya
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
関数データ解析の概要とその方法
by
Hidetoshi Matsui
ベイズ統計学の概論的紹介
by
Naoki Hayashi
階層ベイズによるワンToワンマーケティング入門
by
shima o
2 3.GLMの基礎
by
logics-of-blue
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
階層モデルの分散パラメータの事前分布について
by
hoxo_m
ベイズ統計入門
by
Miyoshi Yuya
What's hot
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PPTX
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
PDF
DSIRNLP#1 ランキング学習ことはじめ
by
sleepy_yoshi
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PDF
正準相関分析
by
Akisato Kimura
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
最適輸送の解き方
by
joisino
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
PPTX
backbone としての timm 入門
by
Takuji Tahara
PDF
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
PDF
なぜベイズ統計はリスク分析に向いているのか? その哲学上および実用上の理由
by
takehikoihayashi
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
21世紀の手法対決 (MIC vs HSIC)
by
Toru Imai
PDF
ベイズ推定の概要@広島ベイズ塾
by
Yoshitake Takebayashi
PPTX
ベイズファクターとモデル選択
by
kazutantan
GAN(と強化学習との関係)
by
Masahiro Suzuki
一般化線形混合モデル入門の入門
by
Yu Tamura
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
DSIRNLP#1 ランキング学習ことはじめ
by
sleepy_yoshi
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
正準相関分析
by
Akisato Kimura
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
最適輸送の解き方
by
joisino
機械学習モデルの判断根拠の説明
by
Satoshi Hara
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
backbone としての timm 入門
by
Takuji Tahara
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
なぜベイズ統計はリスク分析に向いているのか? その哲学上および実用上の理由
by
takehikoihayashi
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
21世紀の手法対決 (MIC vs HSIC)
by
Toru Imai
ベイズ推定の概要@広島ベイズ塾
by
Yoshitake Takebayashi
ベイズファクターとモデル選択
by
kazutantan
Similar to 一般化線形モデル (GLM) & 一般化加法モデル(GAM)
PDF
2 4.devianceと尤度比検定
by
logics-of-blue
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
MLaPP 9章 「一般化線形モデルと指数型分布族」
by
moterech
PDF
反応時間データをどう分析し図示するか
by
SAKAUE, Tatsuya
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
PDF
Mplusの使い方 中級編
by
Hiroshi Shimizu
PPTX
一般線形モデル
by
MatsuiRyo
PDF
みどりぼん3章前半
by
Akifumi Eguchi
PDF
【書きかけ】一般化線形モデルの流れ
by
Tomoshige Nakamura
PDF
分布から見た線形モデル・GLM・GLMM
by
. .
PPTX
一般化線形モデル
by
MatsuiRyo
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PDF
データ解析のための統計モデリング入門 6.5章 後半
by
Yurie Oka
PPTX
第三回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
データ解析のための統計モデリング入門3章後半
by
Shinya Akiba
PDF
分割表の作図・GLM・ベイズモデル http://goo.gl/qQ1Ok
by
Kubo_Takuya
PPTX
第四回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
PDF
データ解析のための統計モデリング入門-6章後半
by
yukit_cesc
2 4.devianceと尤度比検定
by
logics-of-blue
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
MLaPP 9章 「一般化線形モデルと指数型分布族」
by
moterech
反応時間データをどう分析し図示するか
by
SAKAUE, Tatsuya
Stanコードの書き方 中級編
by
Hiroshi Shimizu
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
Mplusの使い方 中級編
by
Hiroshi Shimizu
一般線形モデル
by
MatsuiRyo
みどりぼん3章前半
by
Akifumi Eguchi
【書きかけ】一般化線形モデルの流れ
by
Tomoshige Nakamura
分布から見た線形モデル・GLM・GLMM
by
. .
一般化線形モデル
by
MatsuiRyo
PRML10-draft1002
by
Toshiyuki Shimono
データ解析のための統計モデリング入門 6.5章 後半
by
Yurie Oka
第三回統計学勉強会@東大駒場
by
Daisuke Yoneoka
データ解析のための統計モデリング入門3章後半
by
Shinya Akiba
分割表の作図・GLM・ベイズモデル http://goo.gl/qQ1Ok
by
Kubo_Takuya
第四回統計学勉強会@東大駒場
by
Daisuke Yoneoka
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
データ解析のための統計モデリング入門-6章後半
by
yukit_cesc
More from Deep Learning Lab(ディープラーニング・ラボ)
PDF
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Edge AI ソリューションを支える Azure IoT サービス
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
深層強化学習を用いた複合機の搬送制御
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
厚生労働分野におけるAI技術の利活用について
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream With Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream With Azure IoT 事前準備
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
AIによる細胞診支援技術の紹介と、AI人材が考える医療バイオ領域における参入障壁の乗り越え方
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
「言語」×AI Digital Device
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Azure ML 強化学習を用いた最新アルゴリズムの活用手法
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Intel AI in Healthcare 各国事例からみるAIとの向き合い方
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson 活用による スタートアップ企業支援
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
医学と工学の垣根を越えた医療AI開発
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
DLLAB Healthcare Day 2021 Event Report
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
先端技術がもたらす「より良いヘルスケアのかたち」
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
ICTを用いた健康なまちづくりの 取り組みとAI活用への期待
by
Deep Learning Lab(ディープラーニング・ラボ)
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
Edge AI ソリューションを支える Azure IoT サービス
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
深層強化学習を用いた複合機の搬送制御
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測
by
Deep Learning Lab(ディープラーニング・ラボ)
厚生労働分野におけるAI技術の利活用について
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream With Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream With Azure IoT 事前準備
by
Deep Learning Lab(ディープラーニング・ラボ)
AIによる細胞診支援技術の紹介と、AI人材が考える医療バイオ領域における参入障壁の乗り越え方
by
Deep Learning Lab(ディープラーニング・ラボ)
「言語」×AI Digital Device
by
Deep Learning Lab(ディープラーニング・ラボ)
Azure ML 強化学習を用いた最新アルゴリズムの活用手法
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略
by
Deep Learning Lab(ディープラーニング・ラボ)
Intel AI in Healthcare 各国事例からみるAIとの向き合い方
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson 活用による スタートアップ企業支援
by
Deep Learning Lab(ディープラーニング・ラボ)
医学と工学の垣根を越えた医療AI開発
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~
by
Deep Learning Lab(ディープラーニング・ラボ)
DLLAB Healthcare Day 2021 Event Report
by
Deep Learning Lab(ディープラーニング・ラボ)
先端技術がもたらす「より良いヘルスケアのかたち」
by
Deep Learning Lab(ディープラーニング・ラボ)
ICTを用いた健康なまちづくりの 取り組みとAI活用への期待
by
Deep Learning Lab(ディープラーニング・ラボ)
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
1.
一般化線形モデル(GLM) & 一般化加法モデル(GAM) 山口 順也 日本マイクロソフト株式会社
2.
• 近年、機械学習モデルの解釈可能性が重視されている • 総務省
AI 開発ガイドライン案 (2017) “透明性の原則: 開発者は、AIシステムの入出力の検証可能 性及び判断結果の説明可能性に留意する。“ • GDBR (2018) “the data controller shall implement suitable measures to safeguard the data subject’s rights and freedoms and legitimate interests” • モデルの解釈方法にはいくつか種類がある • 大域的な説明:モデル自体を解釈する • 局所的な説明:特定の入力に対する予測の根拠を提示 • 説明可能なモデルの設計:そもそも最初から可読性の高いモデルを作る戦略 • 深層学習モデルの説明:深層学習モデル、特に画像認識モデルの説明法 • GLM や GAM は自然に説明可能なモデルの一つであり、その発展形として のモデル解釈の道はまだ半ば • Microsoft Research から GA2M と呼ばれる GAM の拡張手法が提案 (Lou Yin, et al. 2019) なんで今さら GLM?GAM?
3.
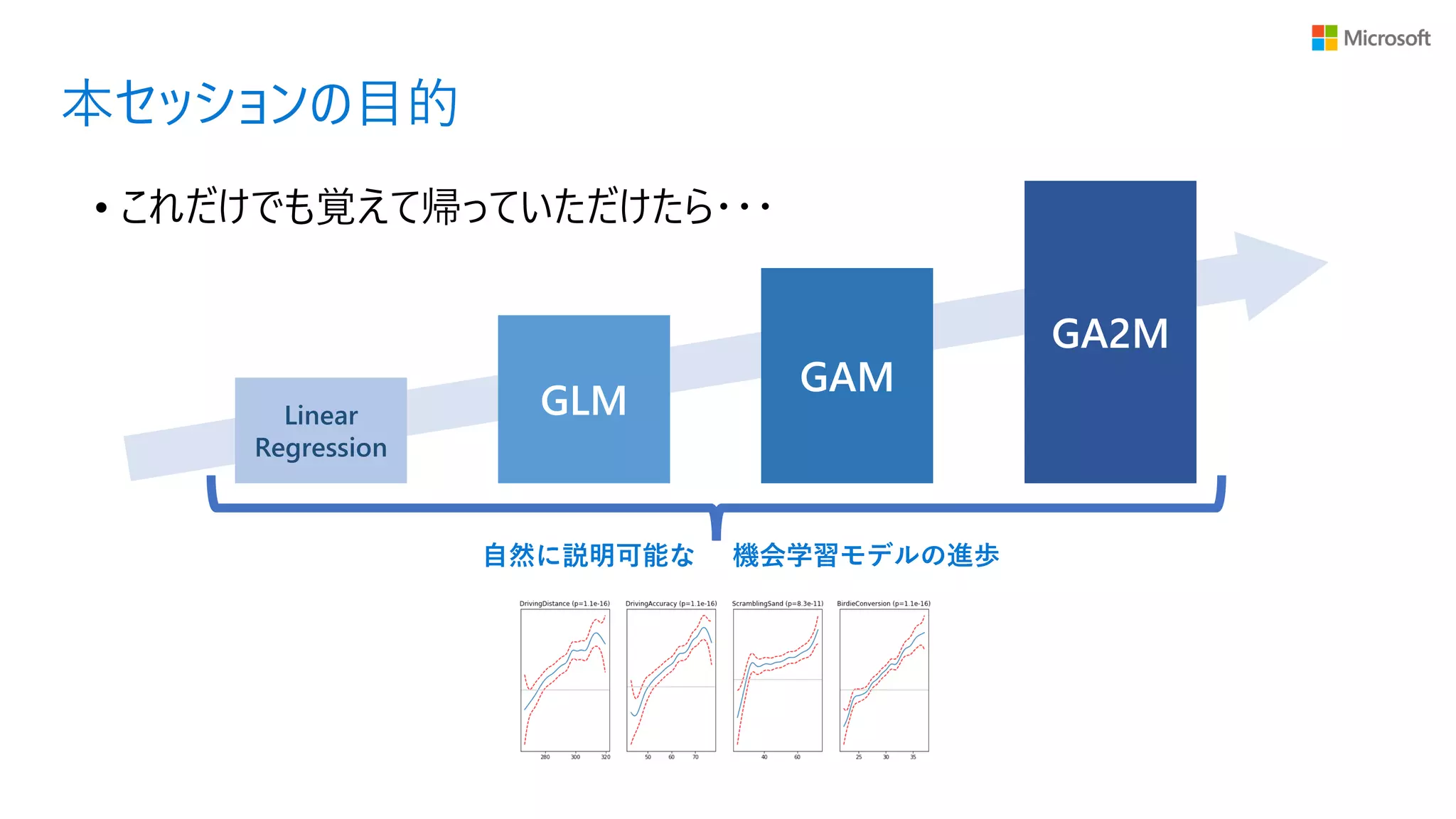
• これだけでも覚えて帰っていただけたら・・・ 本セッションの目的 自然に説明可能な 機会学習モデルの進歩 GLM GAM GA2M Linear Regression
4.
• 一般化線形モデル (GLM)
ってなに? • GLM 利用時の注意点 • 一般化加法モデル (GAM) ってなに? • GLM と GAM の Python パッケージ • GA2M への拡張 話すこと GLM GAM GA2M
5.
• ブラックボックスモデルの解釈方法 • PD,
SHAP, Anchors, Prototype Selection… • 「自然に解釈可能な機械学習モデル」のその他の動向 • 決定木、ルール学習、ナイーブベイズ・・・ • Angelino, Elaine, et al. “Learning certifiably optimal rule lists for categorical data.“ 2017 • Wang, Tong, et al. "A Bayesian framework for learning rule sets for interpretable classification." 2017 • 解釈の先を考慮したメタ的な戦略 • モデル列挙によってユーザの安心できる結果を提示 Satoshi Hara, Masakazu Ishihata “Approximate and Exact Enumeration of Rule Models.” AAAI, 2018 話さないこと
6.
参考資料 (俯瞰的な資料) Interpretable Machine
Learning – A Guide for Making Black Box Models Explainable. https://christophm.github.io/interpretable-ml-book/ 私のブックマーク「機械学習における解釈性(Interpretability in Machine Learning)」 – 人工知能 学会 https://www.ai-gakkai.or.jp/my-bookmark_vol33-no3/ 私のブックマーク「説明可能AI」(Explainable AI) – 人工知能学会 https://www.ai-gakkai.or.jp/my-bookmark_vol34-no4/ 機械学習モデルの判断根拠の説明 – YouTube https://www.youtube.com/watch?v=Fgza_C6KphU
7.
Generalized Linear Models
8.
歴史 Nelder と Wedderburn
によって、様々な統計モデルを統合的する目的で GLM が定式化 1972 1982 McCullagh & Nelder による最初の GLM の教科書 “Generalized Linear Models” 線形回帰, ポアソン回帰, ロジスティック回帰, … ⇒ GLM Dobson, A. J. “An Introduction to Generalized Linear Models”1990 2nd Edition は 2004 年, 3rd Edition は 2008 年 2nd Edition は 1989 年
9.
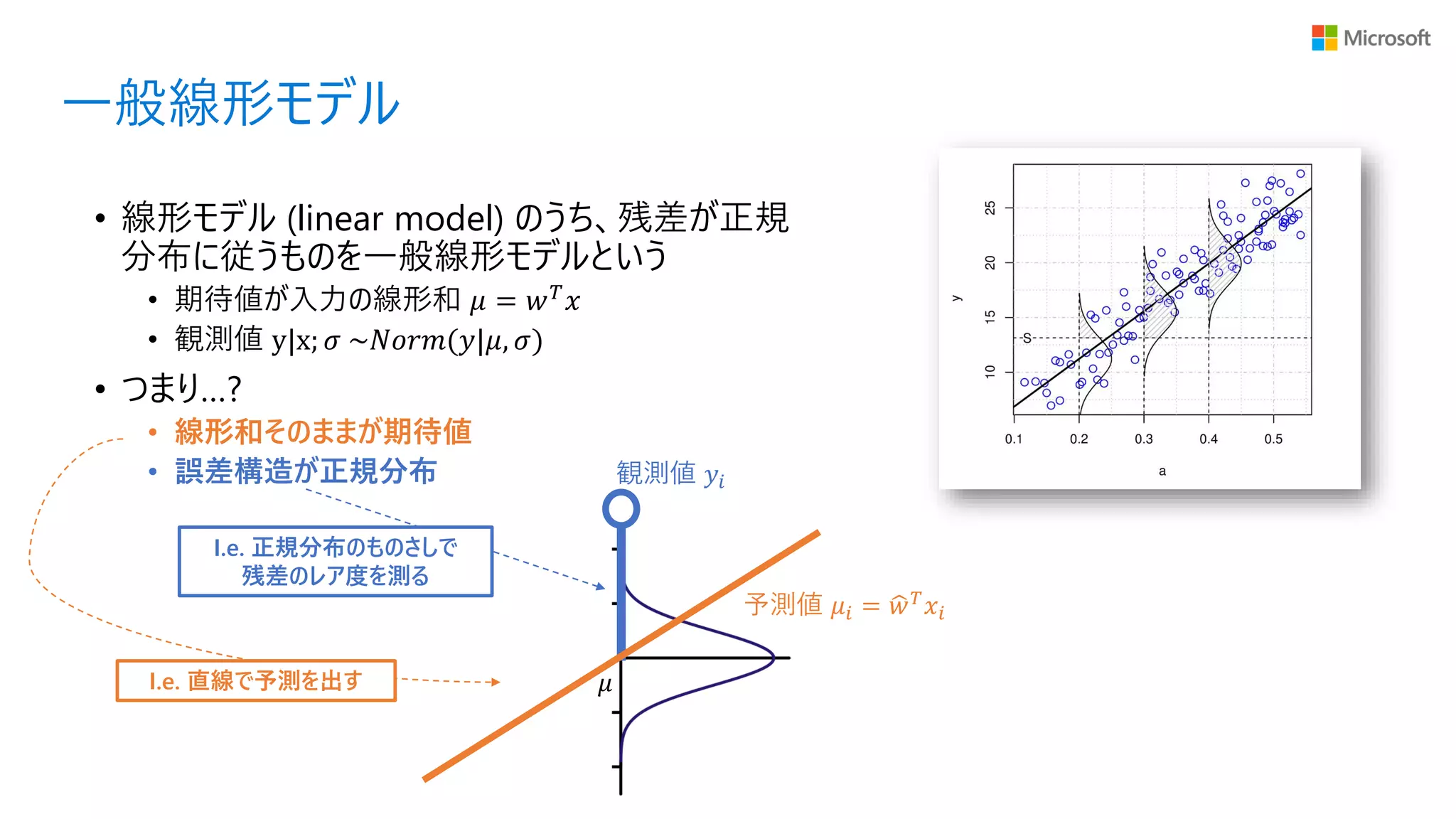
一般線形モデル • 線形モデル (linear
model) のうち、残差が正規 分布に従うものを一般線形モデルという • 期待値が入力の線形和 𝜇 = 𝑤 𝑇 𝑥 • 観測値 y|x; 𝜎 ~𝑁𝑜𝑟𝑚(𝑦|𝜇, 𝜎) • つまり…? • 線形和そのままが期待値 • 誤差構造が正規分布 I.e. 正規分布のものさしで 残差のレア度を測る 𝜇 観測値 𝑦𝑖 予測値 𝜇𝑖 = ෝ𝑤 𝑇 𝑥𝑖 I.e. 直線で予測を出す
10.
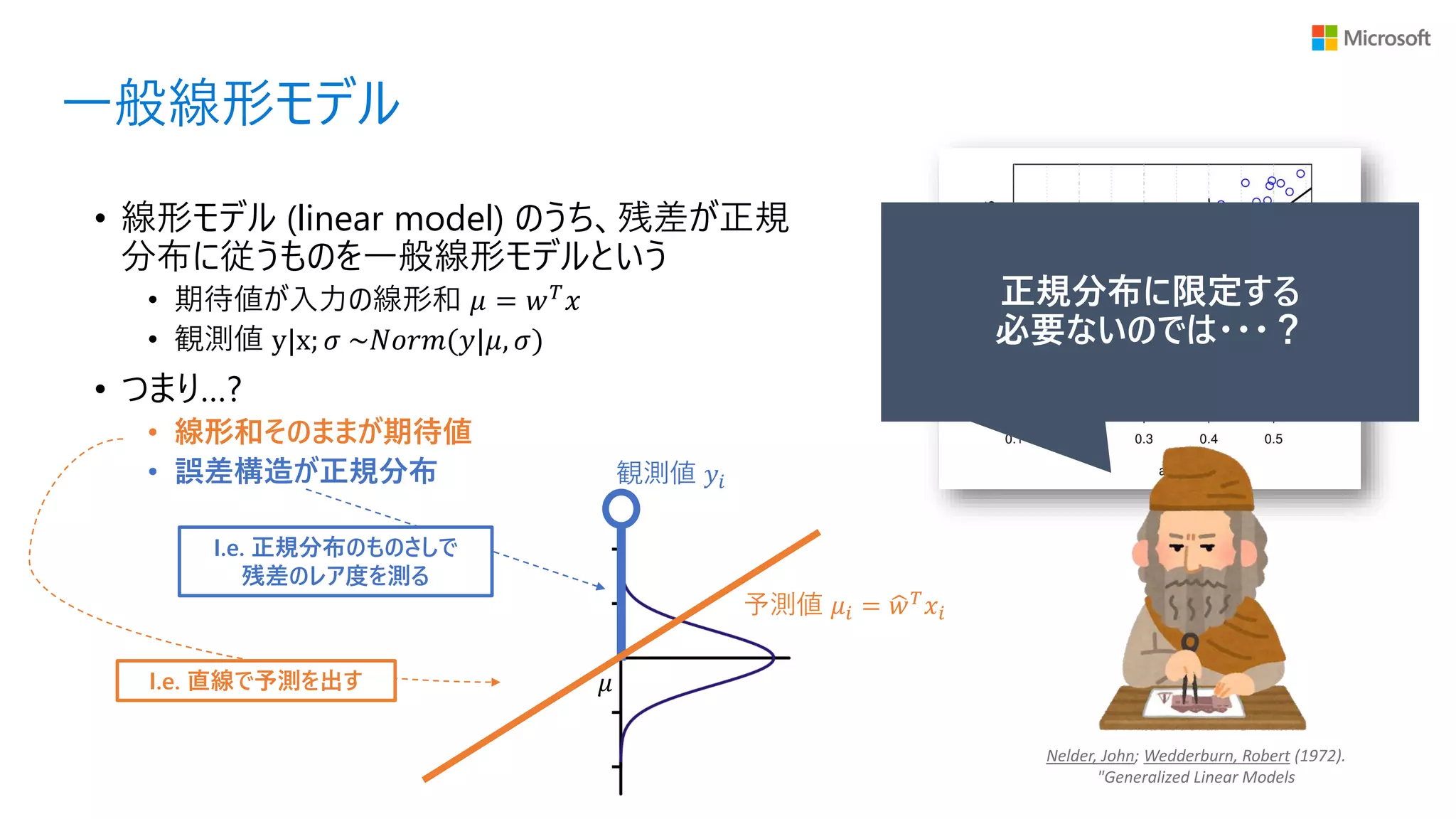
一般線形モデル • 線形モデル (linear
model) のうち、残差が正規 分布に従うものを一般線形モデルという • 期待値が入力の線形和 𝜇 = 𝑤 𝑇 𝑥 • 観測値 y|x; 𝜎 ~𝑁𝑜𝑟𝑚(𝑦|𝜇, 𝜎) • つまり…? • 線形和そのままが期待値 • 誤差構造が正規分布 I.e. 正規分布のものさしで 残差のレア度を測る 𝜇 観測値 𝑦𝑖 予測値 𝜇𝑖 = ෝ𝑤 𝑇 𝑥𝑖 I.e. 直線で予測を出す 正規分布に限定する 必要ないのでは・・・? Nelder, John; Wedderburn, Robert (1972). "Generalized Linear Models
11.
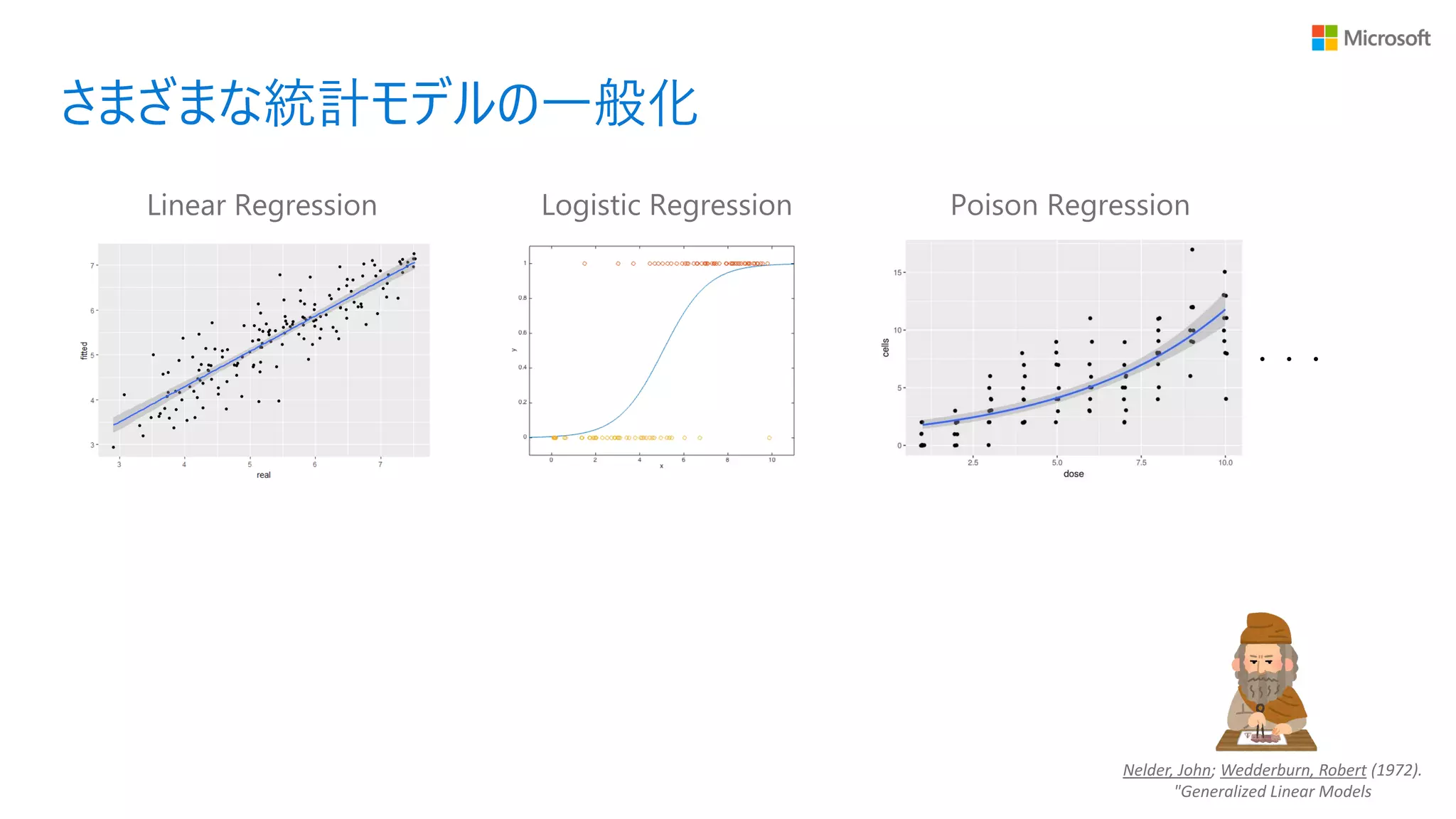
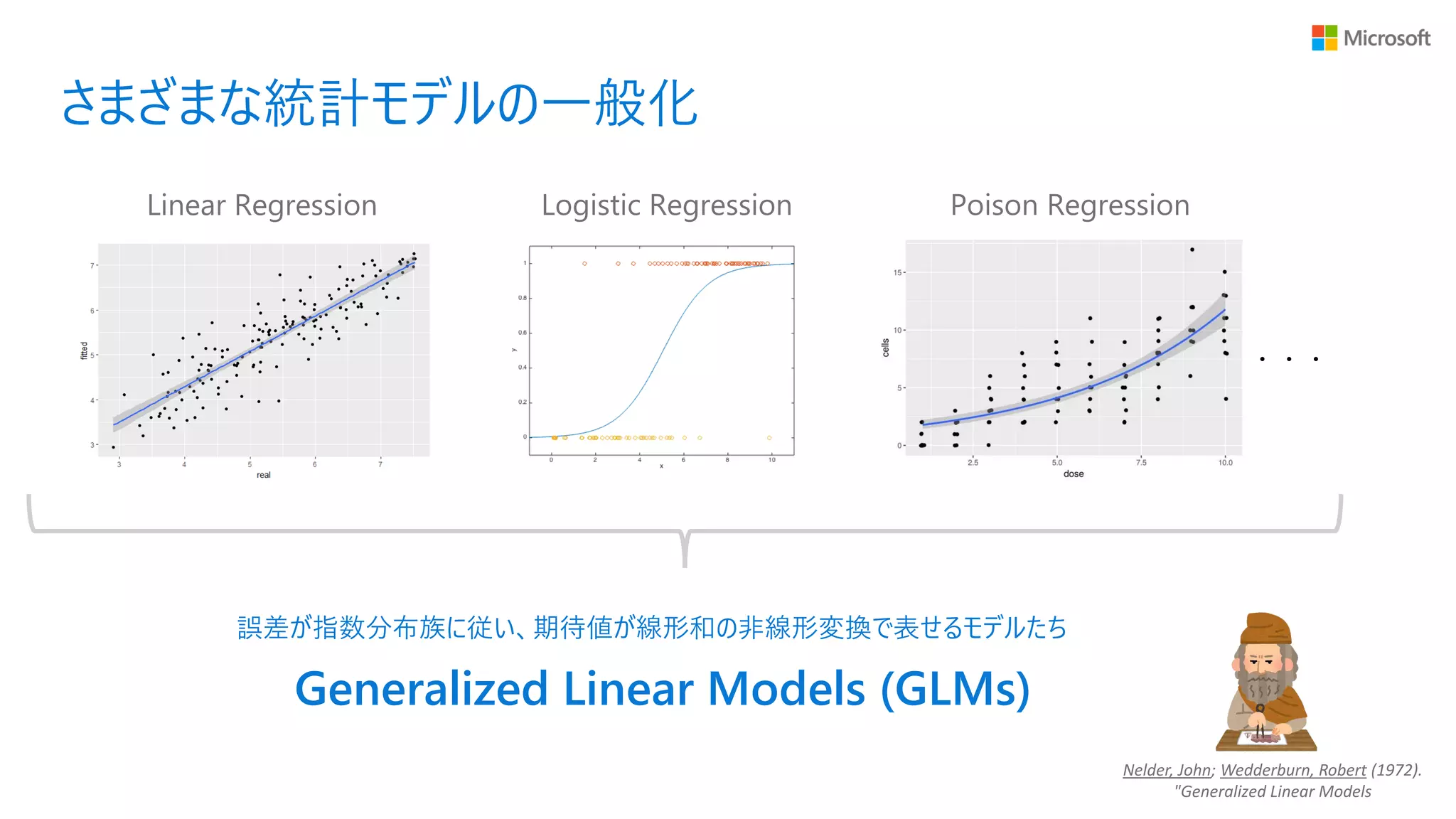
さまざまな統計モデルの一般化 Linear Regression Logistic
Regression ・・・ Poison Regression Nelder, John; Wedderburn, Robert (1972). "Generalized Linear Models
12.
さまざまな統計モデルの一般化 Linear Regression Logistic
Regression ・・・ Poison Regression 誤差が指数分布族に従い、期待値が線形和の非線形変換で表せるモデルたち Generalized Linear Models (GLMs) Nelder, John; Wedderburn, Robert (1972). "Generalized Linear Models
13.
Generalized Linear Model •
一般化線形モデル (Generalized Linear Model; GLM) は、期待値が「線 形予測子の非線形変換」で表され、誤差が「指数型分布族の分布」に独立 に従うことを仮定する統計モデル • 特徴 • 各特徴量が独立 (相互作用を考慮しない) • 線形和と期待値を繋ぐ「リンク関数 g」の存在 • 𝑦|𝑥 の誤差構造を、指数型分布族の中から自由にモデリング可能 • i.i.d. データの対数尤度関数が十分統計量の一次変換 • ベイズ統計において、共役事前分布を必ず持つ • さらにその事後分布が閉じた形で求まる 指数型分布族は 統計の世界において便利な道具
14.
• パンデミックの初期段階では、患者数 𝑦
は指数関数的に増加 • 経過日数 𝑡𝑖 で期待される患者数 𝐸 𝑦𝑖 = 𝜇𝑖 は次のように表現可能 • 推定したいパラメータ: 𝛾, 𝛿 • これを変換すると・・・ • あとは y が整数のカウントデータであることに注意しながら、誤差をポアソン分 布でモデリングすれば、GLM の完成 • GLM の推定アルゴリズムで学習すれば 𝛽0, 𝛽1 が手に入る • 任意の 𝑡 𝑛 日後の期待患者数が予測できる! GLM の例: 感染症の患者数
15.
リンク関数の気持ち • 線形和が取りうる値は、すべての実数 • つまり、マイナスの値にもなるし、ゼロになったりもする •
目的変数 𝒚 の分布によっては、期待値 𝑬[𝒚] の範囲を制御したい • 確率値 0 < 𝐸 𝑦 < 1 になって欲しいとき… • 正の値 0 < 𝐸[𝑦] になって欲しいとき… • そのためのリンク関数 • 逆関数が存在するなめらかな曲線である必要があるが、勝手に決めて良い • ただ、一般的に用いられるリンク関数は大体決まっている ※ 期待値から指数型分布族の正準パラメータへの 写像でリンク関数を与えた時、 そのリンク関数を正準 (canonical) であるという。 0.7 0.9 0.1 -12 +56 -30
16.
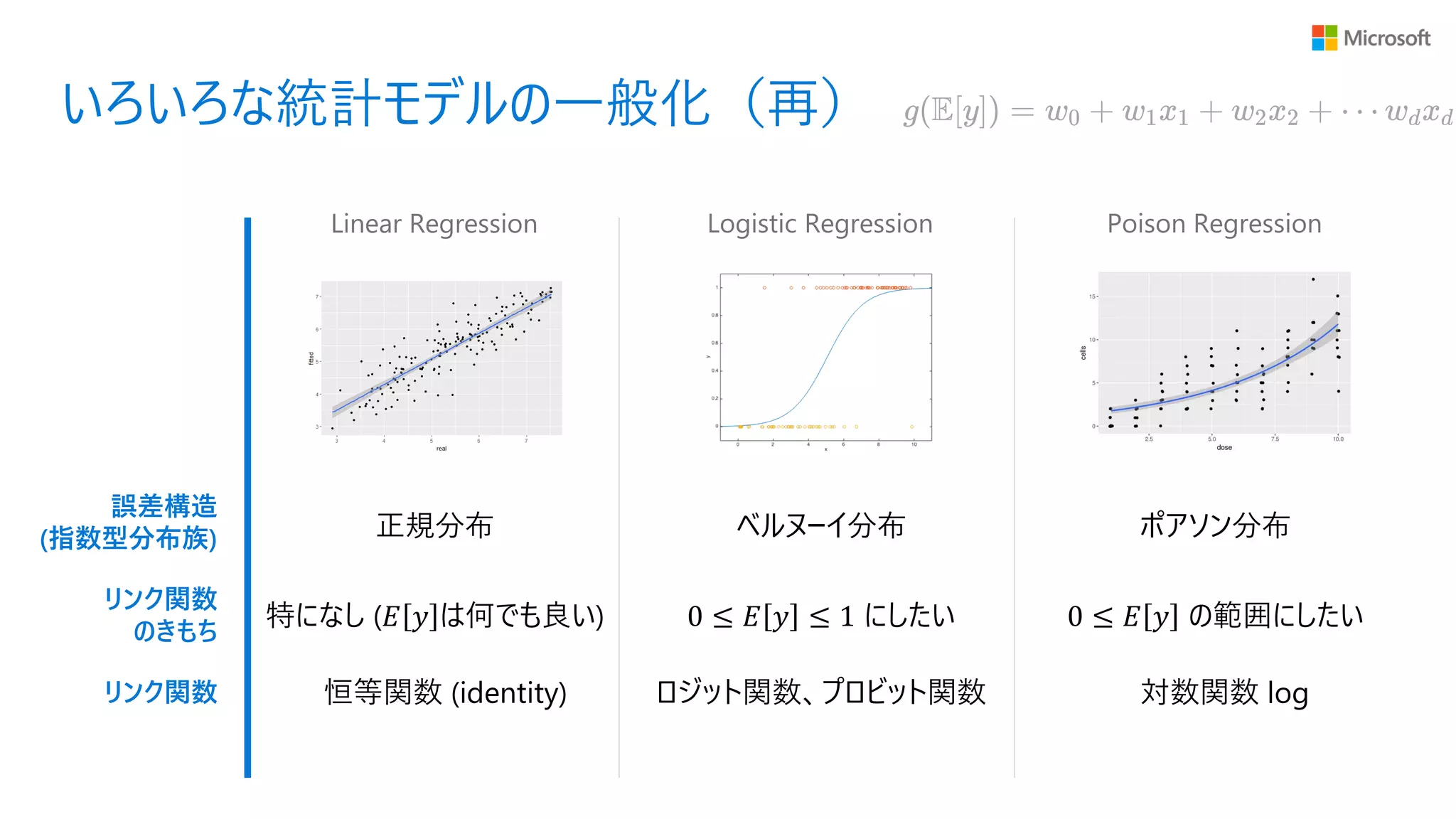
いろいろな統計モデルの一般化(再) Linear Regression Logistic
Regression Poison Regression リンク関数 誤差構造 (指数型分布族) リンク関数 のきもち 正規分布 ベルヌーイ分布 ポアソン分布 特になし (𝐸 𝑦 は何でも良い) 恒等関数 (identity) ロジット関数、プロビット関数 対数関数 log 0 ≤ 𝐸 𝑦 ≤ 1 にしたい 0 ≤ 𝐸 𝑦 の範囲にしたい
17.
GLM 利用時の注意点
18.
GLM での Assumptions i.i.d.
標本 誤差の正しいモデル化 分散の正しいモデル化 特徴量同士の相関が小さい
19.
GLM での Assumptions i.i.d.
標本 誤差の正しいモデル化 分散の正しいモデル化 特徴量同士の相関が小さい How to check Bad Cases • 階層データ:クラスを考慮しない生徒の学力値 • 自己相関データ:同じ患者から何回も採血した血液データ • 自己相関グラフ, Lag プロット • Permutation tests, カイ二乗検定 Examples • サイコロを連続で振った時の “目” の列 • テストの試験 https://www.ucalgary.ca/pst2017/files/pst2017/paper-40.pdf https://rstudio-pubs-static.s3.amazonaws.com/236274_dc519356638e4c5b9b52beb1321fe3ff.html
20.
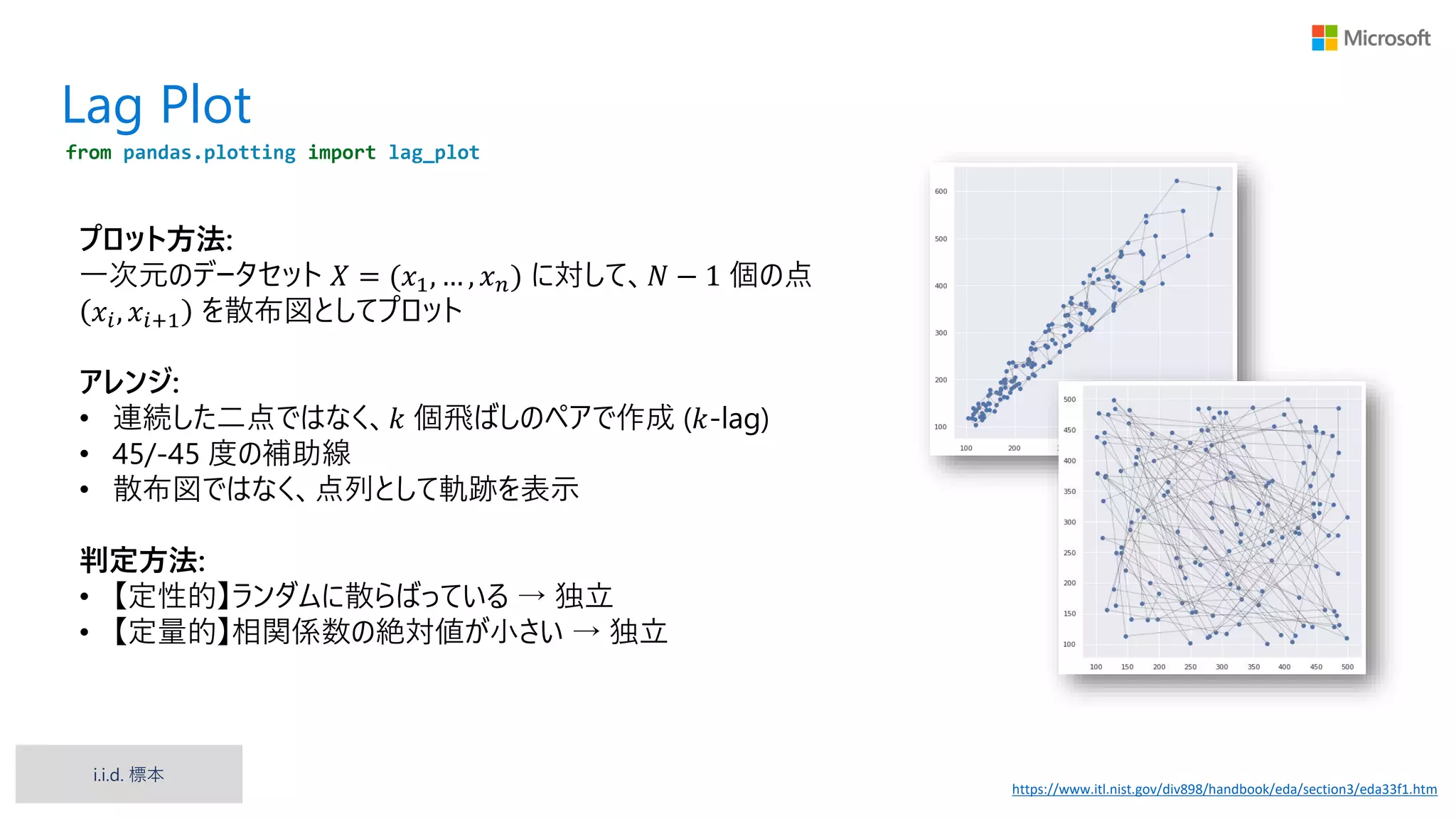
Lag Plot https://www.itl.nist.gov/div898/handbook/eda/section3/eda33f1.htm プロット方法: 一次元のデータセット 𝑋
= (𝑥1, … , 𝑥 𝑛) に対して、𝑁 − 1 個の点 𝑥𝑖, 𝑥𝑖+1 を散布図としてプロット アレンジ: • 連続した二点ではなく、𝑘 個飛ばしのペアで作成 (𝑘-lag) • 45/-45 度の補助線 • 散布図ではなく、点列として軌跡を表示 判定方法: • 【定性的】ランダムに散らばっている → 独立 • 【定量的】相関係数の絶対値が小さい → 独立 from pandas.plotting import lag_plot i.i.d. 標本
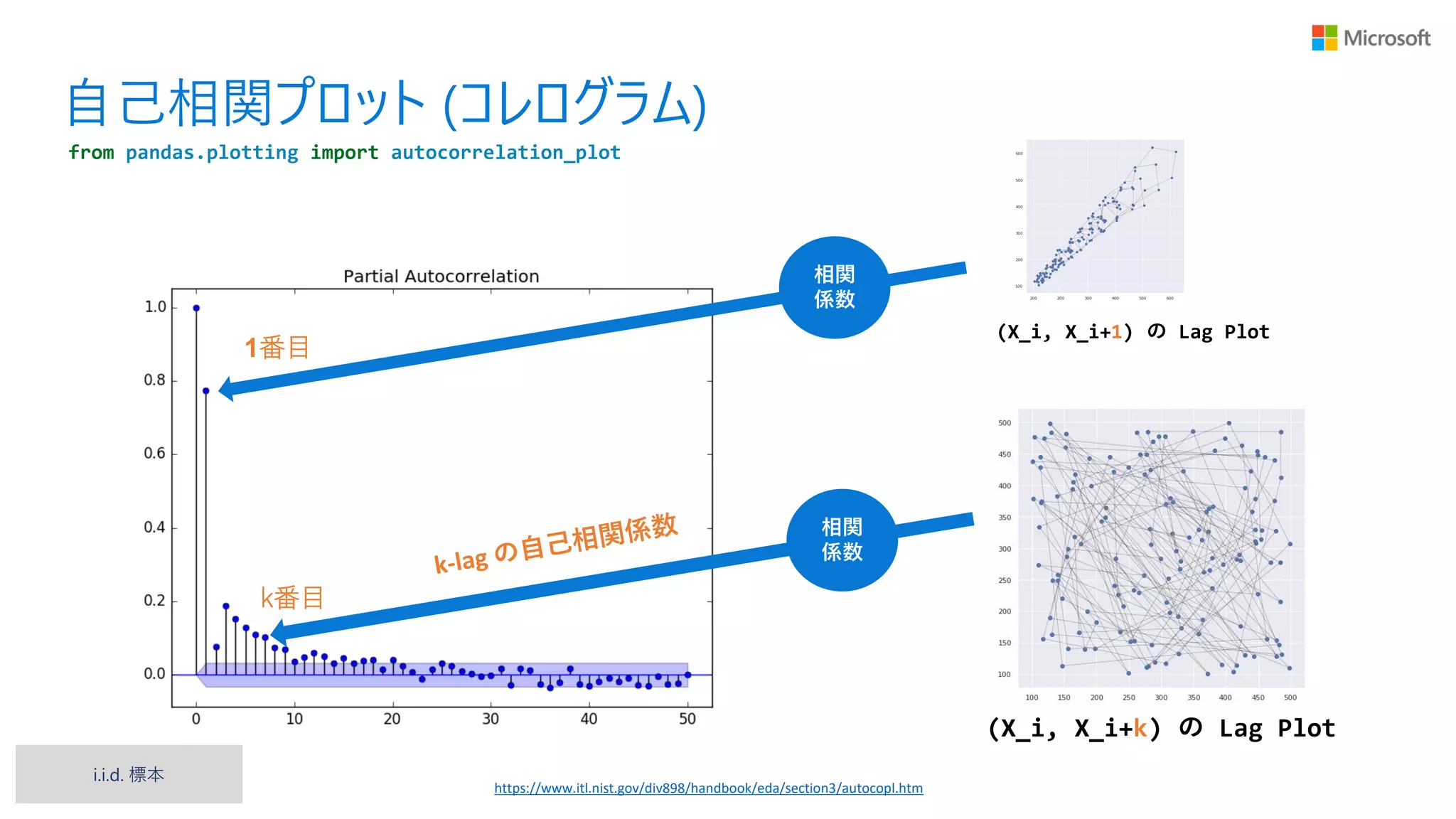
21.
自己相関プロット (コレログラム) from pandas.plotting
import autocorrelation_plot 相関 係数 (X_i, X_i+1) の Lag Plot 相関 係数 1番目 k番目 (X_i, X_i+k) の Lag Plot https://www.itl.nist.gov/div898/handbook/eda/section3/autocopl.htm i.i.d. 標本
22.
GLM での Assumptions i.i.d.
標本 誤差の正しいモデル化 分散の正しいモデル化 特徴量同士の相関が小さい How to check Bad Cases • とりあえず正規分布 • 上限のあるカウントデータにポアソン分布を利用 • Q-Q (quantile-quantile) Plot Examples • 体重の誤差構造を正規分布で表現 • 売上データをポアソン分布で表現
23.
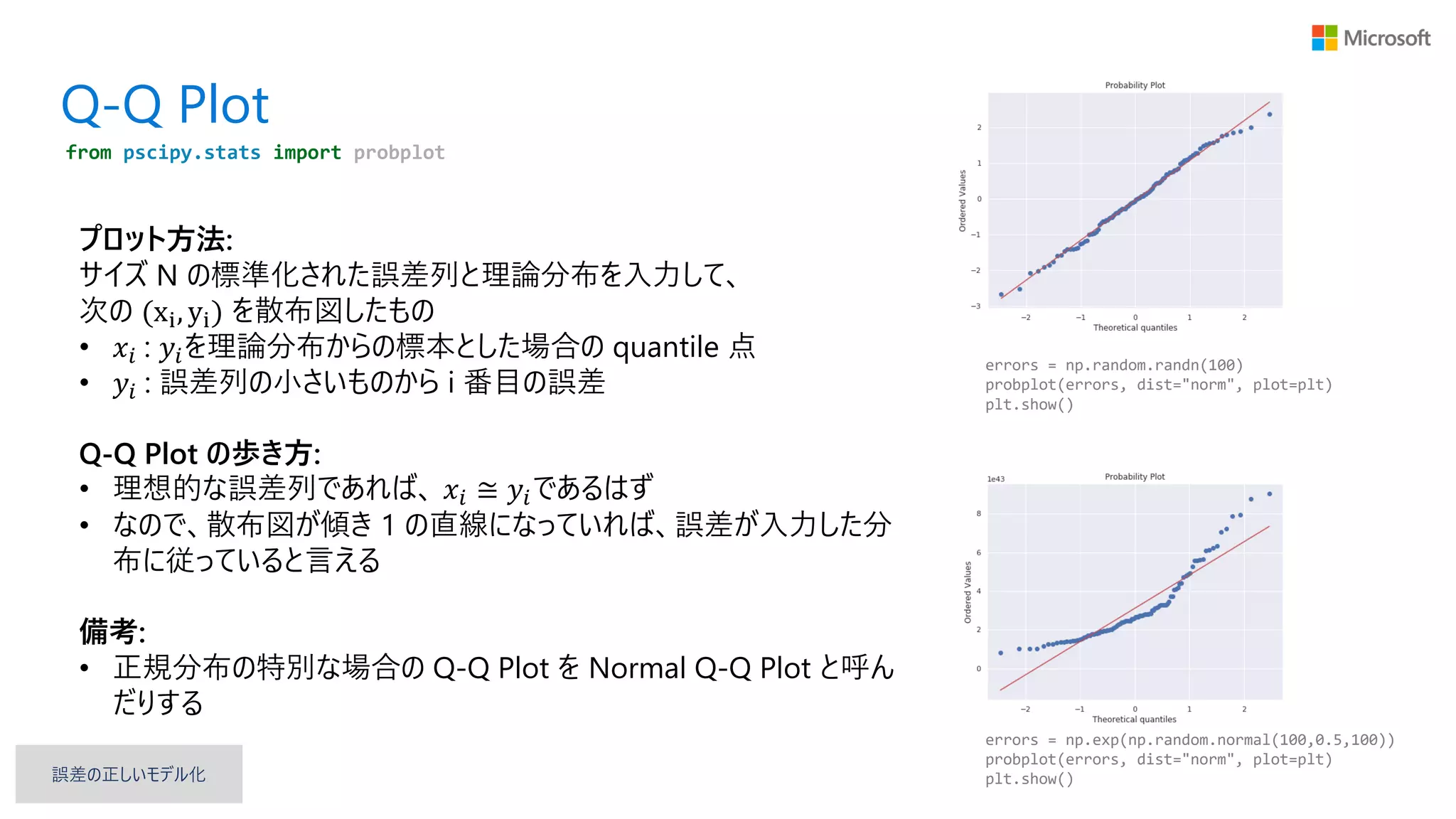
Q-Q Plot プロット方法: サイズ N
の標準化された誤差列と理論分布を入力して、 次の (xi, yi) を散布図したもの • 𝑥𝑖 : 𝑦𝑖を理論分布からの標本とした場合の quantile 点 • 𝑦𝑖 : 誤差列の小さいものから i 番目の誤差 Q-Q Plot の歩き方: • 理想的な誤差列であれば、 𝑥𝑖 ≅ 𝑦𝑖であるはず • なので、散布図が傾き 1 の直線になっていれば、誤差が入力した分 布に従っていると言える 備考: • 正規分布の特別な場合の Q-Q Plot を Normal Q-Q Plot と呼ん だりする from pscipy.stats import probplot errors = np.random.randn(100) probplot(errors, dist="norm", plot=plt) plt.show() errors = np.exp(np.random.normal(100,0.5,100)) probplot(errors, dist="norm", plot=plt) plt.show()誤差の正しいモデル化
24.
GLM での Assumptions i.i.d.
標本 誤差の正しいモデル化 分散の正しいモデル化 特徴量同士の相関が小さい How to check Bad Cases • 価格が高いほど分散が増加する家の価格を、正規分布でモ デリング • 残差プロット (residual plot) Examples • 分散一定のデータを正規分布でモデリング • 分散が期待値の大きさと同じデータをポアソン分布でモデ リング
25.
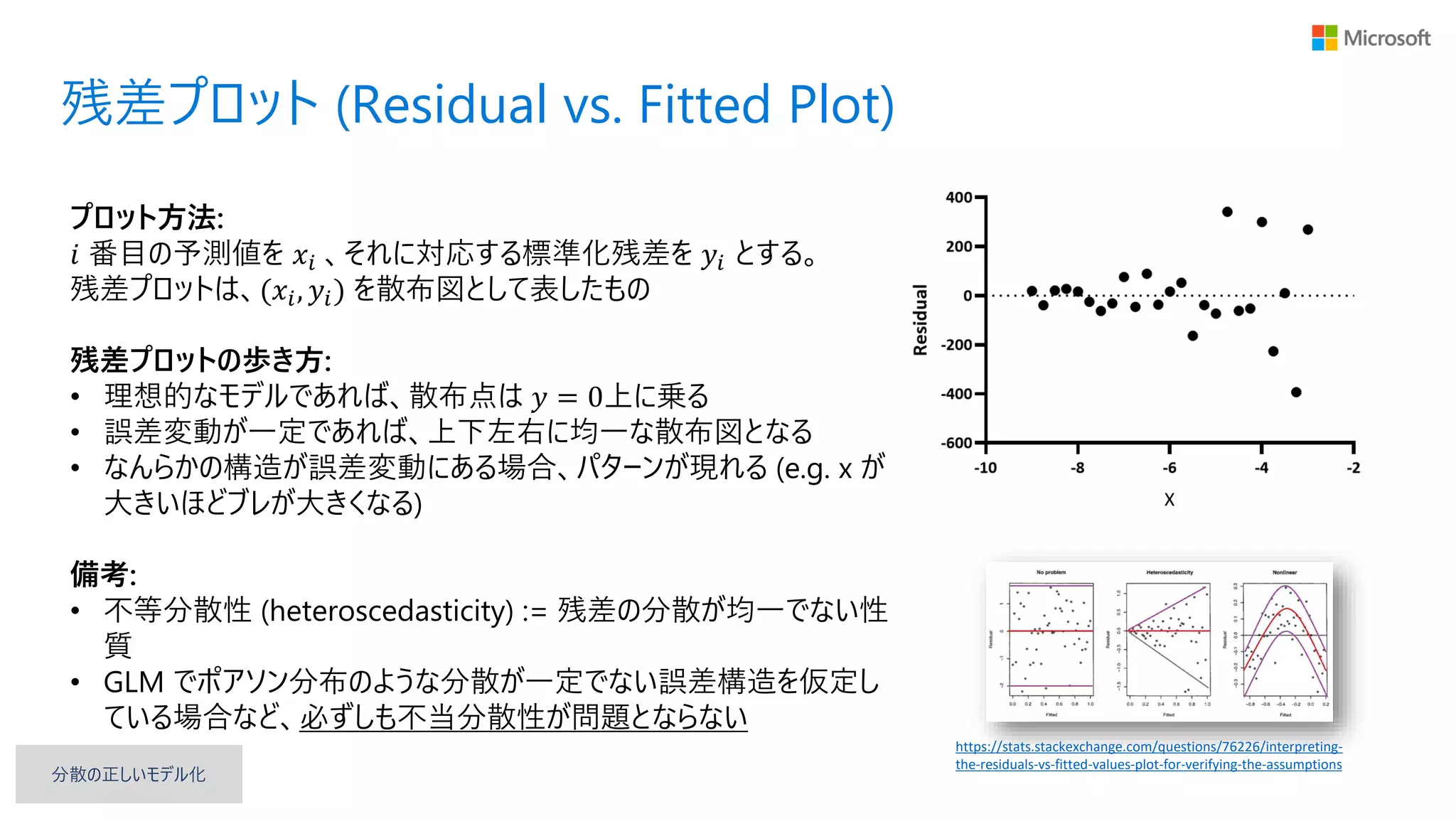
残差プロット (Residual vs.
Fitted Plot) プロット方法: 𝑖 番目の予測値を 𝑥𝑖 、それに対応する標準化残差を 𝑦𝑖 とする。 残差プロットは、(𝑥𝑖, 𝑦𝑖) を散布図として表したもの 残差プロットの歩き方: • 理想的なモデルであれば、散布点は 𝑦 = 0上に乗る • 誤差変動が一定であれば、上下左右に均一な散布図となる • なんらかの構造が誤差変動にある場合、パターンが現れる (e.g. x が 大きいほどブレが大きくなる) 備考: • 不等分散性 (heteroscedasticity) := 残差の分散が均一でない性 質 • GLM でポアソン分布のような分散が一定でない誤差構造を仮定し ている場合など、必ずしも不当分散性が問題とならない https://stats.stackexchange.com/questions/76226/interpreting- the-residuals-vs-fitted-values-plot-for-verifying-the-assumptions 分散の正しいモデル化
26.
GLM での Assumptions i.i.d.
標本 誤差の正しいモデル化 分散の正しいモデル化 特徴量同士の相関が小さい How to check Bad Cases • 目的変数:レンタルサイクルの一日のレンタル数 [count] • 特徴量:天気、傘の売上数、湿度 • 相関係数 • 分散拡大要因 (Variance Inflation Factor; VIF) • 相関行列の条件数 • etc Examples • 目的変数:ある日に筋トレをしたか? [binary] • 特徴量:体調の良さ、仕事の量
27.
• 説明変数間の相関が高く、線形モデルの学習が不安定となる状態を多重 共線性 (multicollinearity)
という • 多重共線性が存在すると? • 回帰係数の標準偏差 (推定のばらつき) が増加 • 推定の度に結果が大きく変わったり、そもそも推定アルゴリズムが収束しなかったり、結 果が信頼できなかったり・・・ • 多重共線性の主な検出方法 • 分散拡大要因 (VIF) • 閾値として 5 や 10 が使われ、それ以上の値の VIF が存在する場合は危険なサイン • 相関行列の条件数 • ノートルダム大学 R. William 先生のノート (www3.nd.edu/~rwilliam/stats2/l11.pdf) や 英語版の Wikipedia が役に立つ 多重共線性 (まるちこ) の検出 O’Brien, R. M. (2007). "A Caution Regarding Rules of Thumb for Variance Inflation Factors".
28.
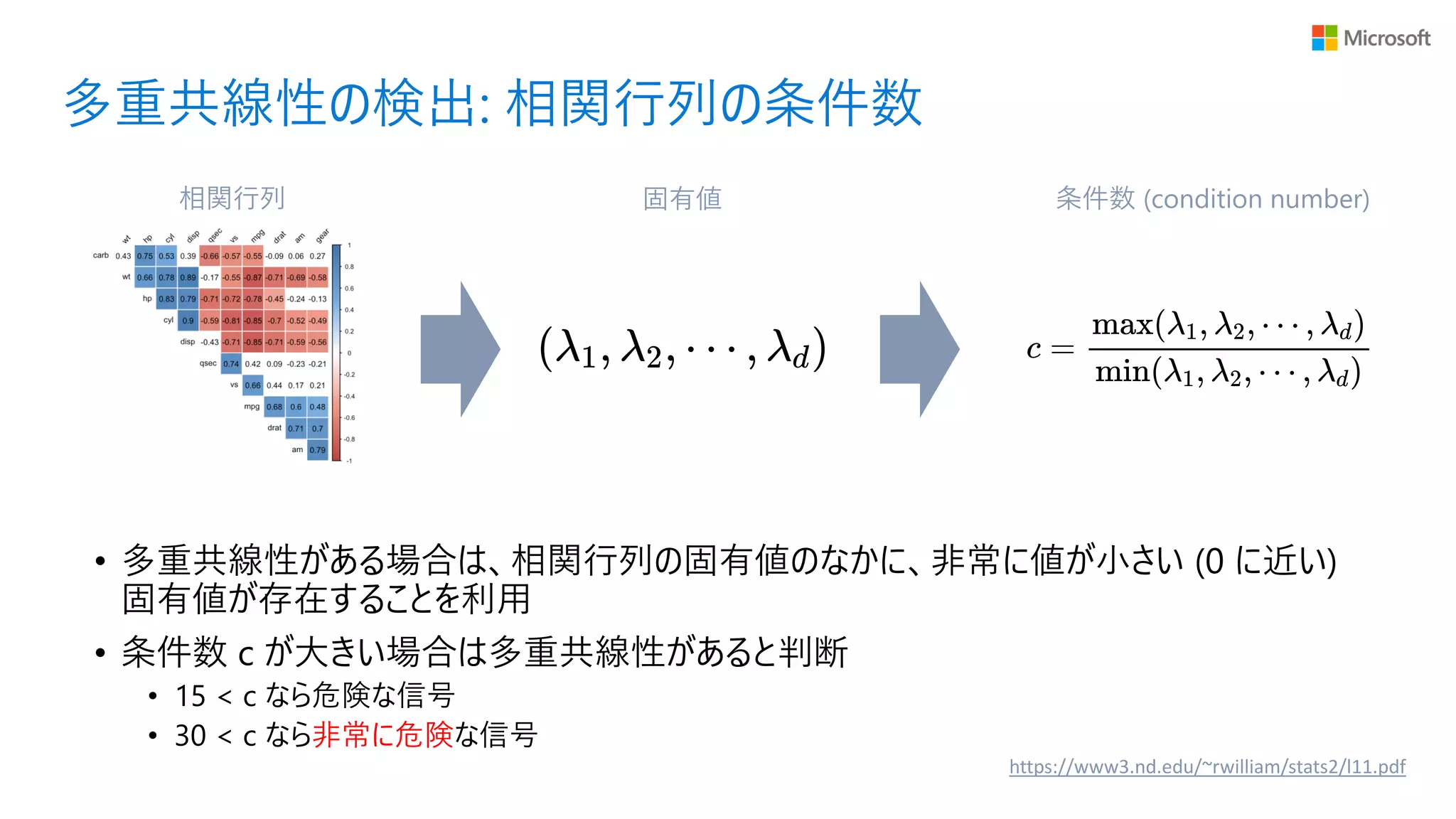
多重共線性の検出: 相関行列の条件数 条件数 (condition
number)相関行列 固有値 • 多重共線性がある場合は、相関行列の固有値のなかに、非常に値が小さい (0 に近い) 固有値が存在することを利用 • 条件数 c が大きい場合は多重共線性があると判断 • 15 < c なら危険な信号 • 30 < c なら非常に危険な信号 https://www3.nd.edu/~rwilliam/stats2/l11.pdf
29.
GLM での Assumptions i.i.d.
標本 誤差の正しいモデル化 分散の正しいモデル化 特徴量同士の相関が小さい • 自己相関グラフ, Lag プロット • Permutation tests, カイ二乗検定 • Q-Q プロット (quantile-quantile plot) • 残差プロット (residual plot) • 相関係数 • 分散拡大要因 (Variance Inflation Factor; VIF) • 相関行列の条件数 • etc
30.
Generalized Additive Models
31.
歴史 Nelder と Wedderburn
によって、様々な統計モデルを統合的する目的で GLM が定式化 1972 1982 McCullagh & Nelder による最初の GLM の教科書 “Generalized Linear Models” 線形回帰, ポアソン回帰, ロジスティック回帰, … ⇒ GLM Dobson, A. J. “An Introduction to Generalized Linear Models”1990 2nd Edition は 2004 年, 3rd Edition は 2008 年 2nd Edition は 1989 年 GLM をさらに発展させた GAM が提案1990
32.
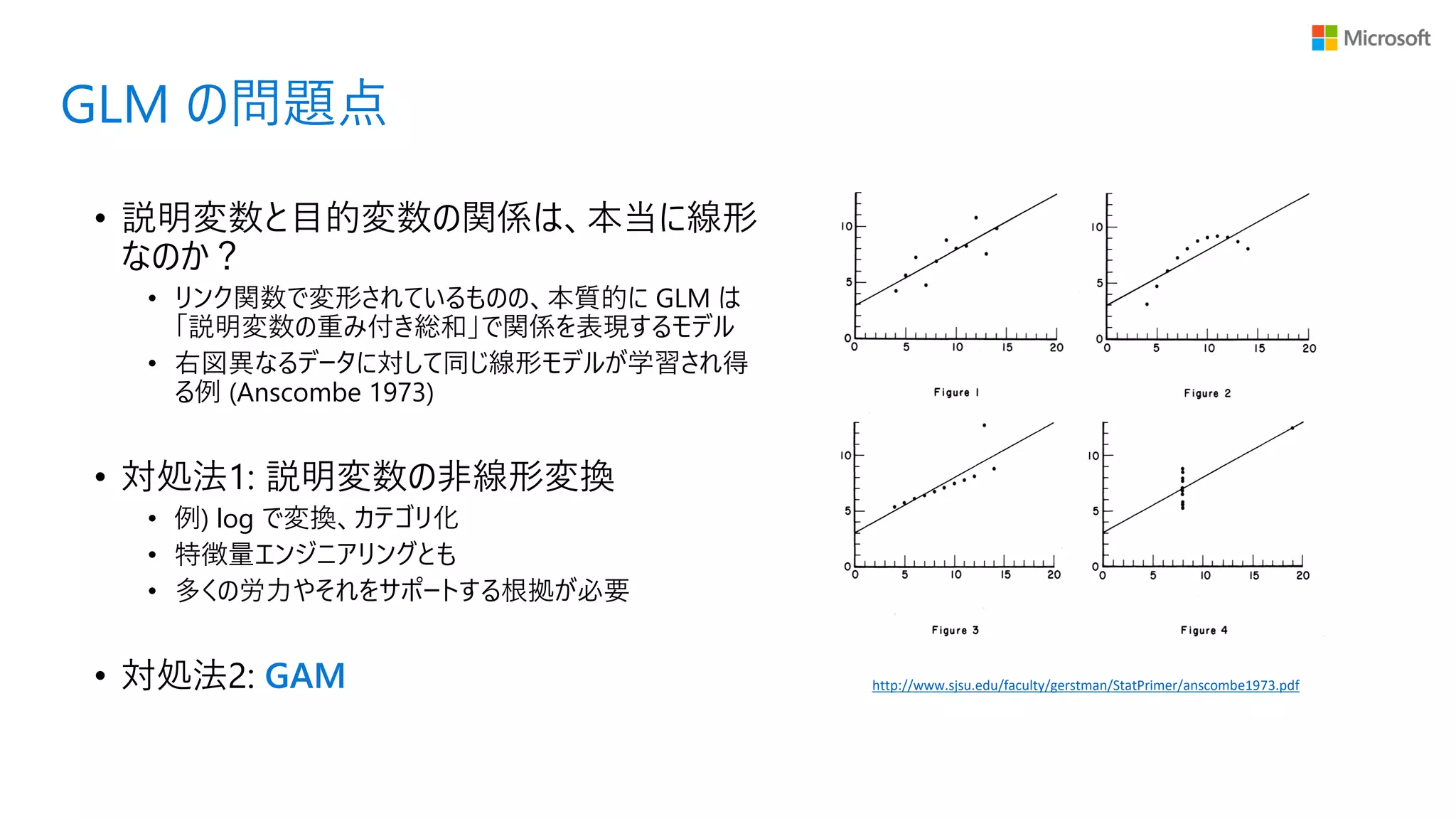
GLM の問題点 • 説明変数と目的変数の関係は、本当に線形 なのか? •
リンク関数で変形されているものの、本質的に GLM は 「説明変数の重み付き総和」で関係を表現するモデル • 右図異なるデータに対して同じ線形モデルが学習され得 る例 (Anscombe 1973) • 対処法1: 説明変数の非線形変換 • 例) log で変換、カテゴリ化 • 特徴量エンジニアリングとも • 多くの労力やそれをサポートする根拠が必要 • 対処法2: GAM http://www.sjsu.edu/faculty/gerstman/StatPrimer/anscombe1973.pdf
33.
Generalized Linear Model •
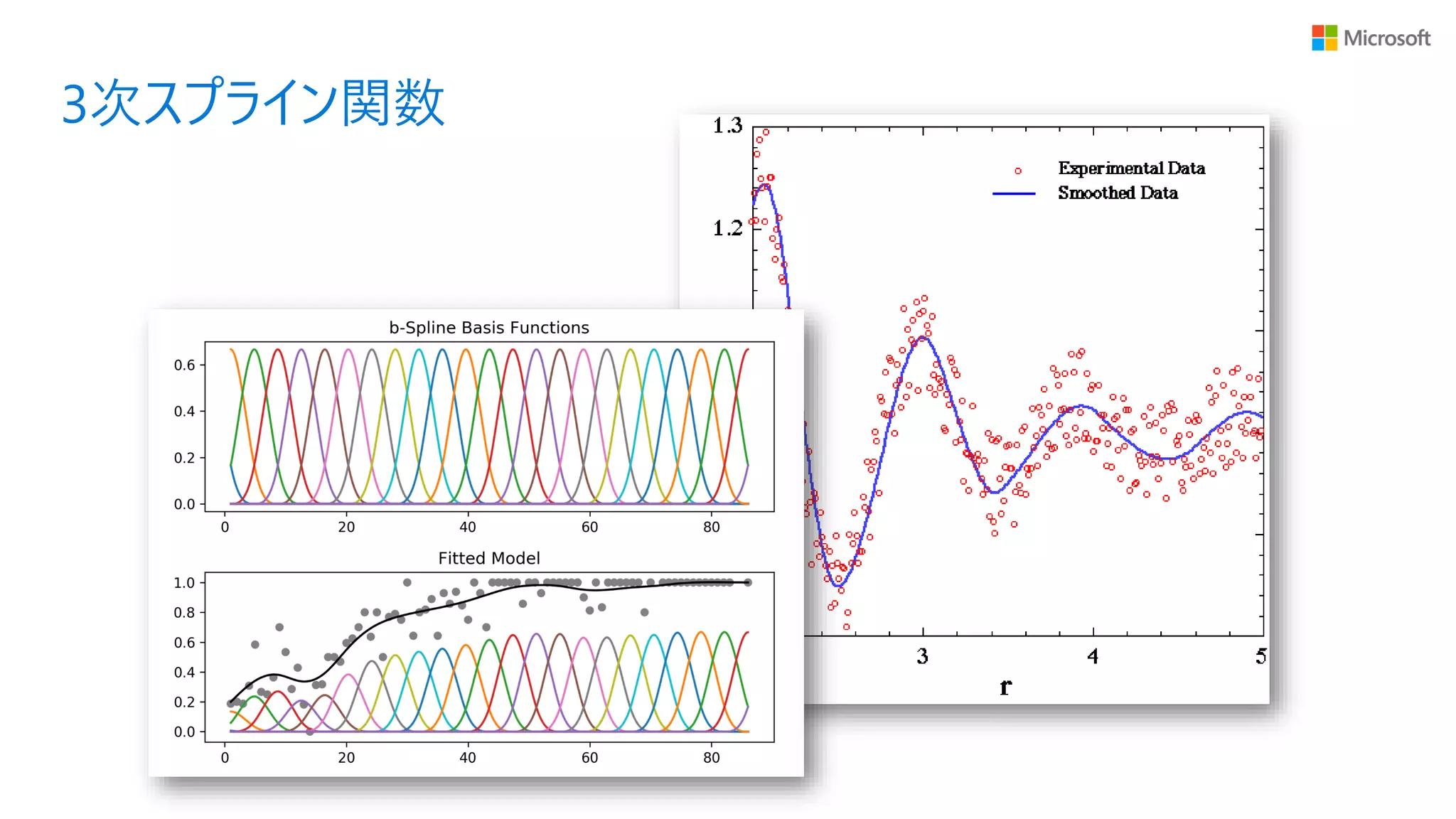
一般化加法モデル (Generalized Additive Model; GAM) は、1990 年 に Hastie と Tibshirani によって提案された統計モデル • GLM の線形和という制約を緩和 • より柔軟な曲線 (3 次スプライン関数) で各変数の期待値への寄与を計算する
34.
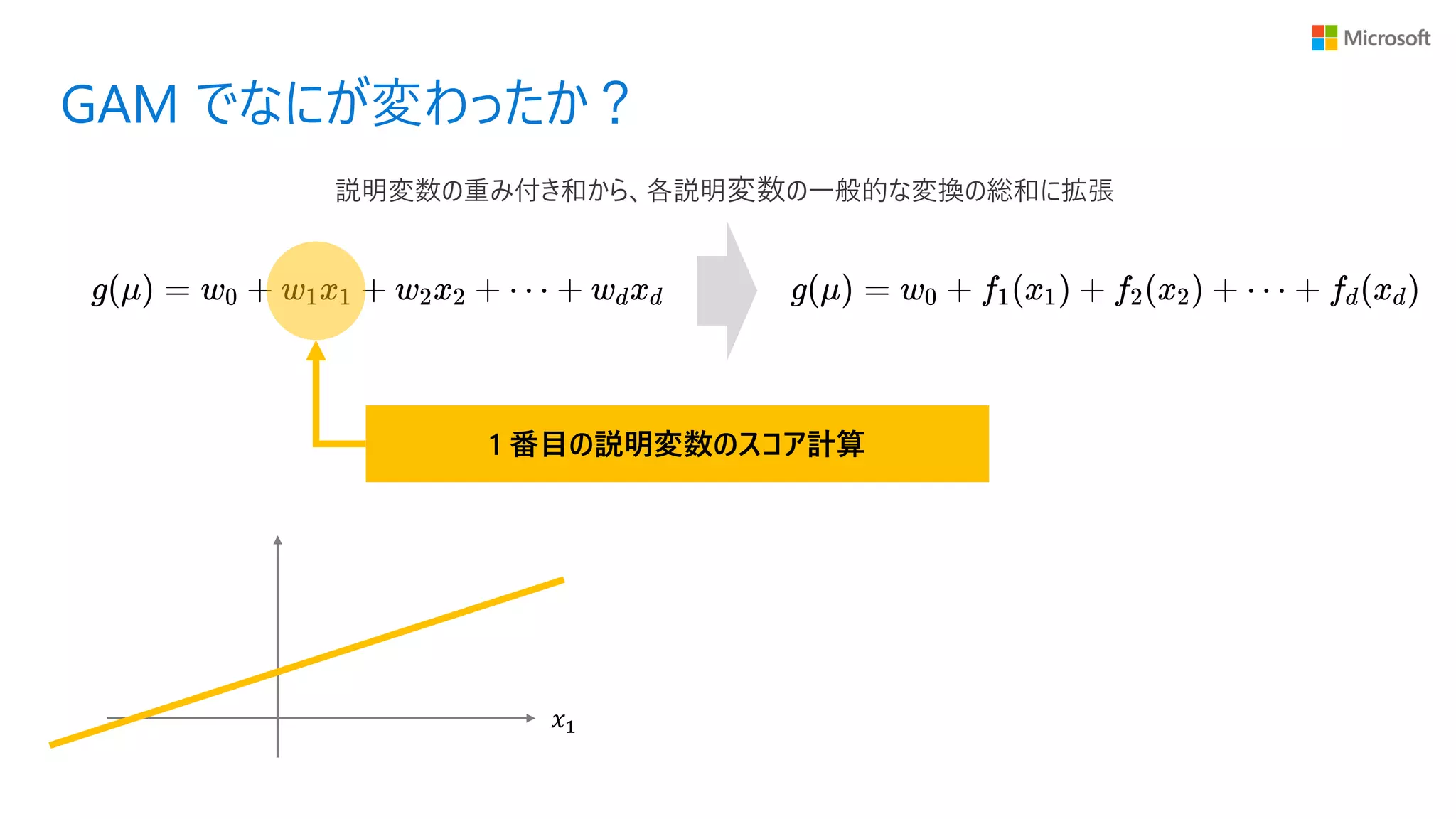
GAM でなにが変わったか? 説明変数の重み付き和から、各説明変数の一般的な変換の総和に拡張
35.
GAM でなにが変わったか? 1 番目の説明変数のスコア計算 𝑥1 説明変数の重み付き和から、各説明変数の一般的な変換の総和に拡張
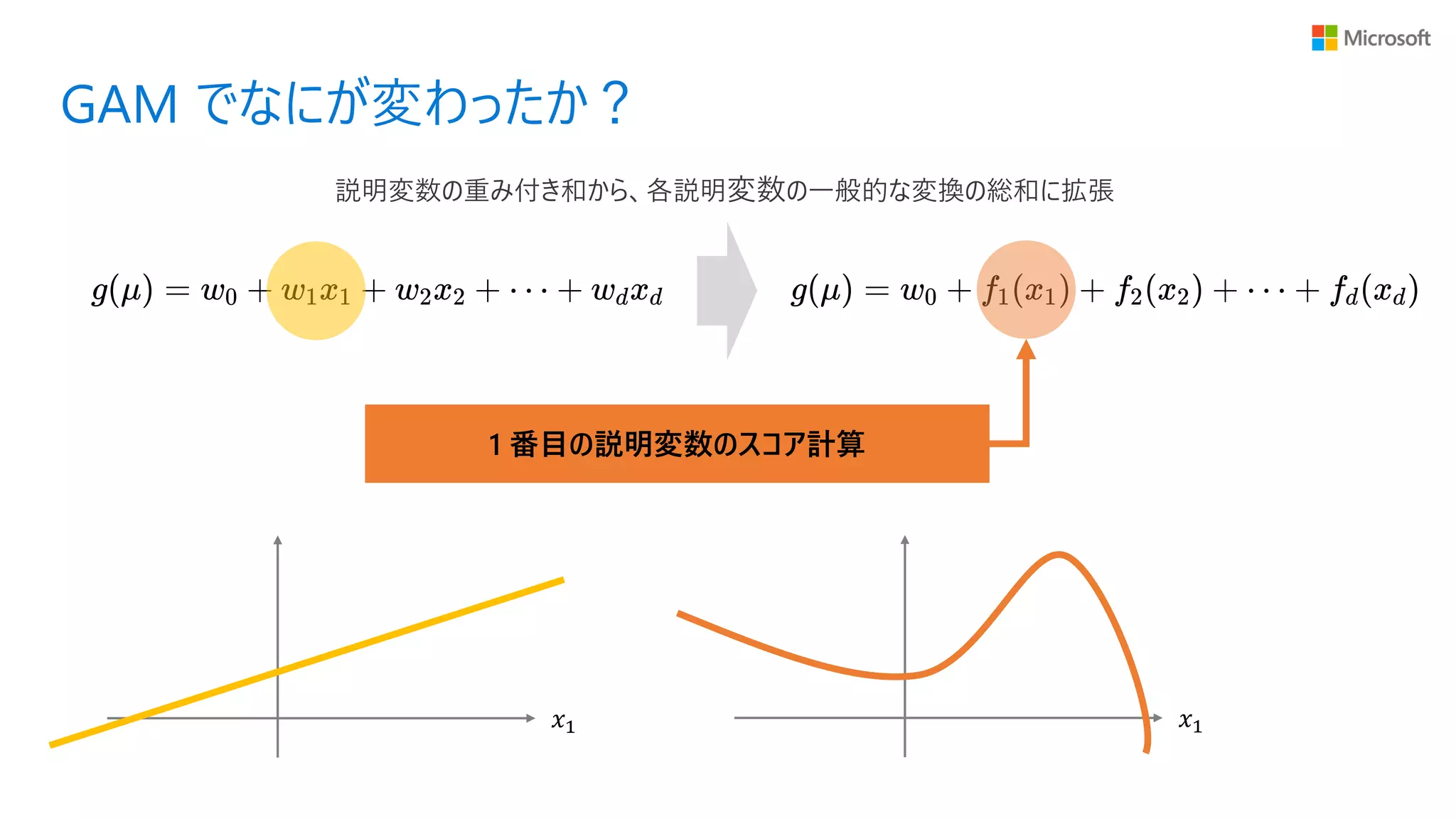
36.
GAM でなにが変わったか? 1 番目の説明変数のスコア計算 𝑥1
𝑥1 説明変数の重み付き和から、各説明変数の一般的な変換の総和に拡張
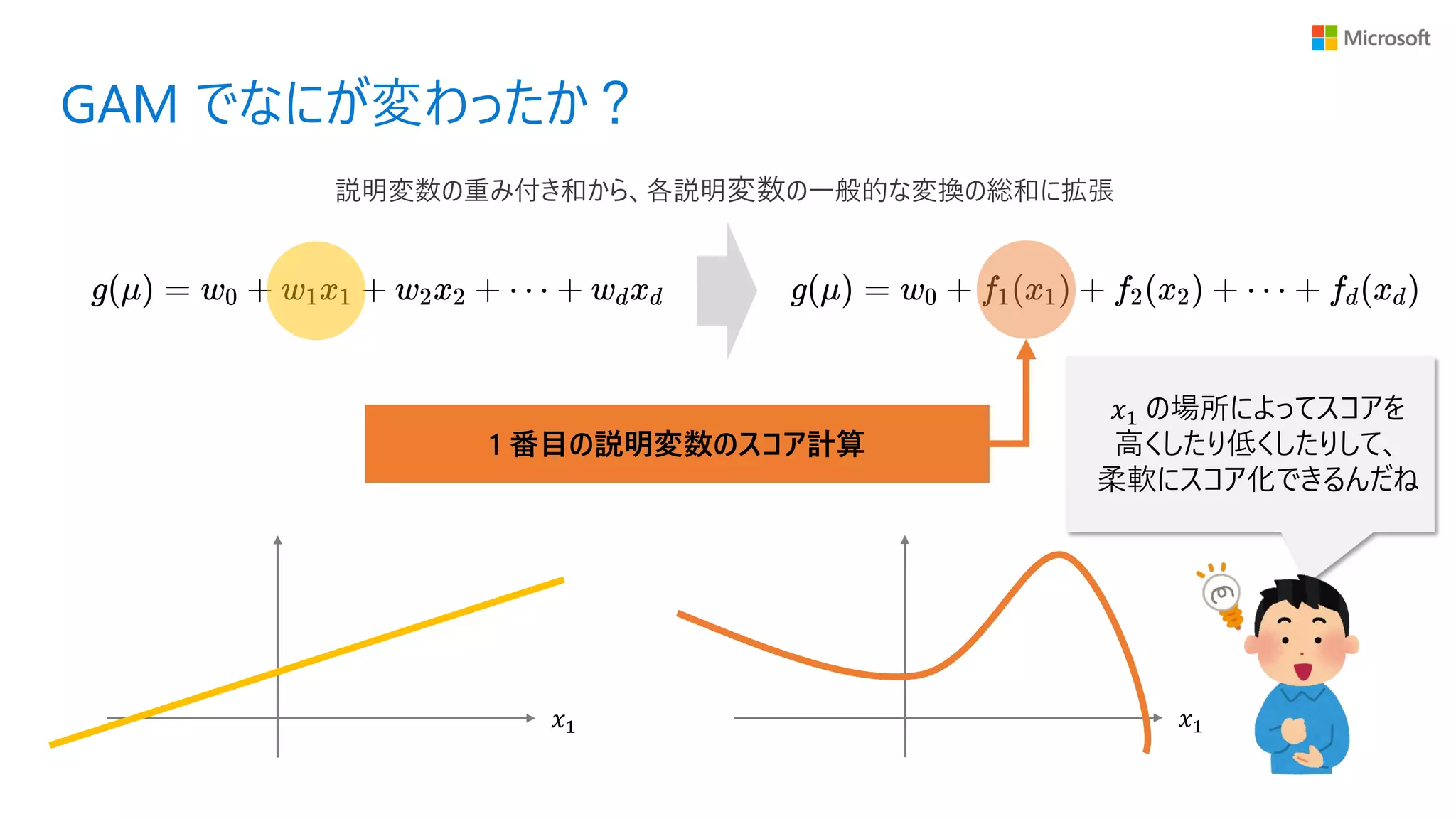
37.
GAM でなにが変わったか? 1 番目の説明変数のスコア計算 𝑥1
𝑥1 𝑥1 の場所によってスコアを 高くしたり低くしたりして、 柔軟にスコア化できるんだね 説明変数の重み付き和から、各説明変数の一般的な変換の総和に拡張
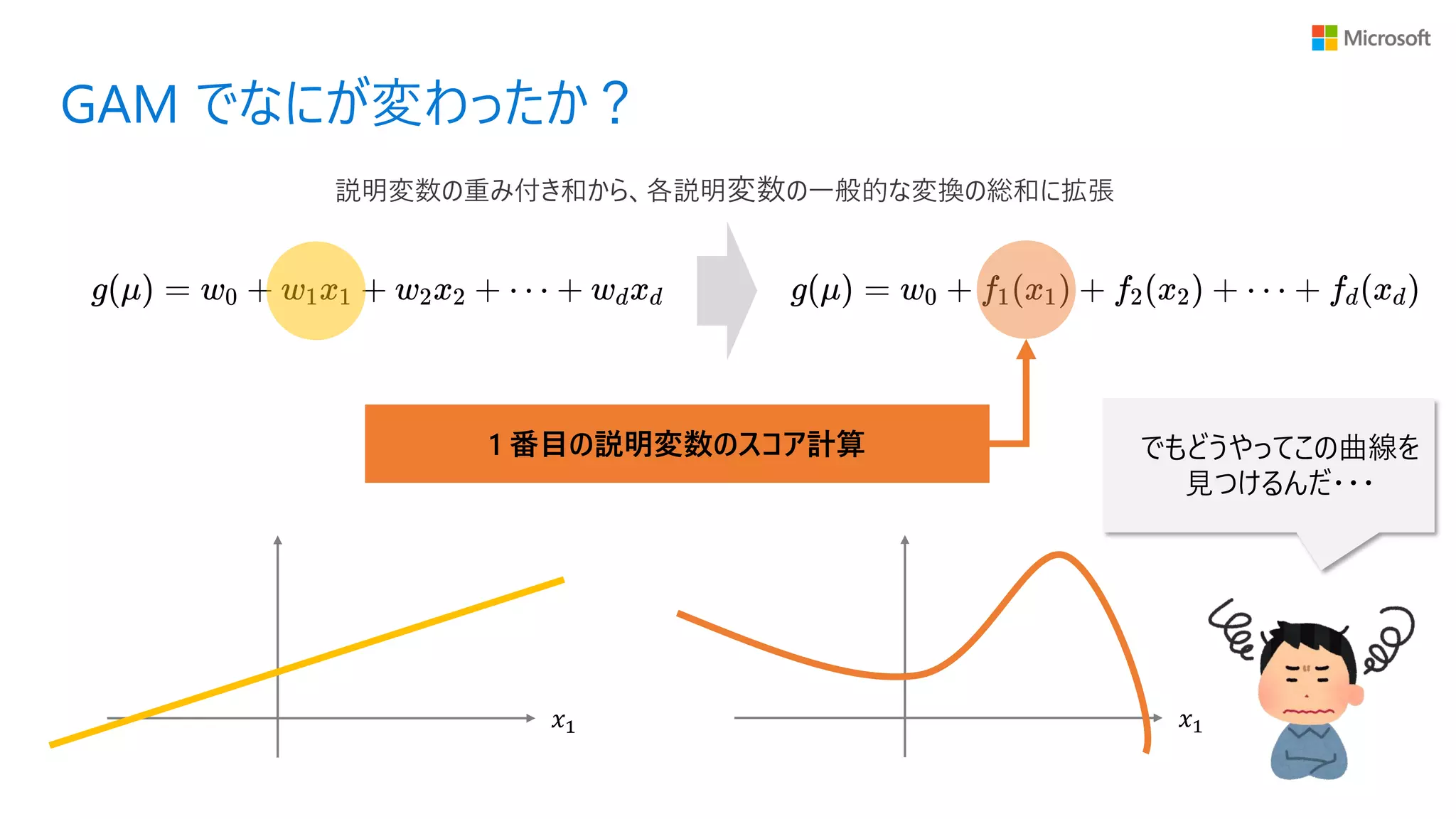
38.
GAM でなにが変わったか? 1 番目の説明変数のスコア計算 𝑥1
𝑥1 説明変数の重み付き和から、各説明変数の一般的な変換の総和に拡張 でもどうやってこの曲線を 見つけるんだ・・・
39.
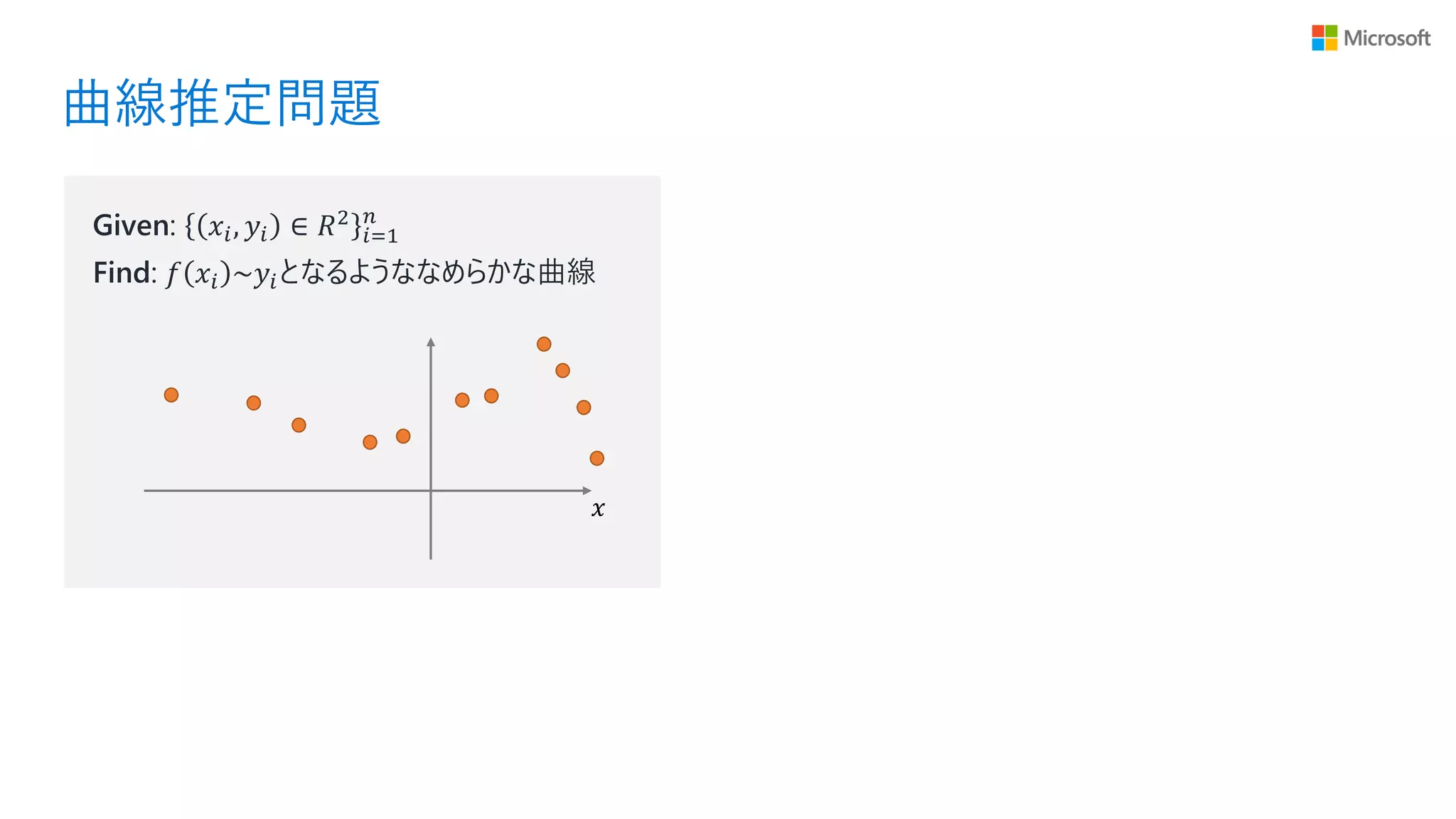
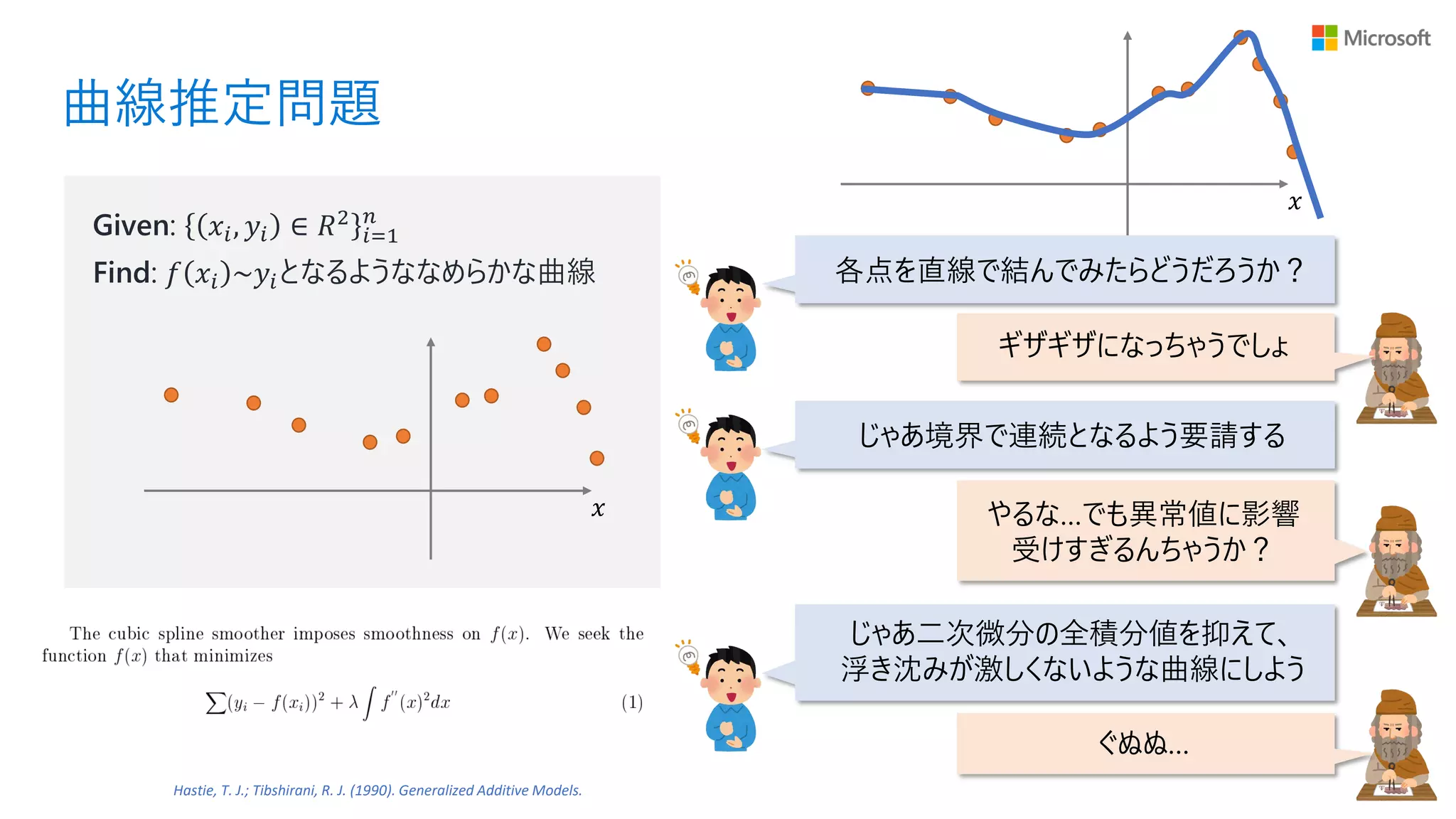
曲線推定問題 𝑥 Given: 𝑥𝑖, 𝑦𝑖
∈ 𝑅2 𝑖=1 𝑛 Find: 𝑓 𝑥𝑖 ~𝑦𝑖となるようななめらかな曲線
40.
曲線推定問題: 移動指数平均
41.
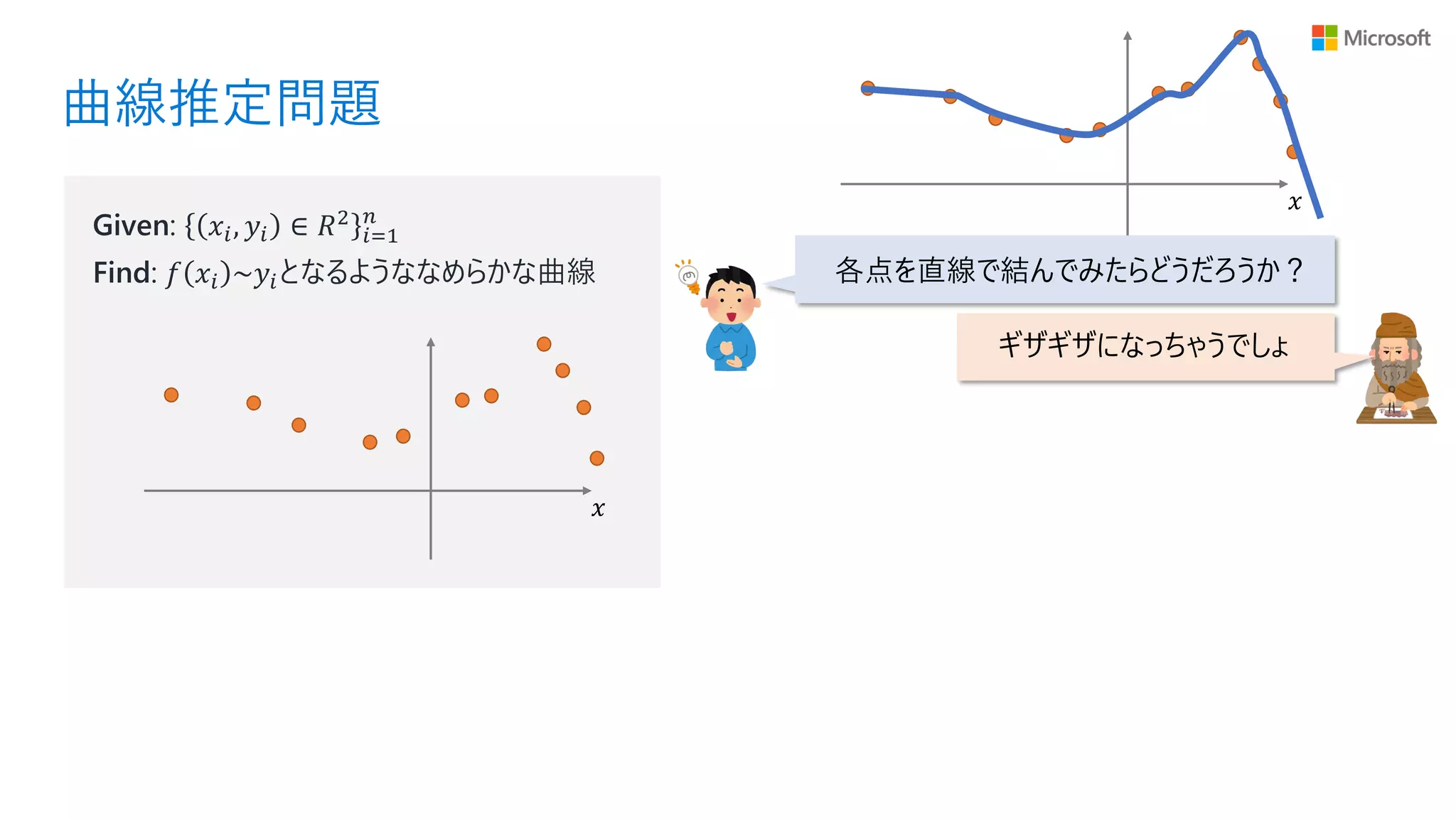
曲線推定問題 𝑥 Given: 𝑥𝑖, 𝑦𝑖
∈ 𝑅2 𝑖=1 𝑛 Find: 𝑓 𝑥𝑖 ~𝑦𝑖となるようななめらかな曲線 𝑥 各点を直線で結んでみたらどうだろうか? ギザギザになっちゃうでしょ
42.
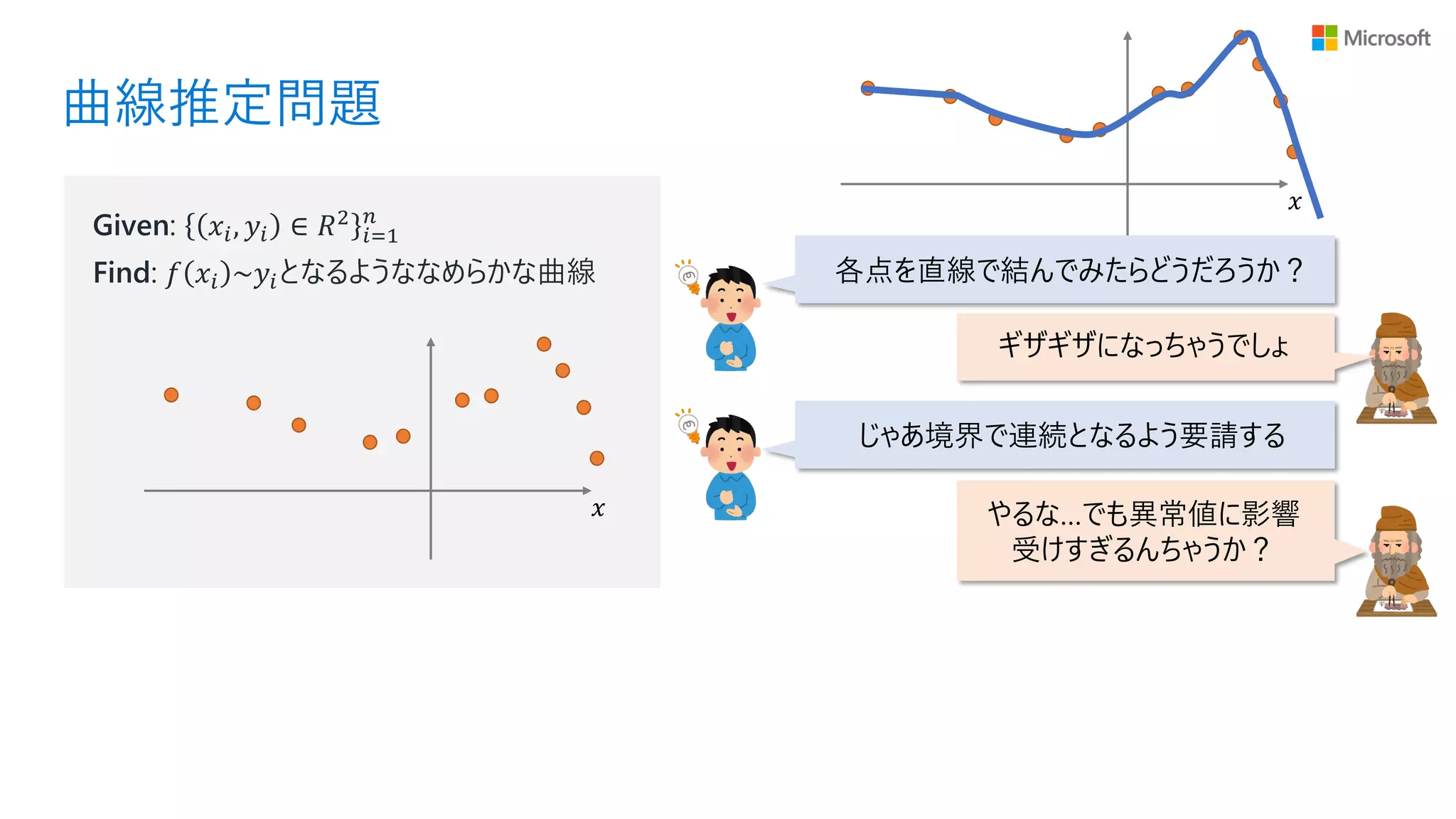
曲線推定問題 𝑥 Given: 𝑥𝑖, 𝑦𝑖
∈ 𝑅2 𝑖=1 𝑛 Find: 𝑓 𝑥𝑖 ~𝑦𝑖となるようななめらかな曲線 𝑥 各点を直線で結んでみたらどうだろうか? ギザギザになっちゃうでしょ じゃあ境界で連続となるよう要請する やるな…でも異常値に影響 受けすぎるんちゃうか?
43.
曲線推定問題 𝑥 Given: 𝑥𝑖, 𝑦𝑖
∈ 𝑅2 𝑖=1 𝑛 Find: 𝑓 𝑥𝑖 ~𝑦𝑖となるようななめらかな曲線 𝑥 各点を直線で結んでみたらどうだろうか? ギザギザになっちゃうでしょ じゃあ境界で連続となるよう要請する やるな…でも異常値に影響 受けすぎるんちゃうか? ぐぬぬ… じゃあ二次微分の全積分値を抑えて、 浮き沈みが激しくないような曲線にしよう Hastie, T. J.; Tibshirani, R. J. (1990). Generalized Additive Models.
44.
3次スプライン関数
45.
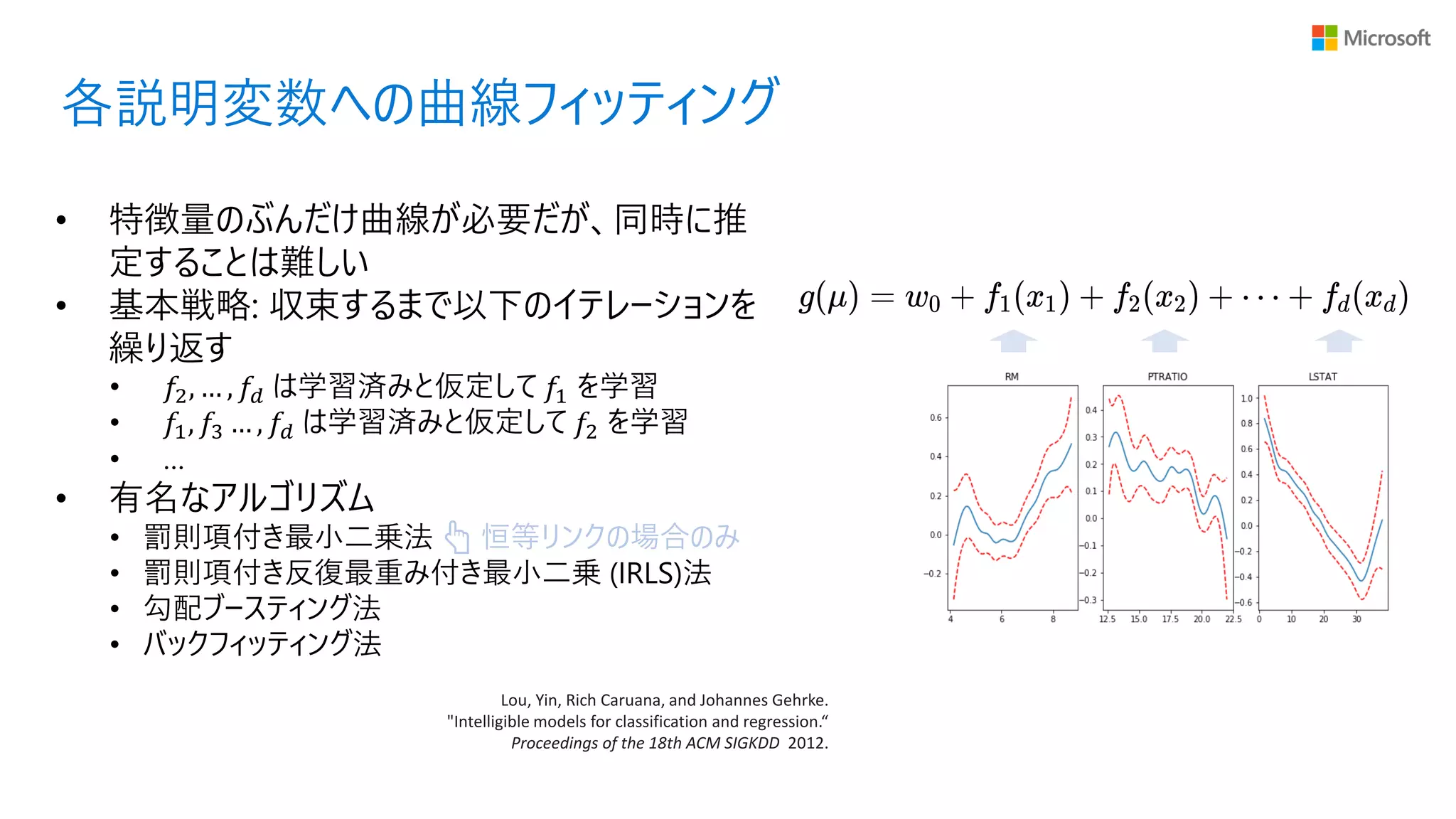
各説明変数への曲線フィッティング Lou, Yin, Rich
Caruana, and Johannes Gehrke. "Intelligible models for classification and regression.“ Proceedings of the 18th ACM SIGKDD 2012. • 特徴量のぶんだけ曲線が必要だが、同時に推 定することは難しい • 基本戦略: 収束するまで以下のイテレーションを 繰り返す • 𝑓2, … , 𝑓𝑑 は学習済みと仮定して 𝑓1 を学習 • 𝑓1, 𝑓3 … , 𝑓𝑑 は学習済みと仮定して 𝑓2 を学習 • … • 有名なアルゴリズム • 罰則項付き最小二乗法 👆 恒等リンクの場合のみ • 罰則項付き反復最重み付き最小二乗 (IRLS)法 • 勾配ブースティング法 • バックフィッティング法
46.
Generalized Linear Model
(まとめ) • 一般化加法モデル (Generalized Additive Model; GAM) は、1990 年に Hastie と Tibshirani によって提案された統計モデル • GLM の線形和という制約を緩和 • より柔軟な曲線 (3 次スプライン関数) で各変数の期待値への寄与を計算する • 反復的なアルゴリズムによって同時に複数のスプライン関数を推定する
47.
GLM と GAM
のパッケージ
48.
pip install pygam
49.
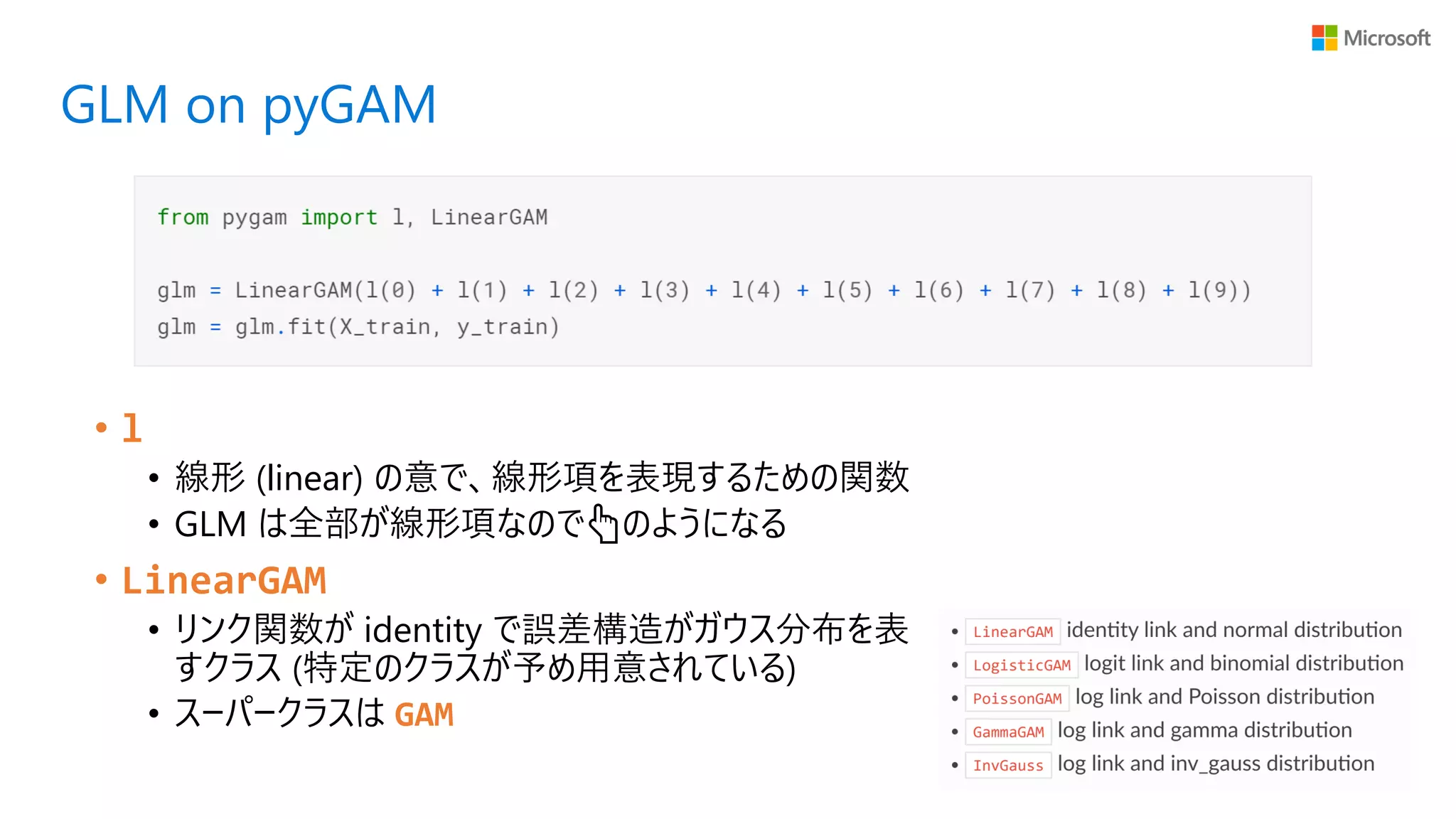
GLM on pyGAM •
l • 線形 (linear) の意で、線形項を表現するための関数 • GLM は全部が線形項なので👆のようになる • LinearGAM • リンク関数が identity で誤差構造がガウス分布を表 すクラス (特定のクラスが予め用意されている) • スーパークラスは GAM
50.
GAM on pyGAM •
s • スプライン (spline) の意で、3次スプライン関数を表す 関数 • 基本形はすべて s だが、l をまぜたりしても良い • LinearGAM • リンク関数が identity で誤差構造がガウス分布
51.
• LinearGAM 内部で項を表現するために指定できる関数は
4 種類 • l(i):線形項 • s(i):スプライン項 • f(i):因子項 (カテゴリカル変数) • te(i,j):テンソル項 (相互作用項) • 例 Functional Form
52.
GA2M
53.
歴史 Nelder と Wedderburn
によって、様々な統計モデルを統合的する目的で GLM が定式化 1972 1982 McCullagh & Nelder による最初の GLM の教科書 “Generalized Linear Models” 線形回帰, ポアソン回帰, ロジスティック回帰, … ⇒ GLM Dobson, A. J. “An Introduction to Generalized Linear Models”1990 2nd Edition は 2004 年, 3rd Edition は 2008 年 2nd Edition は 1989 年 GLM をさらに発展させた GAM が提案1990 MSR の Lou Yin らが GAM に相互作用項を加えたモデル GA2M を提案2013
54.
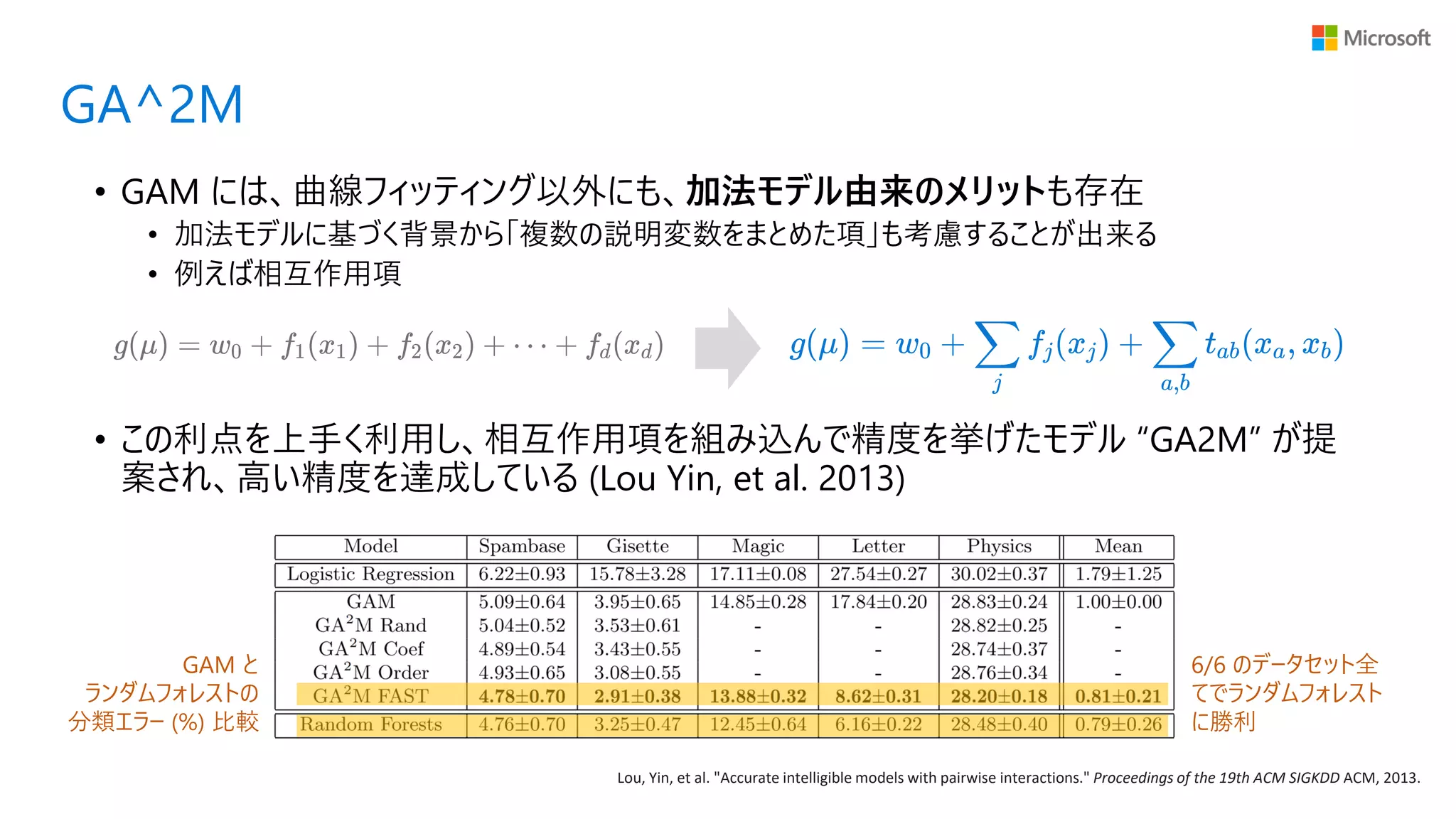
GA^2M • GAM には、曲線フィッティング以外にも、加法モデル由来のメリットも存在 •
加法モデルに基づく背景から「複数の説明変数をまとめた項」も考慮することが出来る • 例えば相互作用項 • この利点を上手く利用し、相互作用項を組み込んで精度を挙げたモデル “GA2M” が提 案され、高い精度を達成している (Lou Yin, et al. 2013) Lou, Yin, et al. "Accurate intelligible models with pairwise interactions." Proceedings of the 19th ACM SIGKDD ACM, 2013. GAM と ランダムフォレストの 分類エラー (%) 比較 6/6 のデータセット全 てでランダムフォレスト に勝利
55.
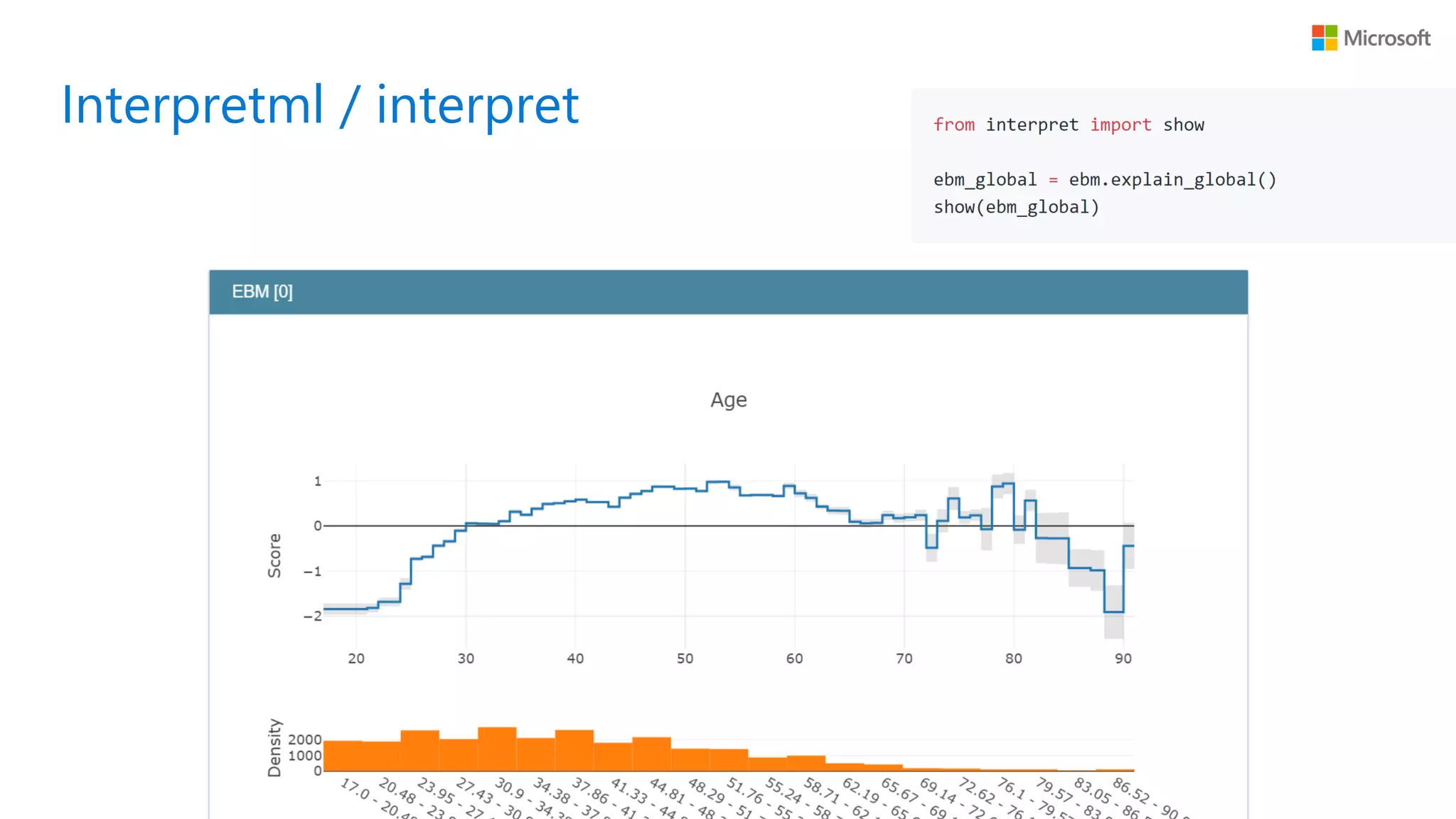
Interpretml / interpret
56.
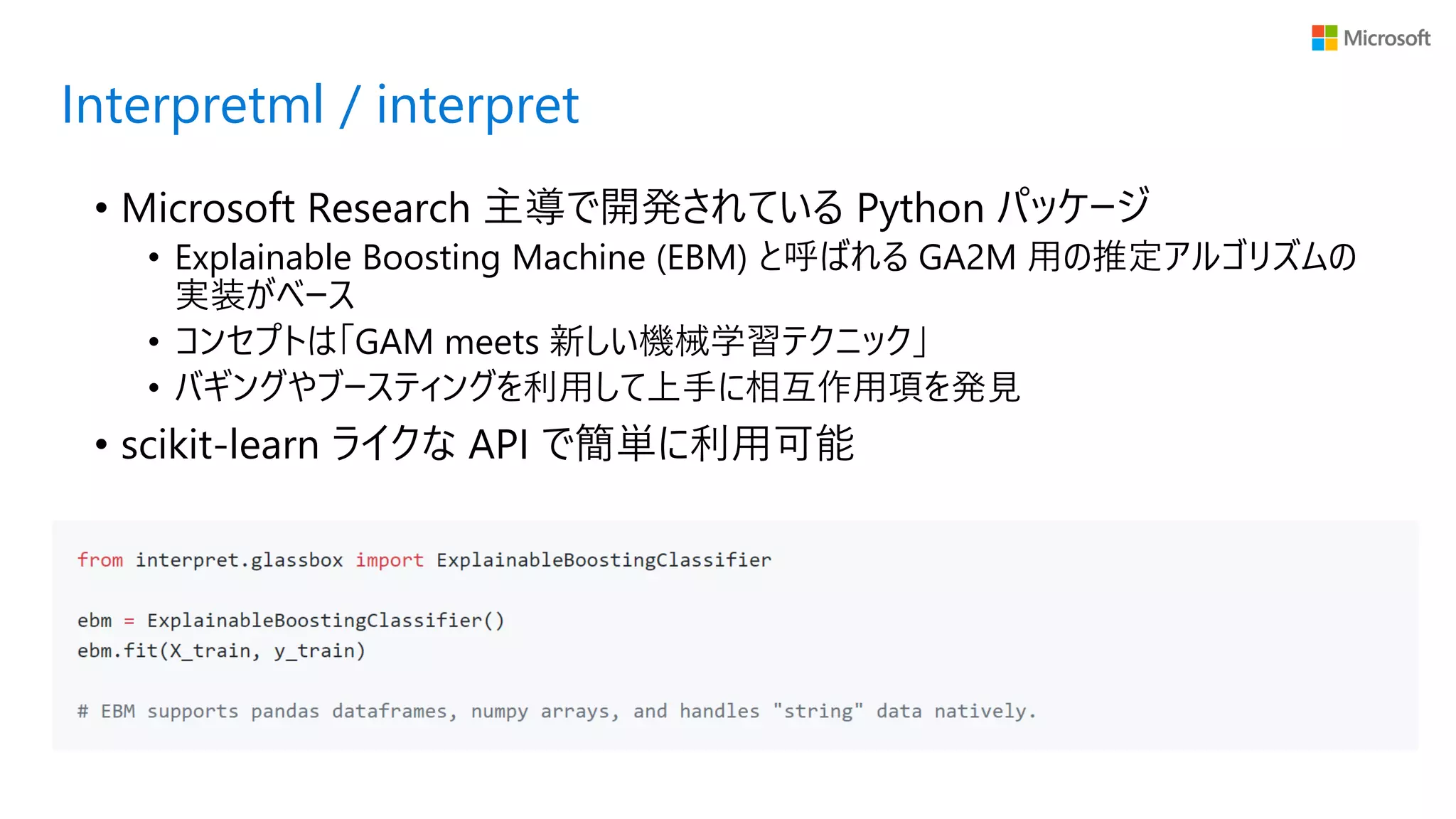
• Microsoft Research
主導で開発されている Python パッケージ • Explainable Boosting Machine (EBM) と呼ばれる GA2M 用の推定アルゴリズムの 実装がベース • コンセプトは「GAM meets 新しい機械学習テクニック」 • バギングやブースティングを利用して上手に相互作用項を発見 • scikit-learn ライクな API で簡単に利用可能 Interpretml / interpret
57.
Interpretml / interpret
58.
• https://www.kaggle.com/juyamagu/pga-tour-analysis-by-gam Demo
59.
まとめ
60.
• GLM/GAM/GA2M は自然に解釈可能な機械学習モデル •
GLM は自由に分布を設定してモデリングする土台を作った • 多重共線性等、データについて注意しなくてはいけないことがある • データを事前に検査したり、モデルの結果をみることが大事 • 各問題に関しては既知の検出方法があるので、システマチックに適用すれば良い • pyGAM で、簡単に Python で GLM と GAM のモデリングが可能 • さらに、相互作用項を上手く GAM に組み込んだ GA2M も近年登場 • ランダムフォレストを凌駕する性能を示すことも • interpretml/interpret から利用 まとめ GLM GAM GA2M
Download










![リンク関数の気持ち
• 線形和が取りうる値は、すべての実数
• つまり、マイナスの値にもなるし、ゼロになったりもする
• 目的変数 𝒚 の分布によっては、期待値 𝑬[𝒚] の範囲を制御したい
• 確率値 0 < 𝐸 𝑦 < 1 になって欲しいとき…
• 正の値 0 < 𝐸[𝑦] になって欲しいとき…
• そのためのリンク関数
• 逆関数が存在するなめらかな曲線である必要があるが、勝手に決めて良い
• ただ、一般的に用いられるリンク関数は大体決まっている
※ 期待値から指数型分布族の正準パラメータへの
写像でリンク関数を与えた時、
そのリンク関数を正準 (canonical) であるという。
0.7
0.9
0.1
-12
+56
-30](https://image.slidesharecdn.com/glmgam-191127114530/75/GLM-GAM-15-2048.jpg)





![GLM での Assumptions
i.i.d. 標本
誤差の正しいモデル化
分散の正しいモデル化
特徴量同士の相関が小さい
How to check
Bad Cases
• 目的変数:レンタルサイクルの一日のレンタル数 [count]
• 特徴量:天気、傘の売上数、湿度
• 相関係数
• 分散拡大要因 (Variance Inflation Factor; VIF)
• 相関行列の条件数
• etc
Examples
• 目的変数:ある日に筋トレをしたか? [binary]
• 特徴量:体調の良さ、仕事の量](https://image.slidesharecdn.com/glmgam-191127114530/75/GLM-GAM-26-2048.jpg)





























![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~](https://cdn.slidesharecdn.com/ss_thumbnails/3-2dllabconferencedaikinisid2020-07-20-2-200819034039-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測](https://cdn.slidesharecdn.com/ss_thumbnails/dldc20200801nssoltokutake-200819025900-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略](https://cdn.slidesharecdn.com/ss_thumbnails/datumstudiomitsuda-200819031400-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~](https://cdn.slidesharecdn.com/ss_thumbnails/integraixdllpdf-200819065852-thumbnail.jpg?width=640&height=640&fit=bounds)








