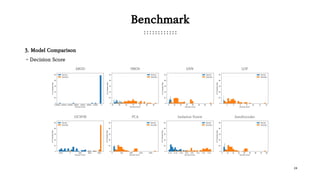
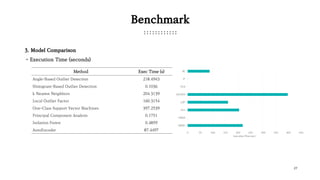
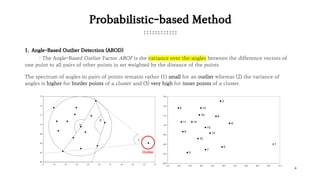
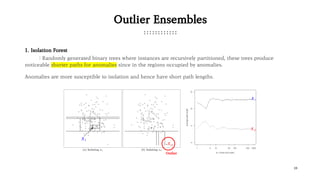
The document presents various outlier detection methods categorized into probabilistic-based, proximity-based, linear models, outlier ensembles, and neural networks. It discusses techniques such as angle-based outlier detection, local outlier factor, one-class support vector machines, and isolation forest, detailing their mechanisms and implications. Additionally, it contains a benchmark section comparing these methods' performance based on execution time and precision-recall metrics using a credit card transaction dataset.


















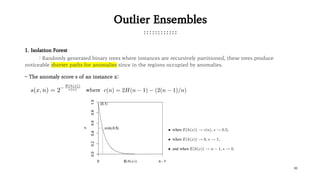


![23
Benchmark
2. Model Selection
: Use model implemented in ‘pyod’ library. The parameters were selected through several tests.
Method Selected parameter (Others are default)
Angle-Based Outlier Detection {method=‘fast’}
Histogram-Based Outlier Detection {n_bins=5}
k Nearest Neighbors {n_neighbors=100}
Local Outlier Factor {n_neighbors=300}
One-Class Support Vector Machines {kernel=‘rbf’}
Principal Component Analysis {}
Isolation Forest {max_features=0.5, n_estimators=10, Bootstrap=False}
AutoEncoder
{hidden_neurons=[24, 16, 24], batch_size=2048,
epochs=300, validation_size=0.2}](https://image.slidesharecdn.com/outlierdetectionmethodintroduction-190131070758/85/Outlier-detection-method-introduction-23-320.jpg)