Downloaded 116 times



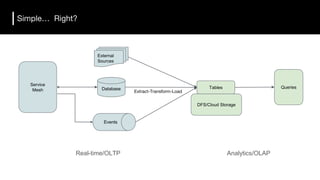
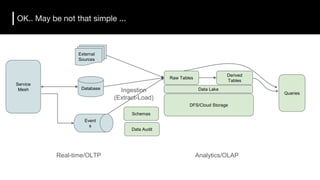

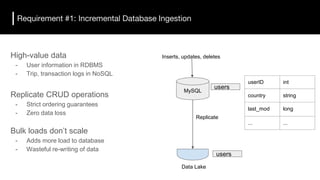
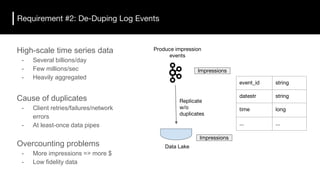


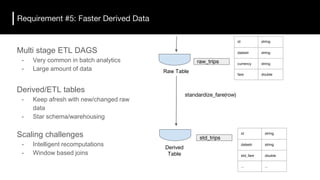





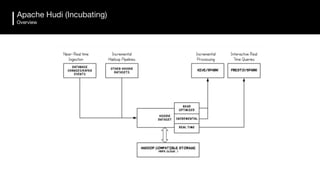

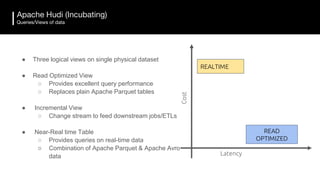
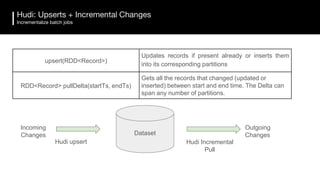


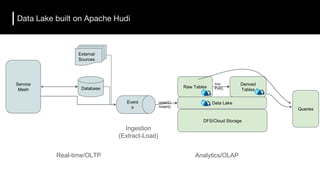
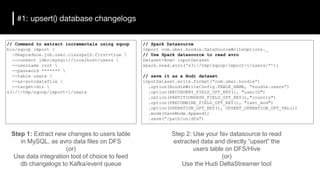
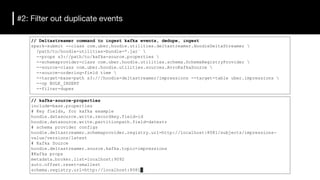












The document discusses the challenges and requirements for building efficient data lakes using Apache Hudi, focusing on issues like incremental data ingestion, deduplication, transactional consistency, file management, and legal requirements for data retention. It provides insights into the architecture, functionality, and benefits of Hudi, including support for snapshot isolation, upserts, and optimized querying. Additionally, it outlines the roadmap for Apache Hudi's development and its current status in open-source community support.













![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)























































