Downloaded 202 times


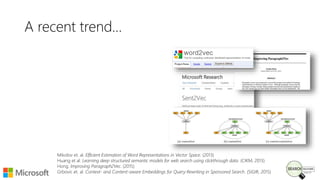


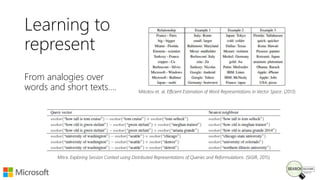




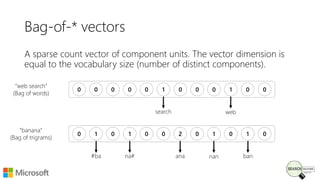
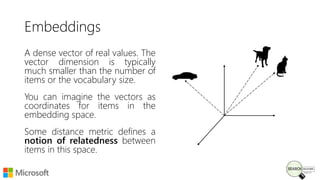



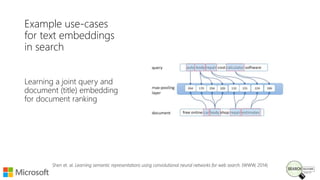




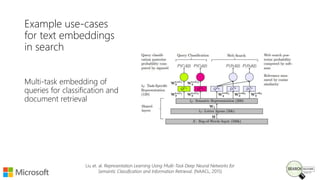

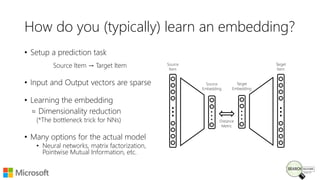
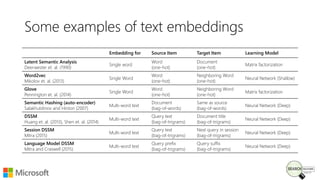
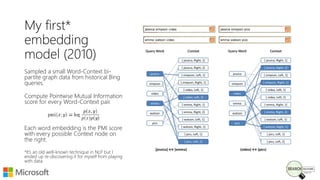













Bhaskar Mitra, a relevance engineer at Microsoft Bing, discusses his experiences and insights on text embeddings in information retrieval during a presentation. He emphasizes the impact of neural models in learning vector representations for various types of information, highlighting notable research and applications in search systems. Mitra also cautions against blindly using pre-trained embeddings and differentiates between typical and topical similarity in embedding training.











































































































