Download as PDF, PPTX





![Other
possible
solu$ons…
• Kissàconcrete
sense:
touching
with
lips/mouth
• animate
kiss
[using
lips/
mouth]
animate/inanimate
• Ex:
he
kissed
her;
• The
dolphin
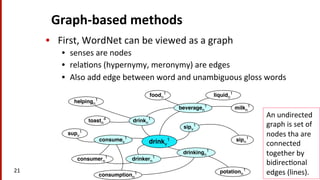
kissed
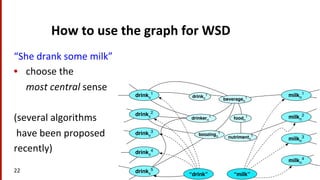
the
kid
• Why
does
the
pope
kiss
the
ground
a^er
he
disembarks
...
• Kissàfigura(ve
sense:
touching
• animate
kiss
inanimate
• Ex:
"Walk
as
if
you
are
kissing
the
Earth
with
your
feet."
5
pursed
lips?](https://image.slidesharecdn.com/05lectwordsensedisambiguation-160205103145/85/Lecture-Word-Sense-Disambiguation-5-320.jpg)














































![Colloca$onal
features
• Posi(on-‐specific
informa(on
about
the
words
and
colloca(ons
in
window
• guitar
and
bass
player
stand
• word
1,2,3
grams
in
window
of
±3
is
common
encoding local lexical and grammatical information that can often accurately isola
a given sense.
For example consider the ambiguous word bass in the following WSJ sentenc
(16.17) An electric guitar and bass player stand off to one side, not really part of
the scene, just as a sort of nod to gringo expectations perhaps.
A collocational feature vector, extracted from a window of two words to the rig
and left of the target word, made up of the words themselves, their respective part
of-speech, and pairs of words, that is,
[wi 2,POSi 2,wi 1,POSi 1,wi+1,POSi+1,wi+2,POSi+2,wi 1
i 2,wi+1
i ] (16.1
would yield the following vector:
[guitar, NN, and, CC, player, NN, stand, VB, and guitar, player stand]
High performing systems generally use POS tags and word collocations of leng
1, 2, and 3 from a window of words 3 to the left and 3 to the right (Zhong and N
For example consider the ambiguous word bass in the following WSJ sent
6.17) An electric guitar and bass player stand off to one side, not really par
the scene, just as a sort of nod to gringo expectations perhaps.
collocational feature vector, extracted from a window of two words to the
d left of the target word, made up of the words themselves, their respective
-speech, and pairs of words, that is,
[wi 2,POSi 2,wi 1,POSi 1,wi+1,POSi+1,wi+2,POSi+2,wi 1
i 2,wi+1
i ] (
ould yield the following vector:
[guitar, NN, and, CC, player, NN, stand, VB, and guitar, player stand]
gh performing systems generally use POS tags and word collocations of l
2, and 3 from a window of words 3 to the left and 3 to the right (Zhong an](https://image.slidesharecdn.com/05lectwordsensedisambiguation-160205103145/85/Lecture-Word-Sense-Disambiguation-57-320.jpg)

![Co-‐Occurrence
Example
• Assume
we’ve
semled
on
a
possible
vocabulary
of
12
words
in
“bass”
sentences:
[fishing,
big,
sound,
player,
fly,
rod,
pound,
double,
runs,
playing,
guitar,
band]
• The
vector
for:
guitar
and
bass
player
stand
[0,0,0,1,0,0,0,0,0,0,1,0]](https://image.slidesharecdn.com/05lectwordsensedisambiguation-160205103145/85/Lecture-Word-Sense-Disambiguation-59-320.jpg)




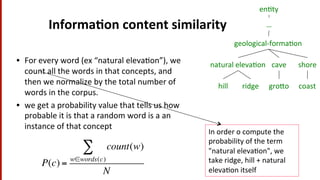
The document discusses methods and challenges of word sense disambiguation (WSD) in language technology, focusing on approaches such as thesaurus/dictionary methods and machine learning techniques. It highlights the significance of understanding context, polysemy, and the diverse solutions presented by students in practical activities. The lecture emphasizes the importance of various algorithms, including the simplified Lesk algorithm and graph-based methods, in improving disambiguation and word similarity assessments.































![Biomedical Word Sense Disambiguation presentation [Autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/c1c4b39c-e950-412e-8f67-71d4a8f4ef7b-161027154523-thumbnail.jpg?width=640&height=640&fit=bounds)











































































