Downloaded 122 times












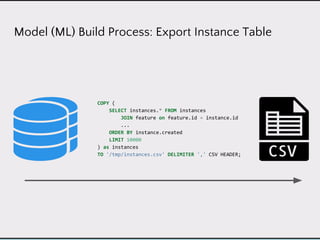
![Model (ML) Build Process: Build Model
import pandas as pd
from sklearn.svm import SVC
from sklearn.cross_validation import KFold
# Load Data
data = pd.read_csv('/tmp/instances.csv')
scores = []
# Evaluation
folds = KFold(n=len(data), n_folds=12)
for train, test in folds:
model = SVC()
model.fit(data[train])
score = model.score(data[test])
scores.append(score)
# Build the actual model
model = SVC()
model.fit(data)](https://image.slidesharecdn.com/dataproductarchitectures-160721230340/85/Data-Product-Architectures-33-320.jpg)
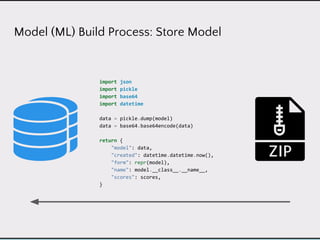
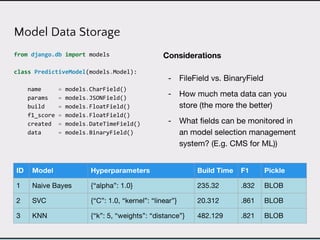
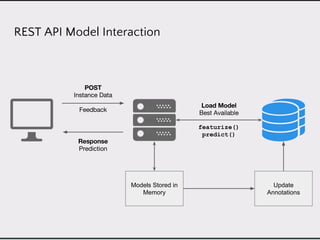



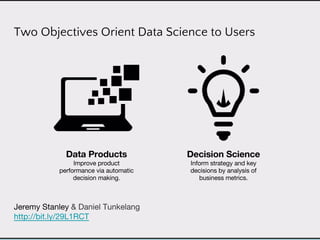
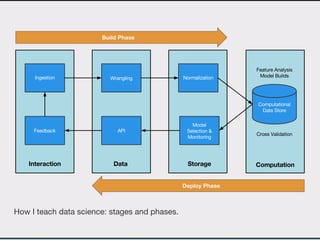
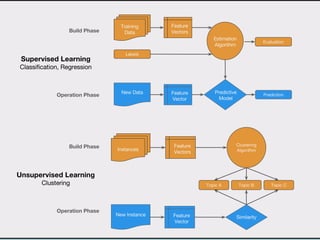
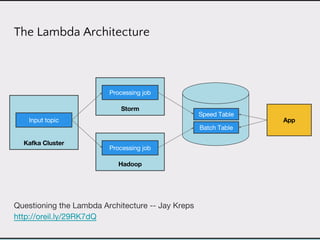
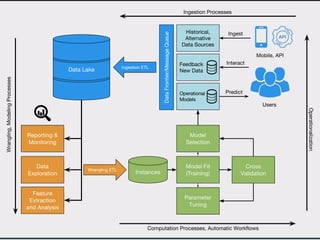
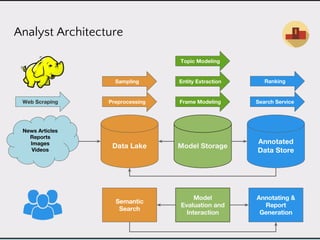
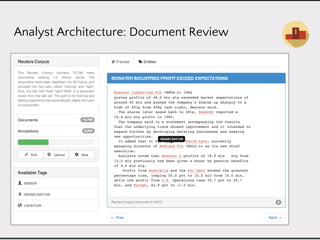
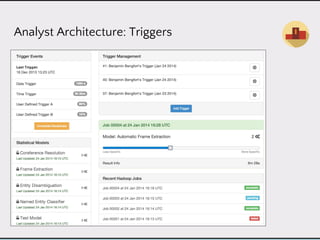
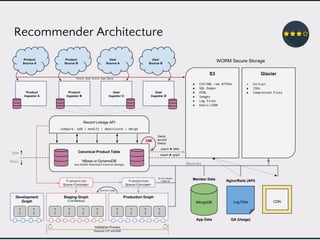
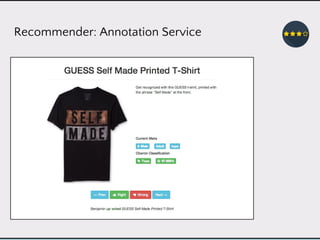
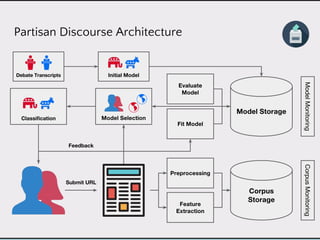
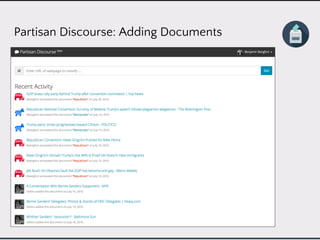
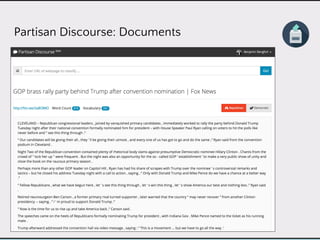
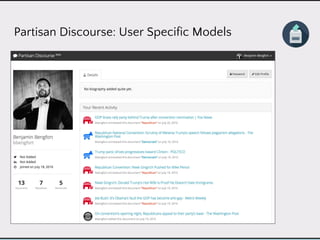
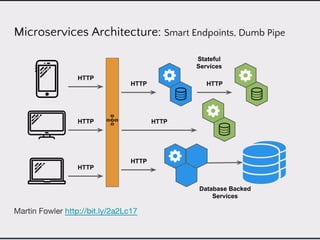
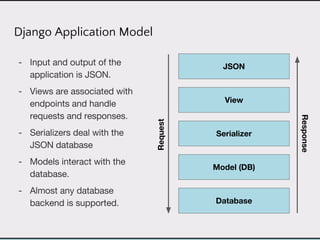
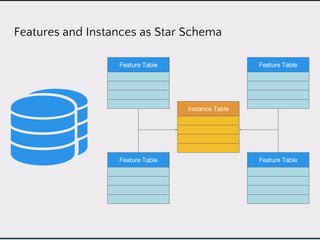
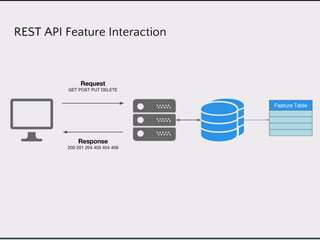
This document discusses data product architectures and provides examples of different architectures for data products, including the lambda architecture, analyst architecture, recommender architecture, and partisan discourse architecture. It also discusses common design principles for data product architectures, such as using microservices with stateful backend services and database-backed APIs. Key aspects of data product architectures include handling training data and models, making predictions via APIs, updating models and annotations, and designing flexible systems that can incorporate new models and data.
























































![[DSC Europe 22] Engineers guide for shepherding models in to production - Mar...](https://cdn.slidesharecdn.com/ss_thumbnails/markodimitrijevic-engineersguideforshepherdingmodelsintoproduction2-221130080720-6e979b6f-thumbnail.jpg?width=640&height=640&fit=bounds)











































