Downloaded 54 times












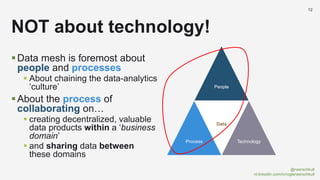
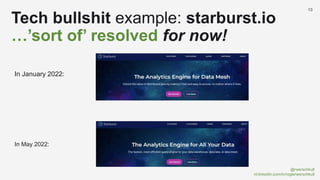


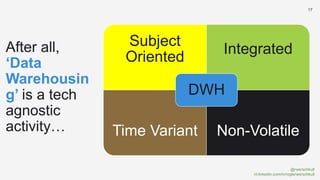
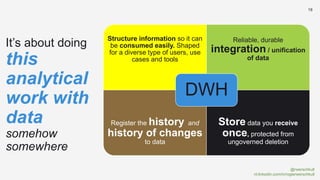
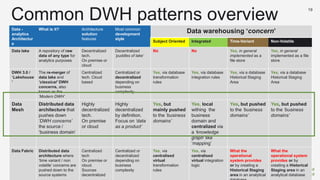
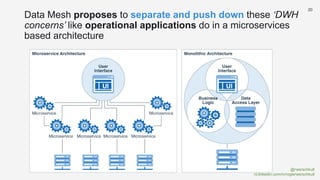

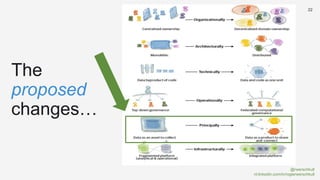
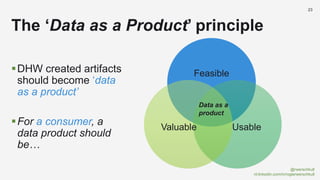



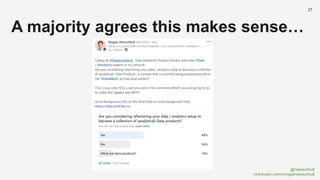
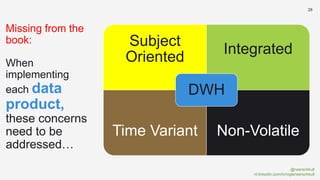







The document discusses the concept of data mesh, arguing it will not solve the analytics challenges faced by organizations but highlights its potential benefits when implemented correctly. It emphasizes that successful data mesh implementation relies on decentralization, cultural change, and viewing data as a product. Additionally, it critiques the existing literature on data mesh for lacking practical implementation guidance while suggesting an alternative approach using data warehousing principles.











































![[DSC Europe 23] Ivan Dundovic - How To Treat Your Data As A Product.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ewangp91sryz0b4shlxd-ivan-dundovic-howtotreatyourdataasaproduct-231129143902-dd1541cf-thumbnail.jpg?width=640&height=640&fit=bounds)




















