Download to read offline














![A peak under the
hood
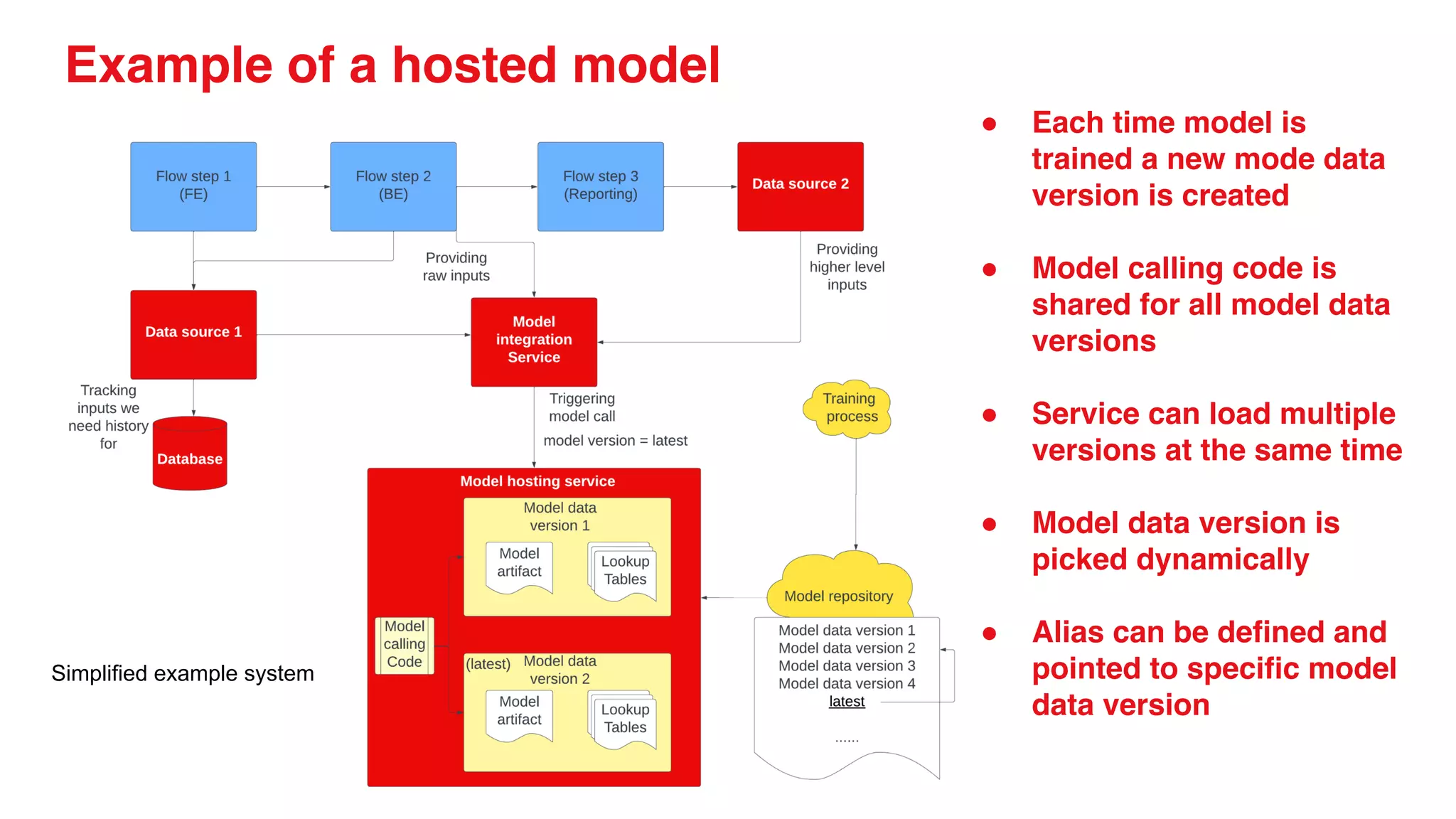
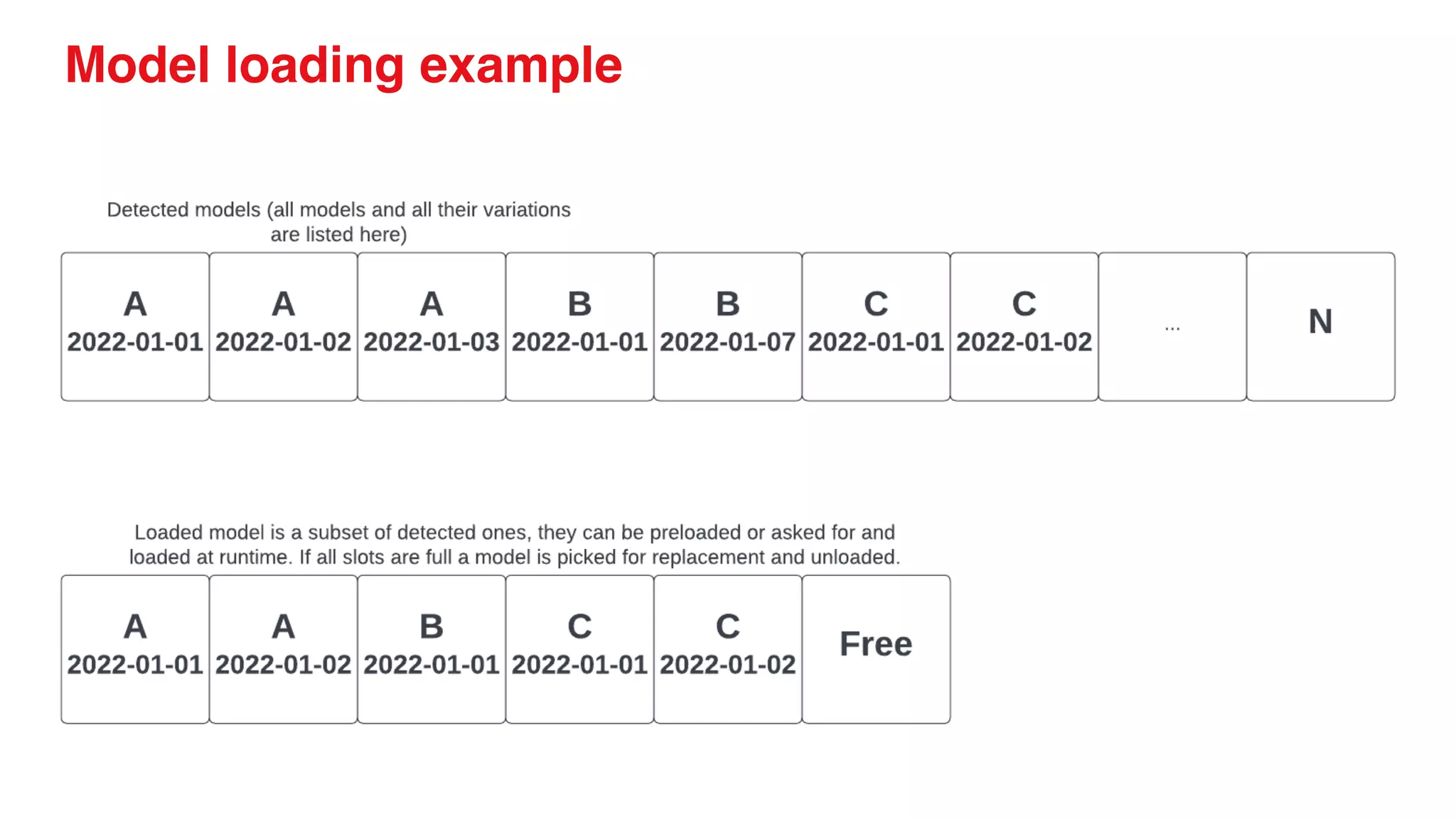
● We use python based service for model hosting
to make DS integration of calling code easy
● We expose a set of REST API routes for each
supported model
● We run on aws ec2 instances directly and
support gpu and cpu based models
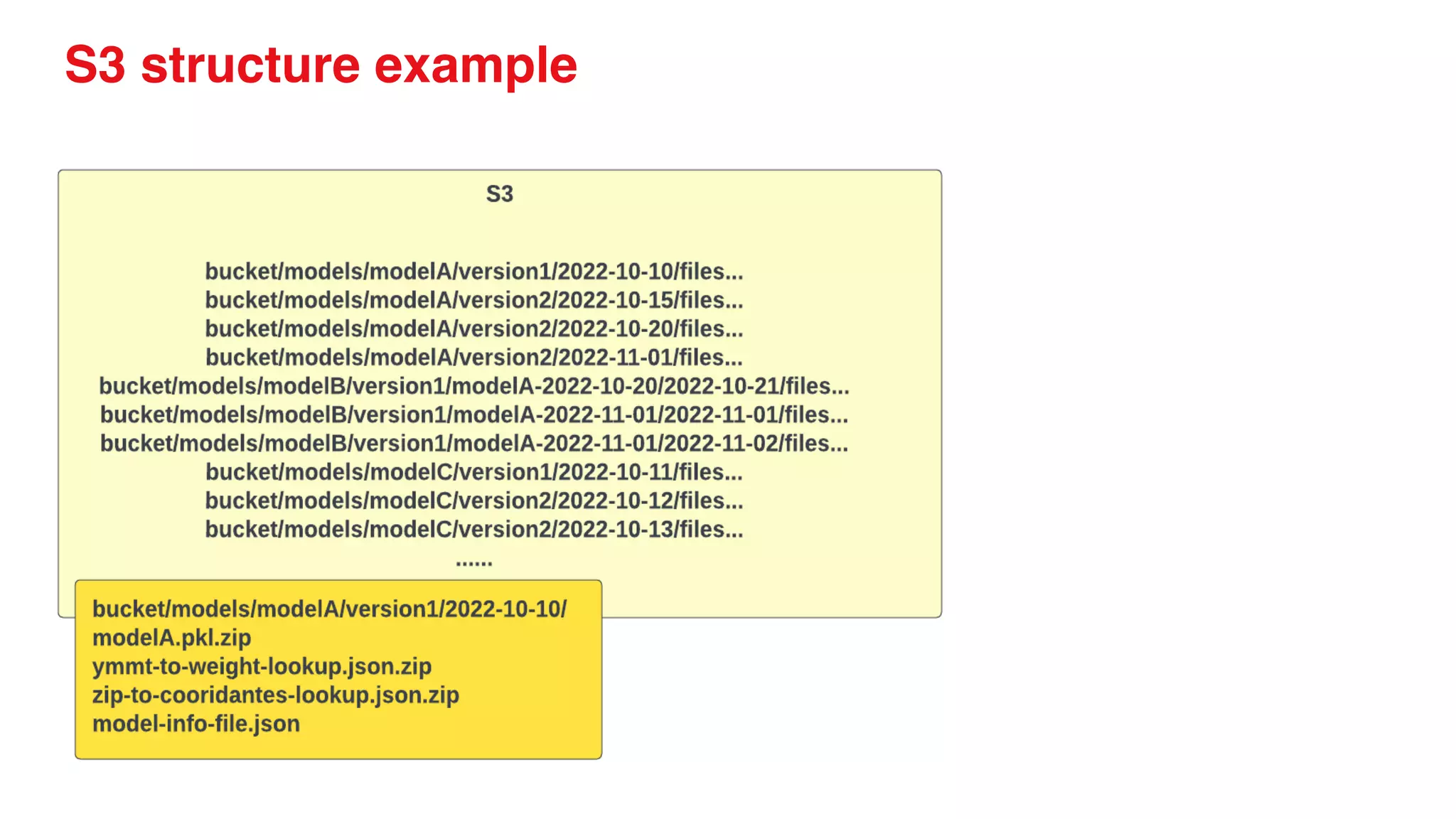
● We use s3 to store model data
● We run batch predictions and one by one real
time predictions and produce millions of
predictions per day
● Models are called by services that specialize in
orchestration, data gathering and caching
host/some-model/1/predict?modelDataVersion=last_one
Request:
[{
"vehicle": {
"year": 2019,
"make": "Lamborghini",
"model": "Huracan Spyder"
....
}
other inputs....
}]
Response:
{
"modelDataVersion": "2022-11-11",
"prediction": [
{
"reconditioningCost": "a lot of money :)"
}
]
}
*fictional api example](https://image.slidesharecdn.com/markodimitrijevic-engineersguideforshepherdingmodelsintoproduction2-221130080720-6e979b6f/75/DSC-Europe-22-Engineers-guide-for-shepherding-models-in-to-production-Marko-Dimitrijevic-18-2048.jpg)




The document serves as a comprehensive guide for engineers on developing and deploying data science models in a production environment, emphasizing model reliability, performance, and integration with existing systems. Key topics include building model pipelines, hosting strategies, common challenges in data handling, and best practices for efficient model operation. The document also highlights the significance of collaboration, monitoring, and scaling in maintaining robust model performance while addressing potential issues such as data incompleteness and integration complexities.




























![[DSC Europe 25] Jean Del Rosario - How to Reduce GenAI Costs up to 73.45%.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zjehcwqsiwjisav1znml-5-251217093201-eae4440a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Wolfgang Klein & Olena Brandsch - Operationalizing GenAI: Tur...](https://cdn.slidesharecdn.com/ss_thumbnails/mdjqcqgoriqj6kdjabxk-8-251216105606-9290bc27-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] WeiWei Feng - AI Resource Management.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/zgasvxslslg6ujvoq1ij-10-251216105605-bba59301-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Obradovic - The 80/50 Paradox: Why 50% chance of error...](https://cdn.slidesharecdn.com/ss_thumbnails/931bywtzsw2qchhnckvt-11-251216105605-9338584e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Petrovic - Is it really that expensive to build an AI sy...](https://cdn.slidesharecdn.com/ss_thumbnails/ybqhdwvusbg7jms3doxh-9-251216105605-7aab5a10-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/nc6emrfbrtwu7milgjdv-2-251216103155-797a4786-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nemanja Zivkovic - Beyond the AI Buzz: Building GTM Systems T...](https://cdn.slidesharecdn.com/ss_thumbnails/9fyxgiotsyghoolp8zvx-1-251216103155-7825d5d8-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Frank Ravanelli - Agentic AI: implications for DTC and intern...](https://cdn.slidesharecdn.com/ss_thumbnails/jcjxpmbqt8a1t3pslat6-6-251216103155-287496ef-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jakub Stech - AI for Public Good: How Data and AI Can Transfo...](https://cdn.slidesharecdn.com/ss_thumbnails/ayuupcru6ggr9f7vbp0q-1-251215095918-7b7334a3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Maria Kokiasmenos - AI Governance US Perspective.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/eszqnbzlsqa2vch6dmci-6-251215095918-6fcdf45f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Francisco Prado Moreno - Model Validation in the Age of AI: T...](https://cdn.slidesharecdn.com/ss_thumbnails/2igqvkir1yd2yzlhoylg-3-251215095918-6676c4e6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tom Winter - Automate or Fall Behind: Build Scalable AI Workf...](https://cdn.slidesharecdn.com/ss_thumbnails/row416yxt2wq7hgich0z-7-251215095918-7c974475-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Boris Surija - How AI psychologist can help you make the most...](https://cdn.slidesharecdn.com/ss_thumbnails/wmecvm1dsus4hzwm0zvc-8-251215095918-1b9adac8-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
