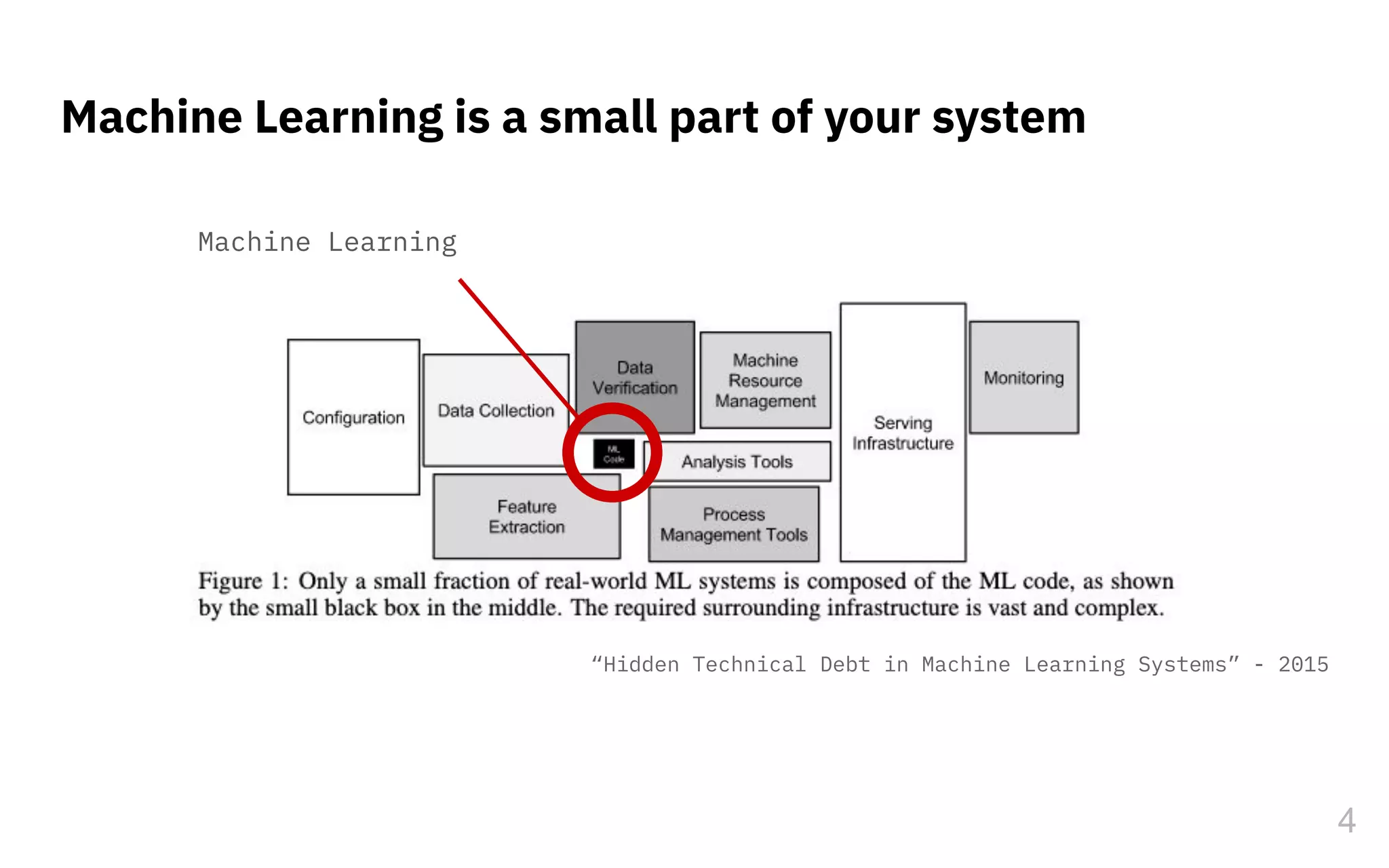
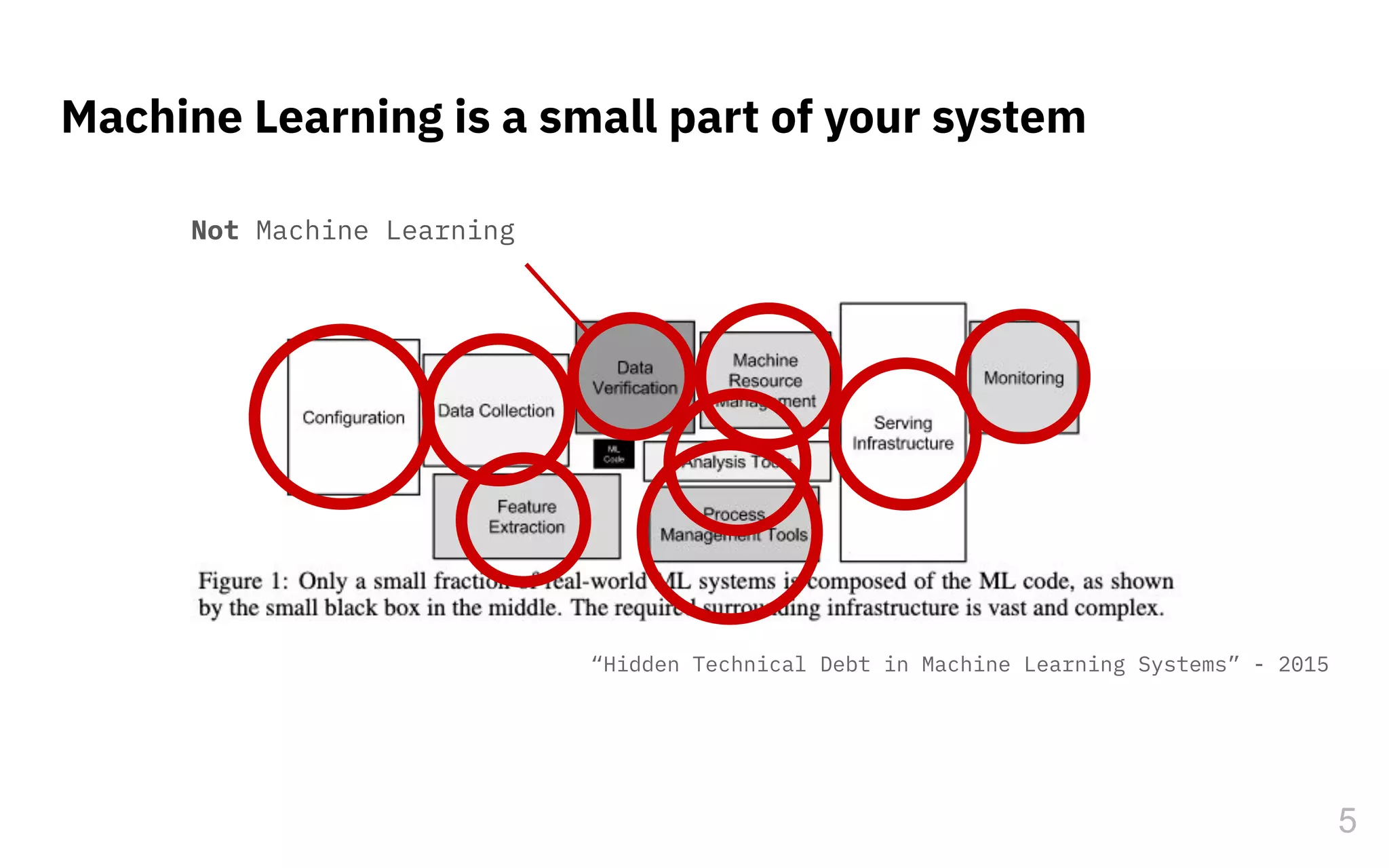
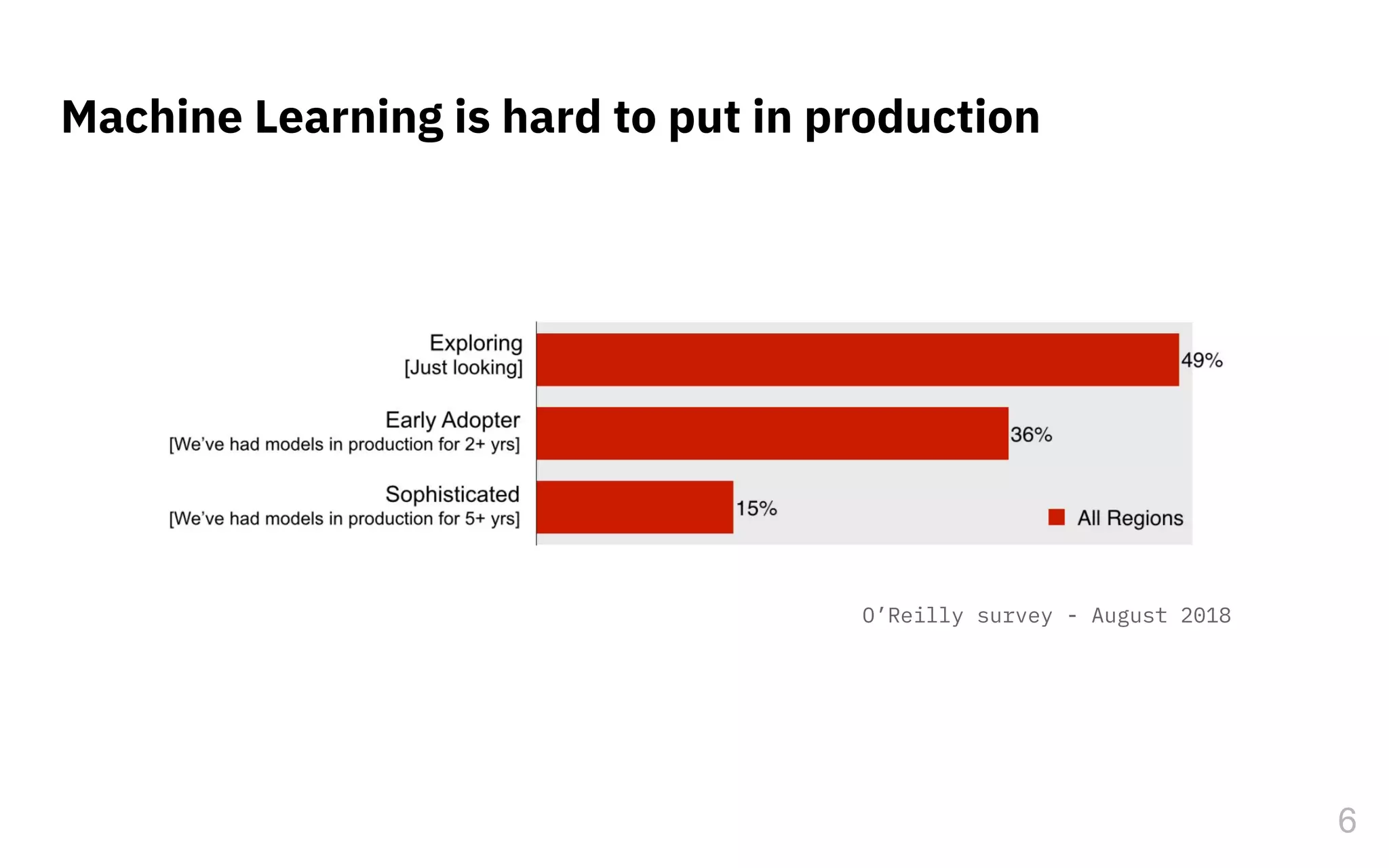
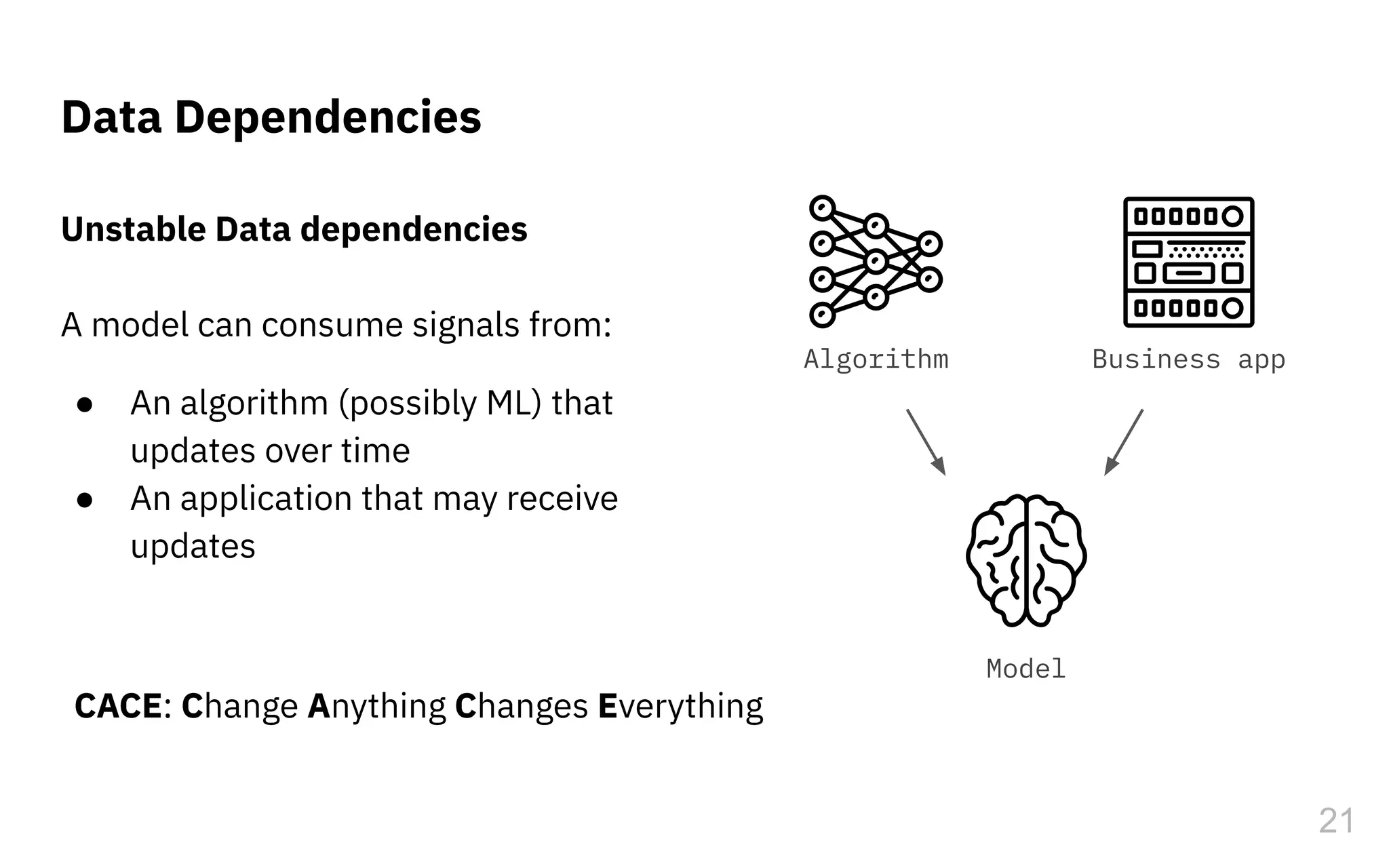
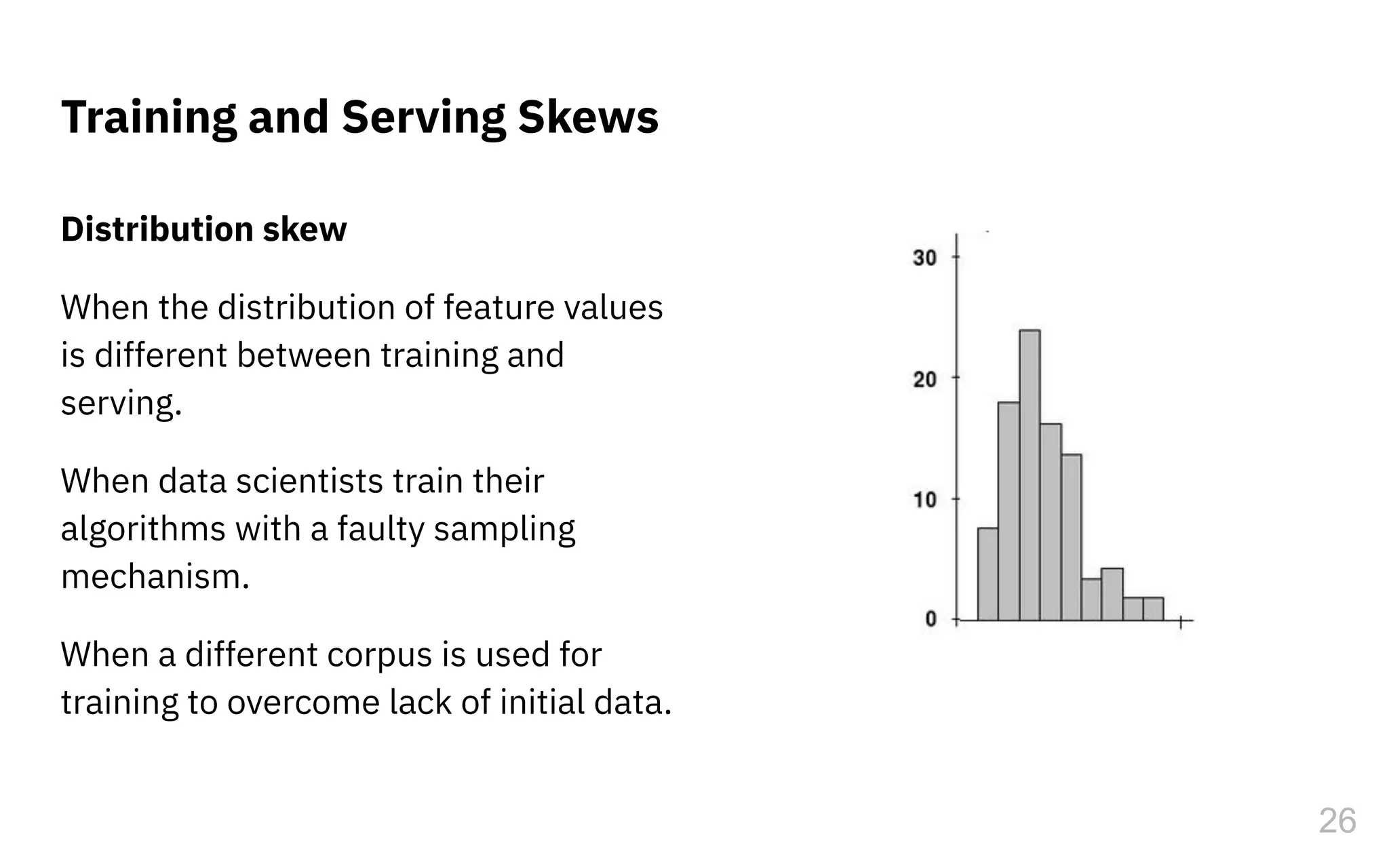
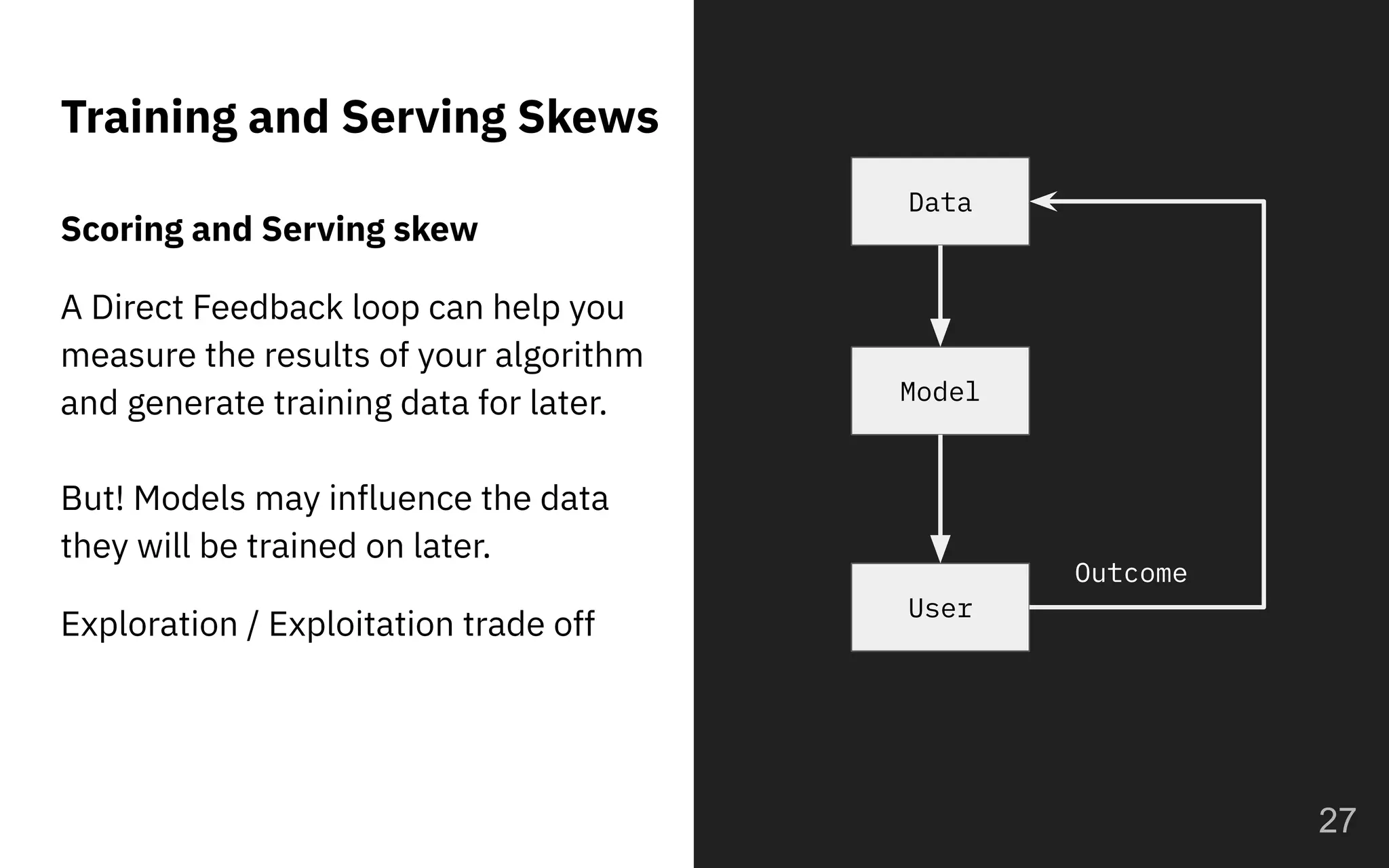
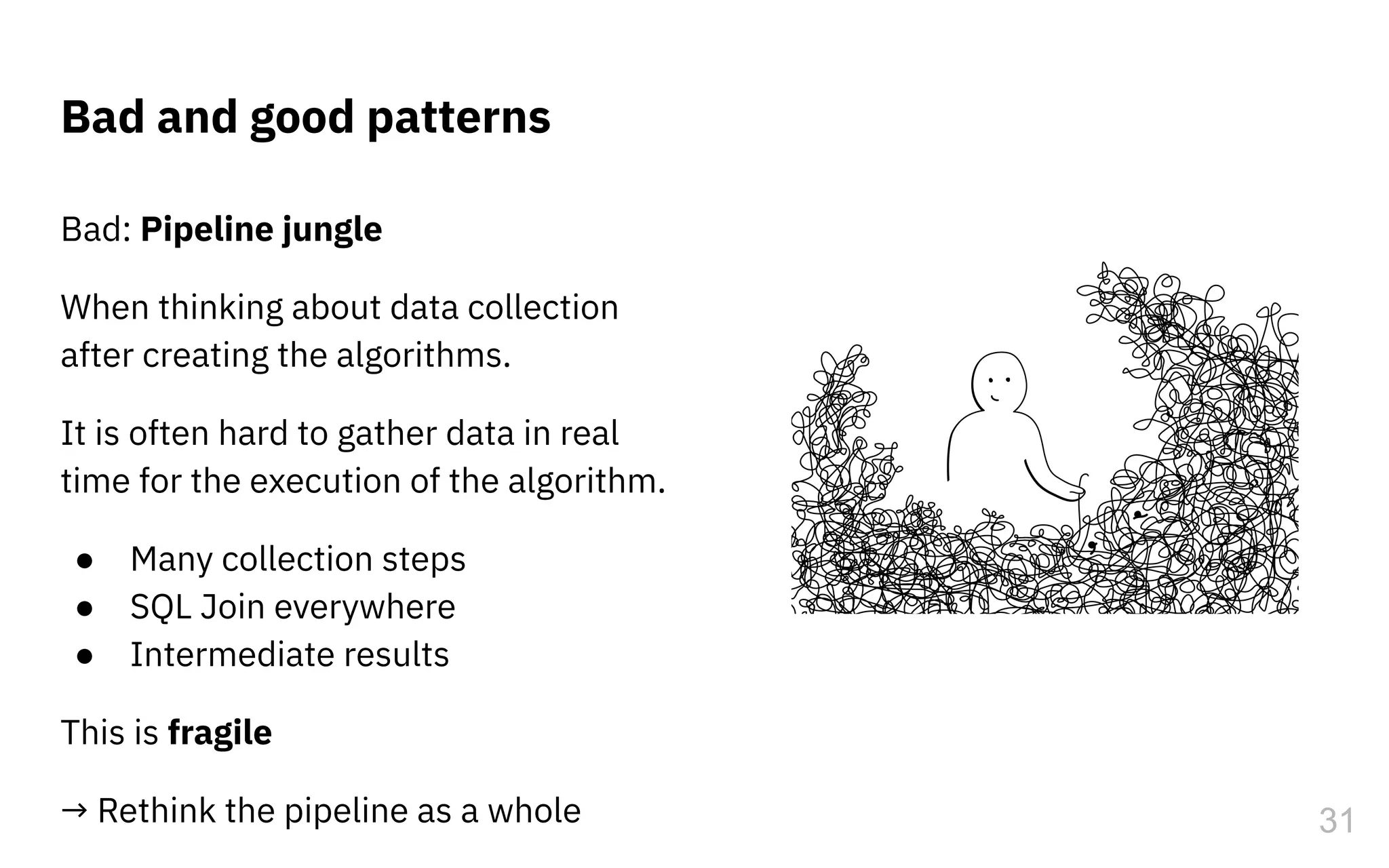
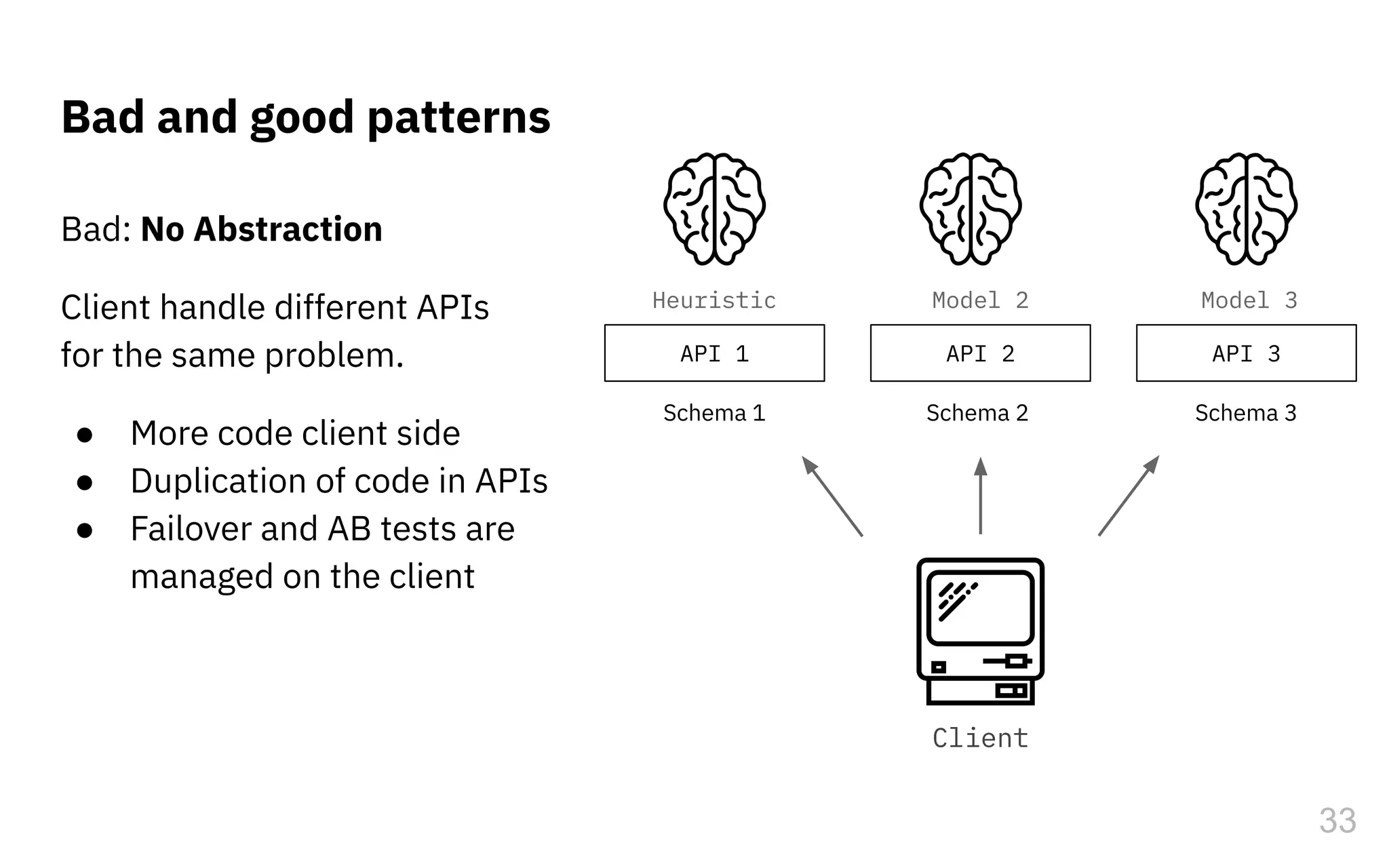
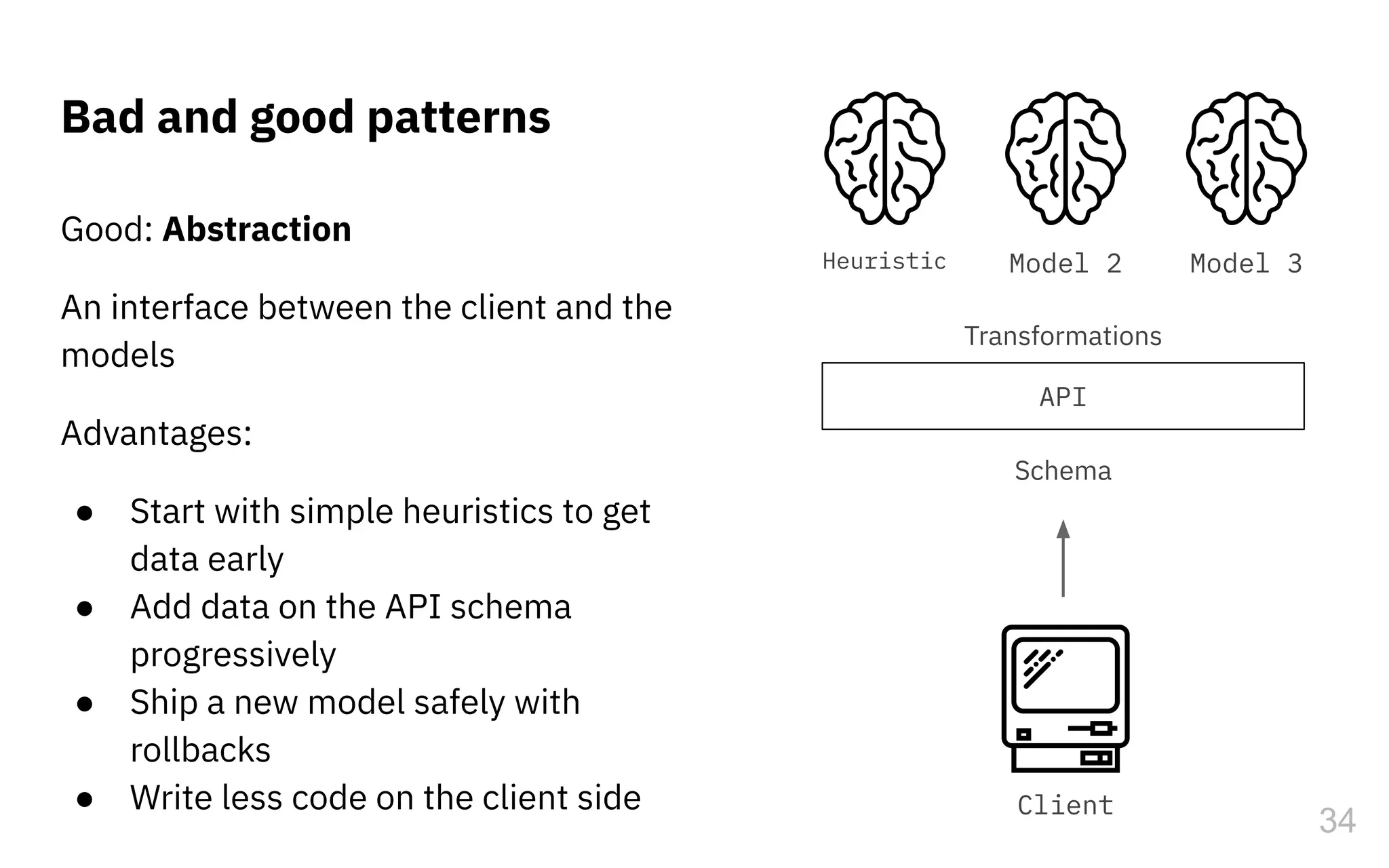
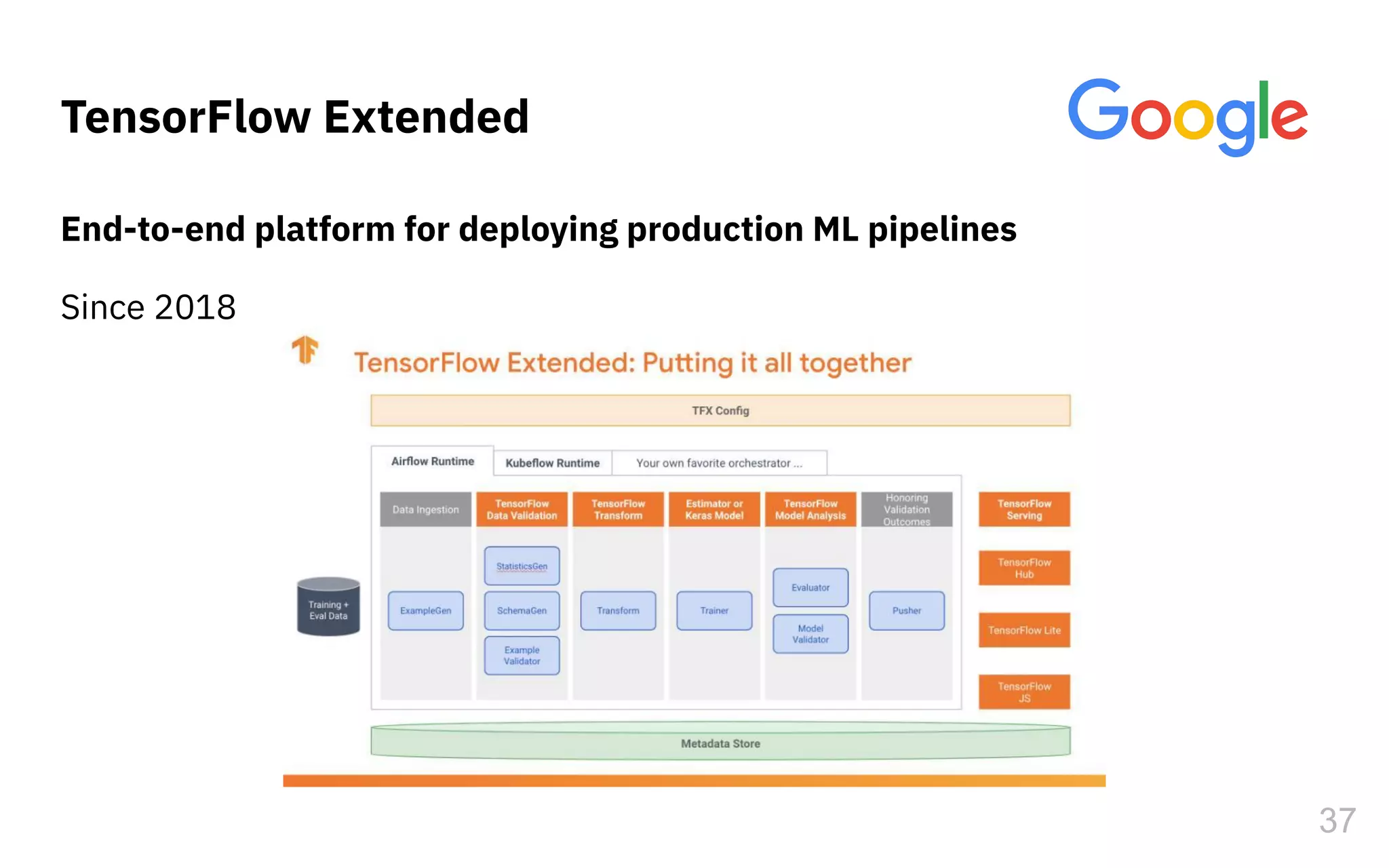
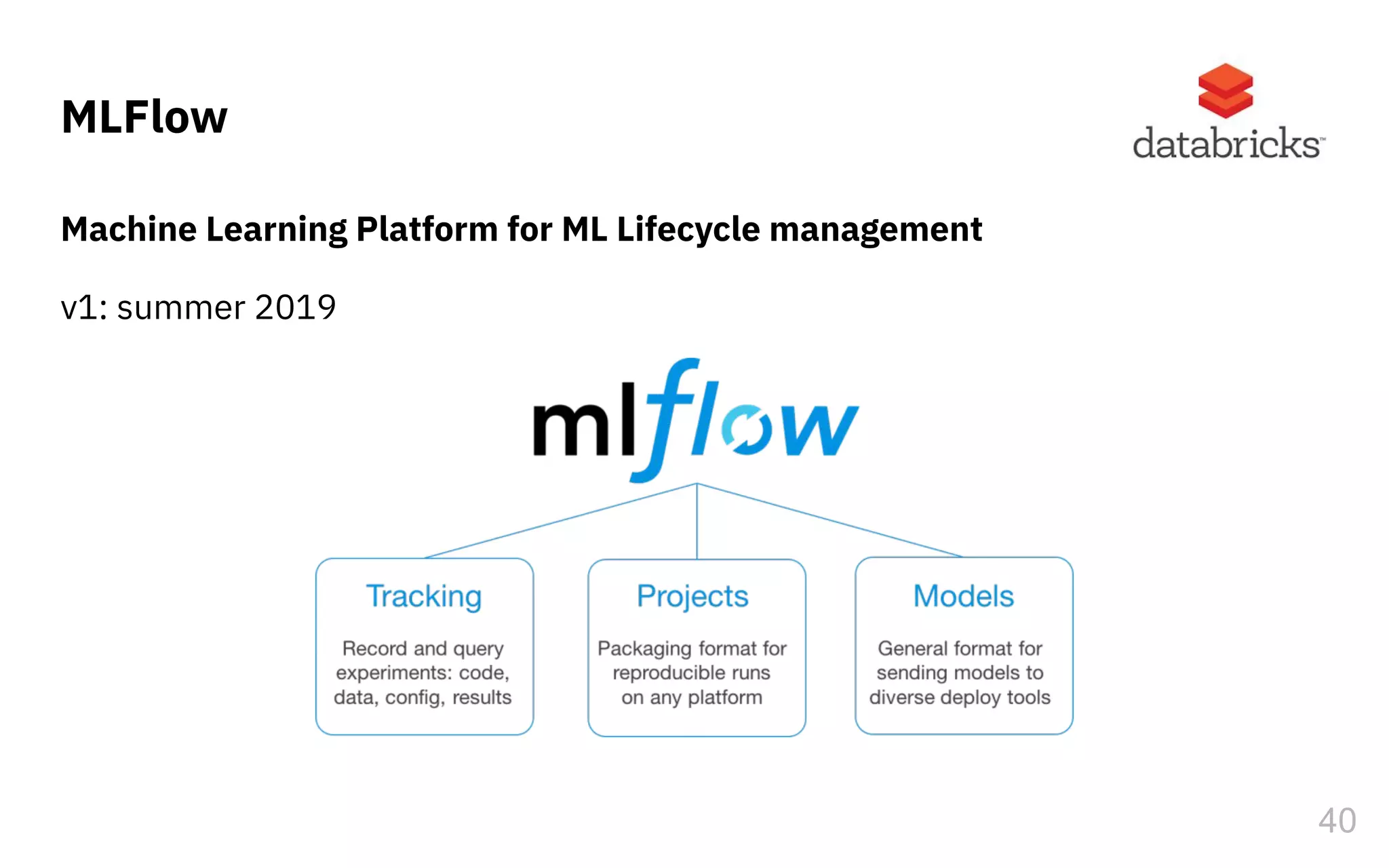
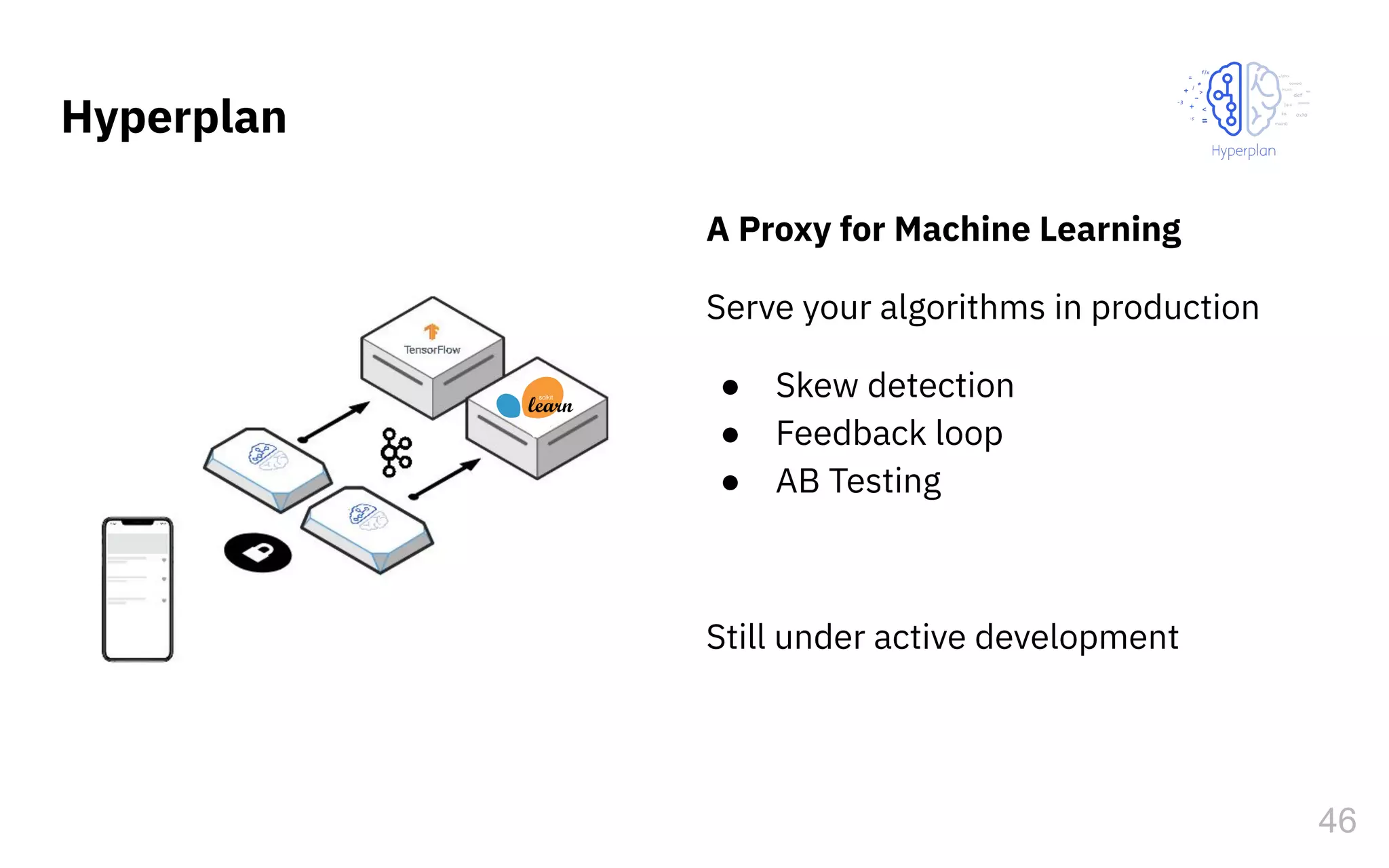
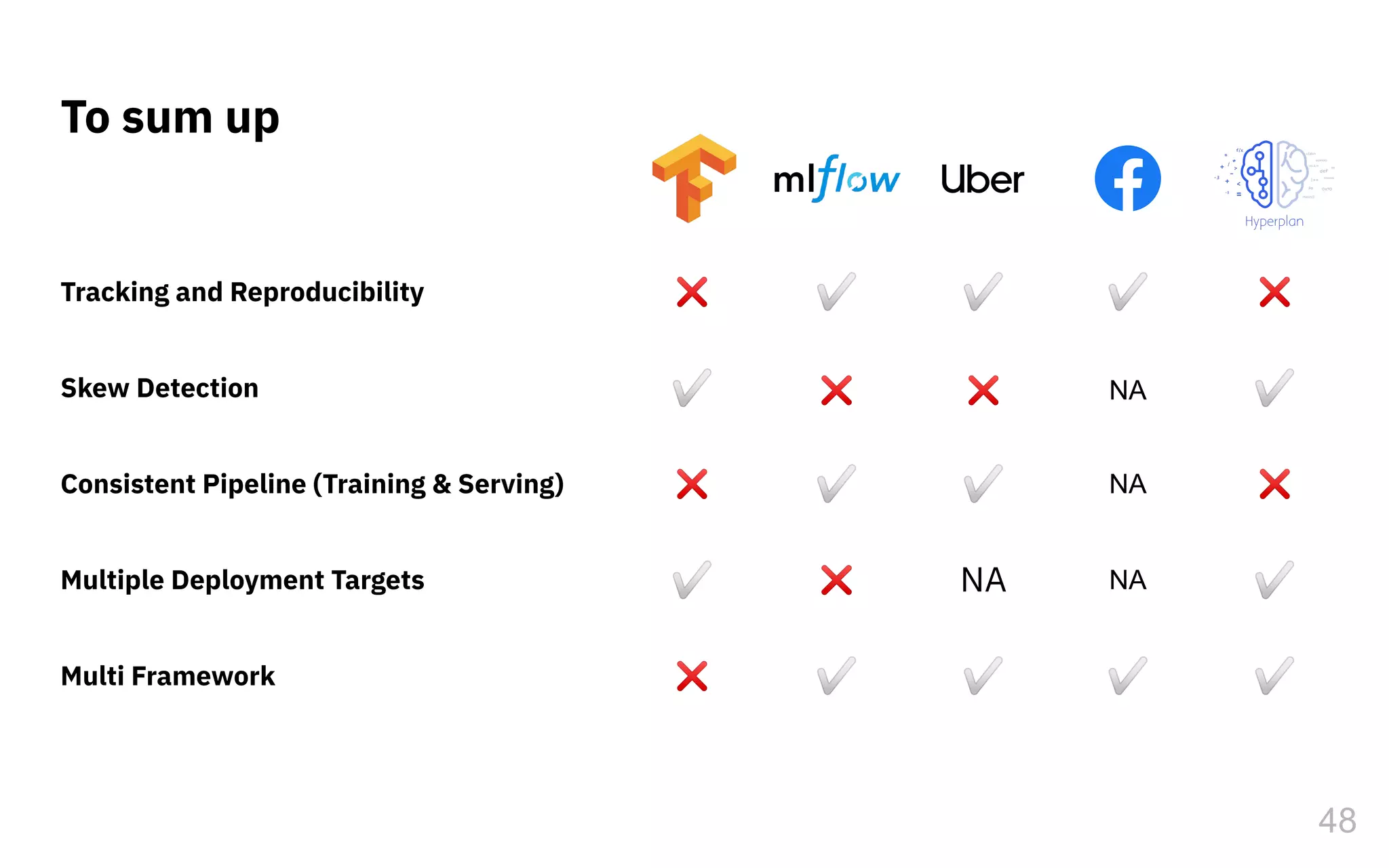
The document discusses the challenges and pitfalls of deploying machine learning systems in production, highlighting the concept of technical debt unique to ML systems. It emphasizes collaboration difficulties among teams with differing goals, as well as issues related to data dependencies and model skews that can affect performance. Additionally, it reviews various tools and platforms for tracking and managing machine learning lifecycles, such as TensorFlow Extended and MLflow.










































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














