Downloaded 23 times













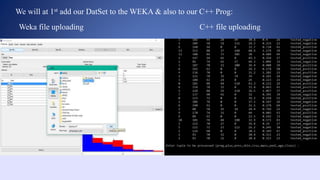
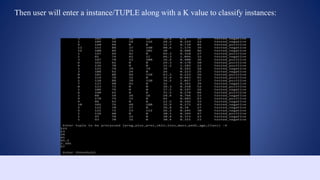
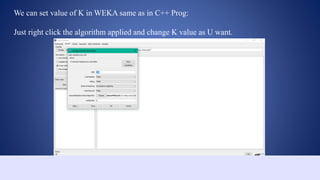
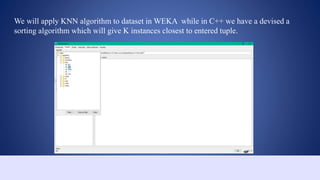
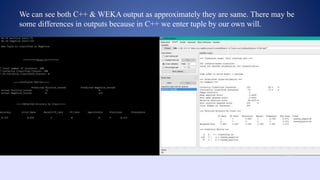

This document outlines a data structures project focused on the C++ implementation of the k-nearest neighbors (k-NN) algorithm, detailing its definition, background, and variations. It explains how k-NN classifies data based on proximity to neighbor points, discusses its advantages and disadvantages, and provides a working process for its implementation in C++. The project involves comparing the outputs of k-NN using C++ and Weka software for consistency.


































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







