Download as PDF, PPTX



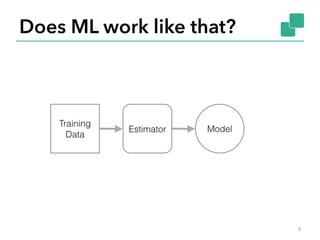
![Technology inside Flink
§ Technology inspired by compilers +
MPP databases + distributed systems
§ For ease of use, reliable performance,
and scalability
case
class
Path
(from:
Long,
to:
Long)
val
tc
=
edges.iterate(10)
{
paths:
DataSet[Path]
=>
val
next
=
paths
.join(edges)
.where("to")
.equalTo("from")
{
(path,
edge)
=>
Path(path.from,
edge.to)
}
.union(paths)
.distinct()
next
}
Cost-based
optimizer
Type extraction
stack
Memory
manager
Out-of-core
algos
real-time
streaming
Task
scheduling
Recovery
metadata
Data
serialization
stack
Streaming
network
stack
...
Pre-flight
(client) Master
Workers](https://image.slidesharecdn.com/flinkstockholm-150324090049-conversion-gate01/85/Machine-Learning-with-Apache-Flink-at-Stockholm-Machine-Learning-Group-3-320.jpg)




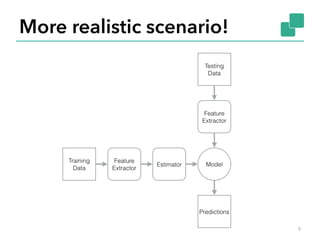



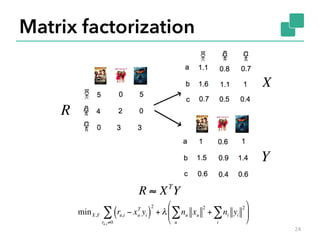
![Example: Gaussian non-negative matrix
factorization
§ Given input matrix V, find W and H such
that
§ Iterative approximation
14
Ht+1 = Ht ∗ Wt
T
V /Wt
T
Wt Ht( )
Wt+1 = Wt ∗ VHt+1
T
/Wt Ht+1Ht+1
T
( )
V ≈ WH
var
i
=
0
var
H:
CheckpointedDrm[Int]
=
randomMatrix(k,
V.numCols)
var
W:
CheckpointedDrm[Int]
=
randomMatrix(V.numRows,
k)
while(i
<
maxIterations)
{
H
=
H
*
(W.t
%*%
V
/
W.t
%*%
W
%*%
H)
W
=
W
*
(V
%*%
H.t
/
W
%*%
H
%*%
H.t)
i
+=
1
}](https://image.slidesharecdn.com/flinkstockholm-150324090049-conversion-gate01/85/Machine-Learning-with-Apache-Flink-at-Stockholm-Machine-Learning-Group-14-320.jpg)





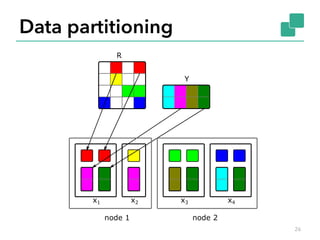
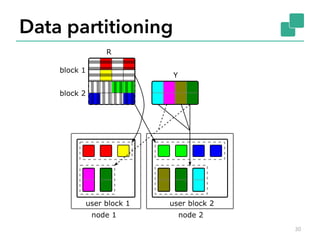
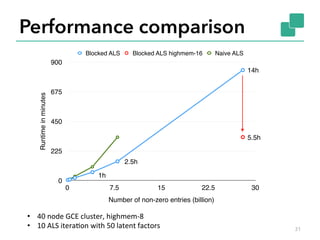
![Naïve ALS
case
class
Rating(userID:
Int,
itemID:
Int,
rating:
Double)
case
class
ColumnVector(columnIndex:
Int,
vector:
Array[Double])
val
items:
DataSet[ColumnVector]
=
_
val
ratings:
DataSet[Rating]
=
_
//
Generate
tuples
of
items
with
their
ratings
val
uVA
=
items.join(ratings).where(0).equalTo(1)
{
(item,
ratingEntry)
=>
{
val
Rating(uID,
_,
rating)
=
ratingEntry
(uID,
rating,
item.vector)
}
}
27](https://image.slidesharecdn.com/flinkstockholm-150324090049-conversion-gate01/85/Machine-Learning-with-Apache-Flink-at-Stockholm-Machine-Learning-Group-27-320.jpg)










The document discusses Apache Flink, a large-scale data processing engine with capabilities for batch and real-time streaming analysis, utilizing a cost-based optimizer and custom memory management. It covers the implementation of machine learning pipelines using Flink, highlighting features like stateful iterations and delta iterations, as well as various algorithms and applications in streaming machine learning. Additionally, it mentions ongoing developments in Flink-ML and its integration with other frameworks for advanced machine learning functionalities.








































![[FFE19] Build a Flink AI Ecosystem](https://cdn.slidesharecdn.com/ss_thumbnails/ffe19flinkaiecosystem-191010100923-thumbnail.jpg?width=640&height=640&fit=bounds)






























![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)












