Download as PDF, PPTX




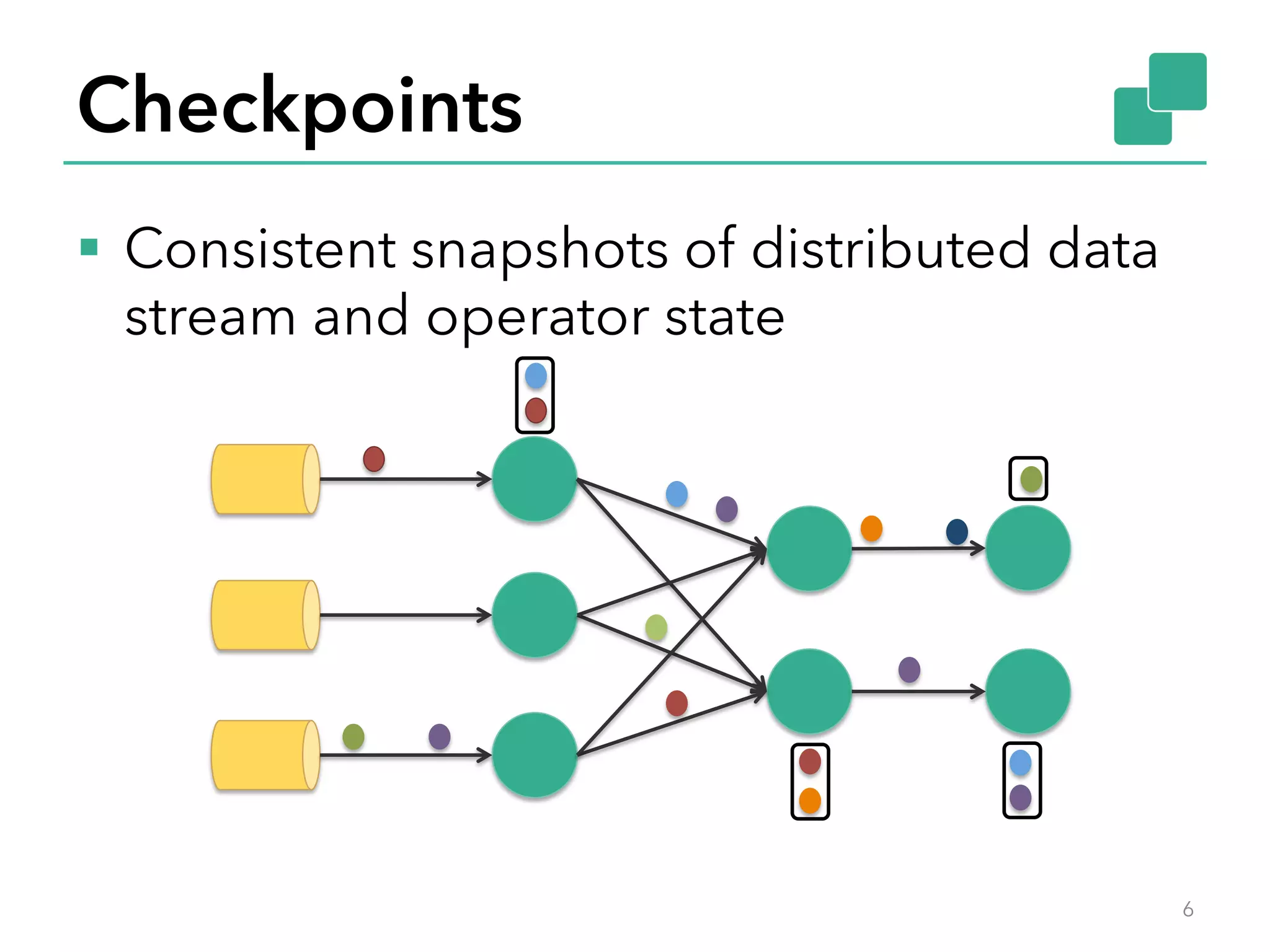
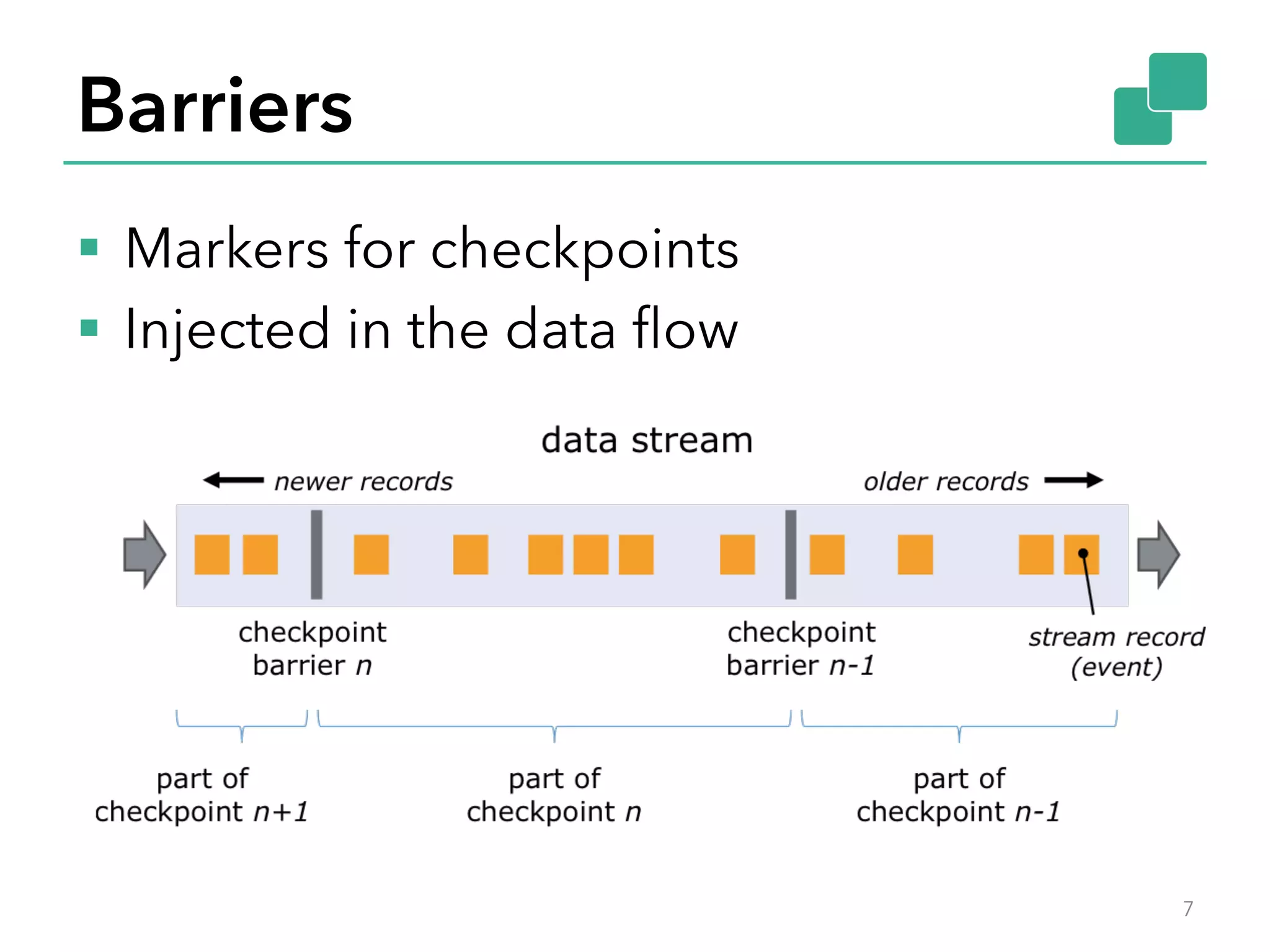
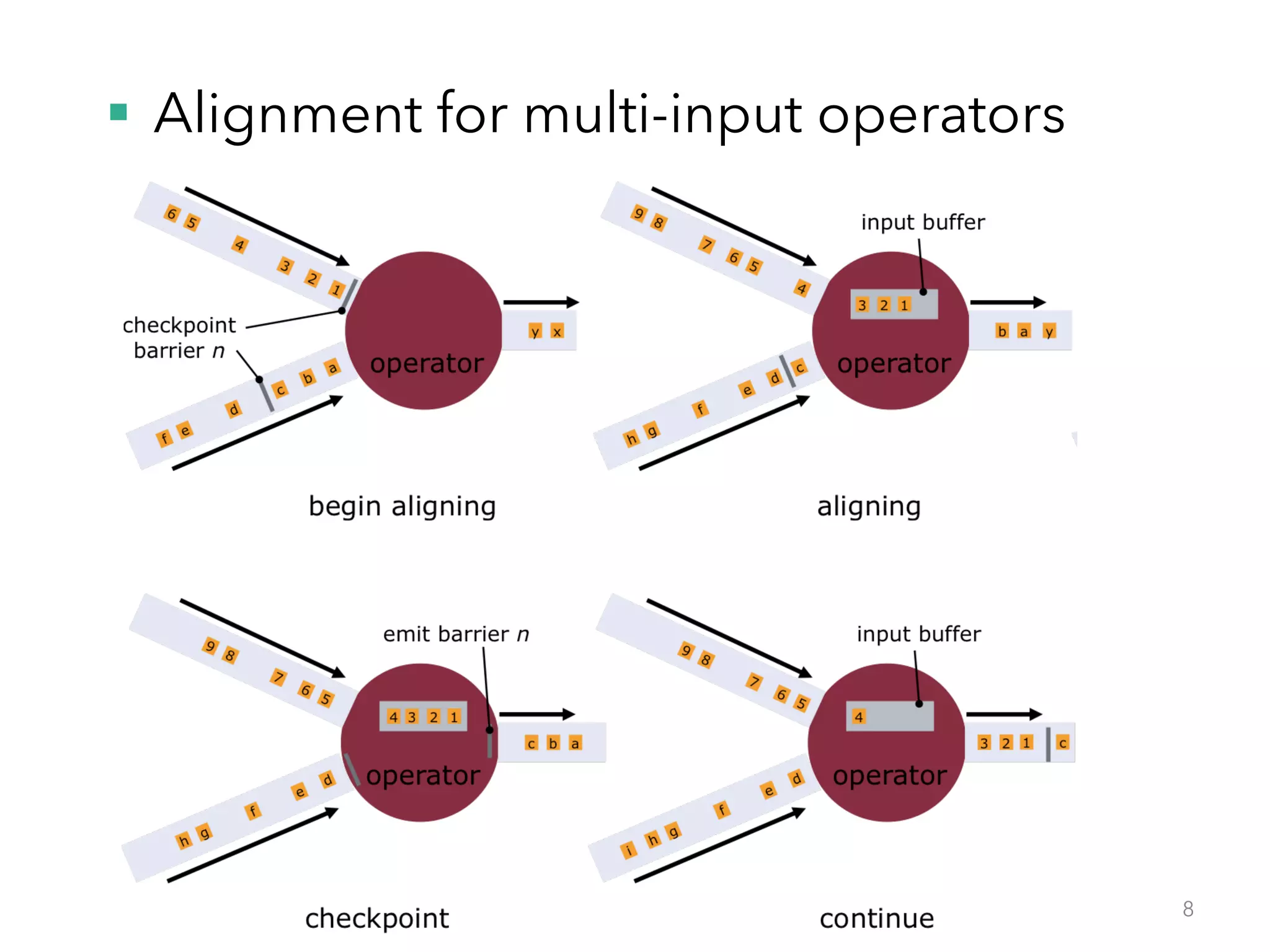

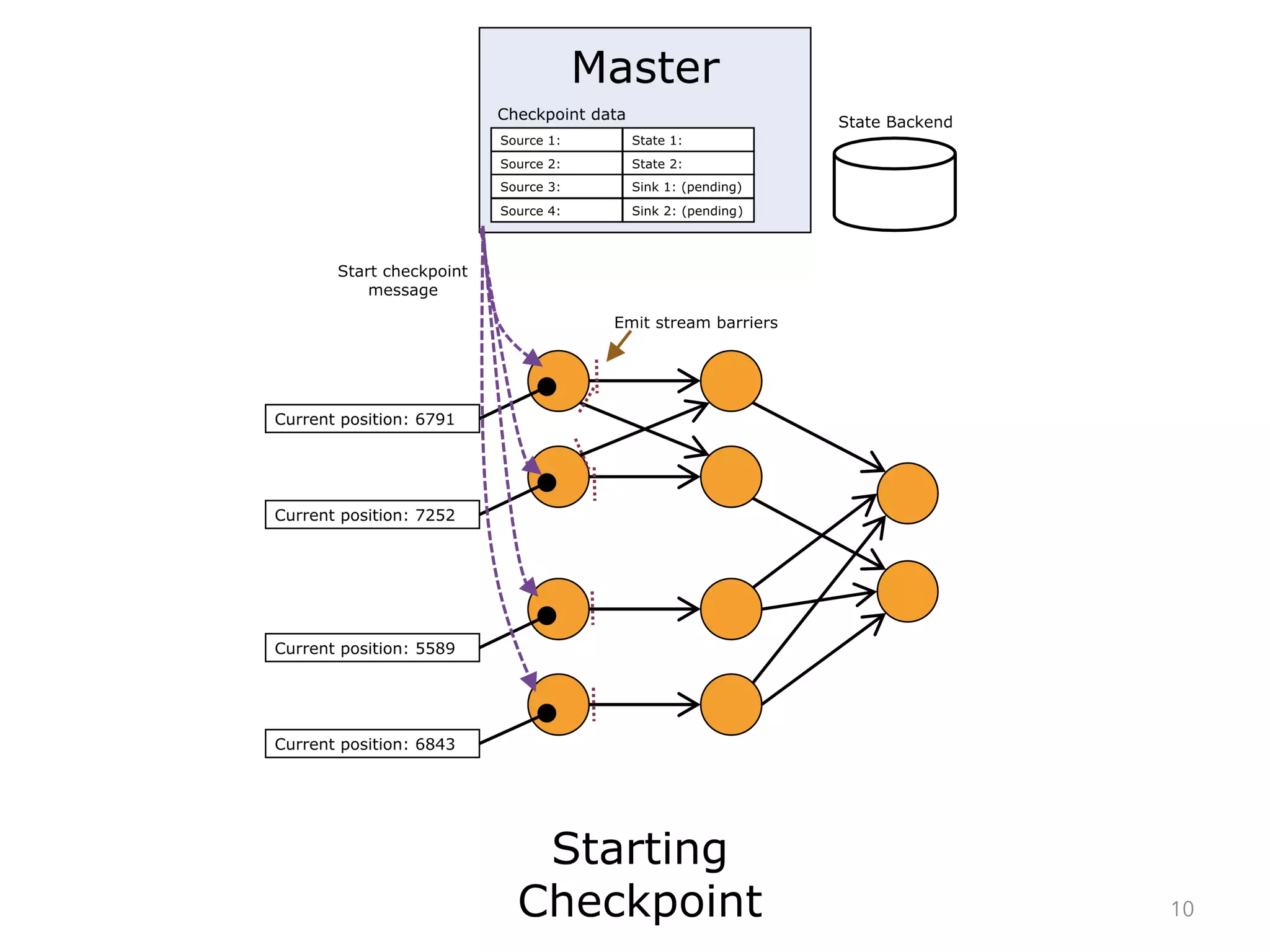
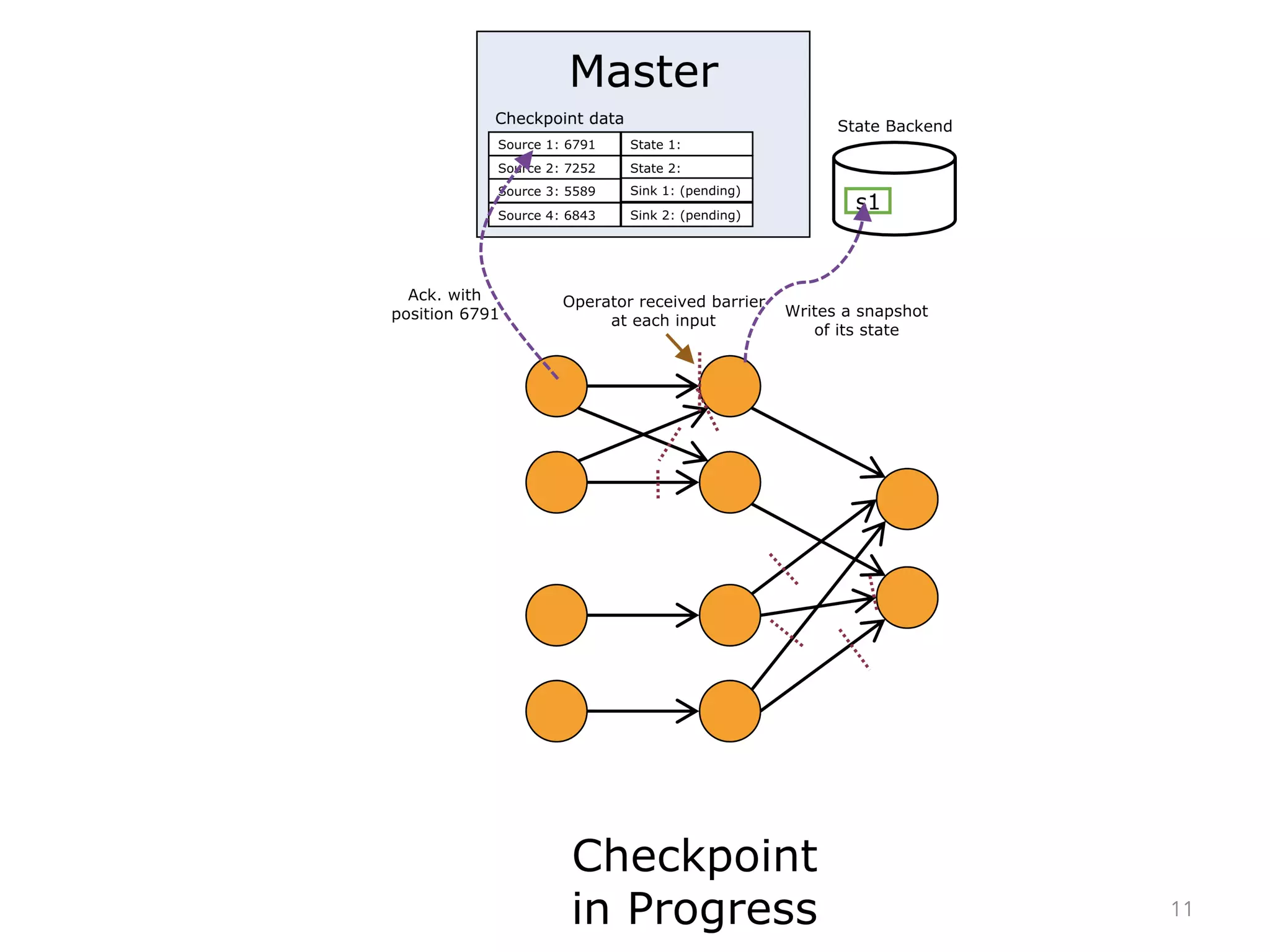
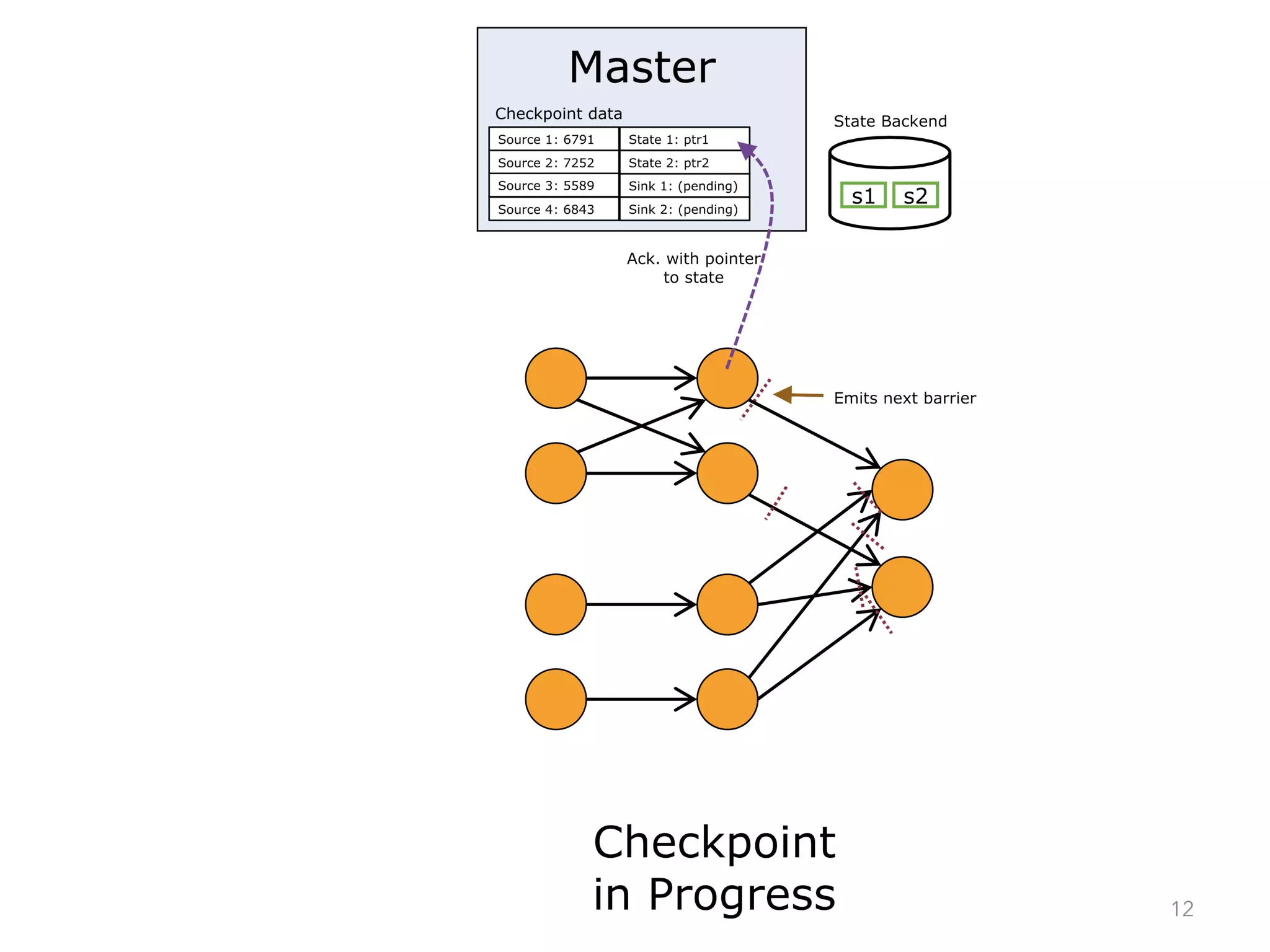
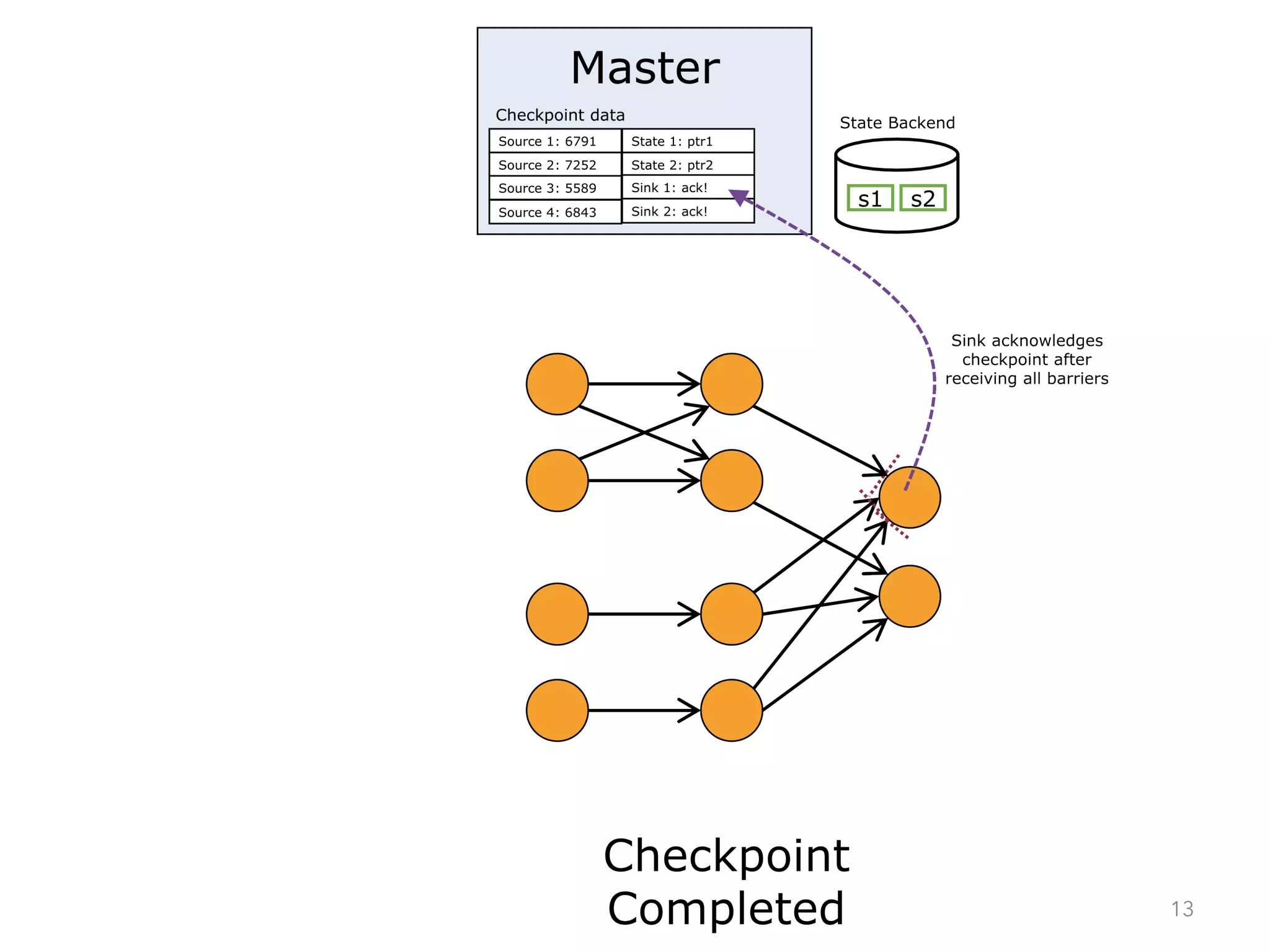
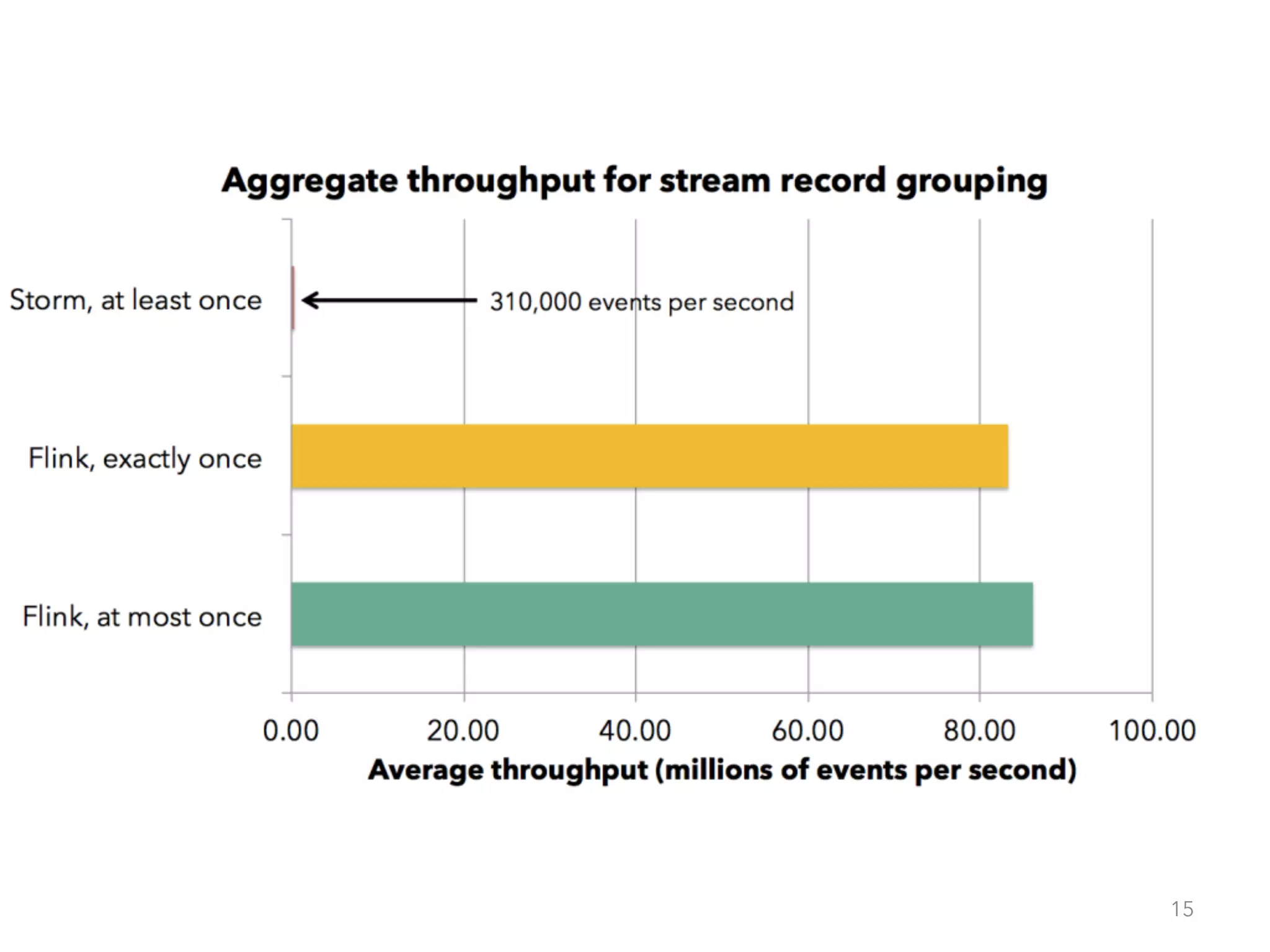

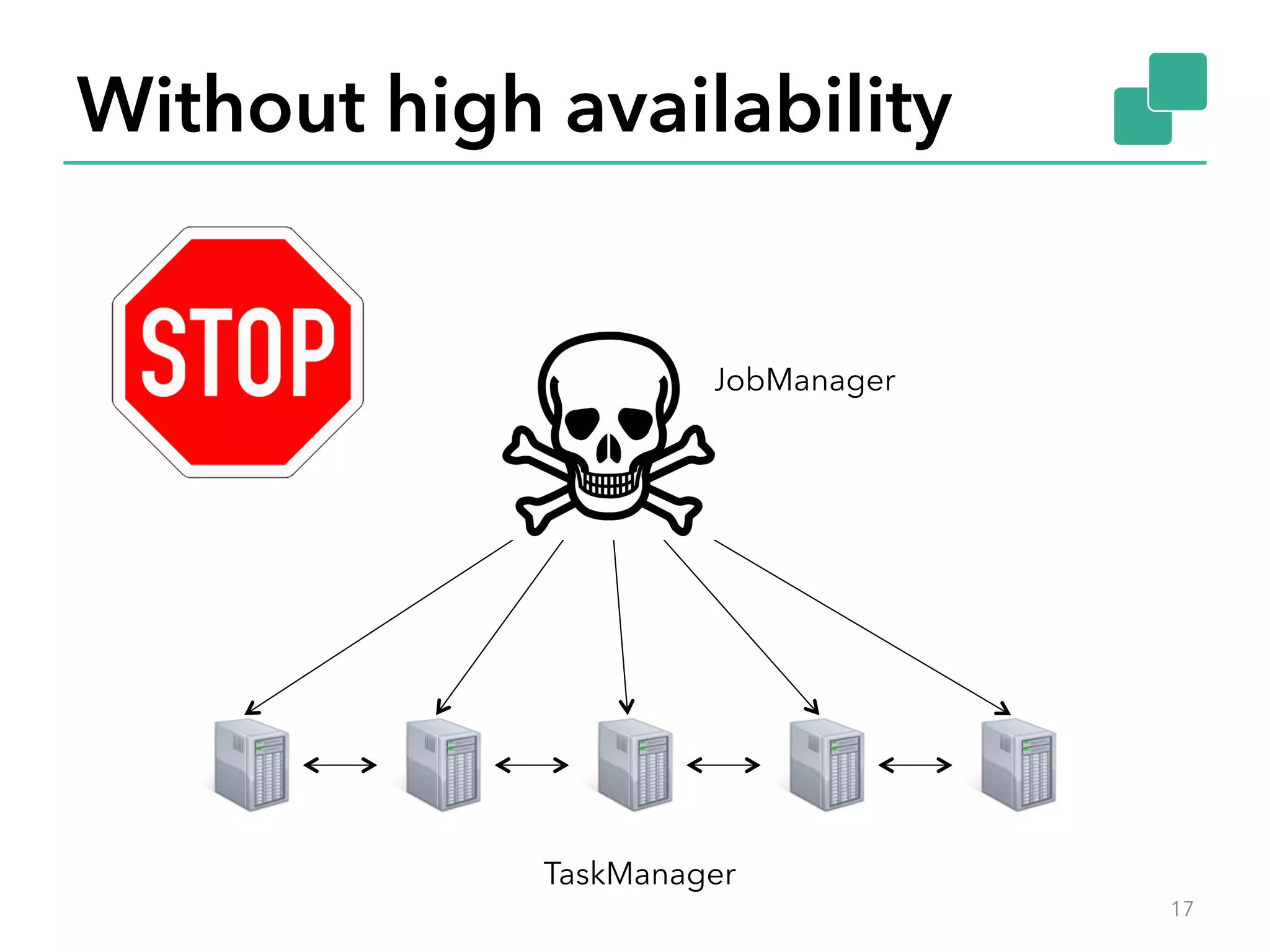
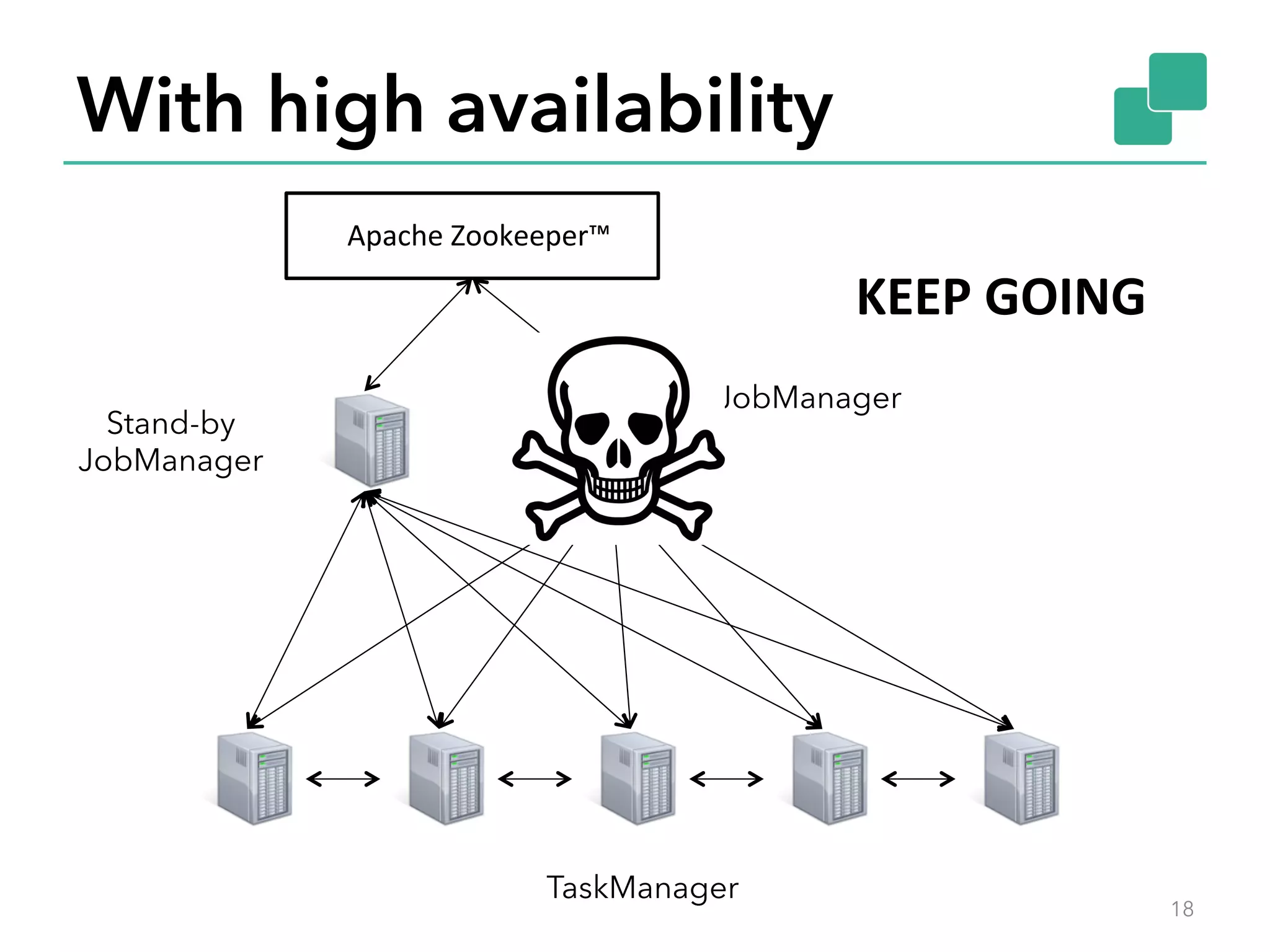
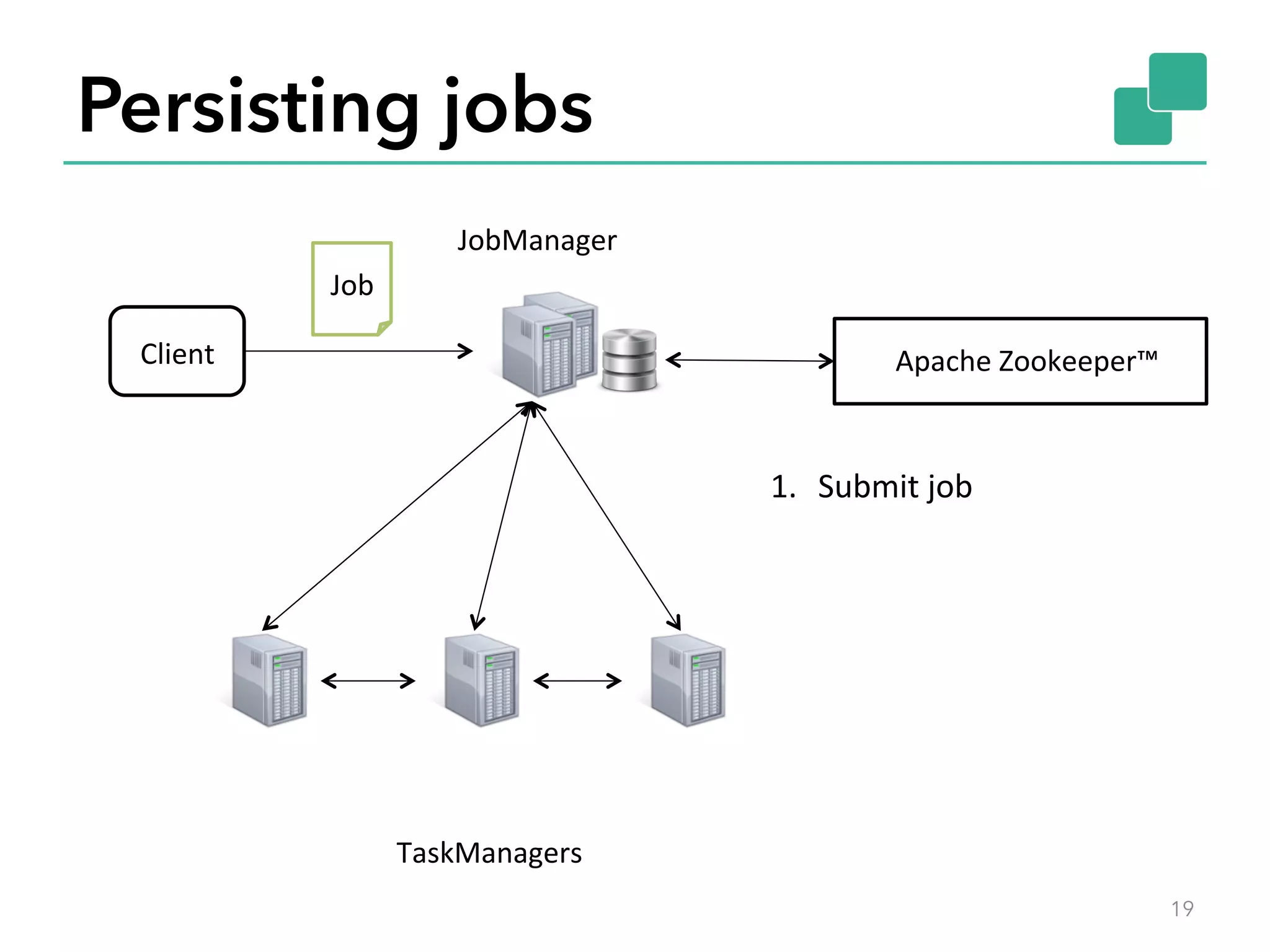
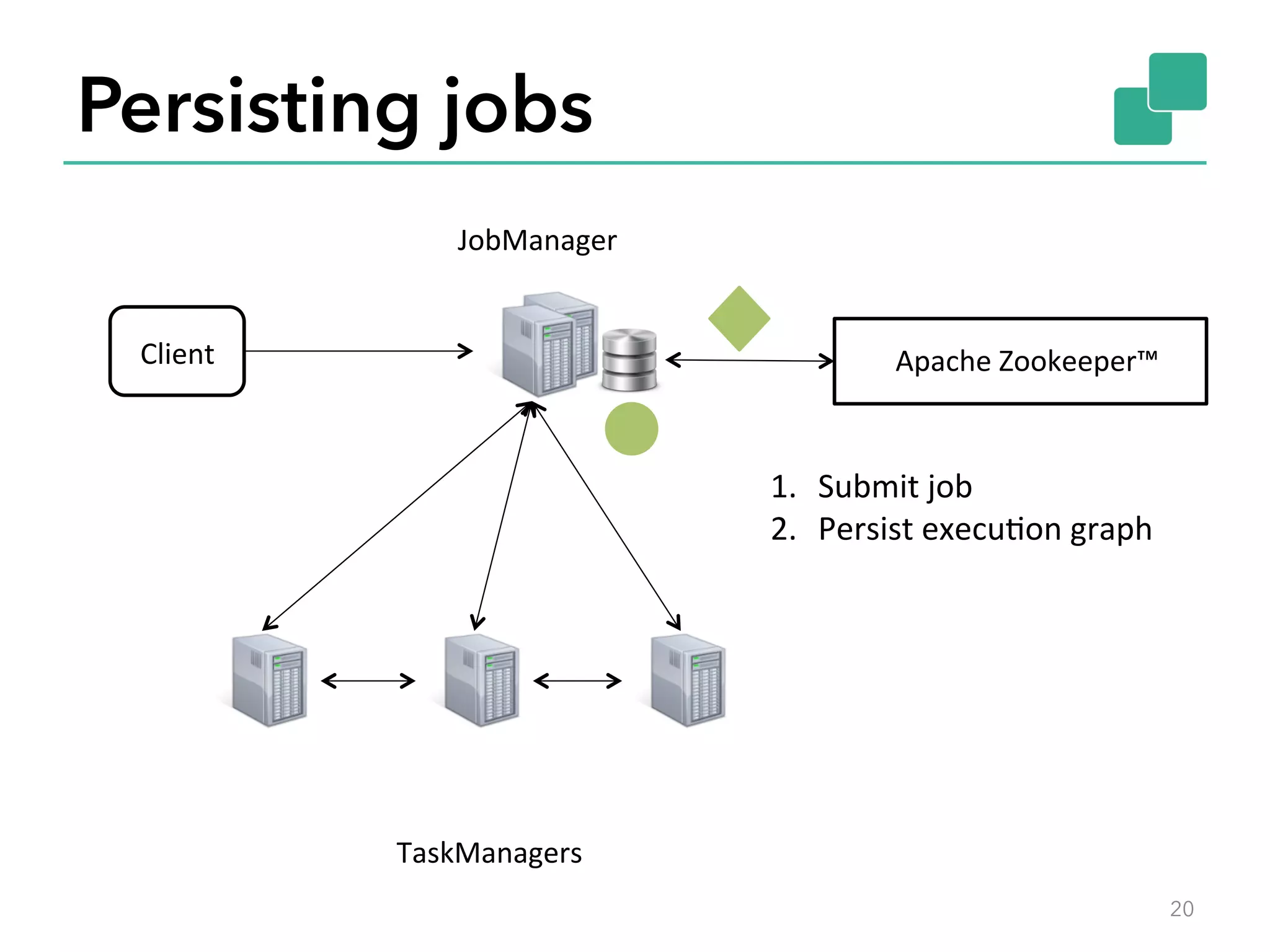
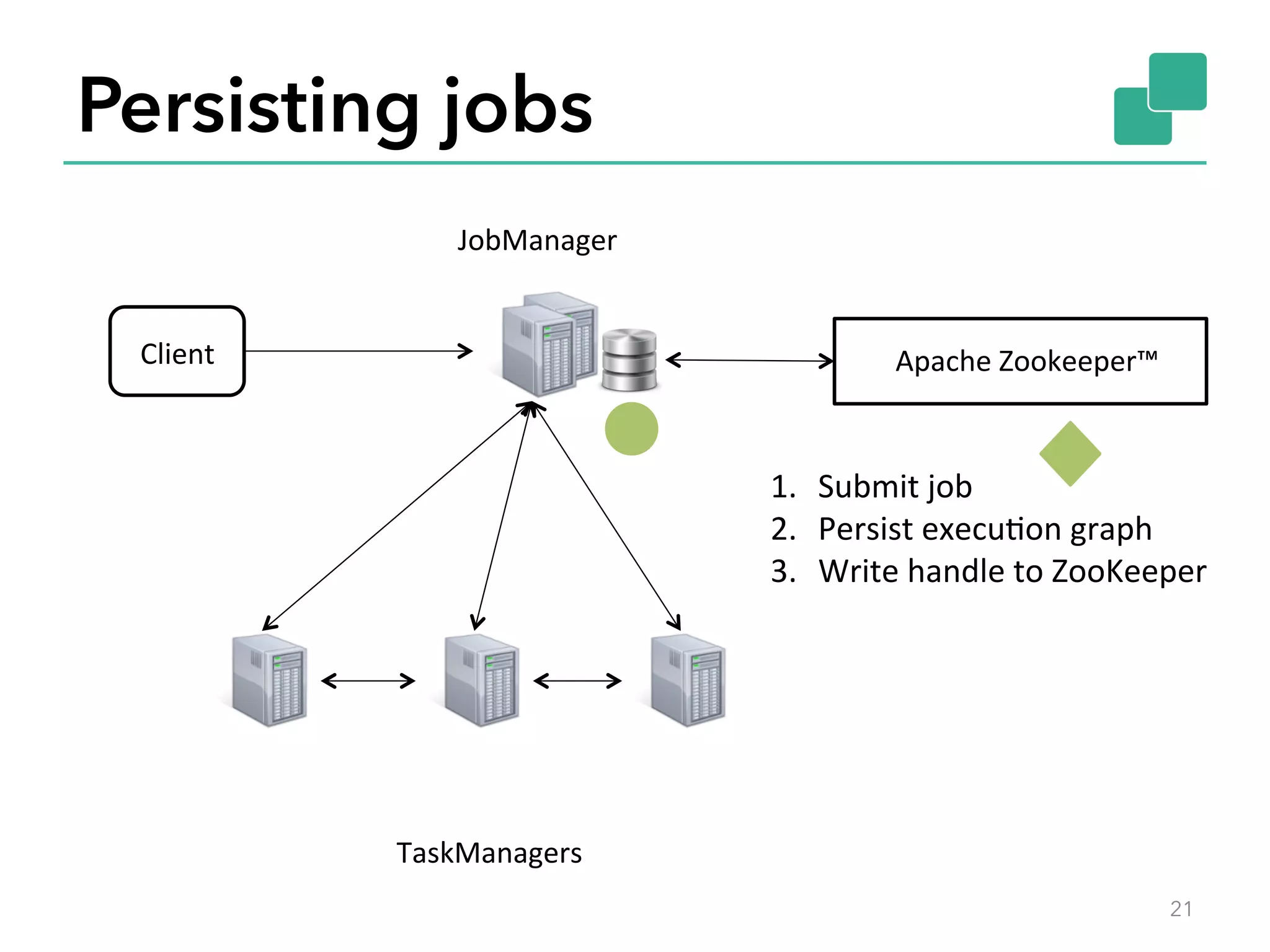
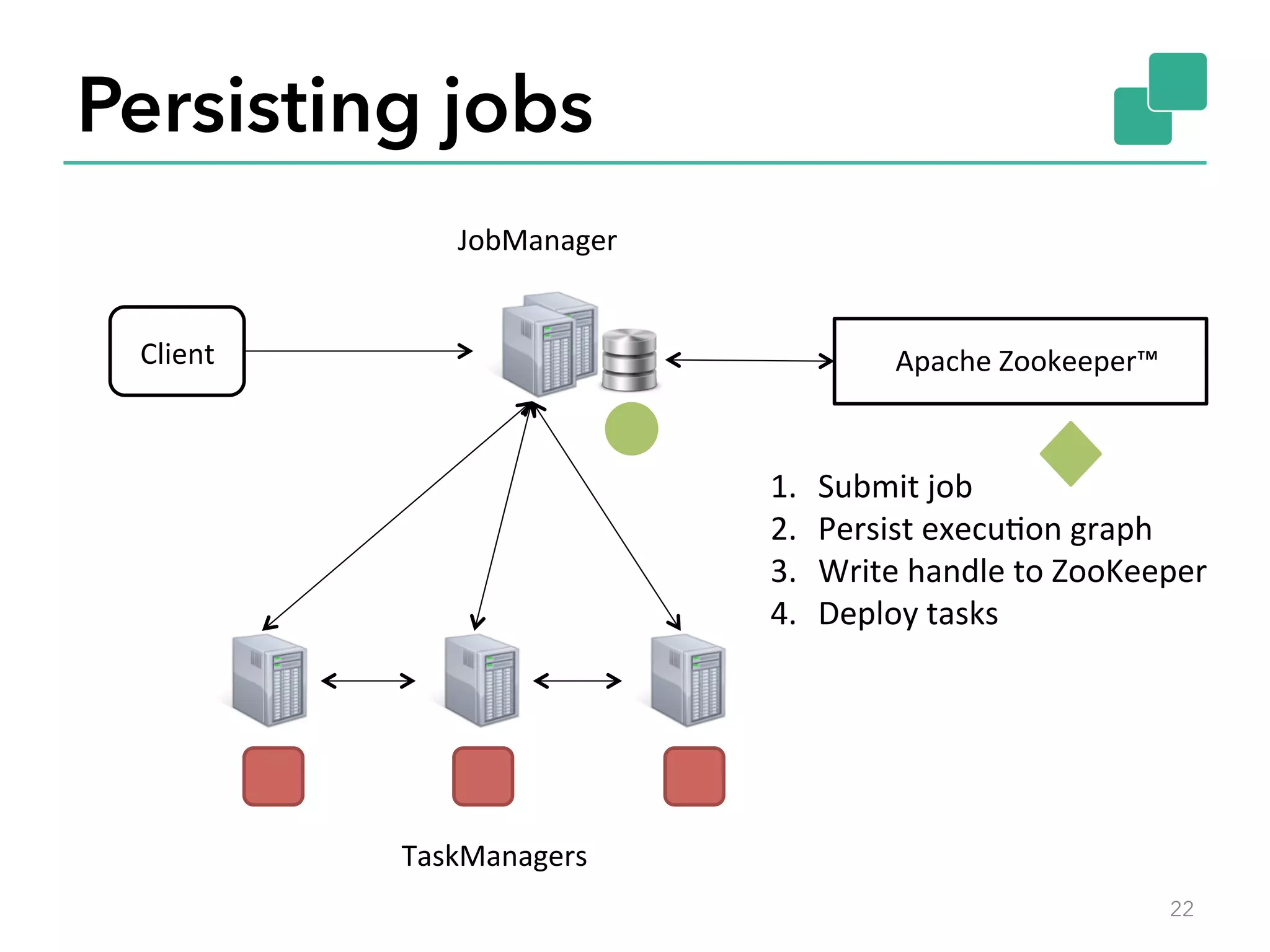
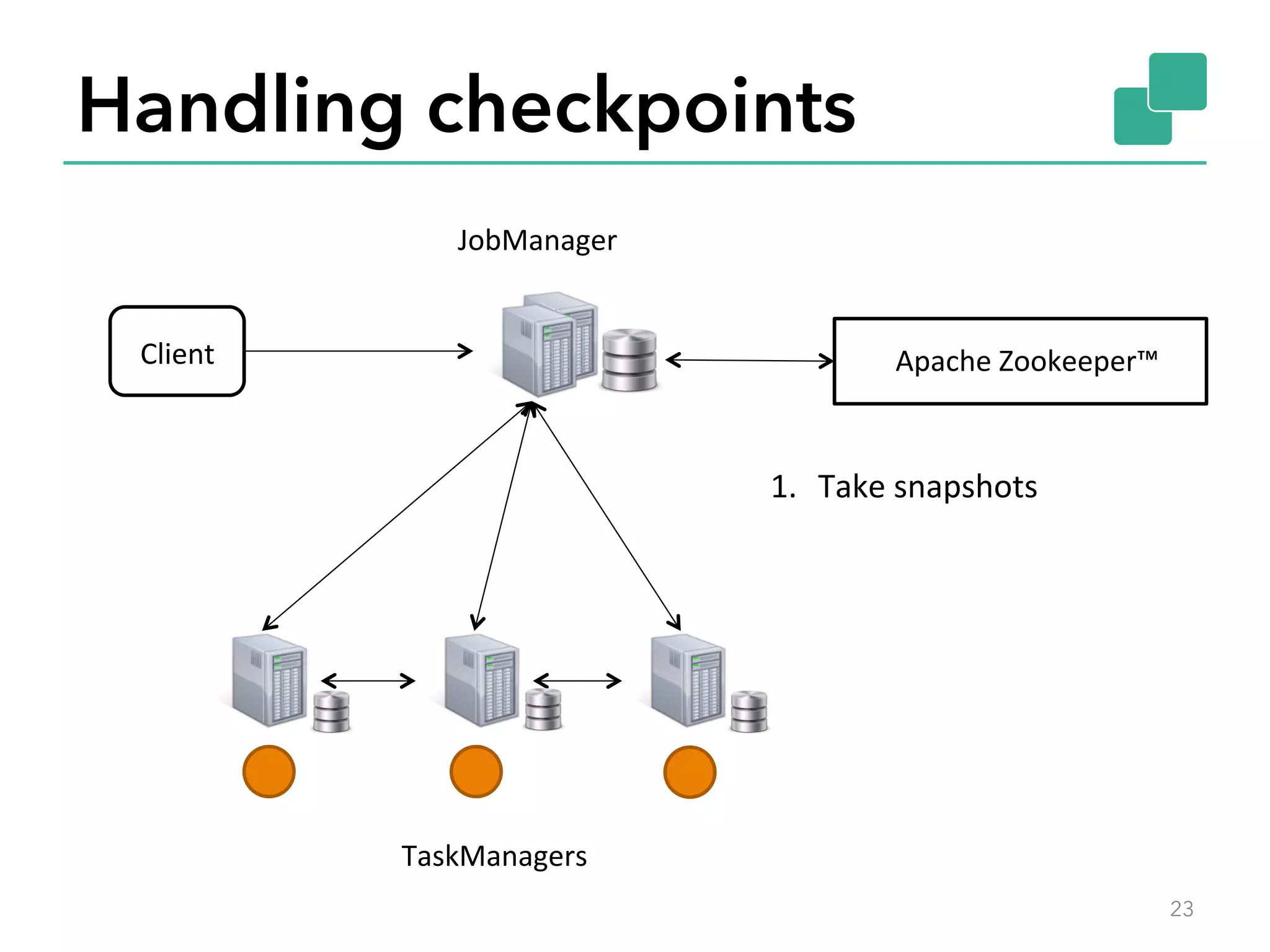
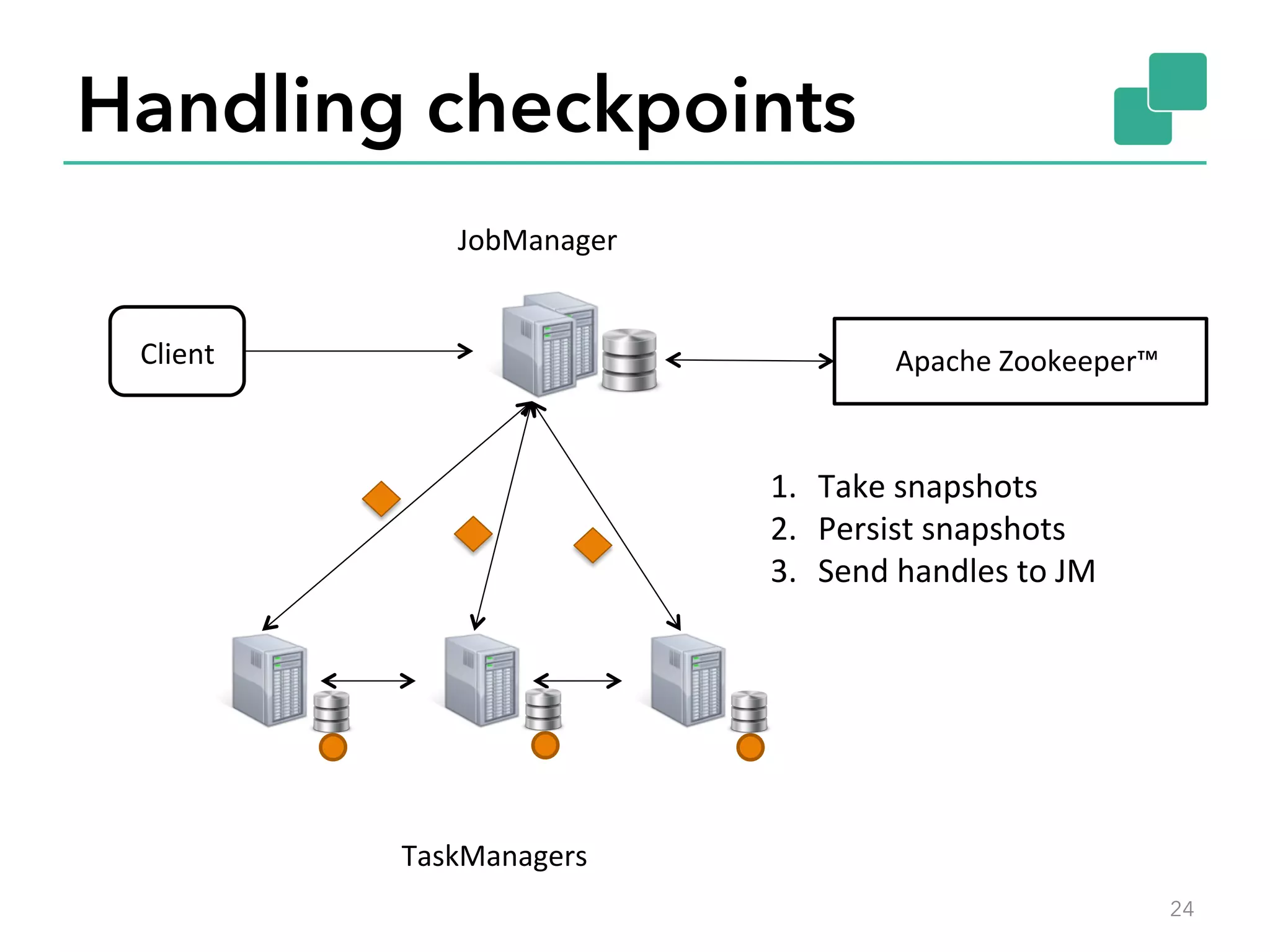
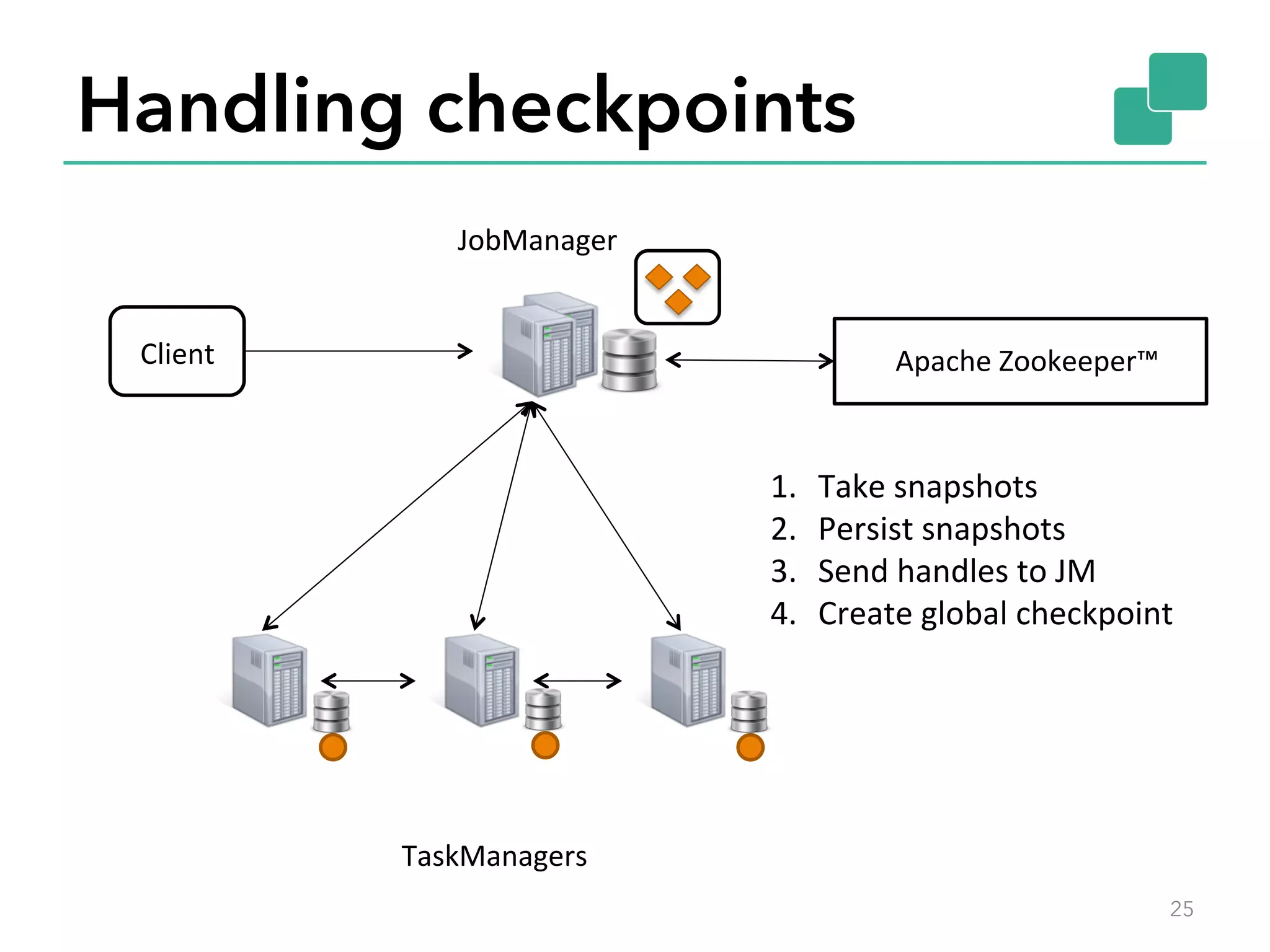
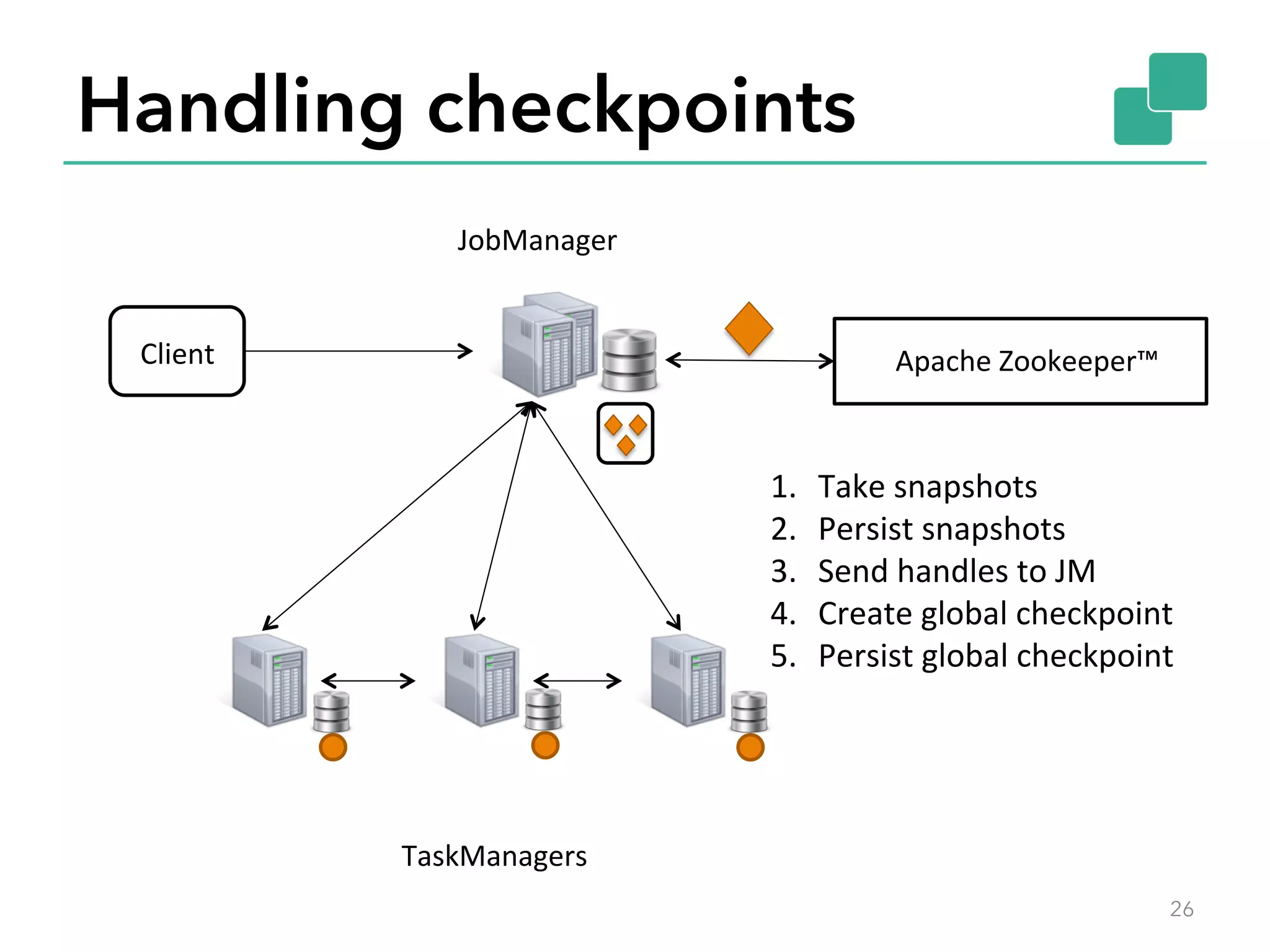
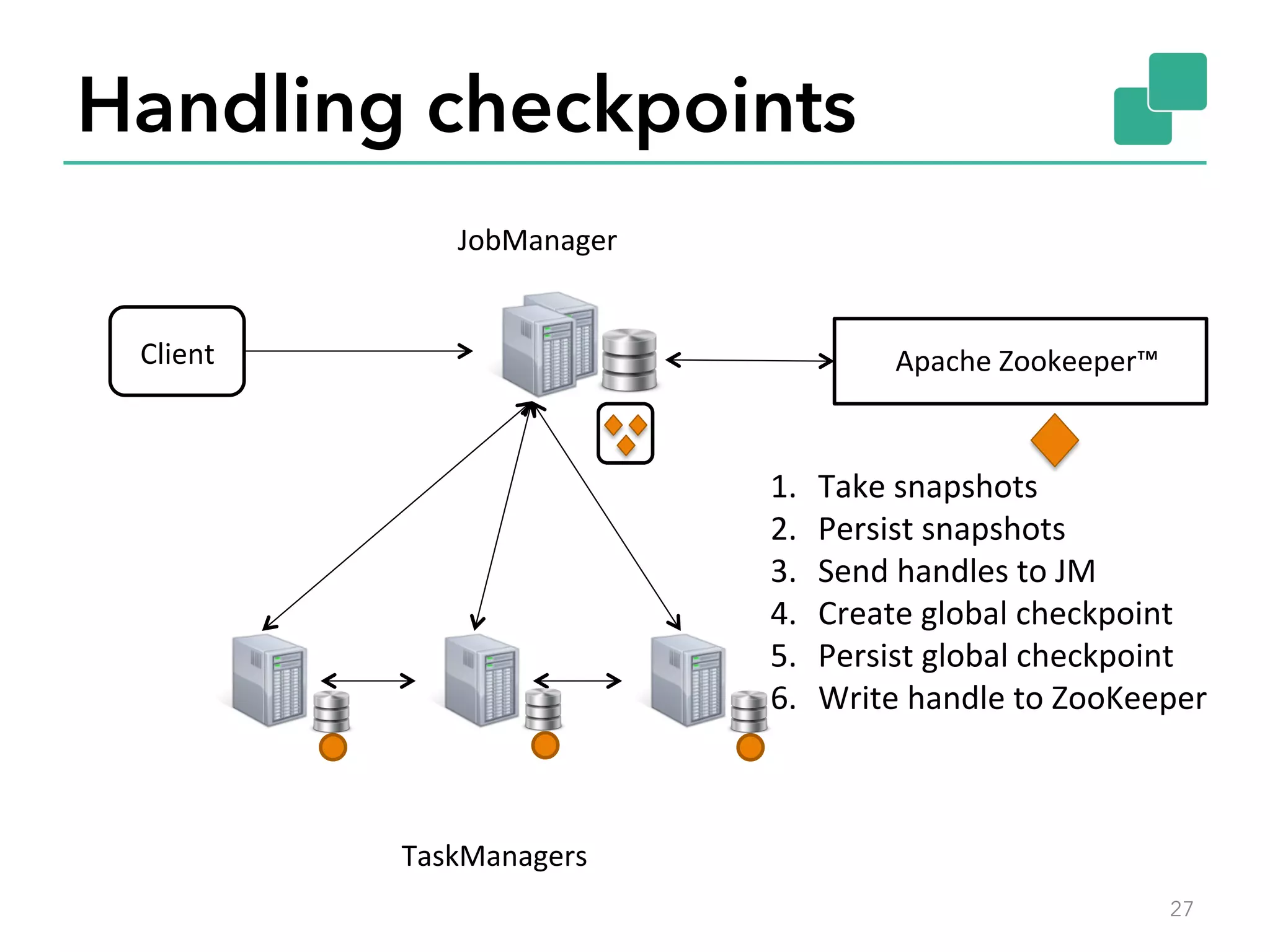






The document discusses fault tolerance and job recovery mechanisms in Apache Flink, highlighting the importance of implementing such features to prevent data loss and system downtime. It details concepts like checkpoints, barriers, and the different fault tolerance guarantees provided by Flink, enabling high availability and effective job processing. The overall message emphasizes that Flink ensures reliable data processing with low latency and high throughput through its advanced recovery strategies.


















































































