Downloaded 31 times






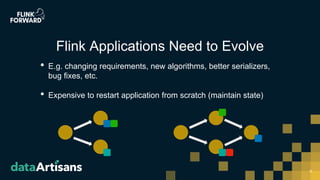

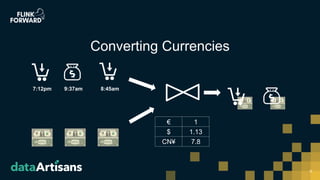
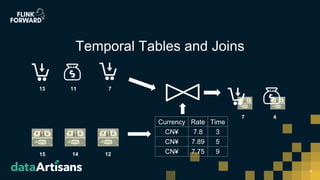





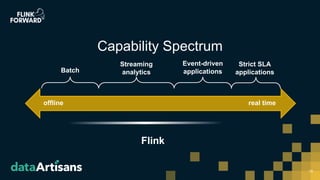


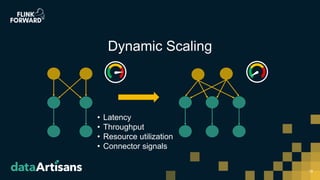

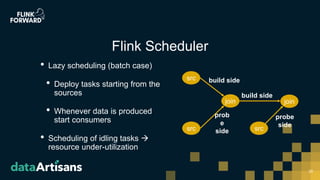


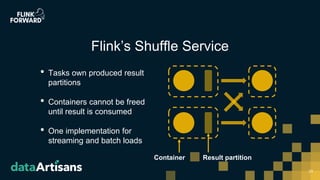
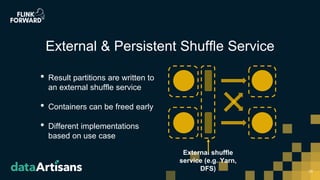
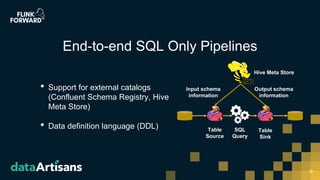



This document discusses Apache Flink version 1.7 and beyond. It summarizes key features of Flink 1.7 including contributions from 112 contributors and over 1,000 commits. It also discusses upcoming features in Flink 1.8 such as support for state schema evolution, dynamic scaling, unifying batch and streaming, an extendable scheduler, and end-to-end SQL-only pipelines. The document encourages participation in the Flink community.













































































